PIP 15: Pulsar Functions
- Status: Implemented
- Author: Sanjeev Kulkarni, Jerry Peng, Sijie Guo
- Pull Request:
- Mailing List discussion:
- Release: 2.0.0
There has been a renewed interest from users in lightweight computing frameworks. Typical things what they mean by lightweight is:
- They are not compute systems that need to be installed/run/monitored. Thus they are much more ops light. Some of them are offered as pure SaaS(like AWS Lambda) while others are integrated with message queues(like KStreams)
- Their interface should be as simple as it gets. Typically it takes the form of a function/subroutine that is the basic compute block in most programming languages. And API must be multi-language capable.
- The deployment models should be flexible. Users should be able to run these functions using their favorite management tools, or they can run them with the brokers.
The aim of all of these would be to dramatically increase the pace of experimentation/dev productivity. They also fit in the event driven architecture that most companies are moving towards where data is constantly arriving. The aim is for users to run simple functions against arriving data and not really worry about mastering the complicated API/semantics as well as managing/monitoring a complex compute infra.
A message queue like Pulsar sits at the heart of any event driven architecture. Data coming in from all sources typically lands in the message bus first. Thus if Pulsar(or a Pulsar extension) has this feature of being able to register/run simple user functions, it could be a long way to drive Pulsar adoption. Users could just deploy Pulsar and instantly have a very flexible way of doing basic computation.
This document outlines the goals/design of what we want in such a system and how they can be built into Pulsar.
- Simplest possible programmability: This is the overarching goal. Anyone with the ability to write a function in a supported language should be able to get productive in matter of minutes.
- Multi Language Capability:- We should provide the API in at-least the most popular languages, Java/Scala/Python/Go/JavaScript.
- Flexible runtime deployment:- User should be able to run these functions as a simple process using their favorite management tools. They should also be able to submit their functions to be run in a Pulsar cluster.
- Built in State Management:- Computations should be allowed to keep state across computations. The system should take care of persisting this state in a robust manner. Basic things like incrBy/get/put/update functionality is a must. This dramatically simplifies the architecture for the developer.
- Queryable State:- The state written by a function should be queryable using standard rest apis.
- Automatic Load Balancing:- The Managed runtime should take care of assigning workers to the functions.
- Scale Up/Down:- Users should be able to scale up/down the number of function instances in the managed runtime.
- Flexible Invocation:- Thread based, process based and docker based invocation should be supported for running each function.
- Metrics:- Basic metrics like events processed per second, failures, latency etc should be made available on a per function basis. Users should also be able to publish their own metrics
- REST interface:- Function control should be using REST protocol to have the widest adoption.
- Library/CLI:- Simple Libraries in all supported languages should exist. Also should come with basic CLI to register/list/query/stats and other admin activities.
The overarching goal of Pulsar Functions is simplicity. Thus the aim is to make the interface as simple as possible. Thus the core interface corresponds to the lowest building block of any programming language: A function/subroutine that takes in one argument, viz the input tuple. Thus in Java world a user can actually just code up a native java.util.Function and run it. An exclamation function for instance takes in the following form:
import java.util.Function;
public class ExclamationFunction implements Function<String, String> {
@Override
public String apply(String input) {
return input + "!";
}
}The python form of the above takes the following form:
def process(input):
return input + '!'Thus in its simplest form there is no requirement of any kind of sdk to write a function. This greatly simplifies developer productivity and likely adoption. There will also be an interface provided in the form of an SDK that is almost the same as above except for another Context parameter. In Java, that api looks as follows:
public interface PulsarFunction<I, O> {
O process(I input, Context context) throws Exception;
}This api is almost identical to the first API except that the Context parameter allows the programmer to do more powerful stuff. The context allows the users access a bunch of contextual information like message id of the message its processing, etc as well as allows user to use built in capabilities like KVStore thats described more in detail later. For a complete reference to the Context, please refer to the appendix.
The input to a pulsar function are messages from one(or more) pulsar topics. The output of a pulsar function are sent to an output topic. Note that users may choose not to output anything, in which case there are no messages in the output topic.
In Pulsar, a topic exists within a particular tenant/namespace hierarchy. Similarly a function exists within a particular tenant/namespace. Thus the triplet (tenant, namespace, function name) uniquely identifies a function. We refer to this triplet as Fully Qualified Function Name or FQFN to be short.
