A command-line tool and web app that extracts key terms from an Etsy shop’s listings.

- python 3.7 (anaconda3-2018.12)
- nodejs 10.15.3
- redis 3.2.0
- Flask
- React
- sklearn
- pytest
- enzyme
- Some exploratory artifacts are found in /artifacts.
- Front-end code is in /src
- Application logic is in /lib/services
- Web app logic is in /lib/web
- Python tests are in /tests and JavaScript tests are co-located with their implementation files.
Copy .env.example and source, adjusting as necessary and populating the value of
ETSY_API_KEY.
% cp .env.example .env % source .env
Issue the following to source data for analysis in the jupyter notebook in /artifacts.
python artifacts/save_listings_to_csv.py
# INFO:EtsyShop:[AgnesHart] Requesting active listings page: 1
# INFO:EtsyShop:[AgnesHart] Received page: 1 of 5
# INFO:EtsyShop:[AgnesHart] Requesting active listings page: 2
# INFO:EtsyShop:[AgnesHart] Requesting active listings page: 3To run the app locally, issue flask run from the project root.
- To minimize latency, the Etsy API query code makes requests in parallel
- The notion of a “meaningful term” is operationalized as “most commonly occurring semantically significant non-stop-words.” A naive approach using a simple count across the entire corpus was initially explored.
- The TF-IDF vectorizer down-weights words common across the entire corpus, but not explicitly excluded as stop words, highlighting the more “semantically significant” words in listing text documents. The vectorizer runs with acceptable performance on data of this size.
# lib/web/routes.py L51-73
@app.route('/key-terms', methods=['GET'])
def key_terms():
"""
Source listings and return meaningful terms for the given `shop_name`,
perform the analysis if necessary, returning cached values if available.
"""
shop_names = request.args.get('q')
if not shop_names:
resp = jsonify({'error': 'missing query string'})
return make_response(resp, 422)
results = []
for shop_name in shop_names.split(','):
result = perform_analysis(
shop_name,
logger=app.logger,
log_level=LOG_LEVEL,
etsy_api_key=ETSY_API_KEY,
max_number_of_terms=MAX_NUMBER_OF_TERMS,
redis_store=redis_store)
results.append(result)
return jsonify({'results': results})# lib/services/shop_listings_analysis.py L42-52
# source listings from the etsy api
shop = EtsyShop(
name=shop_name,
log_level=log_level,
api_key=etsy_api_key,
logger=logger,
).get_active_listings()
# determine key terms across the corpus of listing text
corpus = [f"{l['title']} {l['description']}" for l in shop.listings]
key_terms = compute_key_terms(corpus, number=max_number_of_terms)# lib/services/etsy_shop.py L54-79
def get_active_listings(self) -> 'EtsyShop':
"""
Query the Etsy API for this shop's active listings.
Side effect: Populates `self.listings`.
Return self.
"""
if self.listings:
return self
# Get first page of listings
request = self._initiate_request(page_num=1)
self._process_response(request, page_num=1)
if self.total_pages == 1:
return self
# Initialize parallel requests for subsequent pages
requests = {
page_num: self._initiate_request(page_num)
for page_num in range(2, self.total_pages + 1)
}
for page_num, request in requests.items():
self._process_response(request, page_num)
return self# lib/services/key_terms.py L18-38
def compute_key_terms(corpus: list, number: int = 5) -> tuple:
"""
Determine the NUMBER (default: 5) most meaningful terms from the provided
list CORPUS using a TF-IDF vectorizer.
