- Data Science for Innovation, Social Impact, and Social Good
- Date: October 6-7th, 2018
- Created By: Hansel Wei, Linh Pham, Herambh Yadavalli, Timothy Chacko
- License: MIT
- Description: Human Trafficking Textual & Emoji Analysis and Feature Generation for used with Machine Learning.
- Web App Link:
-
The City of Charlotte is plagued with human trafficking, averaging around 78 cases per year, making it the #1 city in North Carolina. The inspiration for our project came from a workshop that one of our members attended hosted by an organization that provides assistance to survivors. During the workshop, the presenter spoke of code words that are used within online advertisements for human trafficking.
-
These ads are posted on various sites, such as Craiglist and Bedwatch, tends to contain keywords that allow them to camouflage among other ads.
-
These keywords tend to change so it is difficult for law enforcement to make correct predictions on potential human trafficking ads.
-
Our idea is using machine learning and natural language processing to recognize key factors of human trafficking and generate datasets containing keywords and emojis.
- Our program will create a dataset based on the site contents searching for particular emojis and keywords
- It runs sentiment analysis and caragorical Natural Language Processing through the Google Cloud NLP API.
- Uses seaborn to help visualize data.
- The HTML component is able to upload a CSV file contain the dataset and generating into a JSON file
-
Our original plan was to gather datasets and use machine learning to create an application that can through the sites and scan for keywords that could potential be linked to a sex trafficking advertisement However, as we were working on finding datasets, we were not able to find anything on human trafficking ads analysis. But we did came across studies that spoke of how there are little to no datasets on human trafficking ads. Though we have the tools to build the application that we want, we were missing datasets.
-
Therefore we had to explore the unknown and extract raw data from forums, websites and social media and came across a website that had ads with likelyhood of human trafficking to model our project and research which can be found below:
- Facebook sued for allegedly enabling human trafficking
- (PDF) ResearchGate - Don’t Want to Get Caught? Don’t Say It: The Use of EMOJIS in Online Human Sex Trafficking Ads
- Deep Dive - Memex Human Trafficking Summary
- We later found out that the majority what we were doing was called feature engineering after we found our raw data points from traversing information through leaked information and connections about Dark Web and utilizing our cyber-threat hunting knowledge through websites like Pipl - People Search check the validity of the data and find people including usernames, phones, and addresses we were collecting from our searches.
Machine Learning Process:
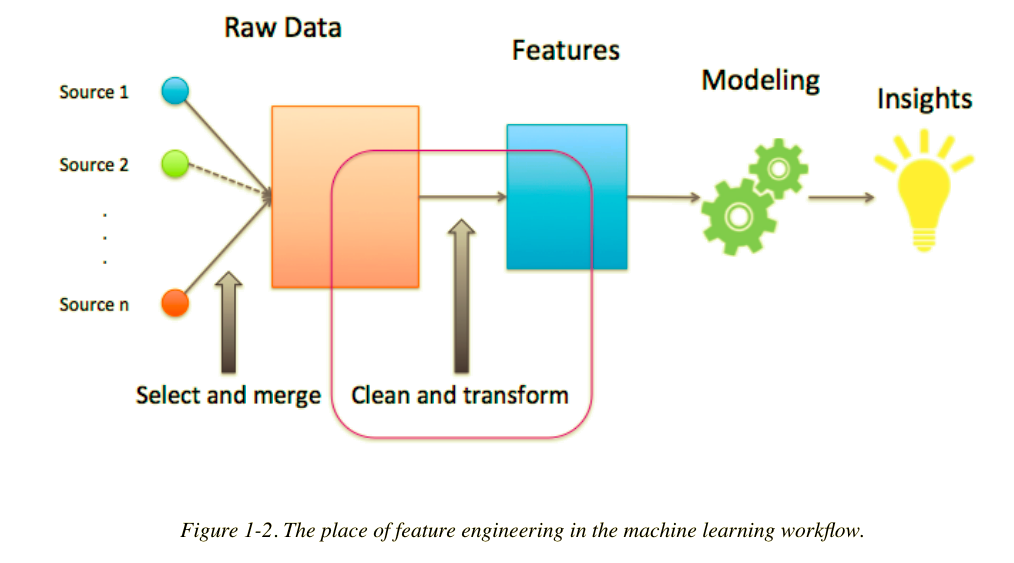
Feature Engineering is the process of using domain knowledge of the data
to create features that make machine learning algorithms work.
Feature engineering is fundamental to the application of machine learning,
and is both difficult and expensive.
- We further submitted our data under the MIT Open Source License in hopes that future researchers can help us predict human trafficking ads. Predicting of ads can allow for law enforcement to target the specific traffickers since they can come into contact with these individuals who often move between places. In addition, we made a simple web app to demo our project that will allow users to visualize and data engineered which will help identify future posts.
- Since we weren't able to find any datasets to implement our original idea, we had to generate data ourselves
- We had a few difficulties with setting up the Google Cloud Natural Language Processing API (GCloud NLP). We weren't downloading the correct installations so it took us about an hour to fix the problem
- Since most of us weren't familiar with tools such a Jupyter, git and GCloud NLP, there was a high learning curve
- Conversion of CSV to JSON was difficult when we were trying to visualize our data
- Trying to build a website 2 hours before it is due because we didn't have all of the pieces together on time.
- Encoded and decoded emojis in Python
- Generating semantic analysis and category classification using GCloud NLP
- How to use Jupyter
- Data Science
- Git
- Python
- GCloud NLP
- Beautiful Soup
- We would like to publish and extract larger datasets as more research is needed.
- We would like to explore more Machine Learning and Textual Analysis models.
- We want to turn this into an API or build better applications to detect human trafficking by using process.