[Closed][Pylint] Making frontend tests pylint compliant #11703
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
9f09a92
to
41e5f5b
Compare
- Skip Hexagon benchmarks whenever the env. var `ANDROID_SERIAL_NUMBER` has the value `simulator`. This is a temporary hack to prevent the CI pre-commit hook from running benchmarks, due to the extra time required. - Fix a bug where the elementwise-add benchmark code was broken by an earlier change to the `HexagonLauncherRPC` class. - Rename `benchmark_elemwise_add.py` to `test_benchmark_elemwise_add.py` so that it's noticed by the CI test infrastructure. (CI tests are sometimes run in contexts _other than_ the pre-commit hook.) - Miscellaneous small changes to `tests/python/contrib/test_hexagon/benchmark_util.py`.
This PR includes the distributed measurement of tuning candidates using builder and async runner, as well as some auxiliary functions. It enables multiple builders and multiple runners with a tracker connecting in between. The hierarchy of files in the database can be further compacted to make the database more concise.
- Add benchmarking framework for Hexagon maxpool-2d kernels, and one (simple) kernel.
… Inputs (apache#11315) * [Runtime][PipleineExecutor] Added Interface to Track Number of Global Inputs Added a feature to PipelineExecutor to track number of Global Inputs. * Fixed CI Error * Fixed remaining CI Error
…e#11766) Pointed out by @sunggg that the description of `number` and `repeat` for evaluator configuration is not accurate, updated to a version more consistent with `TimeEvaluator`. 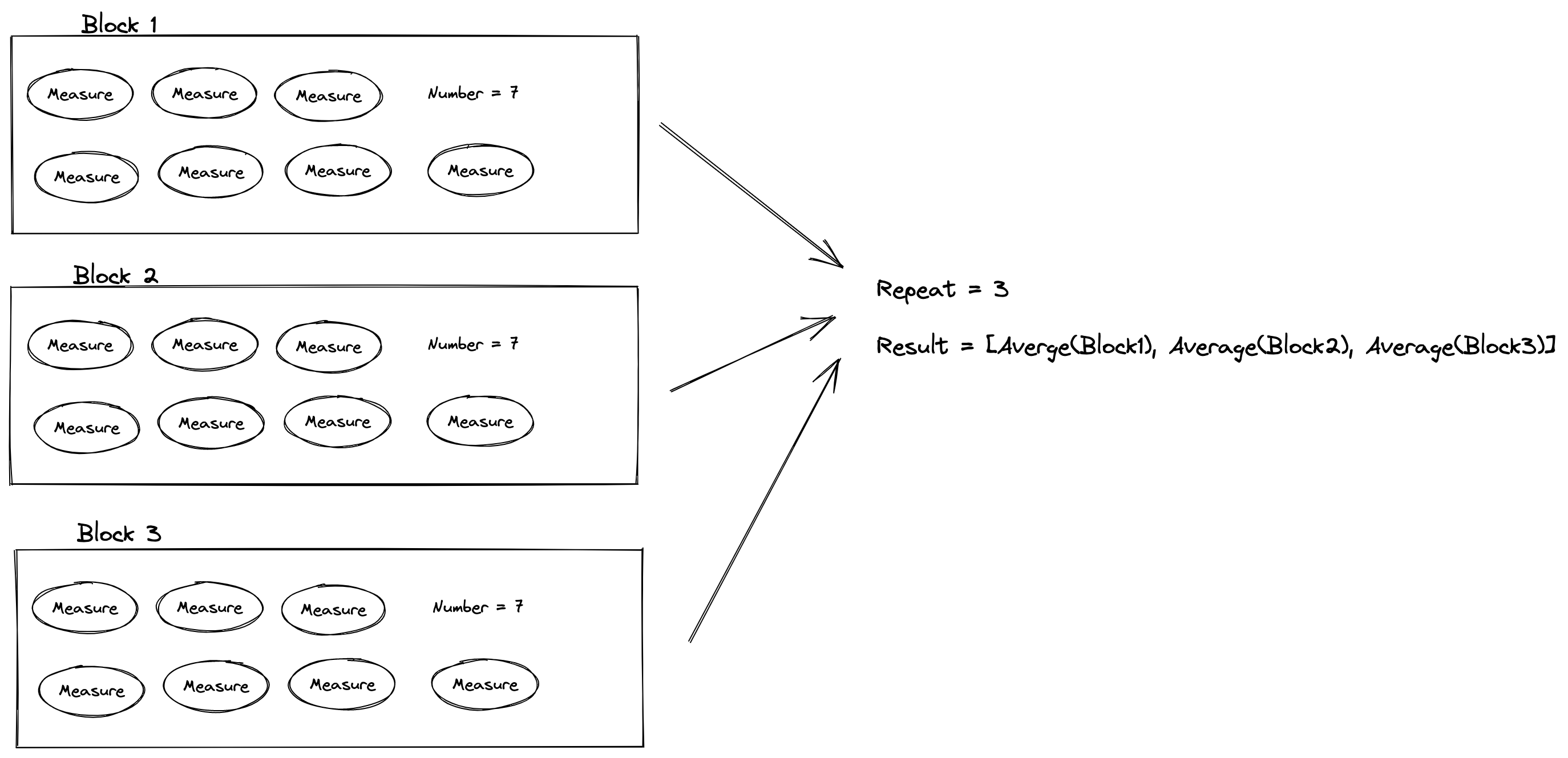
{kind=link}
…e#11754) This PR is based on apache#11751 and adds `describe` function for `tune_relay` and `tune_onnx` script on both AutoScheduler and MetaSchedule. It prints out very useful information for reproducibility as follows: ``` Python Environment TVM version = 0.9.dev0 Python version = 3.8.8 (default, Apr 13 2021, 19:58:26) [GCC 7.3.0] (64 bit) os.uname() = Linux 5.15.5-76051505-generic #202111250933~1638201579~21.04~09f1aa7-Ubuntu SMP Tue Nov 30 02: x86_64 CMake Options: { "BUILD_STATIC_RUNTIME": "OFF", "COMPILER_RT_PATH": "3rdparty/compiler-rt", "CUDA_VERSION": "NOT-FOUND", "DLPACK_PATH": "3rdparty/dlpack/include", "DMLC_PATH": "3rdparty/dmlc-core/include", "GIT_COMMIT_HASH": "3b872a0adae07b0cd60248346fd31b158cba630c", "GIT_COMMIT_TIME": "2022-06-15 