{kind=link}
{kind=link}
Performs context based spelling correction.
Based on: https://arxiv.org/pdf/1910.11242.pdf
You have a search engine (like Elastic search) and your user perform queries. If the user query does not contain any results you could use this to get a list of possible other queries and implement a functionality similar to other search engines
showing results for:
For this use case, ideally, you should train the model using your user's queries that produced results.
The datasets that are provided in the repository are from wikipedia or from news, because of privacy reasons. Although, even with these datasets results could be satisfactory.
See the most important environment variables in order to get started.
SC_ADDR: The address the server listens to (default :10000)
SC_SENTENCES_PATH: The path of the file containing sentences from the language
you want to perform spelling correction for. (File must be gzipped)
SC_DICT_PATH: The path of the file with word frequency dictionary for the languate. (file must be gzipped)
See the internal/config/config.go for additional variables
Example assuming that the train files are in the datasets/ folder.
make buildSC_ADDR=:10000 SC_SENTENCES_PATH=datasets/en/sentences.txt.gz SC_DICT_PATH=datasets/en/freq-dict.txt.gz ./spell-correct-server
It starts a web server listening by default on port 10.000
curl 'http://localhost:10000/?query=scred%20a%20bicycle%20kikc'
It gives you back the suggestions. The suggestions are ordered with the ones the algorithm decides are most relevant first.