The core element of Pulsar Function execution framework is an Instance. An instance is pictured below.

A few features about Instance
- A collection of Consumers each consuming different topics represent the input side of a function. These consumers append to some sort of producer consumer queue. The consumers uses the FQFN as the subscriber name. This way one can run many instances of a function and the load will be automatically shared between them based on the subscription type. The subscription type can be specified at a per function level.
- The Executor consumes the PC queue and invokes the function.
- If the function returns any output, it is sent via a producer to the outgoing topic
- The instance is implemented in different programming languages. This way we can support multiple different languages.
The instance is invoked inside a runtime. Different types of runtimes are provided each with different costs and isolation guarantees. The following runtimes are supported:
- Process Runtime in which each instance is run as a process.
- Docker Runtime in which each instance is run as a docker container
- Threaded Runtime in which each instance is run as a thread. This type is applicable only to Java instance since Pulsar Functions framework itself is written in Java.
The easiest way to run a Pulsar Function would be to instantiate a Runtime/Instance and run them locally. A helper command line tool makes all of this simple. In this mode called localrun, the function is running as a standalone runtime and can be monitored and controlled by any process/docker/thread control mechanisms available. Users can spawn these runtime across machines manually or use sophisticated schedulers like Mesos/Kubernetes to distribute them across a cluster.
One can also run a function inside the Pulsar cluster alongside the broker. In this mode users can ‘submit’ their functions to a running pulsar cluster and Pulsar will take care of distributing them across the cluster and monitoring and executing them. This model allows developers to focus on writing their functions and not worry about managing their life cycle. The component of Pulsar that embodies this functionality is called as Pulsar Function Worker.
The purpose of the Pulsar Function Worker is monitor, orchestrate, and execute individual Pulsar Functions. The Pulsar Function Worker is a process that can be run inside a Pulsar broker or by itself in a cluster. The Pulsar Function Worker was designed to be standalone and self-contained thus the user does not need to worry about external dependencies other than their own to run a Pulsar Function.
The Pulsar Function Worker can be run as part of a Pulsar Broker or standalone to form a cluster of “worker” nodes. Pulsar Function Worker reuses many existing mechanism in Pulsar, e.g. leader election and topics to manage state, thus it does not bring in any external dependencies and reuses, as much as possible, already tested code.
A user can interact with workers via REST endpoints exposed by a web server that is run on every worker. These REST endpoints allows users to create, update, delete and get various information about the status of functions executing. We piggyback on the Pulsar admin webserver to expose these endpoints.
All state change requests to a function(create/delete/update) are published to a special topic called Function Metadata Topic (FMT). Every message written to this topic is keyed by FQFN and topic compaction is used to maintain only the latest update for each function. This prevents the topic from growing too large.
Each worker consumes the FMT and uses the Function Metadata Manager to keep track of all the metadata related to all submitted Pulsar Functions. The Function Metadata Manager uses the Function Metadata Topic (FMT) as a replicated state machine to persist all updates to functions so that a global state of functions can also be derived from the FMT. In this way, each worker knows about all the metadata of all functions.
The task of function assignment aka which workers handle which instances of a function is determined by the Membership Manager leader. A special topic called membership topic is used for this purpose. Upon startup, each worker writes into the membership topic, indicating that it is joining the worker ensemble. All workers subscribe to the membership topic in a failover subscription. This guarantees that there is only one active consumer for this topic at any point. The active worker becomes the leader and performs function assignment. In case of the leader fails, the failover subscription mechanism built into Pulsar chooses another worker to be the leader. This way there is a guaranteed leader despite worker failures. The elected leader performs function assignment using the Scheduler Manager. Currently we do a simple round robin assignment of function instances among all workers.
The assignment information is kept in a special topic called assignment topic. Anytime the leader notices a create/delete/update in its Function Metadata Manager, it triggers the scheduler manager to compute an assignment. The scheduler manager computes an assignment which is then written into the assignment topic. Each assignment message contains all assignments for all functions and workers at the point of time the assignment is computed. Thus only the latest assignment update needs to be preserved. Workers will acknowledge all all previous assignments updates allowing them to be garbage collected thus preventing the topic from growing large with old entries.
