Design zh CN
这里的队列一个双向链表,其将所有HashTable中的元素有序排列在其中。一个元素可以在O(1)的时间复杂度内从HashMap中找到并操作在队列上与其相邻的元素。
访问顺序被定义为缓存中的元素被创建,更新或是被访问的顺序。最近最少被使用的元素将会在队首,而最近被使用的元素将会在队列末尾。这为基于容量的驱逐策略(maximumSize)和基于空闲时间的过期策略(expireAfterAccess)的实现提供了帮助。使用这个队列的挑战在于每次访问都将会对队列当中的节点发生改变,这无法有效的通过并发操作实现。
写顺序被定义为缓存中的元素被创建和更新的顺序。和访问顺序队列类似,写顺序队列的操作也都是基于O(1)的时间复杂度。这个队列为基于存活时间的驱逐策略(expireAfterWrite)的实现提供帮助。
分层时间轮是一个使用hash定位的时间感知的双向链表队列,所有基于其的操作也都是基于O(1)的时间复杂度。这个队列为基于指定时间的驱逐策略 (expireAfter(Expiry))的实现提供帮助。
典型的缓存实现将会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种替代方案是将每个重新排序的操作加入到缓冲区中进行批处理操作。这可以当作页面替换策略的预写日志。当缓冲区满的时候,将会立即尝试获取锁并挂起,直到缓冲区内的操作被处理完毕后将会立即返回。
读缓冲的实现是基于striped ring buffer带状环形队列。带状的设计是以将线程进行hash的方式得到的结果来选择其中一条环形队列来实现,以减少线程之间的资源竞争。环形队列是一个定长数组,提供高性能的能力并最大程度上减少了GC所带来的性能开销。而环形队列的具体数量可以根据竞争预测算法进行动态调整。
与读缓冲类似,写缓冲是为了重放写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此读缓冲中的事件完整程度允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个高效的环形队列。由于每次向写缓冲填充的时候都要清空写缓冲中的内容,因此通常情况下写缓冲的容量都为空或者很小。
这个缓冲区由一个可扩展至最大大小的环形数组所实现。当调整数组大小的时候将会直接分配内存生成一个新的数组。而前置数组将会指向新的数组以便消费者可以访问,这允许旧的数组访问后可以直接释放。通过这种分块机制,这允许缓冲区可以拥有一个较小的初始大小,较低的写入访问成本并且产生较小的垃圾。当缓冲区被写满并无法扩容的时候,缓冲区的生产者将会尝试自旋并触发维护操作,并在短暂的时间后返回可执行状态。这样可以使消费者线程根据线程优先级来清空缓存区重放写操作。
传统缓存会给每个操作加锁,而Caffeine将会通过批处理将加锁开销分摊到各个线程中。这样,锁带来的副作用将由各线程均摊而避免加锁竞争带来的性能开销。维护操作将会分发给所配置的线程池进行执行,在任务被拒绝或者指定调用线程执行策略下,也可以由使用者线程进行维护操作。
批处理的一个优势在于,由于锁的排他性,同一时间将只会有一个线程处理缓冲区内的数据。这将使得基于多生产者/单消费者的消费模型缓冲区实现更加高效。这也将更好地利用CPU缓存优势来更适应硬件特性。
对于缓存的一个挑战便是当缓存不被一个排他锁所保护的时候,针对缓存的操作可能以错误的顺序进行重放。在并发竞争条件下,一个创建-读取-更新-删除的顺序操作可能无法以正确顺序写入缓存。如果要保证顺序正确,可能需要更粗粒度的锁从而导致性能下降。
与典型的并发数据结构一样,Caffeine使用原子状态转变来解决这一难题。一个缓存元素具有存活,退休,死亡三种状态。存活状态是指某一元素同时存在与Hash表和访问/写队列中。而一个元素从Hash表中被移除的时候,其状态也将变为退休并需要从队列中移除。当从队列也移除后,一个元素的状态将会被视为死亡并在GC中被回收。
