Improved syntax checking around line continuations #6420
Comments
|
/cc @jonas054 (I’m not sure who to mention here, but I know you’ve worked on many syntax cops in the past) |
|
"this text is #{foo} " \
'long' # StringLiterals prefers this
"this text is #{foo} " \
"long" # But as per your suggestion LineEndConcatenation should prefer this |
|
The idea was that this cop should take precedence over |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contribution and understanding! |
|
@bbatsov I would like to hear your opinion. Is strings continued over multiple lines within the responsibility of RuboCop, or should a separate tool (e.g. rubocop-strings) handle these niche cases? |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contribution and understanding! |
|
I’m still hopeful that someone with knowledge of Parser will comment on this issue. Maybe @whitequark would be the right person to ask? Or @pocke ? |
|
Each chunk of the literal is emitted as a separate node so you can just look at the line attribute. |
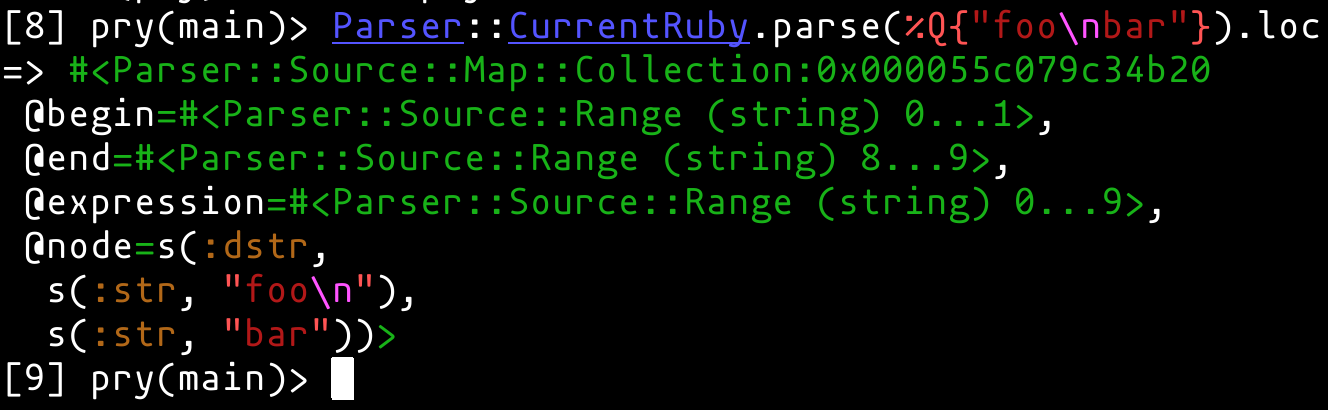
|
@bquorning The first aspect (one space between quote and In fact I was experimenting with extending Doing that I discovered a more general flaw in the cop that needs to be fixed first. |
|
Thank you for the response, @whitequark. But, your example shows a string containing a newline character. My question is regarding two strings that are “implicitly joined” (as two strings joined by whitespace would be, e.g. In the following example, I would like to find the position of the |
No; the location of |
@bquorning This is the approach I was playing with, basically analyzing the whitespace around line breaks with regexps: https://github.com/buehmann/rubocop/blob/32ccea042243ee0edf9d9f0dc426bf5baf5d604e/lib/rubocop/cop/layout/space_before_line_continuation.rb#L54-L61 |
|
@buehmann Interesting approach with the I was playing around with e.g. def on_dstr(node)
node_line_numbers = node.first_line..node.last_line
raw_lines = processed_source.raw_source.lines
node_line_numbers.each do |node_line_number|
raw_node_line = raw_lines[node_line_number - 1]
investigate(node, raw_node_line)
end
endand matching the line with
|
|
It works. The source buffer contains the backslashes, they just sit between tokens returned by Parser. |
|
Please note that https://bugs.ruby-lang.org/issues/6265#note-8 suggests the Ruby core developers are trying to remove this C-like String concatenation syntax in Ruby 3.0. |
|
Thanks @josb, I wasn’t aware of that ruby-core issue. But, reading the ticket I see that the syntax change was suggested 7 years ago, didn’t become a warning in Ruby 2.0, and 5 years ago it didn’t become a warning in Ruby 2.2. The last update (3 years ago) suggests to me that the syntax is still so heavily used in core Ruby that it won‘t be removed for a while yet. |
|
Granted. But it would be good if RuboCop would help people move in the right direction, no? Could even link to that ticket... |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contribution and understanding! |
|
This issues been automatically closed due to lack of activity. Feel free to re-open it if you ever come back to it. |
I have suggested some rules for consistent formatting of these strings in rubocop/rubocop#6420, but it seems to be too complicated to have RuboCop enforce them.
I have suggested some rules for consistent formatting of these strings in rubocop/rubocop#6420, but it seems to be too complicated to have RuboCop enforce them.
I have suggested some rules for consistent formatting of these strings in rubocop/rubocop#6420, but it seems to be too complicated to have RuboCop enforce them.
Style/LineEndConcatenationrecommends that we should use\instead of+or<<to concatenate strings across multiple lines. But I am still seeing wildly inconsistent formatting of these multiline strings. I would like to suggest RuboCop checking the following four aspects of formatting of multiline strings:\.1. One space between quote and
\2. Consistent indentation
Update: This is now handled by Layout/LineEndStringConcatenationIndentation.
Indent
IndentationWidthor match the preceding line’s starting quote.3. Use same quotes on all lines
Update: This is now handled by Style/StringLiterals when setting
ConsistentQuotesInMultiline: true.4. Keep whitespace at the end of lines
In the actual text, disallow spaces at the beginning of line n+1 if line n ends with a non-space.
The text was updated successfully, but these errors were encountered: