Shuffle-based groupby aggregation for high-cardinality groups #9302
Conversation
|
Another fun note: The shuffle-based groupby algorithm can use the ddf.groupby(
"id", dropna=False
).agg(
{"x": "sum", "y": "mean"}, split_every=16, split_out=8, shuffle="p2p"
) |
|
This is awesome @rjzamora, great thinking! This seems vaguely related to #8361. It also makes me wonder if we could simplify/do away with the |
Good call - Thanks for linking that!
Right - I was thinking that something like an estimated (or optionally inferred from the first partition) ‘cardinality_ratio’ could be used to set reasonable defaults for everything. A ratio of unique records to all records gives you a rough idea of how much your data should “compress” after the global aggregation. |
|
Cool. Do you have a sense for how this performs in a few relevant scenarios? I'd be curious about high cardinality / low cardinality and larger than memory / not larger than memory. |
Good question. This is not a silver bullet by any means, and is primarily a performance booster for the “high-cardinality & smaller than memory” case. It may also be effective for “high-cardinality & larger than memory” in some cases, but I would expect heavy spilling to be an issue for task-based shuffling. I suppose the “p2p” option could make things “work” in this case. However, I was hoping that something like the “ACA-then-shuffle” alternative mentioned above would be a better option for both smaller- and larger-than memory. For any case where cardinality is low enough that you don’t need to use Overall, it seems that the shuffle-based groupby probably has a place, but this PR will need to remain WIP until we can figure out exactly what that place is. |
|
I don't mean to slow down progress here. I think that we should be full
steam ahead on this. Mostly I would like for changes like this to come
with some amount of experimentation to see where they do and don't work to
inform the discussion.
This doesn't have to be perfect to be useful. Please don't take my
comments as negative.
…On Tue, Jul 26, 2022 at 7:47 AM Richard (Rick) Zamora < ***@***.***> wrote:
Cool. Do you have a sense for how this performs in a few relevant
scenarios? I'd be curious about high cardinality / low cardinality and
larger than memory / not larger than memory.
Good question. This is not a silver bullet by any means, and is primarily
a performance booster for the “high-cardinality & *smaller* than memory”
case. It may also be effective for “high-cardinality & *larger* than
memory” in some cases, but I would expect heavy spilling to be an issue for
task-based shuffling. I suppose the “p2p” option could make things “work”
in this case. However, I was hoping that something like the
“ACA-then-shuffle” alternative mentioned above would be a better option for
*both* smaller- and larger-than memory.
For any case where cardinality is low enough that you don’t *need* to use
split_out>1, the existing ACA algorithm is often better (even if you do
use something like split_out=2-4).
Overall, it seems that the shuffle-based groupby probably has a place, but
this PR will need to remain WIP until we can figure out exactly what that
place is.
—
Reply to this email directly, view it on GitHub
<#9302 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACKZTBCJRMU4MCBWXMDU73VV7M4PANCNFSM54TA7O2A>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
No worries at all - I'm pretty sure we are on the same page here :) |
|
This maybe stalled? Anything we can do to unstall it? |
|
@ian-r-rose's mentioned he's going to take a detailed look at this PR (also just FYI @rjzamora is OOO this week) |
