👨🏻💻 김동규 (조장)
분석 및 설계(UML), 인프라 구축 및 관리, 설계 및 DB 스키마 정의, 서버 구현
👩🏻💻 김은수
데이터 수집, 머신러닝/딥러닝 모델 구축
👩🏻💻 박진아
UI디자인, android
👩🏻💻 조윤서
UI디자인, android
각자의 파트를 나눠서 진행하기는 하지만 나머지 팀원이 함께 리뷰하고 맞춰가며 최종 완료하는 방식으로 프로젝트를 진행합니다. 또한 소프트웨어개론 수업에서 배운 것처럼 프로젝트 진행 시(소프트웨어 개발시) 문서화 작업 또한 개발의 일부이고 중요하다고 판단하였기 때문에 최대한 모든 회의 내용 및 구현 진행 내용등을 기록하고 문서화하려고 노력하였습니다.
-
1년 전체적인 개발 일정입니다. (세부적인 사항은 당연하게 변동될 수 있습니다.)
-
매주 개인의 진행상황을 서로 이야기하고 방향성을 맞추는 회의를 진행합니다.
**(매주 토요일 마다 카페에 모여 약 4시간 정도 함께 개발하고 회의를 진행합니다.)** -
애자일 프로세스와 같이 “점직적”이고 “반복적”으로 개발해 나갈 수 있도록 노력합니다.
-
아래 개발 일정 계획 시 빠진 부분으로는 EC2, S3, RDS와 같은
**인프라 구축**부분이 있는데 해당 부분은 9, 10월 초까지 진행되었습니다. -
현재(2021.12.1) 스토어 등록을 제외한 모든 부분에서 구현 및 배포가 완료된 상태입니다.

저희 프로젝트 이름에 해당하는 Petalk은 Pet과 talk가 합쳐진 단어로 반려동물이 반려인과 소통한다는 의미에서 지어졌습니다. 저희 프로젝트는 코로나와 1인 가구 증가로 인해 반려동물을 키우는 사례가 늘어남에 발맞추어 반려인과 반려동물의 라이프 플랫폼을 고려하였습니다.
-
프로젝트 제안 배경
→ 1인 가정이 많아지면서 반려동물을 키우는 가정이 많아지는 추세이므로 애완동물과 관련된 프로젝트를 진행하면 개발의 지속적인 동기부여뿐 아니라 사용자에게도 도움이 되는 서비스를 제공할 수 있을 것이라고 생각되었다.
→ 애완동물을 키워 본 사람이라면 누구나 한 번쯤은 소통의 어려움으로 인해 어려움을 겪은 경험이 있다.
→ 여러가지 동영상, 사진 등의 데이터를 통해서 음성 및 행동을 분석하여 애완동물의 감정을 표현하여주는 서비스를 제공한다면 앞서 언급한 어려움을 해결하는데 도움을 줄 수 있다.
→ 이러한 서비스는 웹을 통하여 제공하기 보다는 사용자의 손에 항상 쥐어져있는 앱을 통해서 서비스 하는 것이 접근성 및 활용성이 높다고 판단되기 때문에 모바일 어플로 서비스를 제공하기로 결정하였다.
-
프로젝트 제안 배경 및 필요성
애완동물을 키워 본 반려인이라면 누구나 한 번쯤은 소통의 어려움을 겪었을 것입니다.
이러한 점을 개선하기 위해서 저희 서비스에서는 동영상, 사진 등 멀티미디어 데이터를 통해서 음성 및 행동을 분석하여 애완동물의 감정을 표현해줌으로써 반려동물과의 유대감을 높이는 서비스를 기획하였습니다. 현재는 동물의 울음소리를 동영상으로 촬영하면 울음소리를 머신러닝 기술로 분석하고 현재 동물의 감정이 어떠한지는 7가지 class의 감정으로 세분화시켜 분류하여 줍니다. 이를 통해 사용자는 현재 동물의 감정이 어떠한지를 파악할 수 있게 됩니다. 또한 반려인들의 소통공간이 부족하다고 생각하였고, 커뮤니티 기능을 함께 제공하여 반려인들의 정보교환 및 소통의 장을 마련할 수 있도록 하였습니다.
-
기대 효과
-
기대효과(사용자)
→ 고양이의 말을 번역하여
**반려동물과의 소통을 통해 서로의 유대감**을 높인다.→ 초보인 주인이 **
반려동물의 기분이나 니즈를 파악**하도록 도움을 받는다.→ 반려동물 뿐 아니라 말을 잘 하지 못하는 어린아이의 의사나 사람이 말을 할 때 표정과 포즈를 분석하여 그들이 진짜로 전달하고자 하는 것을 파악하는 분야로
확장이 가능하다. -
기대효과(개발자)
→ 머신러닝을 이용해 반려동물의 포즈와 음성을 분석하여 그들이 전달하고자 하는 의미를 해석할 수 있다.
→ **React-Native, Tensorflow, Spring과 같은
다양항 기술 스택**을 익힐 수 있을 뿐 아니라 이들을 어떻게 연동하여 상호작용할지에 대해서도 많은 공부가 될 것이고 분명 큰 도움이 될 것이라고 기대된다.→ 단순히 정수 및 문자열 데이터 뿐 아니라 동영상과 같은 멀티미디어 데이터를 다룬다는 점 또한 좋은 경험이 될 것이다.
→ 기본적인 웹, 앱 어플리케이션의 동작 과정에 대해서 이해할 수 있다.
→ 뿐만 아니라 서버에 배포를 진행함으로써 Cloud Computing에 대한 경험 및 CI/CD, REST API를 통한 서로 다른 컴퓨터(host) 의 프로세스 간의 통신 경험은 많은 성장을 이끌어 낼 것이라고 기대됩니다.
→ 마지막으로 동영상과 같은 멀티미디어 데이터를 처리하기 때문에 어떻게 좀 더 효율적으로 처리할지 여러 아키텍쳐의 구성을 고민해볼 수 있다.
-
저희는 프로젝트를 통해서 앞서 언급한 필요성에 의해 사용자에게 기대효과에서 언급한 내용을 서비스하는 것이 프로젝트의 목적이기도 하지만
학생 입장에서 이번 졸업작품을 진행하면서 학교를 다니며 배웠던 전공 과목 및 지식들을 최대한 많이 활용하여 실제 카카오, 우아한 형제들과 같이 자사 서비스를 제공하는 회사에서 운영하는 것과 같은 서비스를 설계 및 구현해보는 것이 또 하나의 프로젝트 목표였습니다.
저희가 이번 프로젝트에서 활용한 전공 지식 및 교과목의 연결은 다음과 같습니다.