Example:
make docker-build
docker run -p 10000:10000 -v /home/gosom/datasets:/datasets -e SC_SENTENCES_PATH=/datasets/en/sentences.txt.gz -e SC_DICT_PATH=/datasets/en/freq-dict.txt.gz spell-correctort
The method is language independent. All you need is two files used for training:
- file containing sentences for the languages
- file containing the word frequencies for the languages
In the datasets directory we added examples for English and German.
Datasets source is referenced in the README.md in the language's folder
Here is a naive benchmark in my laptop (Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz)
Bechmarks run with vegeta:
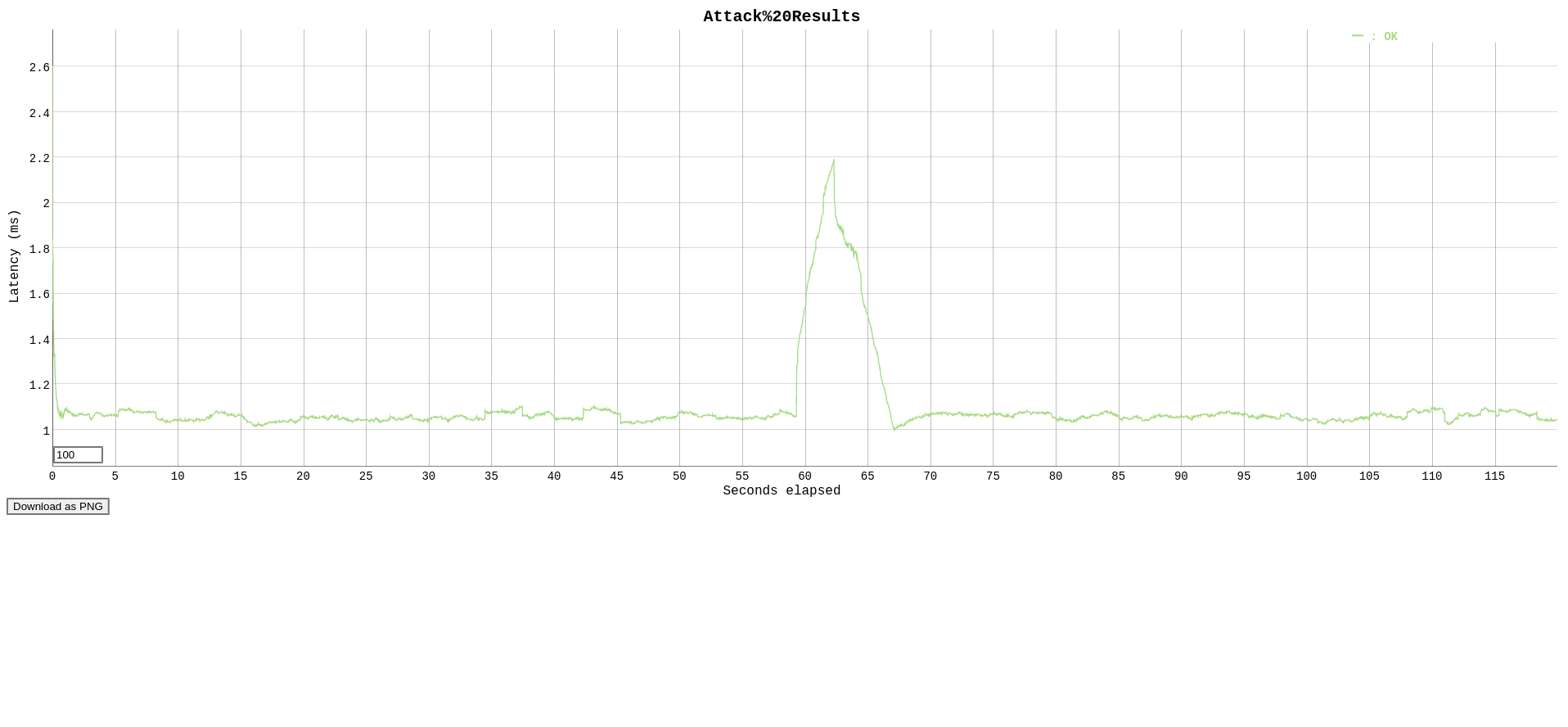
(100 reqs per second)
echo "GET http://localhost:10000/?query=scored%20awsome%20bicicle%20kikc" | vegeta attack -duration=120s -rate 1000 -output=attack-100.bin
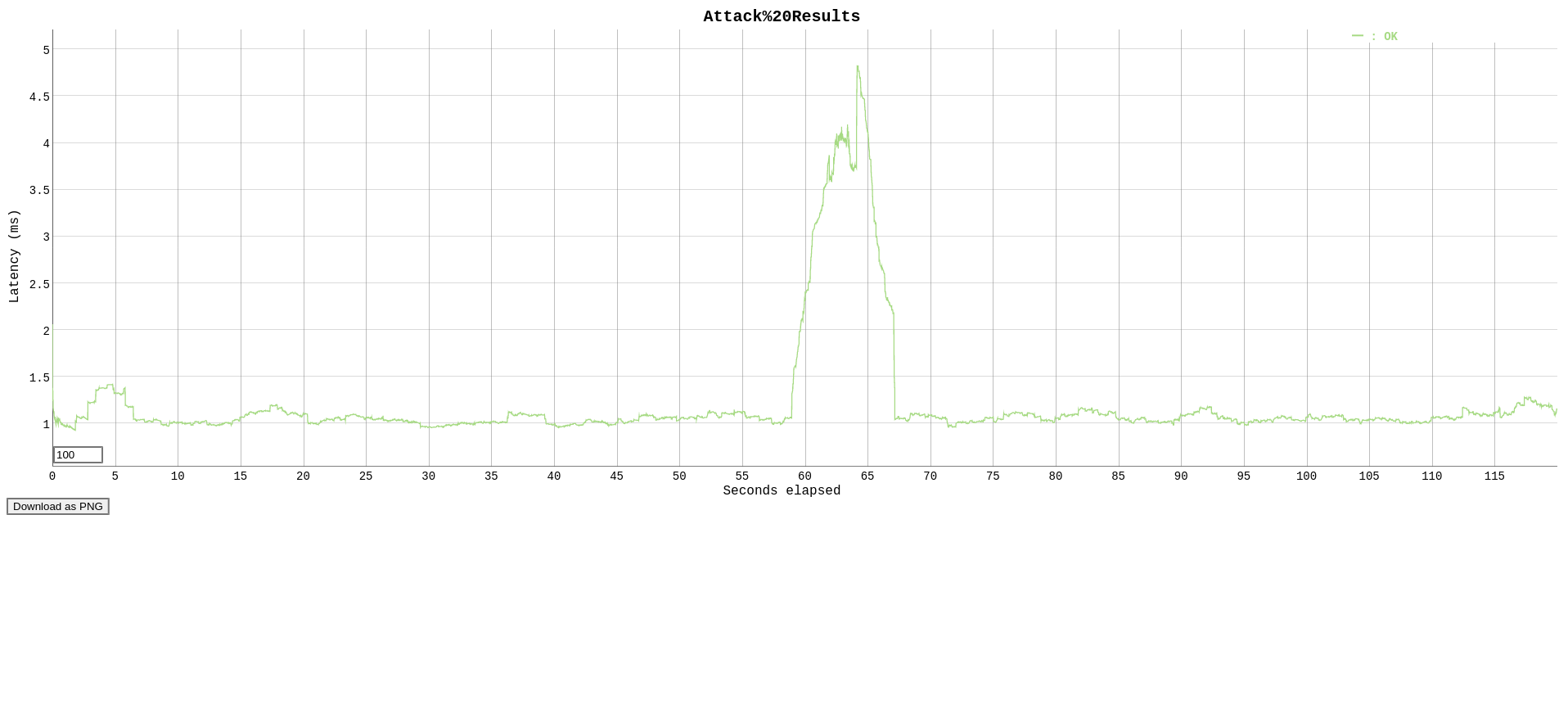
(1000 reqs per second)
echo "GET http://localhost:10000/?query=scored%20awsome%20bicicle%20kikc" | vegeta attack -duration=120s -rate 1000 -output=attack-1000.bin
This project is work in progress. If you find bugs or want to propose improvements feel free to create an Issue [https://github.com/gosom/context-spell-correct/issues] Even better make a pull request
- https://arxiv.org/pdf/1910.11242.pdf
- https://github.com/wolfgarbe/SymSpell
- https://github.com/eskriett/spell
- https://github.com/json-iterator/go
- https://github.com/qiangxue/go-env
- all the package maintainers that are indirect dependencies
- See also datasets//README.md for the dataset's citation