"""
if not corpus:
return tuple()
vectorizer = TfidfVectorizer(
analyzer='word',
ngram_range=(1, 1),
min_df=0.1,
token_pattern=r'\b[a-z]{3,}\b',
max_features=number,
strip_accents='ascii',
lowercase=True,
stop_words=STOP_WORDS)
vectorizer.fit_transform(corpus)
return tuple(vectorizer.get_feature_names())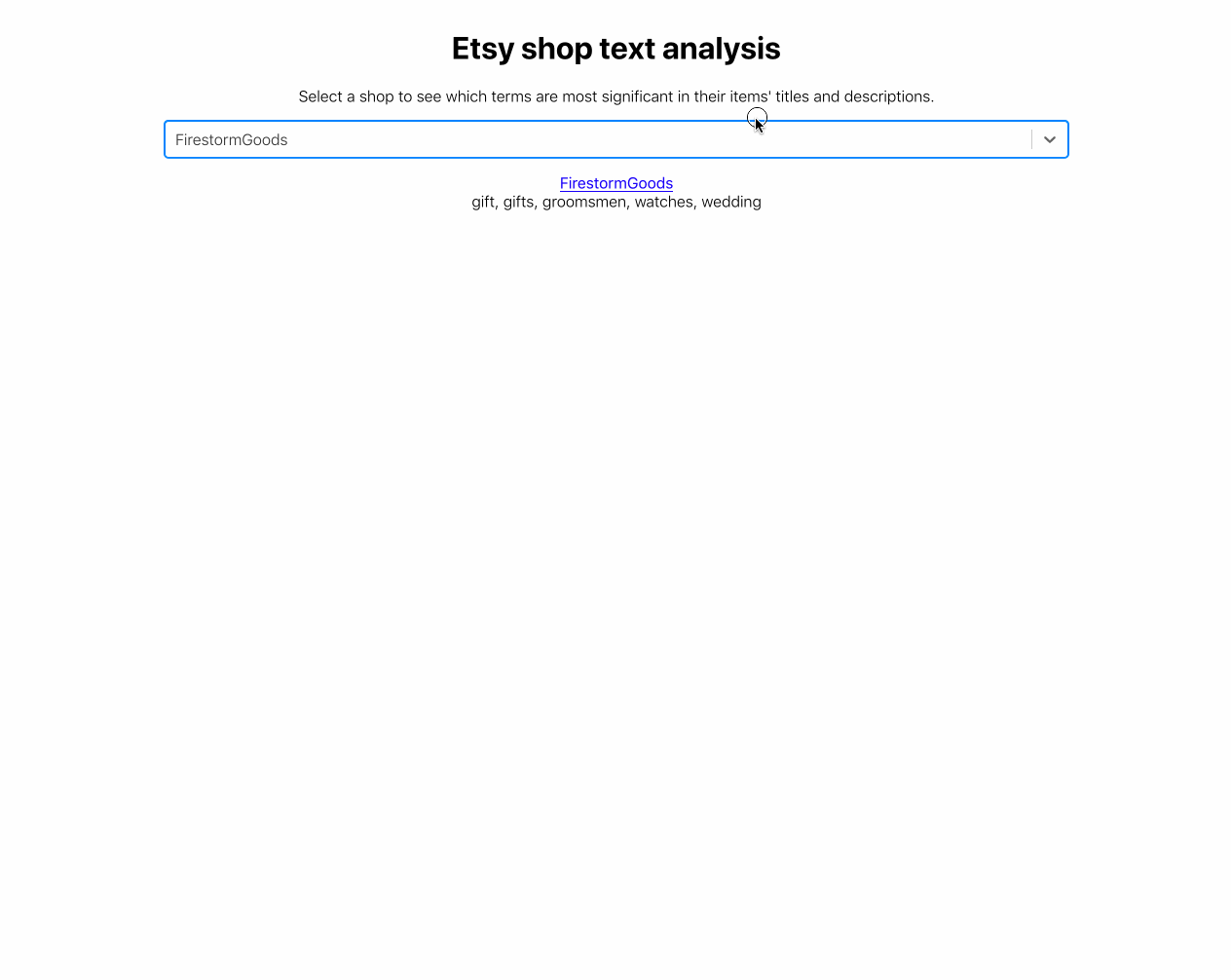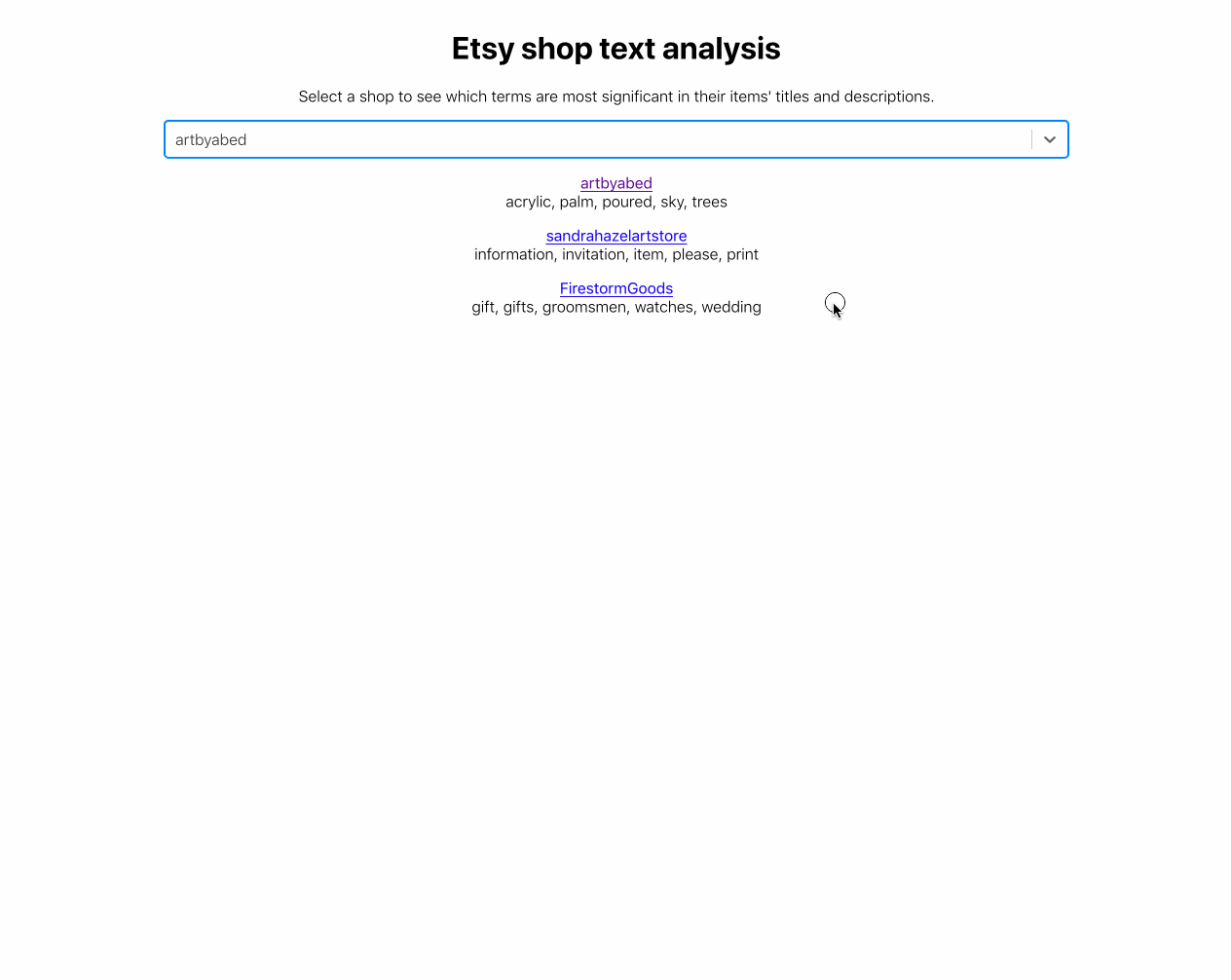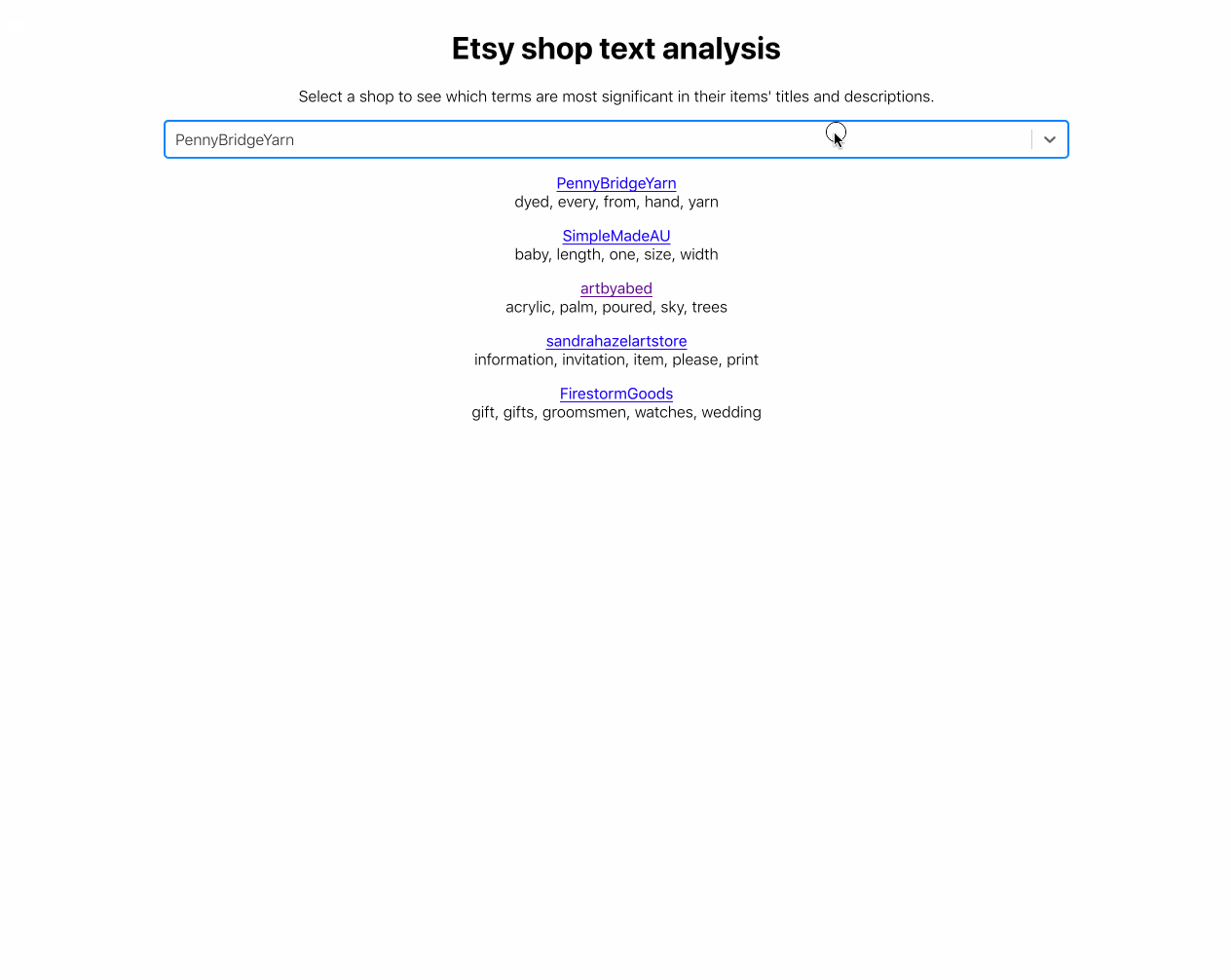