Design
A doubly linked list orders all of the entries residing in the hash table. An entry can be manipulated in O(1) time by finding it in the hash map and then manipulating its neighboring elements.
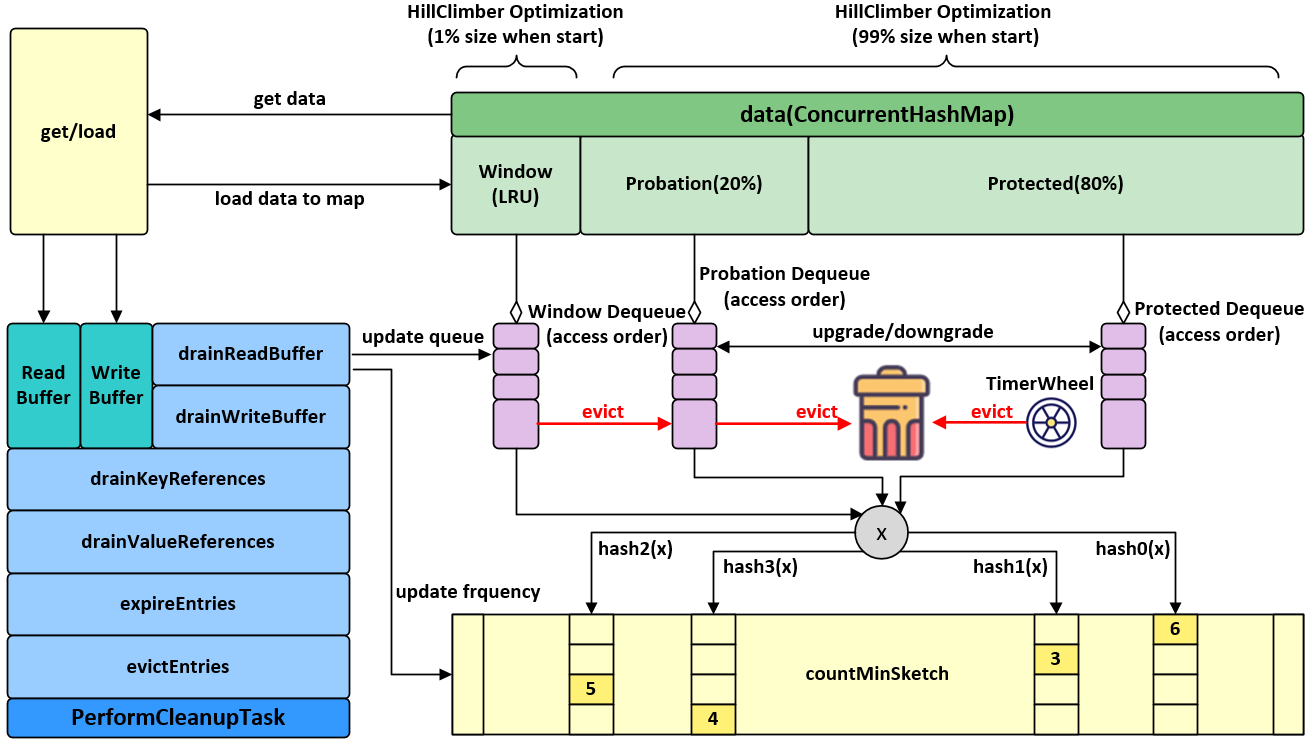
Access order is defined as the creation, update, or read of an entry. The least recently used entry is ordered at the head and the most recently at the tail. This provides support for size-based eviction (maximumSize) and time-to-idle eviction (expireAfterAccess). The challenge is that every access requires a mutation of this list, which itself cannot be implemented efficiently concurrently.
Write order is defined as the creation or update of an entry. Similar to the access ordered queue, the write order queue is operated on in O(1) time. This queue is used for time-to-live expiration (expireAfterWrite).
A time-aware priority queue that uses hashing and doubly linked lists to perform operations in O(1) time. This queue is used for variable expiration (expireAfter(Expiry)).
Typical caches lock on each operation to safely reorder the entry in the access queue. An alternative is to store each reorder operation in a buffer and apply the changes in batches. This could be viewed as a write-ahead log for the page replacement policy. When the buffer is full an attempt is made to acquire the lock and perform the pending operations, but if it is already held then the thread can return immediately.
The read buffer is implemented as a striped ring buffer. The stripes are used to reduce contention and a stripe is selected by a thread specific hash. The ring buffer is a fixed size array, making it efficient and minimizes garbage collection overhead. The number of stripes can grow dynamically based on a contention detecting algorithm.
Similar to the read buffer, this buffer is used to replay write events. The read buffer is allowed to be lossy, as those events are used for optimizing the hit rate of the eviction policy. Writes cannot be lost, so it must be implemented as an efficient bounded queue. Due to the priority of draining the write buffer whenever populated, it typically stays empty or very small.
