Home
📰 PyLaia 1.0 is here 📰
- 🔢 Distributed training (multi-GPU) is supported
- 🐍 Running scripts from Python is supported
- 💥 Experiments can be configured via yaml files
- 👨💻 Our most stable version yet, with dramatically improved test coverage
PyLaia is a toolkit specialized for handwritten text document analysis. More specifically, for Handwritten Text Recognition (HTR) and Keyword Spotting (KWS).
PyLaia is flexible, open-source, device-agnostic, and can be used to express a wide variety of experiments, including (but not limited to) training and inference over Convolutional and Recurrent based deep Neural Network models. The software is extensible and easily configurable and provides a rich set of functional layers with a particular focus on HTR.
It has been used for conducting research over several historic text databases. Additionally, it is one of the main engines used by the Transkribus project where thousands of handwritten and printed pages are transcribed every week by both individuals and organizations around the world. Tested in many languages: English, Spanish, Latin, Bengali, Hebrew, Arabic, Swedish, German, Italian, ...
For non-technical users or those who do not want to set-up the training/inference pipeline, PyLaia is available as a service at https://readcoop.eu/transkribus. Consulting and custom support tailored to your needs is also available through Transkriptorium.
Learn more about PyLaia by looking at the links in the sidebar!
There is a predecessor to PyLaia, simply named Laia. It was developed by 3 members (@jpuigcerver, @mauvilsa, @dmartinalbo) of the Pattern Recognition and Human Language Technology (PRHLT) research center in 2016.
The toolkit was originally built using Torch. Torch's development stopped around mid-2017, just as PyTorch started taking off. This gave us the motivation to build PyLaia as a second-generation system.
PyLaia was written in 2018 by @jpuigcerver to carry out his Ph.D. thesis experiments and @carmocca as his undergraduate final project.
PyLaia can transcribe line-level images of printed or handwritten text. Its input images are typically variable-sized, two-dimensional, and contain a segmented line of a scanned document (e.g. forms, historical manuscripts, newspapers, etc). PyLaia's output is a sequence of characters, the characters presumably present in the input images.
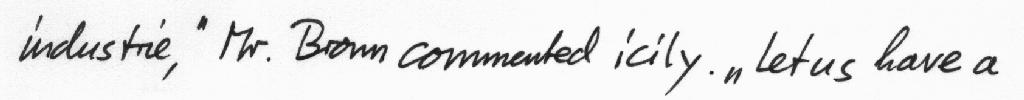
Don't worry, your images do not have to look this clean.
The input images must be annotated, meaning that there must be a ground-truth (aka reference) of the sequence of characters present in the image. The reference does not need to include the position of each character in the image, but their order must be preserved.
PyLaia does not pre-process the input images. Please use different software to standardize and remove artifacts from the input data.
If you found any errors, think something is confusing, or have ideas about how to improve this wiki, do not hesitate to open a GitHub Issue ❤️