All workers subscribe to this assignment topic. In each worker the Function Runtime Manager listens to the Assignment Topic for assignment updates. When an assignment update is received, the Function Runtime Manager updates its internal state that contains the global view of all assignments for all workers and functions. If the assignment update changes the assignment on the current worker, the Function Runtime Manager materializes the new assignment via starting or stopping executing function instances.
The diagram below (Figure 1.) is a depiction of the architecture of the Pulsar Function Worker.
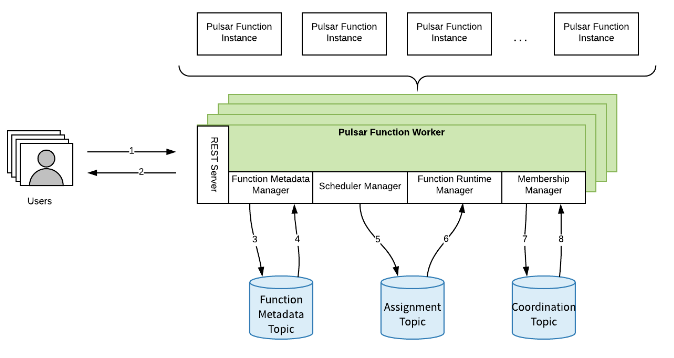
- User sends REST Server request
- REST Server responds to user requests
- Function Metadata Manager writes updates to FMT
- Function Metadata Manager read updates from FMT
- Scheduler Manager writes assignment updates to assignment topic
- Function Runtime Manager reads assignment updates and materializes the new assignment if necessary
- The Membership Manager uses the Coordination Topic for leader election
- The Membership Manager uses the Coordination Topic for maintaining an active membership
Here is an example of a typical workflow of a Pulsar Function Worker:
- A user submits request to the REST server to run a function. This request can be submitted to any worker, as the assignment of the function does not depend on which worker the user request is sent to.
- The REST server will pass the request to the Function Metadata Manager, and the Function Metadata Manager will write that request into the Function Metadata Topic (FMT).
- The Function Metadata Manager also listens for new entries in the FMT. When the Function Metadata Manager receives a new message from the FMT. It will examine the message to see if the message is out of date or not. If the message is out of date, the message will be discarded. If not, the Function Metadata Manager uses the message to update its internal state that contains the global view of all functions that are running. Since every worker runs a Function Metadata Manager, every worker has a eventually consistent global view of all the state of all functions running. Thus, read request like one that gets the status of a running function can be submitted to any worker.
- When the Function Metadata Manager updates its internal state, the Scheduler Manager will also be triggered. Since there is an update to the system, a new schedule needs to be computed. One worker, the leader (chosen through leader election), will execute a scheduling strategy, e.g. round robin, to compute a new assignment and that new assignment is written to the Assignment Topic. The Membership Manager is used for maintaining a leader in the cluster as well as a list of all active workers.
- The Function Runtime Manager listens to the Assignment Topic for assignment updates. When an update arrives, the Function Runtime Manager updates its internal state that contains a global view of all assignments for every worker. If the assignment update, changes the functions assignment it, the Function Runtime Worker will also start or stop function instances accordingly.
Pulsar Functions are not limited to be run via Pulsar Function Workers. Pulsar Functions can also be run via other schedulers such as Kubernetes. The Pulsar Function Worker just provides an out of box solution for users to run Pulsar Functions but should be in no way limit how and where individual functions can be run.
One of the most well known use cases for an event driven computing framework is to keep track of something aka state. Typically this involves computing the state and saving/caching it in another system. When using most of the other compute frameworks, one has to rely on some external service to provide this functionality.
Pulsar uses Apache BookKeeper as the stream storage for persisting its messages. BookKeeper provides a ledger based API that allows Pulsar to do so. Similarly BookKeeper has a built-in key value store to store its meta-data information. Pulsar functions exposes this BookKeeper API to allow functions to store any kind of persistent state. Since Pulsar already uses bookkeeper here is no additional component to run and manage. This provides a unified message + storage solution for pulsar functions to execute lightweight computation.