-
컴퓨터공학 프로그래밍 1,2 → 기본적인 코딩에 대한 지식
-
소프트웨어공학 → UML 등의 배운 내용을 프로젝트의 분석 및 설계 단계에서 적극 활용 및 Agile 바탕으로 '점진적이고 반복적으로 구현', 백엔드 개발 시 SOLID 고려하며 구현
또한 maven을 공부함으로써 프로젝트 관리 도구에 대해서 배울 수 있었으며 해당 프러젝트에서는 Gradle 활용
-
자바 프로그래밍 1, 2 → Spring의 바탕이 되는 Java에 대한 지식을 활용
-
문제해결을 위한 자바활용 → JSP를 학습하며 웹 서버 구현을 경험 (서버-클라이언트 흐름 익힘)
-
Design pattern → 스프링에서 strategy패턴을 이용해 의존성 주입을 하는 등 디자인 패턴 수업에서 배운 내용을 바탕으로 스프링을 공부하고 활용
-
데이터베이스 → 기본적인 데이터베이스 지식을 활용하여 DB 설계 및 구축
JPA 사용하여 패러다임 불일치 해결
-
오픈소스SW기여 → Jenkins, Docker, Git, Gradle 학습하고 이를 활용
-
클라우드 컴퓨팅 → 클라우드에 대한 개념을 바탕으로 EC2와 같은 IaaS를 활용하여 인프라 구축
-
OS/NW 실습, 분산처리 → Server & Client 아키텍쳐에서의 통신, 여러 Host(서버들)간의 연동
-
자료구조, 알고리즘 → 모든 비즈니스 로직에 바탕이 됨
-
웹 프로그래밍 → React-Native를 활용하는데 필요한 기본 지식을 익힘. 뿐만아니라 세션, 쿠키, 토큰 등의 개념 익히고 이를 활용
-
시스템 프로그래밍 & 운영체제 → 리눅스 환경에서 서버를 구축하는 데 필요한 기본 지식 및 명령어 활용
-
컴퓨터 네트워크 → HTTP 웹 기본 지식(HTTP method)을 바탕으로 REST API 사용
-
패턴인식, 인공지능, 인공지능개론 → 인공지능과 기계학습에 대한 전반적인 내용과 수학적 기반, 최근 동향에 대해서 배움
-
데이터마이닝, 빅데이터처리, 빅데이터처리개론 → 데이터의 종류와 빅데이터를 알맞게 처리, 가공하는 방법에 대해 배움
-
딥러닝/클라우드, 영상정보처리 → OpenCV를 이용하여 영상 정보를 처리하는 방법과 처리한 데이터를 다양한 CNN 딥러닝 모델에 적용하는 방법을 배움
-
기능 개요(개념도)
→
**UseCase Diagram**(전체적인 개요이기 때문에 간단하게 나타내어 다음과 같지만 예를 들어 회원가입과 로그인의 경우에 OAuth 2.0을 적용하여 JWT토큰을 사용하는 등 실제로는 보다 복잡합니다.)
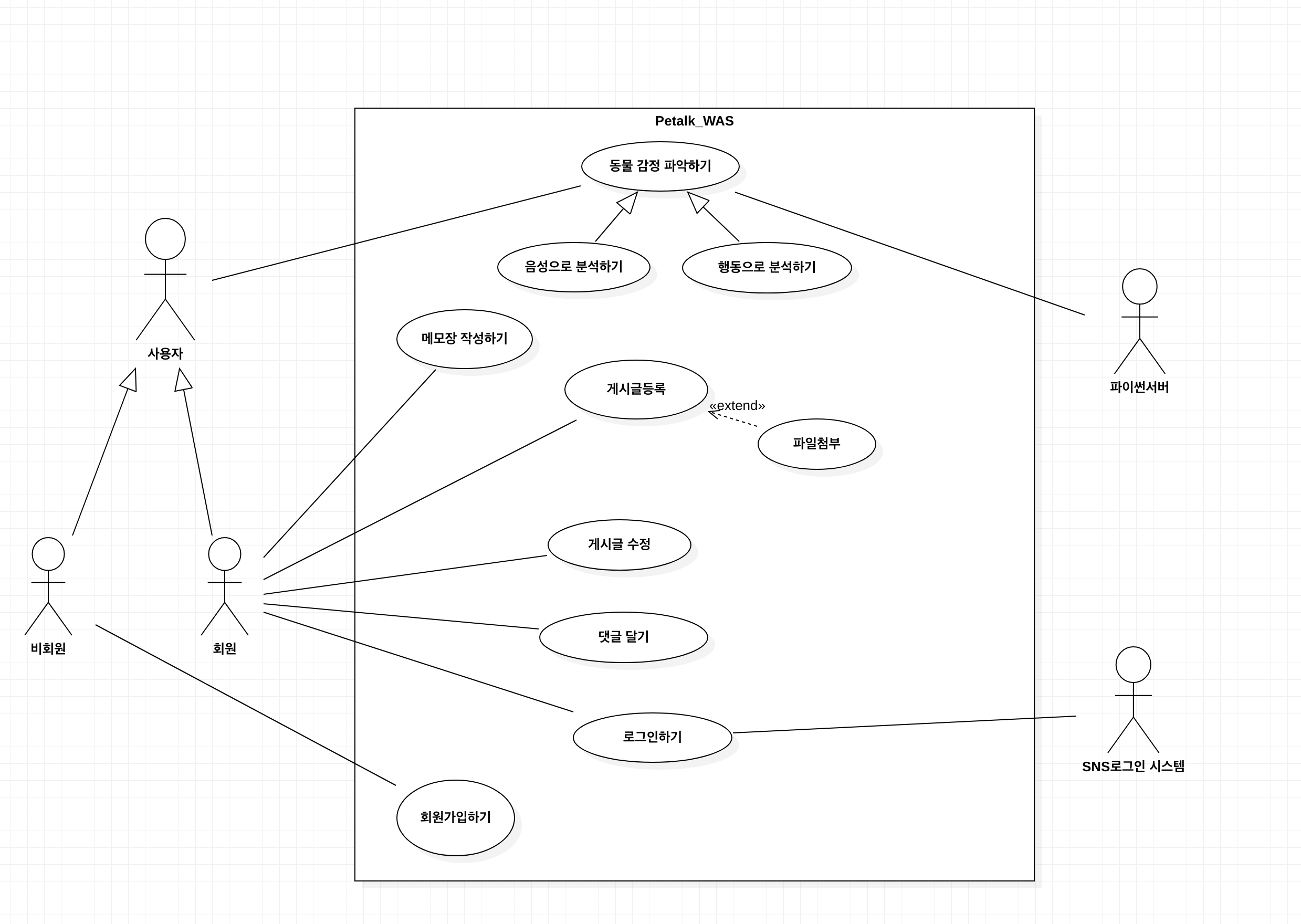
→
Class Diagram-
이전 분석 단계에서 작성하였던 유스케이스 다이어그램을 바탕으로 클래스 다이어그램을 작성하며 설계를 진행해보았습니다.
-
DTO(Data Transfer Object)(순수 데이터 객체)에 해당하는 클래스들 위주로 작성하였습니다.