The buffer is implemented as a growable circular array that resizes up to a maximum. When resizing a new array is allocated and produced into. The previous array includes a forwarding link for the consumer to traverse, which then allows the old array to be deallocated. By using this chunking mechanism the buffer has a small initial size, low cost for reading and writing, and creates minimal garbage. When the buffer is full and cannot be grown, producers continuously spin retrying and attempting to schedule the maintenance work, before yielding after a short duration. This allows the consumer thread to be prioritized and drain the buffer by replaying the writes on the eviction policy.
While traditional caches lock on each operation to perform tiny amounts of work, Caffeine batches the work and spreads the cost across many threads. This amortizes the penalty under lock rather than creating lock contention as the cost. This maintenance penalty is delegated to the configured executor, though it may be performed by a user thread if the task is rejected or a caller runs policy is used.
An advantage of batching is that the buffers are only ever drained by a single thread at a given time, due to the exclusive nature of the lock. This allows using more efficient multiple-producer / single-consumer based buffer implementations. It also better aligns to the hardware characteristics by taking advantage of CPU cache efficiencies.
A challenge when the cache is not guarded by an exclusive lock is that operations may be recorded and replayed in the wrong order. Due to races, a create-read-update-delete sequence may not be stored in the buffers in the same order. To do so would require coarse grained locks, thereby reducing performance.
As is typical in concurrent data structures, Caffeine resolves this dilemma using atomic state transitions. An entry is alive, retired, or dead. The alive state means that it exists in both the hash table and the access/write queues. When the entry is removed from the hash table, it is marked as retired and needs to be removed from the queues. When that occurs the entry is considered dead and is eligible for garbage collection.
Caffeine takes great care to make every volatile operation count. Instead of thinking in terms of the language's volatile reads and writes, memory barriers provide a hardware oriented view. By understanding which barriers are emitted and their effect on the hardware and data visibility, there exists realizable potential for better performance.
Caffeine uses relaxed reads when exclusive access is guaranteed under the lock, as data visibility is provided by the lock acquisition's memory barrier. It may also be acceptable when data races will occur regardless, such as when checking if an entry has expired upon read to simulate a cache miss.
Caffeine uses relaxed writes in a similar manner to reads. If the entry is exclusively written to under a lock then the write can piggy back on the memory barrier emitted when unlocked. It may also be acceptable at times to favor write skew, such as when updating the access timestamp when reading an entry.
Caffeine uses the Window TinyLfu policy to provide a near optimal hit rate. The access queue is split into two spaces: an admission window that evicts to the main spaces if accepted by the TinyLfu policy. TinyLfu estimates the frequency of the window's victim and the main's victim, choosing to retain the entry with the highest historic usage. The frequency counts are stored in a 4-bit CountMinSketch, which requires 8 bytes per cache entry to be accurate. This configuration enables the cache to evict based on frequency and recency in O(1) time and with a small footprint.
The size of the admission window and main space are dynamically determined based on the workload characteristics. A large window is favored if recency-biased and a smaller one by frequency-biased. Caffeine uses hill climbing to sample the hit rate, adjust, and configure itself to the optimal balance.
When the cache is below 50% of its maximum capacity the eviction policy is not yet fully enabled. The frequency sketch is not initialized to reduce the memory footprint, as the cache might be given an artificially high threshold. An access is not recorded, unless required by another feature, to avoid contention on the read buffer and replaying the accesses when draining.
When the keys have the same hash code, or hash to the same locations, the collisions could be exploited to degrade performance. The hash table solves this problem by degrading from linked-list to red-black tree bins.
An attack on TinyLFU is to use a collision to artificially raise the estimated frequency of the eviction policy's victim. This results in all new arrivals being rejected by the frequency filter, thereby making the cache ineffective. A solution is to introduce a small amount of jitter so that the decision is non-deterministic. This is done by randomly admitting ~1% of the rejected candidates that have a moderate frequency.
There are many different configuration options resulting in most fields being required only if a certain subset of features are enabled. If all fields are present by default, this can be wasteful by increasing the cache and per entry overhead. By code generating the optimal implementation, the runtime memory overhead is reduced at the cost of a larger binary on disk.
This technique has potential to be used for algorithmic optimizations. Perhaps when constructing the cache the user could specify the characteristics optimal for their usage. A mobile application may prefer a higher hit rate over concurrency, while a server application may desire a higher hit rate at a cost of memory overhead. Instead of trying to find the optimal balance for all usages, intent could drive the algorithmic choices.
Cache implementations decorate ConcurrentHashMap to add the desired features. The concurrent algorithms for caching and the hash table are individually complex. By keeping them separate, advancements in hash table design can easily be exploited and avoids coarsening locks to cover both the table and eviction concerns.
The cost of this approach is additional runtime overhead. Instead of wrapping the value to hold extra metadata, these fields could be inlined directly onto the table entries. The lack of encapsulation might provide fast paths through a single table operation rather than multiple map calls and short-lived object instances (e.g. lambdas).
The previous projects explored both approaches: the decorator style used by ConcurrentLinkedHashMap and forking the hash table by Guava. Not surprisingly, the motivations for forking rarely materialize due to the overwhelming engineering complexity of the resulting design.