11:27:59 -0700", "HIDE_PRIVATE_SYMBOLS": "OFF", "INDEX_DEFAULT_I64": "ON", "INSTALL_DEV": "OFF", "LLVM_VERSION": "11.0.1", "PICOJSON_PATH": "3rdparty/picojson", "RANG_PATH": "3rdparty/rang/include", "ROCM_PATH": "/opt/rocm", "SUMMARIZE": "OFF", "TVM_CXX_COMPILER_PATH": "/usr/lib/ccache/c++", "USE_ALTERNATIVE_LINKER": "AUTO", "USE_AOT_EXECUTOR": "ON", "USE_ARM_COMPUTE_LIB": "OFF", "USE_ARM_COMPUTE_LIB_GRAPH_EXECUTOR": "OFF", "USE_BLAS": "none", "USE_BNNS": "OFF", "USE_BYODT_POSIT": "OFF", "USE_CLML": "OFF", "USE_CLML_GRAPH_EXECUTOR": "OFF", "USE_CMSISNN": "OFF", "USE_COREML": "OFF", "USE_CPP_RPC": "OFF", "USE_CUBLAS": "OFF", "USE_CUDA": "/usr/lib/cuda-11.2", "USE_CUDNN": "OFF", "USE_CUSTOM_LOGGING": "OFF", "USE_CUTLASS": "OFF", "USE_DNNL": "OFF", "USE_ETHOSN": "OFF", "USE_FALLBACK_STL_MAP": "OFF", "USE_GRAPH_EXECUTOR": "ON", "USE_GRAPH_EXECUTOR_CUDA_GRAPH": "OFF", "USE_GTEST": "AUTO", "USE_HEXAGON": "OFF", "USE_HEXAGON_GTEST": "/path/to/hexagon/gtest", "USE_HEXAGON_RPC": "OFF", "USE_HEXAGON_SDK": "/path/to/sdk", "USE_IOS_RPC": "OFF", "USE_KHRONOS_SPIRV": "OFF", "USE_LIBBACKTRACE": "ON", "USE_LIBTORCH": "OFF", "USE_LLVM": "llvm-config-11", "USE_METAL": "OFF", "USE_MICRO": "OFF", "USE_MICRO_STANDALONE_RUNTIME": "OFF", "USE_MIOPEN": "OFF", "USE_MKL": "OFF", "USE_MSVC_MT": "OFF", "USE_NNPACK": "OFF", "USE_OPENCL": "OFF", "USE_OPENCL_GTEST": "/path/to/opencl/gtest", "USE_OPENMP": "none", "USE_PAPI": "OFF", "USE_PROFILER": "ON", "USE_PT_TVMDSOOP": "OFF", "USE_RANDOM": "ON", "USE_RELAY_DEBUG": "OFF", "USE_ROCBLAS": "OFF", "USE_ROCM": "OFF", "USE_RPC": "ON", "USE_RTTI": "ON", "USE_RUST_EXT": "OFF", "USE_SORT": "ON", "USE_SPIRV_KHR_INTEGER_DOT_PRODUCT": "OFF", "USE_STACKVM_RUNTIME": "OFF", "USE_TARGET_ONNX": "OFF", "USE_TENSORFLOW_PATH": "none", "USE_TENSORRT_CODEGEN": "OFF", "USE_TENSORRT_RUNTIME": "OFF", "USE_TFLITE": "OFF", "USE_TF_TVMDSOOP": "OFF", "USE_THREADS": "ON", "USE_THRUST": "OFF", "USE_VITIS_AI": "OFF", "USE_VULKAN": "OFF" } ```
…s for auto tensorization (apache#11740) This PR added a utility function `GetAutoTensorizeMappingInfo` to propose mapping from workload block iters to the iters in the tensor intrin. An example usage is conv2d, where the computation block has more iters than the matmul tensor intrin.
* [TVMC] Fix tvmc run when using rpc As described in apache#11707, the RPC mechanism does not support objects of type Map which breaks the use of tvmc run when using RPC after apache#9889. This commit intends to workaround this issue by providing a fallback to the old implementation when RPC is being used. Further, a test has been provided to help prevent this regression in the future. Change-Id: I70c1863d00098270e27c08ba834a3587e9132d69 * fix lint Change-Id: I958cf4e19988d047bdd2e02f6475b9f70afe80c8
These should go to the same tag as in `tlcpack` so the only difference is the user
Originally, when failed with `std::stoi` and `std::stod`, the parser disruptly stops and throw an incomprehensible error message, for example, "stoi". This PR improves the user experience by detailing which string causes the parsing issue. A minor fix: out-of-range integers in parsing will now automatically fall back to floating point numbers.
Previously `cpu-flush` option existed as a boolean or integer argument, which is a bit counter-intuitive because for argparse, any non-empty string such as `False` will be parsed to `True` when using as a boolean and integer a little bit vague here IMHO. This PR used a function from `distutils` to directly parse input string to boolean, which makes the usage more stragiht-forward like `--cpu-flush True` or `--cpu-flush False`. Meanwhile it still supports usage of `0/1` and made sure the argument is always required.
build/html get moved into _docs, update related document.
* [UPSTREAM][HEXAGON] Slice ops added - add, subtract, multiply * Change to v68 * Change transform_numpy function call * Do not disbale pylint errors and fix them * Fix variable names * Move the test file to topi * Resolve conflict * Modify init
* [TIR] Simplify expressions using tir.ceil and tir.log2 These expressions are introduced in `topi.math.ceil_log2`, and can otherwise be propagated through to the generated kernel. * [Arith] Added left shift handling to ConstIntBoundsAnalyzer Previously, only right shift was handled. These left shifts are used in the `cuda.sort` implementation. * Update to avoid left shift of negative numbers * Updated rewriting of log2(x) to only occur in ceil(log2(x)) Per @wrongtest's request, to avoid rounding differences between different devices. * Avoid assumptions made of negative arguments to left-shift * Recognize bounds of int(ceil(log2(arg)))
…che#11693) * Working 8 bit vlut for relay take operator * Formatting * More formatting * clang-format on codegen_hexagon.cc * Update for llvm api * Add return to VisitExpr(BufferLoadNode) function * different llvm api
* Use python3 to run determine_docker_images.py * Properly detect presence of CI env var with + expansion.
This code was there to stop Jenkins restarts from doing a repository scan and scheduling a ton of builds. However, I haven't noticed this happening during restarts lately, and repository scans are useful to patch up PRs that didn't get CI run properly (i.e. while Jenkins was down or something). For example in apache#11914 since this code is there all the messed up PRs needed their CI to be manually re-triggered even though they were detected during the scan.
…elayToTIR hook (apache#11979) * [BYOC] Switch TensorRT BYOC integration to IRModule-at-a-time using RelayToTIR hook This does for the TensorRT integration what apache#11631 did for the CUTLASS integration. - All compilation options are captured within the attributes of a Target of kind "tensorrt" (instead of the "relay.ext.tensorrt.options" attribute in PassContext). This means all BYOC configurations options needed by Collage can be captured uniformly by a list-of-Targets. It also means RPC boundaries (as used internally at OctoML) only need to worry about maintaining the fidelity of the Target instance(s) rather than reaching into the PassContext. - Compilation is switched from function-at-a-time (relying on the TECompiler) to IRModule-at-a-time (using the RelayToTIR target-specific hook mechanism). Though not strictly necessary for Collage I want to check the path is now clear to deprecate the support for BYOC in TEComplier. - Get all the TensorRT tests going again, except for a few I've disabled with x-link to a new issue apache#11765. CAUTION: The TensorRT runtime is not supported in CI so many of these tests are cosmetic. - While trying to track down a 'free(): invalid pointer' error in test_tensorrt_int8_exp.py made the TensorRT allocs/frees more robust, but turns out its also broken in main. No harm leaving these changes in though. * - Lints * - Woops, fix test * - lints * - Use default tensorrt target if none given in targets list * - fix free error * - accidentally introduced 'transforms' namespace - can't use default Target("tensorrt") arg * - D'oh! Include ended up #if protected * - restore mark for test_dynamic_offload - handle missing runtime in versioning - turn test_maskrcnn_resnet50 back on now that we have the import-torch-first workaround. * - wibble
…pache#11984) With LLVM switching to opaque (typeless) pointer types, some functions related to handling typed pointers are being deprecated (and will be removed). The DWARF debug information does express pointee type. When constructing this information from opaque pointers in LLVM IR, the pointee type needs to be obtained from somewhere else (not the pointer). Change the debug info generation to use the original PrimFunc to obtain the necessary type information. This will work with older versions of LLVM as well.