→ DB의 테이블과 1대1 매핑되는 "@Entity" 객체들에는 DB에서 더욱 원활하게 데이터를 관리하기 위해서 실제 서버(Spring)단에는 BaseEntity(엔티티 생성 시 생성 날짜, 수정시 마지막 수정 날짜를 위해서)를 상속하는 등 실제로 가지는 필드는 더 많거나 적습니다.
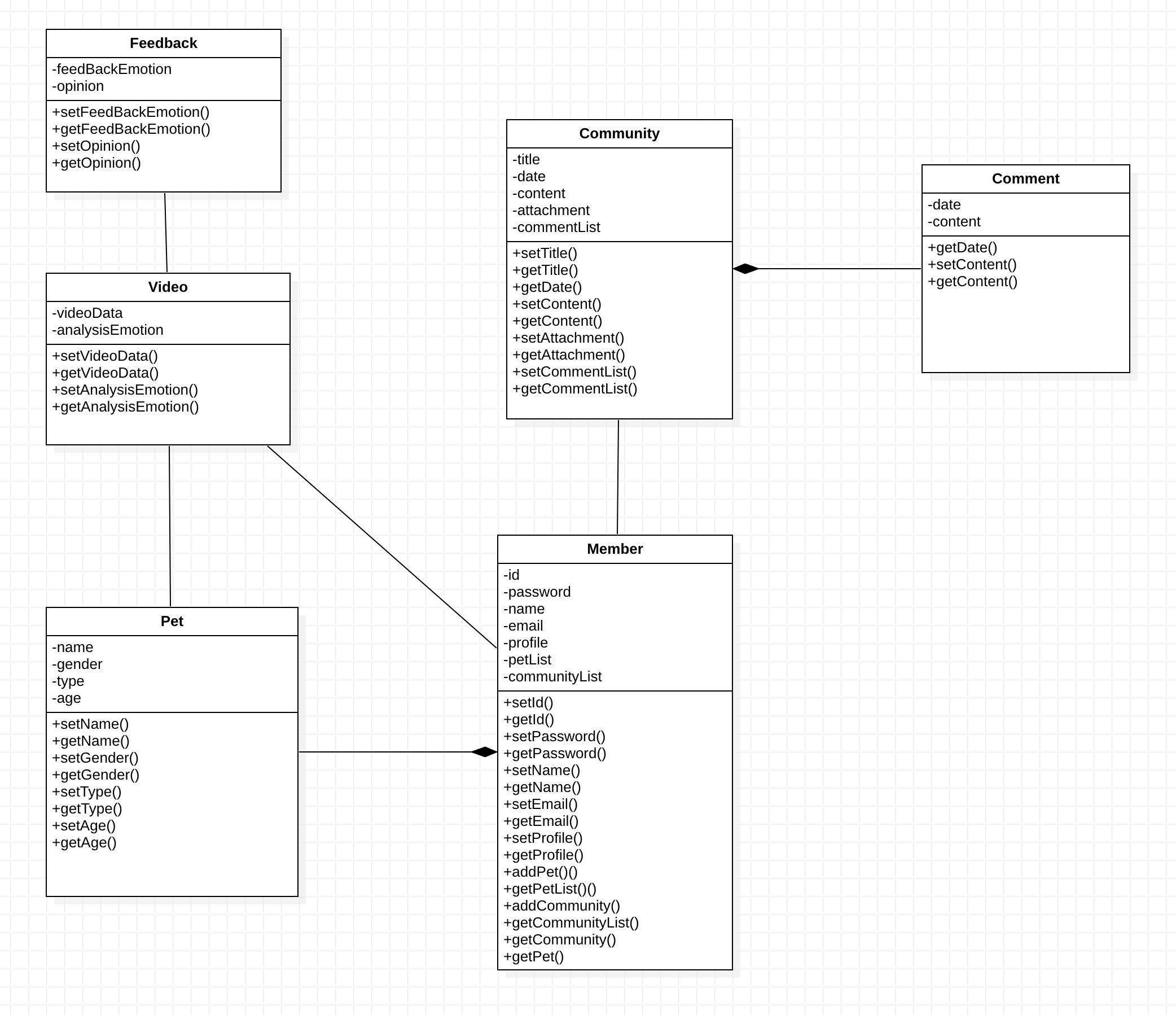
→
**BaseEntity.java**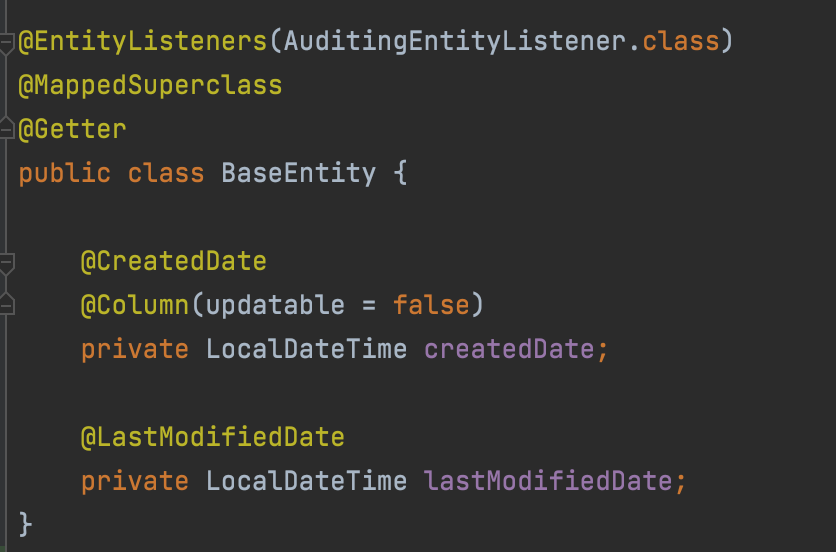
→
**도메인 모델과 테이블 설계**-
(초기) 분석 단계에서 테이블 사이의 연관관계만을 고려하여 테이블을 설계하였던 모습
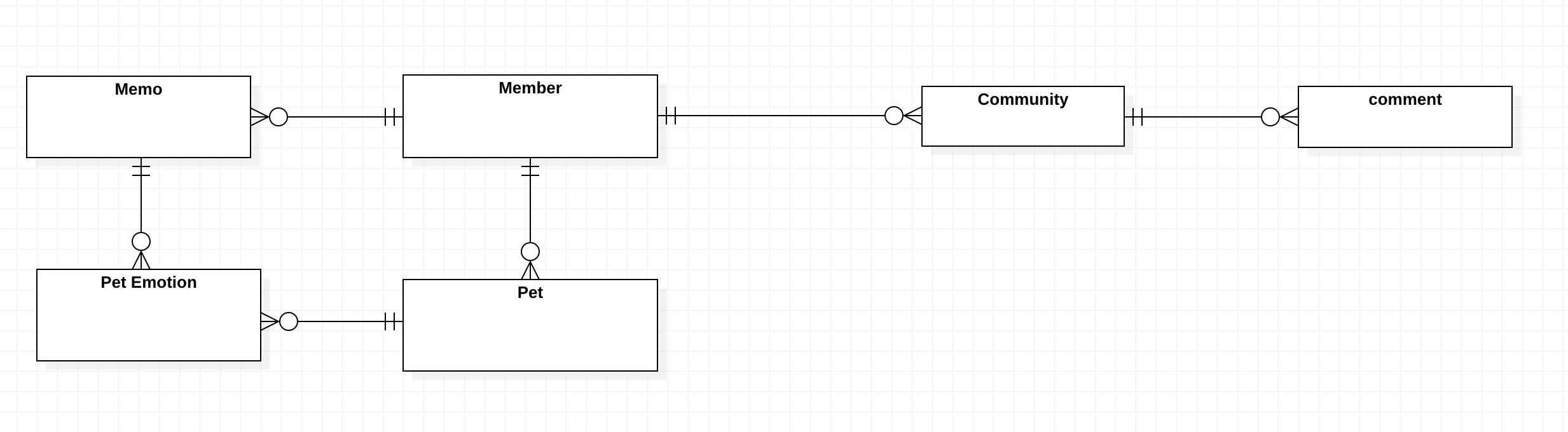
-
이후 분석 → 설계 (분석 이후 설계 단계)에서는 다음과 같이 테이블의 컬럼까지 구체적으로 설계하였다.