Caffeine 对充分利用volatile操作花费了很多精力。 内存屏障提供了一种从硬件角度出发的视角来代替从语言层面思考volatile的读写。通过了解具体哪些屏障被建立以及它们对硬件和数据可视化的影响,将具有实现更好性能的潜力。
当在锁下进行独占访问的时候,Caffeine使用relaxed reads, 因为数据的可见性可以通过锁的内存屏障获取。这在数据竞争无法避免的情况下,比如在读取元素时校验是否过期来模拟缓存丢失,是可以接受的。
Caffeine 以一种和reads相似的方式使用relaxed writes。当一个元素在锁定状态进行排他写,那么写入可以在解锁时释放的内存屏障返回。这也可以用来支持解决写偏序问题,比如在读取一个数据的时候更新其时间戳。
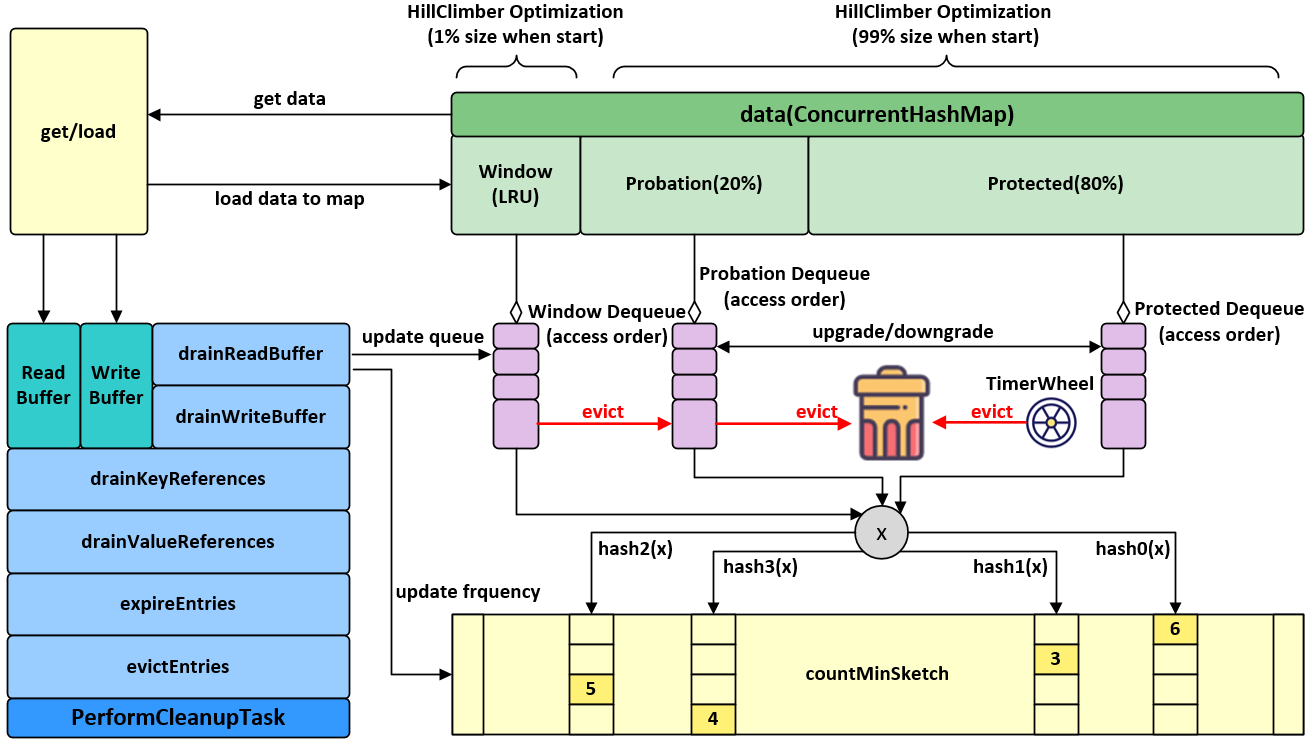
Caffeine 使用 Window TinyLfu策略提供了几乎最优的命中率。访问队列将会被分为两个部分:TinyLfu策略将会从缓存的进入窗口中选择元素驱逐到缓存的主空间当中。TinyLfu会比较窗口中的受害者和主空间的受害者之间的访问频率,选择保留两者之间之前被访问频率更高的元素。频率将在CountMinSketch中通过4位存储,这将为每个元素占用8个字节去计算频率。这些设计允许缓存能够以极小的代价基于访问频率和就近程度去对缓存中的元素进行O(1)时间复杂度的驱逐操作。
进入窗口的大小和主空间的大小将会基于缓存的工作负载特征动态调节。当更加偏向就近度的时候,窗口将会空间更大,而偏向频率的时候窗口则将更小。Caffeine使用了hill climbing算法去采样命中率来调整,并将其配置为最佳的平衡状态。
当缓存的大小还未超过总容量的 50%,驱逐策略也未用的时候,用来记录频率的sketch将不会初始化以减小内存开销,因为缓存可能人为地给了一个较高的阈值进行加载。当没有其他特性要求的时候,访问将不会被记录,以避免读缓冲上的竞争和重放读缓冲上的访问事件。
当key之间的hash值相同,或者hash到了同一个位置,这类的hash冲突可能会导致性能降低。hash表采用将链表降级为红黑树来解决这一问题。
一种针对TinyLFU的攻击行为是人为地提高驱逐策略下的元素的预估频率。这将导致所有后续进入的元素被频率过滤器所拒绝,导致缓存失效。一种解决方案是在比较过程中加入少量抖动使得最后的结果具有一定的不确定性。这通过1%以下的概率选择保留一个将要被驱逐的窗口中的就近更高的中等访问频率元素来实现。
Cache 有许多不同的配置,只有使用特定功能的子集的时候,相关字段才有意义。如果默认情况下所有字段都被存在,将会导致缓存和每个缓存中的元素的内存开销的浪费。而通过代码生成的最合理实现,将会减少运行时的内存开销但是会需要磁盘上更大的二进制文件。
这项技术有通过算法优化的潜力。也许在构造的时候用户可以根据用法指定最适合的特性。一个移动应用可能更需要更高的并发率,而服务器可能需要在一定内存开销下更高的命中率。也许不需要通过不断尝试在所有用法中选择最佳的平衡,而可以通过驱动算法进行选择。
缓存通过在ConcurrentHashMap之上进行封装来添加所需要的特性。缓存和hash表的并发算法非常复杂。通过将两者分开,可以更便利地应用hash表的设计的优秀之处,也可以避免更粗粒度的锁覆盖全表和驱逐所引发的问题。
这种方式的成本是额外的运行时开销。这些字段可以直接内联到表中的元素上,而不是通过包装容纳额外的元数据。缺少包装可以提供单次表操作的快速路径(比如lambdas)而不是多次map调用和短暂存活的对象实例。
之前的项目中探索了两种途径:基于ConcurrentLinkedHashMap 的封装和 Guava中hash表的分支开发。在最后的设计里,分支开发的想法最后没有实施,因为工程实在是太复杂了。