Apologies for not leaving a note in this PR - I was distracted by other groupby improvements, and then took some time off. I do think it is worthwhile (and easy) to add the shuffle approach to groupby aggregations. However, I would like to roll back any changes in this PR that use the shuffle algorithm automatically. My reasoning is that the shuffle algorithm is typically slower for larger-than-memory data, and so the user should probably need to opt in explicitly for now. Side Note: I intend to submit something separate for larger-than-memory groupby aggregations that essentially closes the gap between the algorithms used by dask-dataframe and dask-cudf. It seems that the dask-cudf algorithm is typically more efficient for large-scale/large-memory data (but slower in most other cases). I am not completely sure of the reason for this yet, but I do know that one "low-hanging fruit" is that Dask will currently use |
|
I did some experiments on this PR yesterday to try to draw out a bit more when using a shuffle-based approach is a good idea (warning: highly-faceted charts incoming to capture multiple dimensions). I ran a number of groupby-aggs on a ~60GiB timeseries-based dataset where I dialed the number of unique groups up and down to investigate the effects of cardinality on the outputs. Rough code, based on @rjzamora's above : @pytest.mark.parametrize("shuffle", [False, "tasks", "p2p"])
@pytest.mark.parametrize("n_groups", [1000, 10_000, 100_000, 1_000_000, 10_000_000])
@pytest.mark.parametrize("split_out", [1, 4, 8])
def test_groupby(groupby_client, split_out, n_groups, shuffle):
ddf = timeseries_of_size(
cluster_memory(groupby_client) // 4,
id_maximum=n_groups,
)
print(len(ddf))
agg = ddf.groupby("id").agg(
{"x": "sum", "y": "mean"},
split_every=16, # Note that the default split_every is a bit small when split_out>1
split_out=split_out,
shuffle=shuffle,
)
wait(agg, groupby_client, 180)Constants:
Variables:
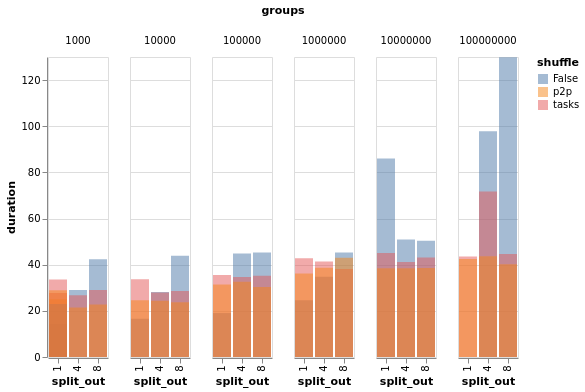
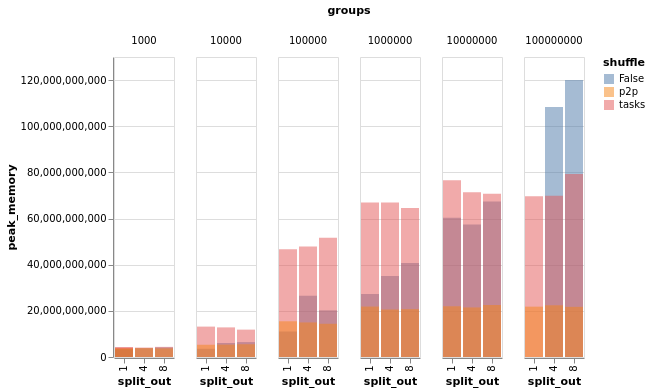
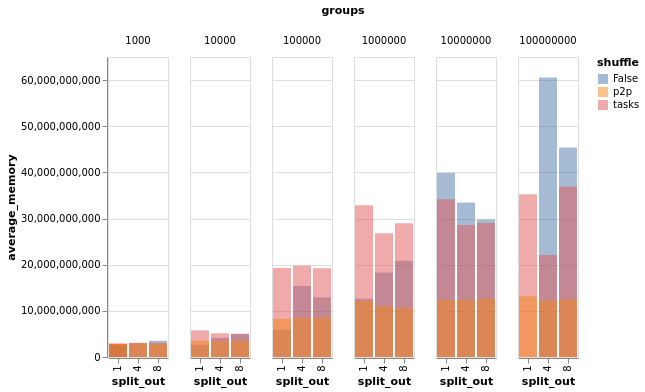
I ran the above on a 15-worker, 60 worker-thread, 240 GiB cluster on AWS, and tracked duration, peak memory usage, and average memory usage. Duration
Peak memory
Average memory
So, some interpretation: First of all, from a broad perspective, ACA-based groupbys/aggs ( However: ACA-based groupby-aggs start to fall over pretty dramatically for high-cardinality cases because the last few partitions are really large and can knock over workers. This worker-killing is not super visible in the average/peak memory charts, as those are cluster-wide, rather than an acute problem on one or a few workers. But this worker-killing predictable, and it's easy to see there is a problem in the duration charts for the 1e8 case. Normally, the advice here would be to tune There is also some useful structure in the memory charts as well. As @rjzamora mentioned above: task-based shuffling generally has worse memory usage than ACA-based grouby/agg. But in the high-cardinality case, that advantage disappears. So at least in that case, I think we can call it an unambiguous win. Also, it's very nice to see that p2p shuffling does indeed have roughly constant memory usage, beating the other two hands-down in the high-cardinality cases. TL;DRThis largely confirms @rjzamora's points above and in conversations I've had with him:
|
|
Thank you for working through these benchmarks and writing this up @ian-r-rose ! It seems safe to conclude that we should add a |
|
Note that I added support for |
|
Cool results. I encourage us to move forward with this quickly. |
|
Also, major kudos to @rjzamora for the work and to @ian-r-rose for the additional perspective |
There was a problem hiding this comment.