-
분석한
감정과 사용자가 메모장에 입력한감정을 비교하여 향후에 모델 업데이트에 사용할 수 있도록 영상 테이블과 메모장 테이블 사이에 관계를 추가해주었다.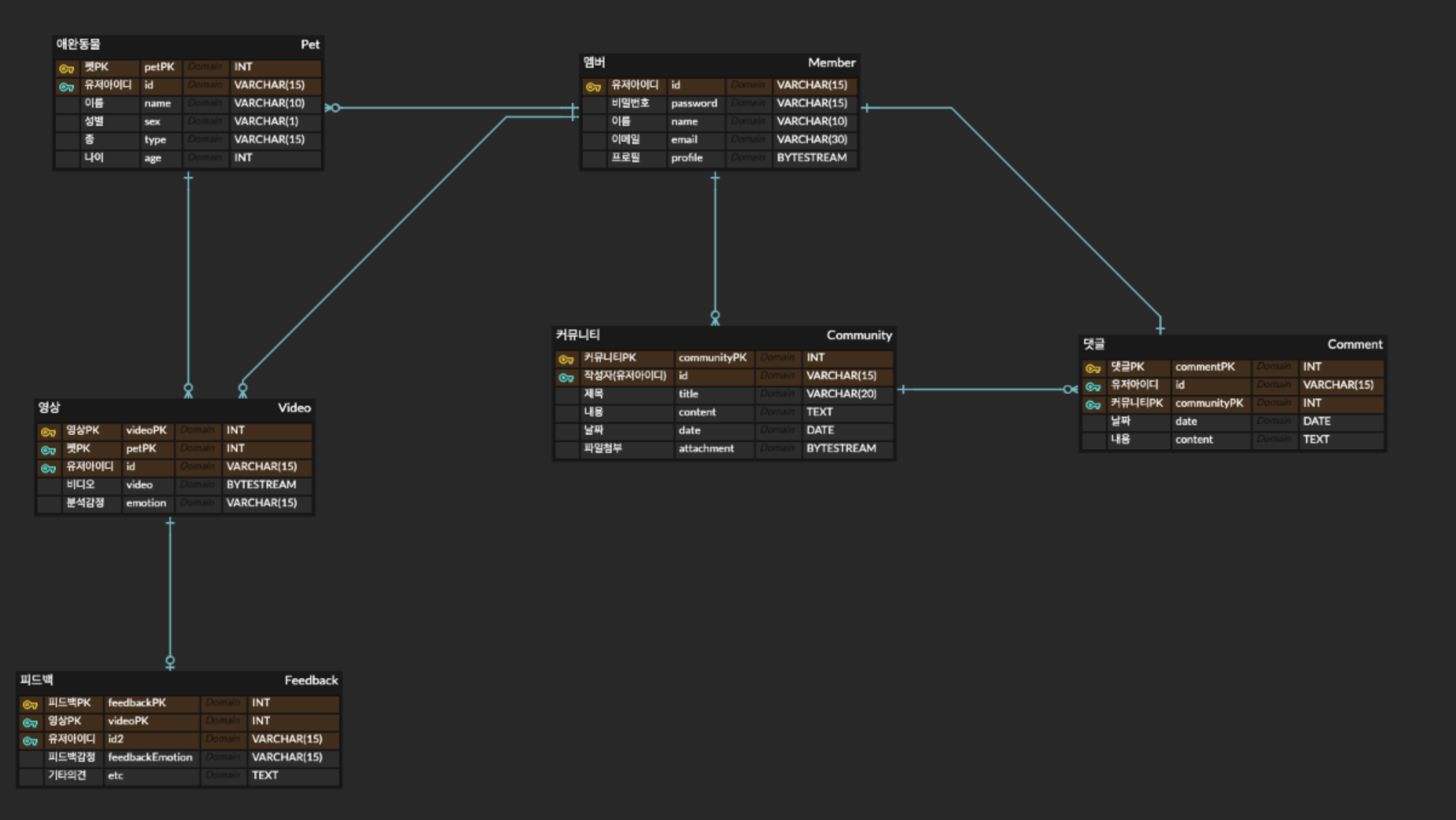
-
위의 E-R Diagram은
개발 중간 단계에서의 모습이고 향후에 개발을 진행하면서수정을 하고 (ex. 각 테이블의 각각의 row에 대하여 created_date와 last_modified_date 를 반영하도록 해당 컬림들추가← 서버 운영 단계에서 매우 유용하기 때문에 추가), 불필요하다고 생각되는 기능들이나 컬럼에 대해서삭제하여 업데이트 된 모습입니다. -
현재(2021.12.1) 실제
AWS RDS에 올라가 있는 DB 테이블의 모습입니다.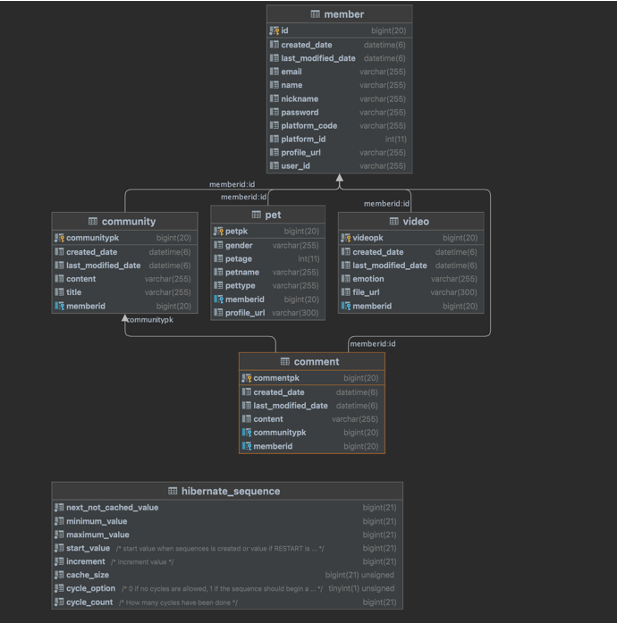
-
-
-
컴포넌트별 기능 명세
→ 회원가입/로그인
-
어플의 커뮤니티, 메모장 기능을 사용하려면 메일, 반려동물 종류와 이름, 사진 등 기본적인 정보를 통해 화원가입을 진행하고, 로그인 하여야한다.
