C++ template library for high performance SIMD based sorting routines for
built-in integers and floats (16-bit, 32-bit and 64-bit data types) and custom
defined C++ objects. The sorting routines are accelerated using AVX-512/AVX2
when available. The library auto picks the best version depending on the
processor it is run on. If you are looking for the AVX-512 or AVX2 specific
implementations, please see
README file
under src/ directory. The following routines are currently supported:
template <typename T, typename Func>
void x86simdsort::object_qsort(T *arr, uint32_t arrsize, Func key_func)T is any user defined struct or class and arr is a pointer to the first
element in the array of objects of type T. Func is a lambda function that
computes the key value for each object which is the metric used to sort the
objects. Func needs to have the following signature:
[] (T obj) -> key_t { key_t key; /* compute key for obj */ return key; }Note that the return type of the key key_t needs to be one of the following
: [float, uint32_t, int32_t, double, uint64_t, int64_t]. object_qsort has a
space complexity of O(N). Specifically, it requires arrsize * sizeof(key_t) bytes to store a vector with all the keys and an additional
arrsize * sizeof(uint32_t) bytes to store the indexes of the object array.
For performance reasons, we support object_qsort only when the array size is
less than or equal to UINT32_MAX. An example usage of object_qsort is
provided in the examples
section. Refer to section to get a sense of
how fast this is relative to std::sort.
void x86simdsort::qsort(T* arr, size_t size, bool hasnan, bool descending);
void x86simdsort::qselect(T* arr, size_t k, size_t size, bool hasnan, bool descending);
void x86simdsort::partial_qsort(T* arr, size_t k, size_t size, bool hasnan, bool descending);Supported datatypes: T [_Float16, uint16_t, int16_t, float, uint32_t, int32_t, double, uint64_t, int64_t]
void x86simdsort::keyvalue_qsort(T1* key, T2* val, size_t size, bool hasnan);Supported datatypes: T1, T2 [float, uint32_t, int32_t, double, uint64_t, int64_t] Note that keyvalue sort is not yet supported for 16-bit
data types.
std::vector<size_t> arg = x86simdsort::argsort(T* arr, size_t size, bool hasnan, bool descending);
std::vector<size_t> arg = x86simdsort::argselect(T* arr, size_t k, size_t size, bool hasnan);Supported datatypes: T [_Float16, uint16_t, int16_t, float, uint32_t, int32_t, double, uint64_t, int64_t]
meson is the used build system. Command to build and install the library:
meson setup --buildtype release builddir && cd builddir
meson compile
sudo meson install
Once installed, you can use pkg-config --cflags --libs x86simdsortcpp to
populate the right cflags and ldflags to compile and link your C++ program.
This repository also contains a test suite and benchmarking suite which are
written using googletest and google
benchmark frameworks respectively. You
can configure meson to build them both by using -Dbuild_tests=true and
-Dbuild_benchmarks=true.
#include "x86simdsort.h"
int main() {
std::vector<float> arr{1000};
x86simdsort::qsort(arr.data(), 1000, true);
return 0;
}#include "x86simdsort.h"
#include <cmath>
struct Point {
double x, y, z;
};
int main() {
std::vector<Point> arr{1000};
// Sort an array of Points by its x value:
x86simdsort::object_qsort(arr.data(), 1000, [](Point p) { return p.x; });
// Sort an array of Points by its distance from origin:
x86simdsort::object_qsort(arr.data(), 1000, [](Point p) {
return sqrt(p.x*p.x+p.y*p.y+p.z*p.z);
});
return 0;
}x86simdsort::qsortis equivalent toqsortin C orstd::sortin C++.x86simdsort::qselectis equivalent tostd::nth_elementin C++ ornp.partitionin NumPy.x86simdsort::partial_qsortis equivalent tostd::partial_sortin C++.x86simdsort::argsortis equivalent tonp.argsortin NumPy.x86simdsort::argselectis equivalent tonp.argpartitionin NumPy.
Supported datatypes: uint16_t, int16_t, _Float16, uint32_t, int32_t, float, uint64_t, int64_t, double. Note that _Float16 will require building this
library with g++ >= 12.x. All the functions have an optional argument bool hasnan set to false by default (these are relevant to floating point data
types only). If your array has NAN's, the the behaviour of the sorting routine
is undefined. If hasnan is set to true, NAN's are always sorted to the end of
the array. In addition to that, qsort will replace all your NAN's with
std::numeric_limits<T>::quiet_NaN. The original bit-exact NaNs in
the input are not preserved. Also note that the arg methods (argsort and
argselect) will not use the SIMD based algorithms if they detect NAN's in the
array. You can read details of all the implementations
here.