* add trilu * update triu and tril; fix empty * fix lint
Previously, Auto-Inline on CPU will only inline according to strict conditions, for example, ordered index mapping. This is generally good practice to do so, but on the other hand, there is no much benefit to stop inlining only due to some restrictive conditions for pure spatial subgraphs. By doing so, we also save some search trials on pure spatial subgraphs so that more can be allocated to more important ones.
This PR introduces `Schedule.work_on`, which instructs `Schedule.get_block` to find the correct PrimFunc to retrieve from without having to specify `func_name` in every time if the PrimFunc's name is not `main`.
* enhance WA in dnnl_convolution, support crop for tensor with mismatched groups and OC * add missing param checks for conv2d, conv3d * fix lint
* add nms_v5 op for TFLite * add a test for the TFLite nms_v5 op
…ance (apache#11822) * rewrite downsize blocks for rensetv1 to get better performance * fix lint
* Common autotuning test * Autotuned model evaluation utilities * Bugfixes and more enablement * Working autotune profiling test * Refactoring based on PR comments Bugfixes to get tests passing Refactor to remove tflite model for consistency Black formatting Linting and bugfixes Add Apache license header Use larger chunk size to read files Explicitly specify LRU cache size for compatibility with Python 3.7 Pass platform to microTVM common tests Better comment for runtime bound Stop directory from being removed after session creation * Use the actual Zephyr timing library Use unsigned integer Additional logging Try negation Try 64 bit timer Use Zephyr's timing library Fix linting Enable timing utilities
* [TIR] Make conversion from Integer to int64_t explicit * Fix compilation errors * Fix compilation issues in cpptest * Fix SPIRV compilation errors
…12007) * Fix infercorrect layout in layoutrewrite. * Compatibility issue. * Fix lint. * Better naming and detailed comments. * Add unittest.
…pache#12011) * [CI] Use command-line argument or TVM_BUILD_PATH for C++ unittests Previously, the `ci.py` script would execute all C++ unit tests in the `"build"` directory, regardless of the docker image being used. This change allows a caller to specify the build directory to be used by `task_cpp_unittest.sh`, either by the command line or by using the same `TVM_BUILD_PATH environment variable as used by the top-level Makefile, and passes this argument from `ci.py`. To preserve the existing behavior for the pre-commit CI, if no argument is passed and if the `TVM_BUILD_PATH` is undefined, `task_cpp_unittest.sh` defaults to the `"build"` directory. Python unit tests executed through `ci.py` used the `TVM_LIBRARY_PATH` environment variable, and were not similarly affected. * Remove `name=name` in format script Co-authored-by: driazati <9407960+driazati@users.noreply.github.com> * Fix lint error * Use default expansion of TVM_BUILD_PATH Otherwise, `set -u` rightly errors out for it being undefined. Co-authored-by: driazati <9407960+driazati@users.noreply.github.com>
This patch increases stability of the hill climb allocation algorithm Change-Id: I56414ae661fa856baeddce00f4717a9f5a9e2954
…pache#11209) * [microNPU] Calculate memory pressure for microNPU external functions During the microNPU compilation stage, the "used_memory" annotations on external microNPU functions are read to determine a memory pressure value. This value is passed to the cascader to better approximate the memory available for the optimization. Change-Id: I11a311b0005e785637014cb451f4aed96edcda26 * fix get size from memory region Change-Id: I41acfc83f05b2204075edb99f86a0eecaba00f71 * add test case for full offload Change-Id: If3e672d402ab237fa82e34761bb972d2e9483ba9
This PR addes: - Doc base class - DocPrinter base class - PythonDocPrinter - LiteralDoc and its support in DocPrinter Tracking issue: apache#11912
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Fix pylint issues in #11414
List of files to complete:
Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from Reviewers by @ them in the pull request thread.