-
사용자는 카카오톡 로그인 API를 통해서 우리 어플의 회원가입을 진행하지 않고 카카오 아이디를 통해서도 로그인하여 서비스를 이용할 수 있다.
-
사용자는 또한 로그인 이후 자신의 반려동물을 등록할 수 있다.
→ 애완동물 번역 기능(핵심 기능)
- 학습시킨 머신러닝 모델을 이용하여 애완동물의 소리와 동작(행동)을 분석한다.
-학습된 모델을 토대로 사용자가 갤러리에서 영상을 선택하거나 영상을 찍어 업로드하면 애완동물의 현재의 기분이나 무슨 말을 하고 싶은지 분석하여, 분석된 내용을 영상과 자막으로 표현하여 제공한다.
예) 고양이 음성이 담긴 영상 업로드: 골골거리는 소리(purring) ⇒ 편안하고 심신안정된 상태(머신러닝 모델이 학습된 내용을 토대로 파악) ⇒ 주인님 기분 좋아요😻 (메모장 페이지 통해서 정보 제공)
- 결과는 메모장에 연동되어 자동으로 업로드된다.
→ 커뮤니티
-
애완동물을 키우는 사람들끼리 정보를 공유할 수 있는 게시판 기능을 제공한다.
-
다른 일반적인 게시판과 동일하게 작성자, 작성날짜, 게시글 내용등이 포함되게 된다. (파일 첨부 X)
→ 메모장
감정 분석 이후 반려동물의 기분 및 감정에 대한 내용을 달력형식의 메모장 기능을 통해서 제공한다.
(
front 영상 업로드 → 백엔드에서 ML로 전달 및 DB 저장 → 분석 이후 DB 내용 업데이트까지의 과정을 동기적으로 처리하는 것 보다는 비동기적으로 처리하도록 해서 사용자가 메모 페이지에서 확인하는 것이 보다 바람직한 설계라고판단되어 이렇게 별도의 메모장 페이지를 구현하도록 하였다.) -
-
크게 Front, WAS, Python Server로 나뉜다.
→ Front: React-Native (js)
React-Native는 "오픈소스 모바일 애플리케이션 프레임워크"로 JS로 개발이 가능하며 하나의 프로그래밍 언어로 IOS와 안드로이드 모바일 앱을 동시에 개발할 수 있는 크로스 플랫폼이라는 강점을 가지고 있습니다. 이외에도
Component기반으로 기능들을 분리해 재사용할 수 있는 구조여서 코드의 재사용과 생산성이 높다는 장점이 있습니다.→ Back: Spring Boot, Java, Apache Tomcat, JPA & Spring Data JPA
Spring은 IoC(제어의 역전), DI(의존성 주입)은 스프링의 가장 핵심이 되는 기술이며 스프링의 강점이다. IoC라는 특징을 이용하여 오브젝트 생성과 관계설정, 사용 및 제거 등의 작업을 독립된 컨테이너가 담당할 수 있다.(코드가 아닌 컨테이너가 오브젝트에 대한 제어권을 가지고 있다.→IoC) 또한 스프링은 DI를 통해서 객체를 직접 생성하지 않고 외부에서 생성한 후 주입하여 모듈 간의
결합도가 낮고 유연성이 높으며 변경이 용이한 시스템을 구성할 수 있다. 그리고 기존 EJB에서 살리지 못한 객체지향의 강점을 잘 살릴 수 있다.또한 자바 진영의
ORM(Object-Relation Mapping) 기술 표준인 JPA를 통해 순수 JDBC에 비해서 코드의 중복을 줄이고 생산성 높은 코드를 작성할 수 있으며객체와 릴레이션간의 패러다임 불일치를 해결하여 SQL에 의존적인 개발이 아닌 정교한 객체 모델링을 유지하게 도와준다. → 더 나아가 Spring Data JPA를 활용하여 보다 높은 생산성을 가지도록 할 수 있다.→ DB: MariaDB, 동영상 저장을 위해 AWS의 S3 버킷 사용 (EC2도 함께 할당받아 활용 & RDS를 활용하여 DB 설정 및 운영을 편리하게 함)
오라클이 MySQL개발사인 썬을 인수합병하면서 소스 공개를 비공개로 전환하고 기본적인 기능만을 갖춘 커뮤니티 버전만을 오픈소스로 제공하고 있기 때문에 MySQL의 개발자가 나와서 만든 mariaDB를 DBMS로 사용하기로 결정하였습니다. (MySQL과도 호환성을 갖고, MaraiDB의 경우 AWS RDS 서비스에서도 '프리티어' 등급이 존재하기 때문에 무료로 사용 가능하다.)
초기에 동영상을 직접 DB에 저장할 계획이었기 때문에 복잡한 쿼리가 가능한 PostgreSQL을 사용하려고 하였으나 현재 동영상은 모두 S3에서 관리하기 때문에 별도록 복잡한 쿼리나 높은 성능을 DB에서 보장할 필요가 없기 때문에 MariaDB를 채택하였습니다.
→ Machine Learning: Python(TensorFlow/Pytorch), Teachable Machine API
Keras, Caffe등 다양한 Deep Learning프레임워크와 비교하여 개발자들이 가장 많이 선호하고 사용되는 프레임워크이며, Google, Facebook에서 제작하였다. Theno보다 컴파일 속도가 빠르며, CPU나 GPU를 활용한 계산이 수월하여 데이터나 모델들의 병렬 처리에 적합하다는 장점이 있다.