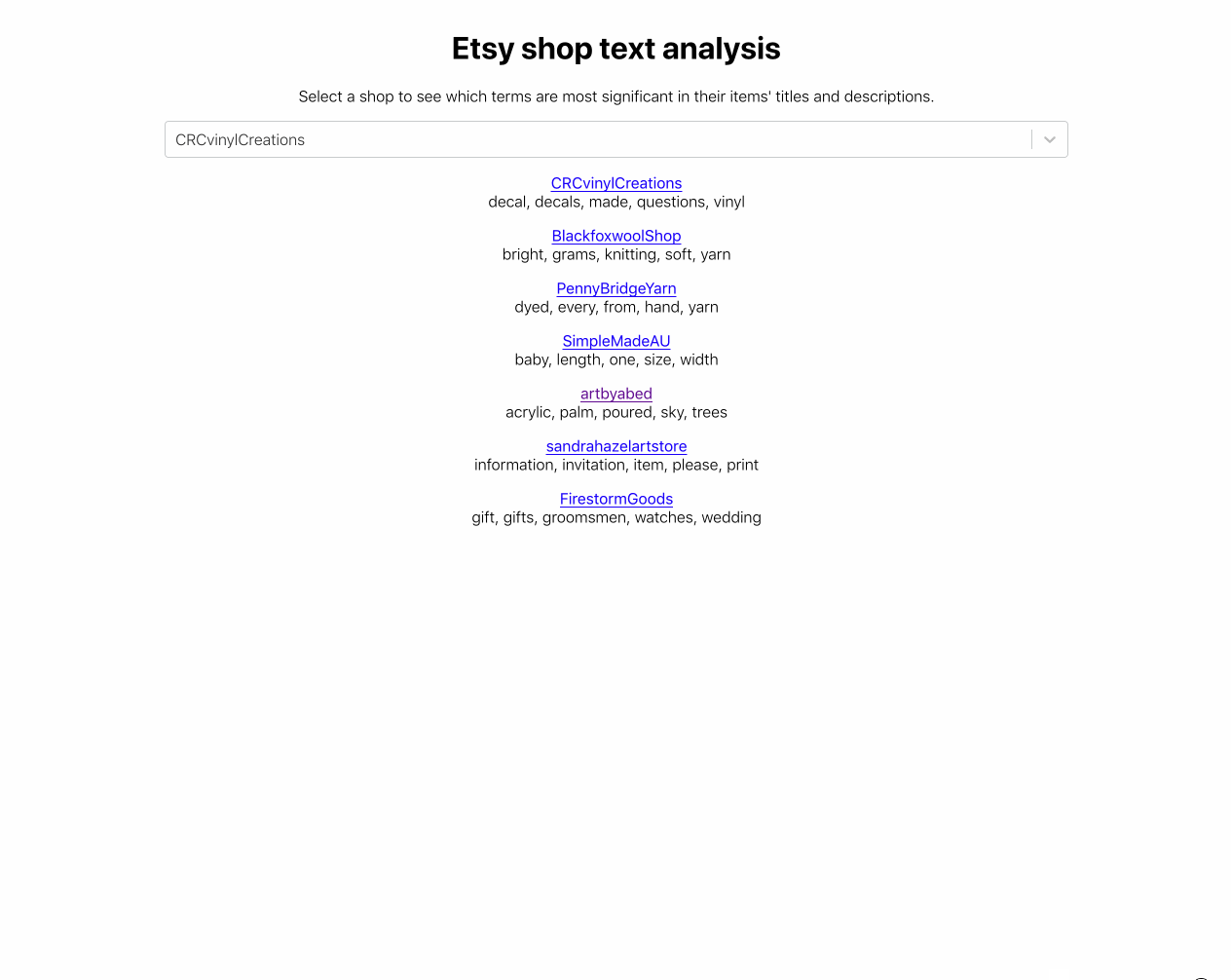
Some tasks punted on due to the timebox on this exercise:
- Augment the test suites (front- and back-end)
- Stem key terms so, for example, ‘game’ and ‘games’ are counted as the same term
- Re-implement the store name search to query the Etsy API by a search string
- Update result list styling to include the store’s avatar, description, other useful info
- Cache invalidation