This key/value table service provides common key/value operations, such as Get/Put/Delete/Increment operation, allowing pulsar functions to persistent its computation results (aka state) and application can query these computation results via CLI tools, storage client or restful api.
Although Apache BookKeeper provides a generic key/value table service, currently we only expose
Increment operation to pulsar function in the first version. As what we have been seeing in the
real-time use cases (such as ETL, streaming analytics), distributed counting is the most common use
case, provide a built-in counter service is vastly simplifying people using pulsar function for
ETL, streaming analytics and various use cases.
Pulsar functions expose the state in the Context object which can be accessed in the function
method. The function writers can use the incrCounter to increment the amount of keys.
/**
* The counter object that can be used for counting.
*/
void incrCounter(String key, long amount);The modification of the counter is applied globally and is available for queries after the execution of a pulsar function. Pulsar Functions provides a built-in CLI for querying the counters.
bin/pulsar-functions functions querystate --tenant <tenant> --namespace <namespace> \
--function-name <function-name> --key <counter-key> [--watch]The function processing guarantee is also applied to the state updates. These guarantees include:
- At-Most Once
- At-Least Once
- Effectively Once
The effectively once is basically achieved by at-least once processing and guaranteed server side deduplication. This means a state update can happen twice, but the same state update will only be applied once, the other duplicated state updates will be discarded at the server side.
Figure 2 illustrates the request flow of how pulsar functions update function state and how the user can use the CLI tool to query the function state. Each pulsar function instance issues an increment operation to the key/value table used by a pulsar function, which the increment operation will increment the amount for a given key. All the increment operations are journaled in the bookkeeper, and aggregated and materialized into a key/value table representation. The application can later use the CLI tool or storage api for access the aggregated value for keys.

The state for each pulsar function is powered by a key/value table in Apache BookKeeper. The key/value table is partitioned into N key ranges, each key range stores and serves a subset of keys. Each key range stores its WAL and checkpoints as bookkeeper ledgers, and indexed in a local rocksdb instance for caching and querying purpose.
See more details at BookKeeper BP-30: Table Service.
public interface Context {
/**
* Returns the messageId of the message that we are processing
* This messageId is a stringified version of the actual MessageId
* @return the messageId
*/
byte[] getMessageId();
/**
* The topic that this message belongs to
* @return The topic name
*/
String getTopicName();
/**
* Get a list of all source topics
* @return a list of all source topics
*/
Collection<String> getSourceTopics();
/**
* Get sink topic of function
* @return sink topic name
*/
String getSinkTopic();
/**
* Get output Serde class
* @return output serde class
*/
String getOutputSerdeClassName();
/**
* The tenant this function belongs to
* @return the tenant this function belongs to
*/
String getTenant();
/**
* The namespace this function belongs to
* @return the namespace this function belongs to
*/
String getNamespace();
/**
* The name of the function that we are executing
* @return The Function name
*/
String getFunctionName();
/**
* The id of the function that we are executing
* @return The function id
*/
String getFunctionId();
/**
* The id of the instance that invokes this function.
*
* @return the instance id
*/
String getInstanceId();
/**
* The version of the function that we are executing
* @return The version id
*/
String getFunctionVersion();
/**
* The logger object that can be used to log in a function
* @return the logger object
*/
Logger getLogger();
/**
* The counter object that can be used for counting.
*
* @return the counter object.
*/
void incrCounter(String key, long amount);
/**
* Get Any user defined key/value
* @param key The key
* @return The value specified by the user for that key. null if no such key
*/
String getUserConfigValue(String key);
/**
* Record a user defined metric
* @param metricName The name of the metric
* @param value The value of the metric
*/
void recordMetric(String metricName, double value);
/**
* Publish an object using serDe for serializing to the topic
* @param topicName The name of the topic for publishing
* @param object The object that needs to be published
* @param serDeClassName The class name of the class that needs to be used to serialize the object before publishing
* @return
*/
<O> CompletableFuture<Void> publish(String topicName, O object, String serDeClassName);
/**
* Publish an object using DefaultSerDe for serializing to the topic
* @param topicName The name of the topic for publishing
* @param object The object that needs to be published
* @return
*/
<O> CompletableFuture<Void> publish(String topicName, O object);
CompletableFuture<Void> ack(byte[] messageId, String topic);
}