-
PostreSQL vs MariaDB 분석 내용
→ 두 DBMS의 가장 큰 차이점은 PostreSQL은
멀티 프로세스 방식이며, MariaDB는멀티쓰레드 방식을 사용하고 있다는 것이다. 따라서 멀티 프로세스를 사용하는 PostgreSQL의 경우 복잡한 쿼리나 join처리 방식에서 더 뛰어난 성능을 보여준다.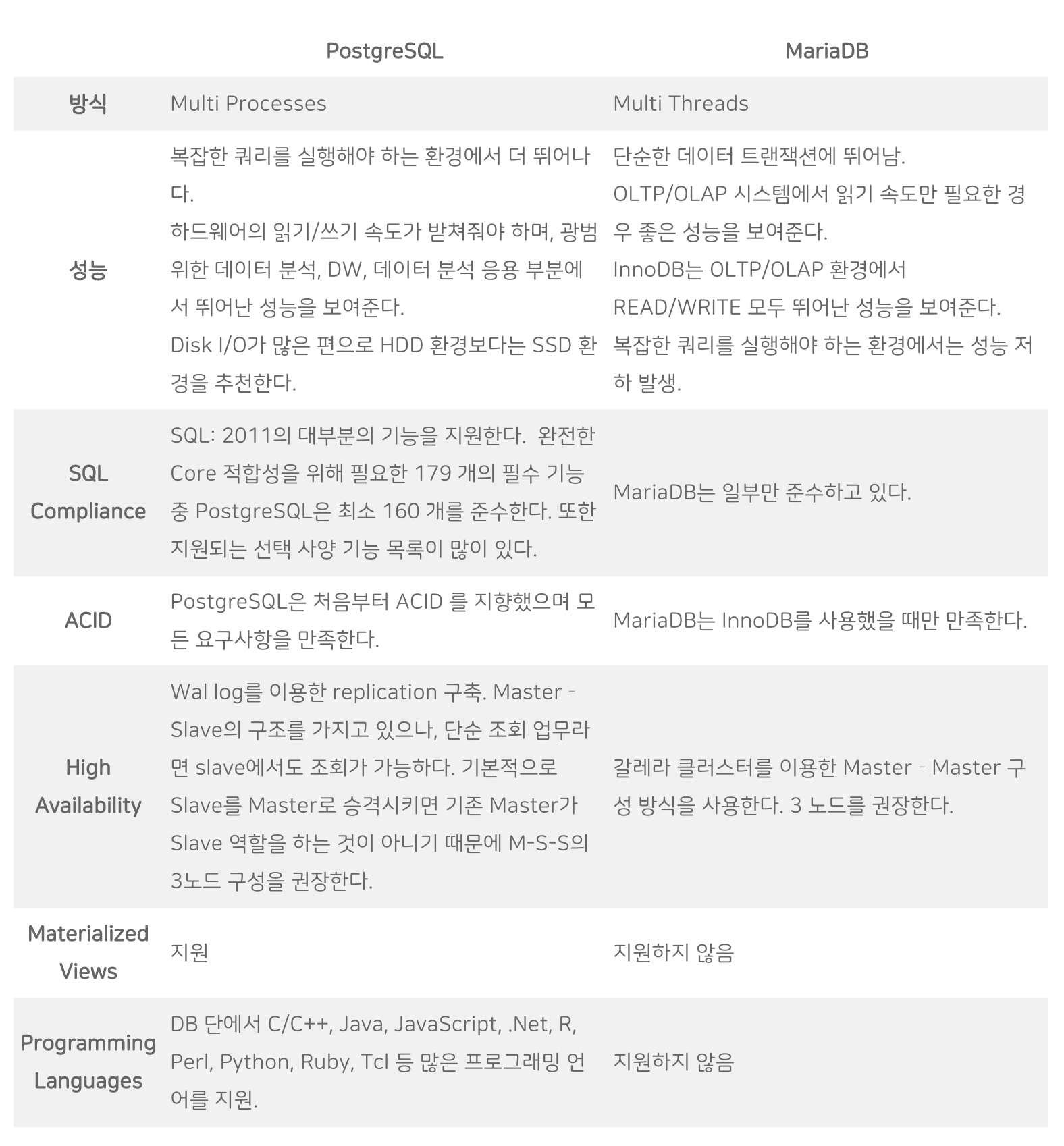
-
PostreSQL vs MySQL
→ MySQL
- top n개의 레코드를 가지고 오는 케이스에 특화
- update성능이 postgre보다 우수
- Nested Loop Join만 지원
- 복잡한 알고리즘은 지원 x (커뮤니티 버전)
- 간단한 처리 속도를 향상 시키는 것을 추구
→ PostgreSQL
-
다양한 join 방법 제공 (nested loop뿐 아니라 hash, sort merge)
-
update시 과거 row를 삭제하고 변경된 데이터를 가진 새로운 row를 추가하는 형태 (update 속도 느림)
-
처리 속도를 빠르게 하기 위해 여러 CPU를 활용하여 쿼리 실행
-
클러스터 백업 기능 제공
(클러스터: 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법)
→ 결론: 대규모 시스템은 아니지만, 동영상 처리가 핵심이라고 판단되므로 읽고 쓰는 속도가 중요하고 복잡한 쿼리가 사용될 것으로 예상되어 PostgreSQL을 초기 DBMS 로 선택하였지만 '
S3의 사용'과 'PostgreSQL은 RDS에서 프리티어 등급이 없어요금에 부담'이 된다는 점을 고려하여 MariaDB로 Migration(이주)하였습니다.
⚙ 전체 시스템 설계(시스템 구상도)
초기 시스템 구상도
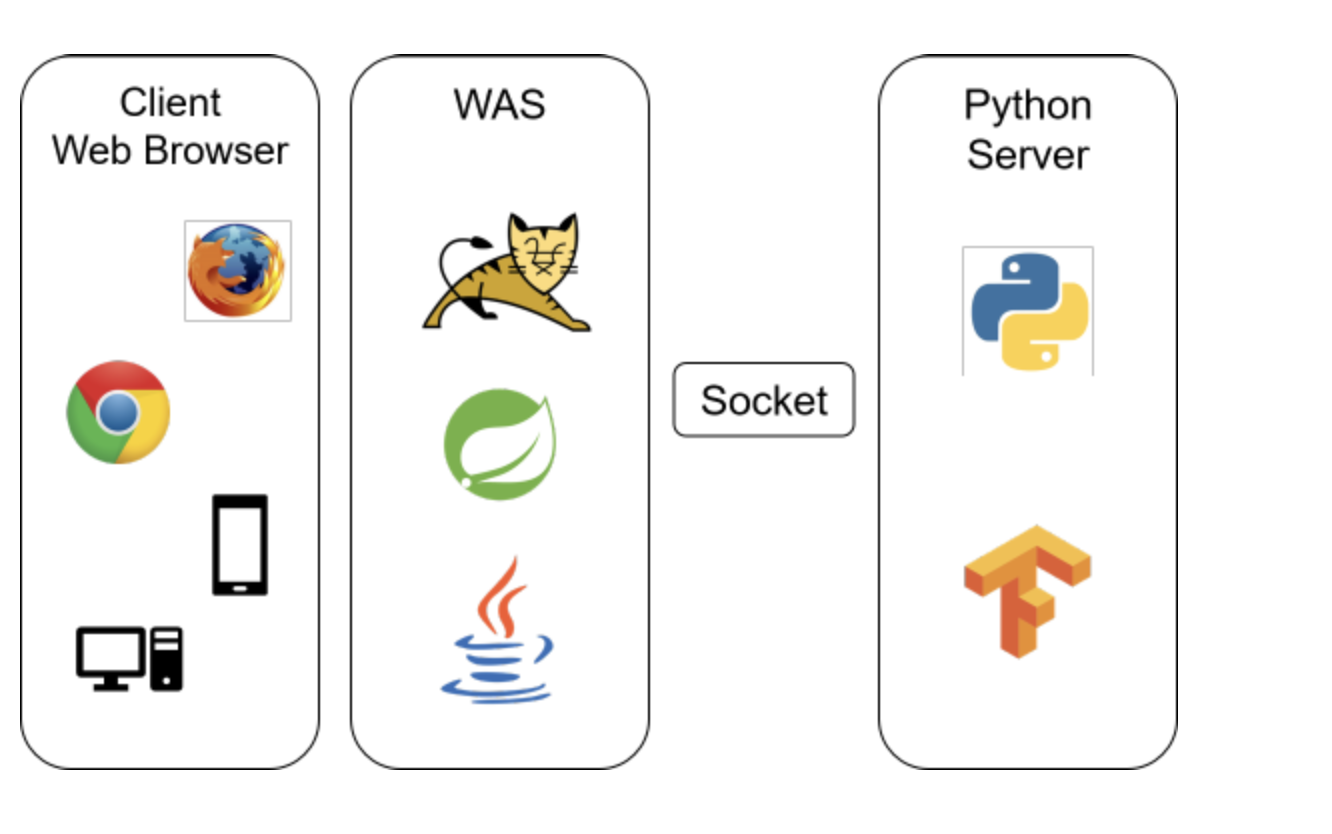
- 사용자가 front영역에서 영상을 업로드하거나 촬영하면 해당 영상 데이터가 WAS(Spring)에서 Python 서버(CPU 및 GPU 자원을 많이 소모하기 때문에 별도의 EC2 인스턴스로 구성)로 전송됩니다.
