An open source Python SDK to allow data scientists to test and deploy machine learning inference pipelines.
- Create and test inference locally.
- Deploy to Seldon for production.
![]()
Tempo provides a unified interface to multiple MLOps projects that enable data scientists to deploy and productionise machine learning systems.
- Package your trained model artifacts to optimized server runtimes (Tensorflow, PyTorch, Sklearn, XGBoost etc)
- Package custom business logic to production servers.
- Build an inference pipeline of models and orchestration steps.
- Include any custom python components as needed. Examples:
- Outlier detectors with Alibi-Detect.
- Explainers with Alibi-Explain.
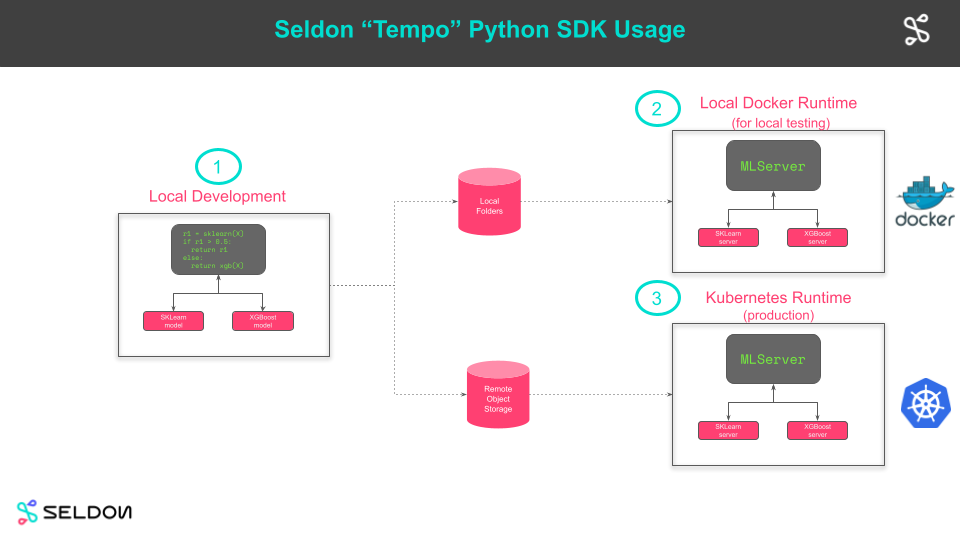
- Test Locally - Deploy to Production
- Run with local unit tests.
- Deploy locally to Docker to test with Docker runtimes.
- Deploy to production on Kubernetes with Seldon
- Extract declarative Kubernetes yaml to follow GitOps workflows.
- Supporting Seldon production runtimes
- Seldon Core open source
- Seldon Deploy enterprise
- Create stateful services. Examples:
- Multi-Armed Bandits.
- Develop locally.
- Test locally on Docker with production artifacts.
- Push artifacts to remote bucket store and launch remotely (on Kubernetes).
Data scientists can easily test their models and orchestrate them with pipelines.
Below we see two Models (sklearn and xgboost) with a function decorated pipeline to call both.
def get_tempo_artifacts(artifacts_folder: str) -> Tuple[Pipeline, Model, Model]:
sklearn_model = Model(
name="test-iris-sklearn",
platform=ModelFramework.SKLearn,
local_folder=f"{artifacts_folder}/{SKLearnFolder}",
uri="s3://tempo/basic/sklearn",
)
xgboost_model = Model(
name="test-iris-xgboost",
platform=ModelFramework.XGBoost,
local_folder=f"{artifacts_folder}/{XGBoostFolder}",
uri="s3://tempo/basic/xgboost",
)
@pipeline(
name="classifier",
uri="s3://tempo/basic/pipeline",
local_folder=f"{artifacts_folder}/{PipelineFolder}",
models=PipelineModels(sklearn=sklearn_model, xgboost=xgboost_model),
)
def classifier(payload: np.ndarray) -> Tuple[np.ndarray, str]:
res1 = classifier.models.sklearn(input=payload)
if res1[0] == 1:
return res1, SKLearnTag
else:
return classifier.models.xgboost(input=payload), XGBoostTag
return classifier, sklearn_model, xgboost_modelSave the pipeline code.
from tempo.serve.loader import save
save(classifier)Deploy locally to docker.
from tempo import deploy_local
remote_model = deploy_local(classifier)Make predictions on containerized servers that would be used in production.
remote_model.predict(np.array([[1, 2, 3, 4]]))Deploy to Kubernetes for production.
from tempo.serve.metadata import SeldonCoreOptions
from tempo import deploy_remote
runtime_options = SeldonCoreOptions(**{
"remote_options": {
"namespace": "production",
"authSecretName": "minio-secret"
}
})
remote_model = deploy_remote(classifier, options=runtime_options)This is an extract from the multi-model introduction demo.