Thanks @rjzamora, this is looking great! I have some minor comments, but I think this looks mostly good-to-go.
|
Everything looks green except for gpuCI, which is unrelated: #9391 |
|
Woo -- great work @rjzamora @ian-r-rose |
Dask-cudf groupby tests *should* be failing as a result of dask/dask#9302 (see [failures](https://gpuci.gpuopenanalytics.com/job/rapidsai/job/gpuci/job/cudf/job/prb/job/cudf-gpu-test/CUDA=11.5,GPU_LABEL=driver-495,LINUX_VER=ubuntu20.04,PYTHON=3.9/9946/) in #11565 is merged - where dask/main is being installed correctly). This PR updates the dask_cudf groupby code to fix these failures. Authors: - Richard (Rick) Zamora (https://github.com/rjzamora) Approvers: - GALI PREM SAGAR (https://github.com/galipremsagar) URL: #11561
This PR corresponds to the `dask_cudf` version of dask/dask#9302 (adding a shuffle-based algorithm for high-cardinality groupby aggregations). The benefits of this algorithm are most significant for cases where `split_out>1` is necessary: ```python agg = ddf.groupby("id").agg({"x": "mean", "y": "max"}, split_out=4, shuffle=True) ``` **NOTES**: - ~`shuffle="explicit-comms"` is also supported (when `dask_cuda` is installed)~ - It should be possible to refactor remove some of this code in the future. However, due to some subtle differences between the groupby code in `dask.dataframe` and `dask_cudf`, the specialized `_shuffle_aggregate` is currently necessary. Authors: - Richard (Rick) Zamora (https://github.com/rjzamora) Approvers: - Benjamin Zaitlen (https://github.com/quasiben) - Lawrence Mitchell (https://github.com/wence-) URL: #11800
Note: Related to performance challenges described in #9292
Dask uses apply-concat-apply (ACA) for most DataFrame reductions and groupby aggregations. This algorithm is typically effective when the final output fits comfortably within a single DataFrame/Series partition. However, performance often degrades quickly as the size of the output grows (and
split_outis set to something greater than ~4-8). We can refer to the case wheresplit_outmust be>1as a "high-cardinality" groupby aggregation.The high-cardinality case is currently handled by splitting the intial blockwise groupby aggregation by hash. A distinct ACA tree reduction is then performed for each hash-based "split". For example, the groupby-aggregation graph for a 6-partition DataFrame with
split_out=2will look something like this:This PR improves the performance of high-cardinality groupby aggregations by leveraging the fact that a shuffle operation will typically require fewer overal tasks than a duplicated tree reduction once
split_outbecomes large enough. That is, for cases where a rough task-count estimate begins to favor a shuffle, the task graph will now look something like this:This PR:
42.99, 53101633(24354tasks)Main:
71.16, 53101633(53016tasks)(Note that this algorithm makes it possible to sort the global order of groups, while the current approach does not. However, sorting isn't targetted in this PR.)
Another Alternative
Although it is clear that the shuffle-based groupby is superior to "split-then-tree reduce" for large values of
split_out, it should require even fewer tasks to perform a single-split tree reduction down to ~split_outpartitions, and then perform the shuffle:I have been exploring this algorithm in a seperate branch, but have not had any luck outperforming the shuflle-based groupby yet.