- Python서버에서 결과를 REST API를 통해 JSON 형식으로 반환하여주면 이를 WAS에서 받아 DB에 update 쿼리를 날립니다.
- WAS에서는 각종 비즈니스 로직을 처리합니다. (ex. front에서 요청된 비디오 처리(S3에 업로드 하고 관련 URL을 DB에 저장, 처리된 영상 결과물의 감정을 관련 row의 emotion 컬럼에 update 등)
- 최종적으로 WAS에서 front영역으로 데이터를 전송하여 사용자에게 결과가 전달된다.
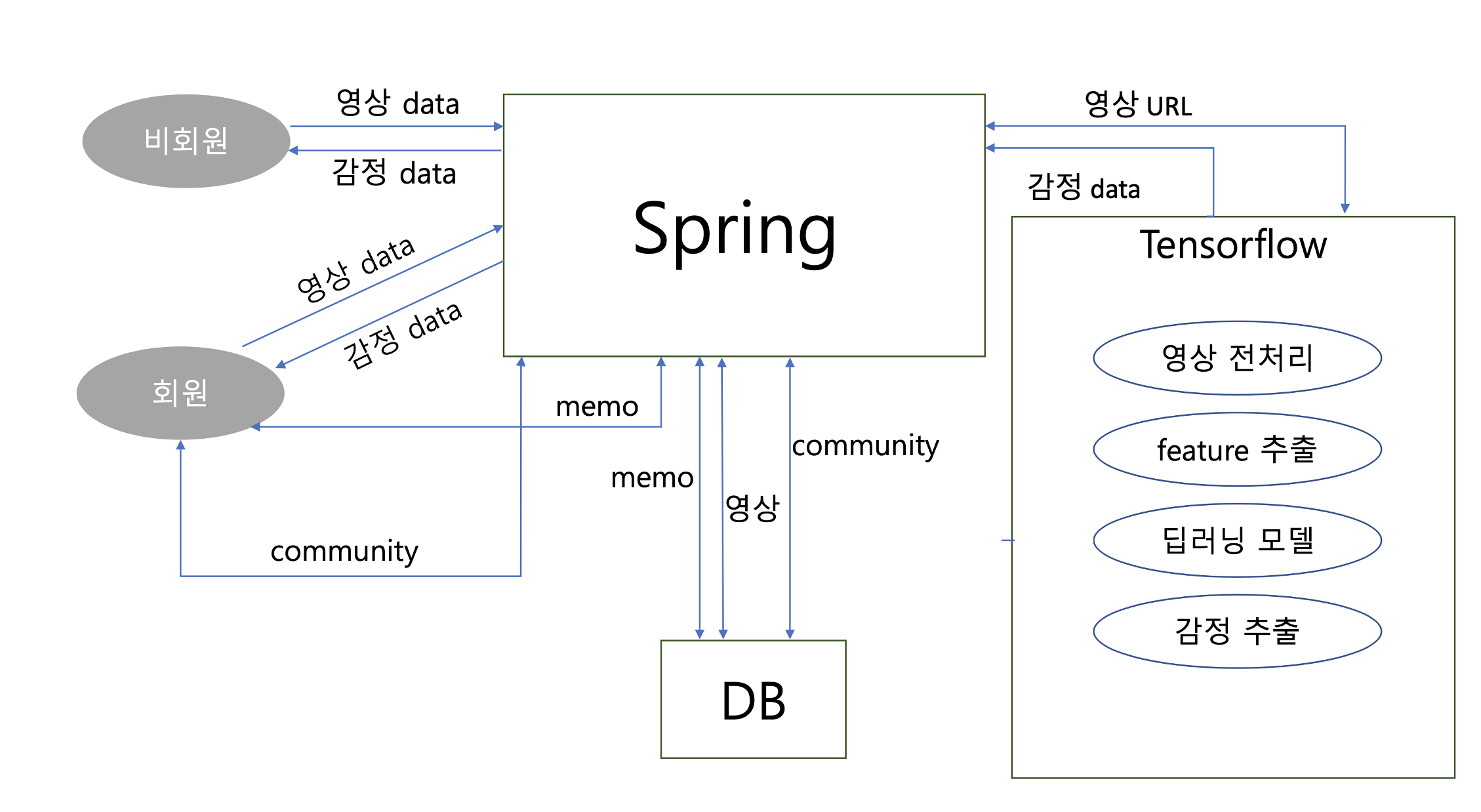
- 위 그림은 초기 개발 단계에서 작성한 시스템 구상도여서 영상 데이터를 직접 DB에 저장하는 것으로 보이고 있지만 이는 매 DB 조회시 부담이 크기 때문에 별도의 AWS S3 버킷에 Object형태로 영상 데이터를 저장하고 이에 대한 URL만을 DB에 저장하는 방식으로 구성됩니다.
- Tensorflow를 구동하는 서버에서는 자원소모가 많이 발생하기 때문에
DB 접근 및 사용자와의 상호작용은 모두Application Server에서담당합니다. 감정 분석 이후 감정 데이터(문자열 약 10글자 미만) 만을 update 쿼리를 통해서 DB에 업데이트해줍니다. - 크게 영상 데이터, 분석된 감정 데이터, 그리고 메모장 및 커뮤니티 데이터 등이 WAS와 상호작용하며 DB에 저장되고, 영상관련 데이터(File URL)는 Tensorflow로 넘겨져 처리됩니다.