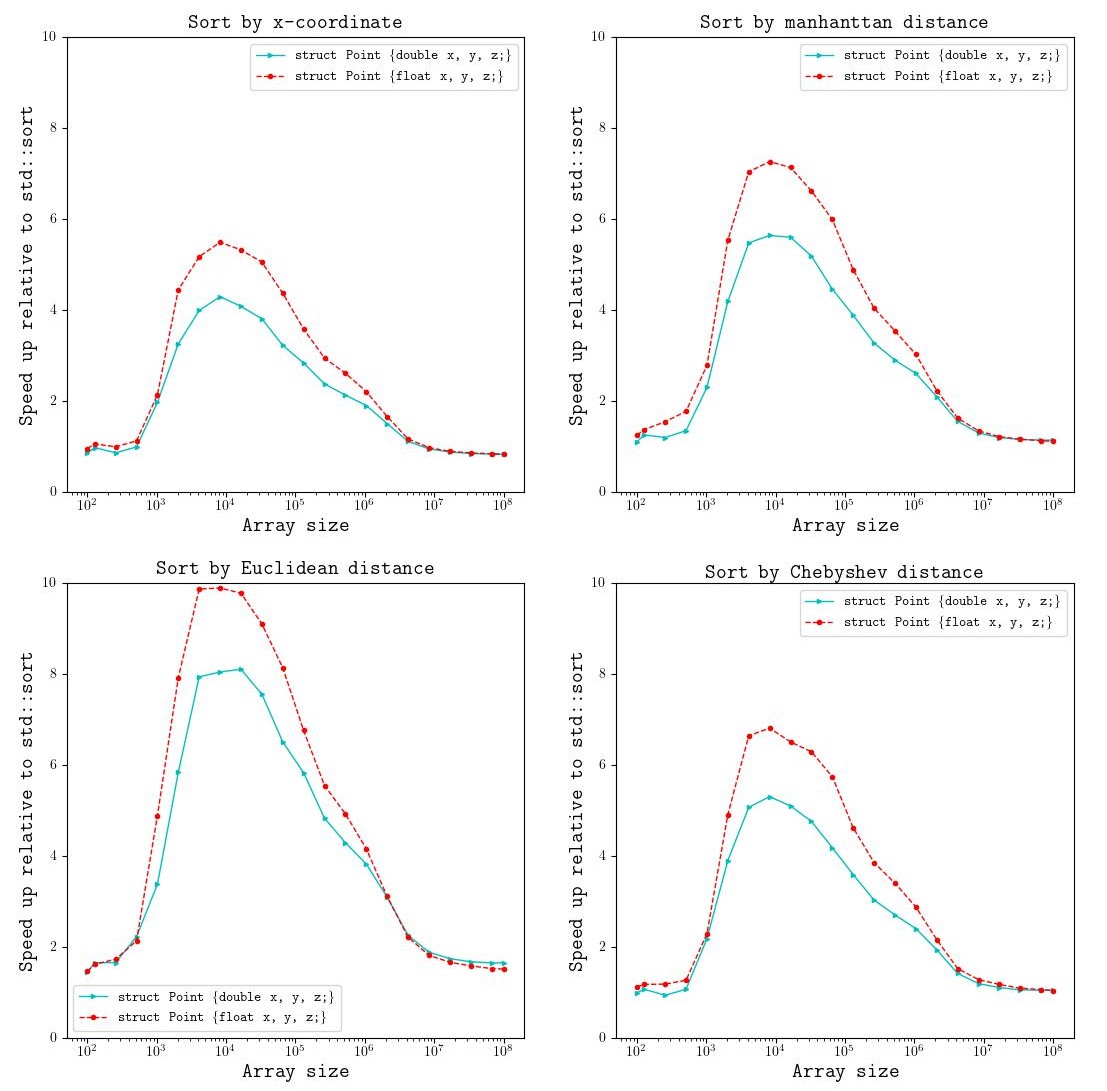
Performance of object_qsort can vary significantly depending on the defintion
of the custom class and we highly recommend benchmarking before using it. For
the sake of illustration, we provide a few examples in
./benchmarks/bench-objsort.hpp which measures
performance of object_qsort relative to std::sort when sorting an array of
3D points represented by the class: struct Point {double x, y, z;} and
struct Point {float x, y, x;}. We sort these points based on several
different metrics:
- sort by coordinate
x - sort by manhanttan distance (relative to origin):
abs(x) + abx(y) + abs(z) - sort by Euclidean distance (relative to origin):
sqrt(x*x + y*y + z*z) - sort by Chebyshev distance (relative to origin):
max(abs(x), abs(y), abs(z))
The performance data (shown in the plot below) can be collected by building the
benchmarks suite and running ./builddir/benchexe --benchmark_filter==*obj*.
The data plot shown below was collected on a processor with AVX-512. For the
simplest of cases where we want to sort an array of struct by one of its
members, object_qsort can be up-to 5x faster for 32-bit data type and about
4x for 64-bit data type. It tends to do even better when the metric to sort by
gets more complicated. Sorting by Euclidean distance can be up-to 10x faster.