- Tensorflow 서버에서 영상을 받으면 음성과 포즈 각각에 대하여 전처리하고, 영상에서 음성과 스켈레톤 feature를 추출하여 학습된 딥러닝 모델에 넣으면, 정해준 기준(class)에 따라 음성과 포즈 각각에 대하여 감정이 추출됩니다.
- 추출된 감정에 대한 결과를 REST API를 통해 WAS로 JSON형태로 전송해주며 WAS에서는 전달받은 감정 data를 관련 비디오에 update 해줍니다. → 이를 비동기적으로 회원은 자신이 업로드했던 비디오 목록(메모 페이지)에서 추가된 감정 데이터를 확인할 수 있습니다.
- 분석한 감정 결과는 S3에 저장되어 추후 모델 업데이트에 사용할 예정이며 이를 통해
**서비스를 계속해서 유지보수하고 업데이트**해나갈 예정입니다.
Docker & Jenkins를 이용한 CI/CD 부분은 미완성입니다.
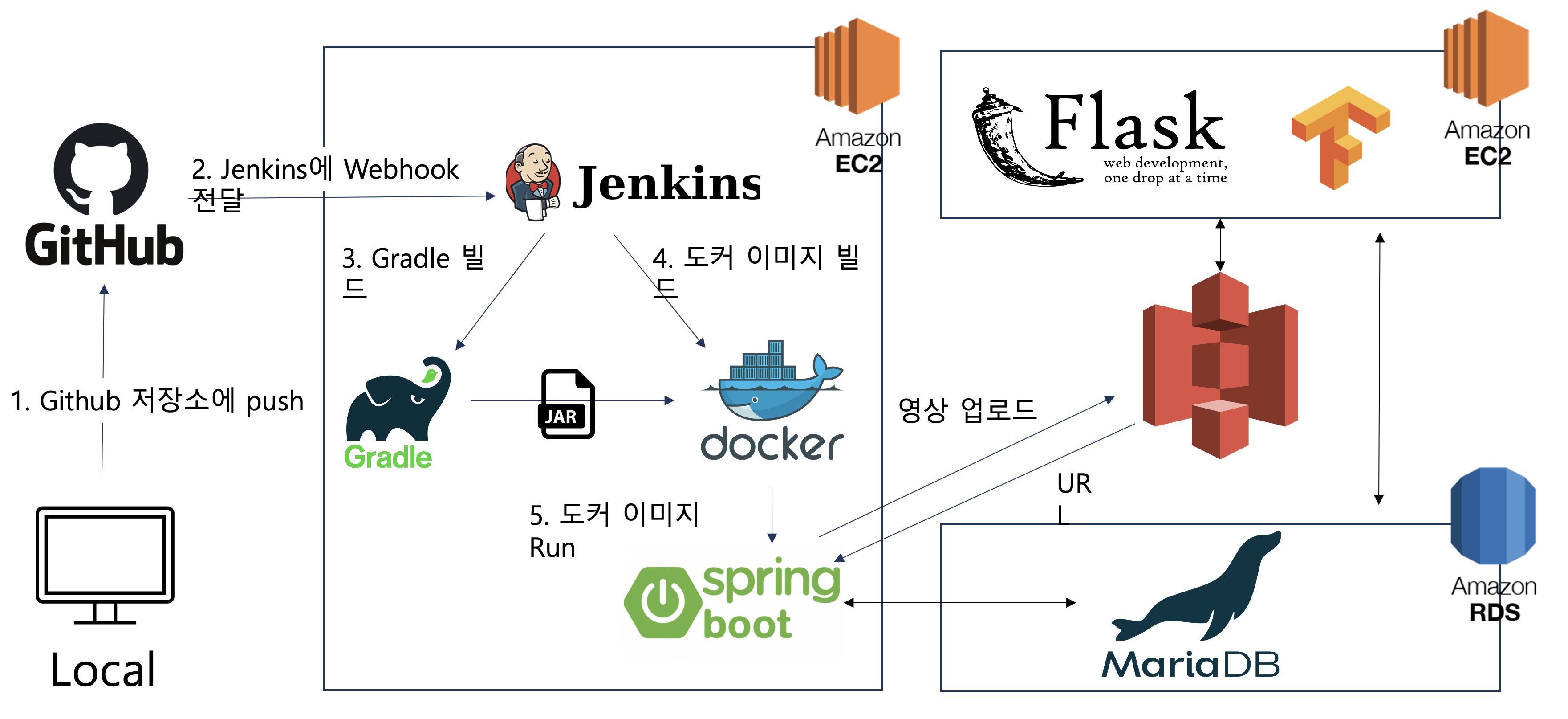
최종적으로 Front & Back & ML 연동을 통해서 성공적으로 어플리케이션 개발을 마무리 하였다. front에서 REST API에 따라 JSON 형식으로 데이터를 서버로 보내주면 서버는 이에 대한 비즈니스 로직을 처리해 응답 또한 JSON형식으로 프런트에 전달해줄 수 있다. 특히 동영상 업로드 및 감정 분석 기능의 경우 front에서 사용자 인증을 위한 JWT 토큰과 함께 MultipartFile 형식으로 영상을 업로드해주면 이를 S3에 올리고 그에 대한 URL을 받은 다음 이를 DB에 우선 저장한다. 이후 URL과 PK값을 ML서버쪽으로 전달하고, ML서버에서는 감정을 분석해 DB에 update쿼리를 날려주는 형식이다.
이 과정에서 우리는 기대효과에 해당하는 것과 같이 다양한 기술 스택을 익히고 또 연동하는 것 까지 경험해볼 수 있었을 뿐 아니라 웹과는 차이가 있는 앱의 동작과정, 그리고 실제 cloud에 배포함을 통해서 인프라 구축까지 앱 기획, 설계부터 개발 및 배포까지 전체 과정을 쭉 경험해볼 수 있었다.
이는 결과적으로 프로젝트 목표와도 같이 사용자에게 성공적으로 분석한 감정 정보를 전달해줄 수 있었으며, 앞서 언급한 것과 같이 3년~4년 동안 학교에서 배운 전공 지식들을 최대한 많이 활용해볼 수 있었다.
이후 해당 프로젝트를 계속해서 유지보수 한다면 앞서 보완사항에서 언급한 것과 같이 IaaS의 성능 업그레이드와 함께 쿼리 최적화를 진행하여 DB접근에 대한 부하를 줄여 더 많은 클라이언트 요구를 수용할 수 있도록 개선할 수 있을 것이며, 사용자 영상에 대해 현재는 비동기적인 처리밖에 못하지만 동기적인 처리를 해줄 수 잇도록 개선할 수 있을 것이다. 또한 동적쿼리를 이용한 게시글 검색등을 통해서 사용자 편의성을 높여줄 수 있으며 마지막으로 음성 뿐 아니라 행동에 대한 분석을 개선하여 보다 나은 감정 분석 서비스를 제공하고 또 고양이 뿐 아니라 강아지나 이외의 다른 반려동물에 대한 감정 분석도 수행해 줄 수 있을 것이다.