Trident provides storage orchestration for Kubernetes, integrating with its Persistent Volume framework to act as an external provisioner for NetApp ONTAP, SolidFire, and E-Series systems. Additionally, through its tridentctl CLI or REST interface, Trident can provide storage orchestration for non-Kubernetes deployments.
Relative to other Kubernetes external provisioners, Trident is novel from the following standpoints:
- Trident is one of the first out-of-tree, out-of-process storage provisioners that works by watching events at the Kubernetes API Server.
- Trident supports storage provisioning on multiple platforms through a unified interface.
Rather than force users to choose a single target for their volumes, Trident selects a backend from those it manages based on the higher-level storage qualities that the user needs. This allows it to provide unified, platform-agnostic management for the storage systems under its control without exposing users to complexities of various backends.
- Getting Started
- Tutorials
- Requirements
- Deploying Trident
- Using Trident
- Provisioning Workflow
- Troubleshooting
- Caveats
Although Trident can be launched in a number of ways, the most straightforward way to deploy it in Kubernetes environments is to launch it as a deployment of a pod containing both Trident and etcd, which Trident uses for persisting its metadata. Note that, although we use a deployment to ensure that Trident remains live, users should never scale Trident beyond a single replica, as this may cause unexpected and incorrect behavior.
These instructions will guide you through the basic steps required to start and run Trident, including the necessary host and backend configuration, creating storage for Trident, and launching and configuring Trident itself. For details on more advanced usage or for how to run Trident if service accounts are not available, see the subsequent sections.
-
Ensure a Kubernetes 1.4+, OpenShift 3.4+, or OpenShift Origin 1.4+ cluster with service accounts is available. If you need to create one, we recommend using kubeadm as it allows for easy creation of clusters that meet Trident's requirements.
-
Ensure iSCSI and the NFS utils are present on all the nodes in the cluster, so that they can mount the volumes that Trident creates. See here for instructions.
-
The installer script requires you to have cluster admin-level privileges in your Kubernetes or OpenShift deployment. Otherwise, the installer script will fail in operating on cluster-level resources such as PVs, ClusterRoles, ClusterRoleBindings, etc. Once installed, the Trident pod is limited to the operations allowed by RBAC authorization (see Kubernetes ClusterRoles or OpenShift ClusterRoles). As an example, logging in as
system:adminprovides the necessary credentials to install Trident in OpenShift:oc login -u system:admin. -
If you plan on using SolidFire with Trident, you'll need to create and specify in your config up to 4 volume AccessGroups. Each Access Group has a limit of 64 initiators (IQN entries) that can belong to it, so if your deployment includes greater than 64 nodes, you'll create a VAG per each setup of 64 nodes. The max number of VAG's per Trident deployment is 4, providing access of up to 256 nodes per configuration. Specify the Access Groups via the AccessGropus entry in your configuration file, which accepts a list of ID's of at least 1 and up to 4 unique existing SolidFire Volume Access Group ID's. If you're upgrading your Trident deployment, remember to include your original Trident Access Group ID in this list!
If you plan on using ONTAP SAN, create an iGroup named
tridentthat contains the IQN of each node in the cluster; for an example of this, see this blog post.If you plan on using E-Series, create a Host Group named
tridentand create a Host in that Host Group that contains the IQN of each node in the cluster. -
Download and untar the Trident installer bundle. Then, change into the
trident-installerdirectory resulted from untar. -
Configure a storage backend from which Trident will provision its volumes. This will also be used in step 8 to provision the PVC on which Trident will store its metadata.
Edit either
sample-input/backend-ontap-nas.json,sample-input/backend-ontap-san.json,sample-input/backend-solidfire.json, orsample-input/sample-eseries-iscsi.jsonto refer to an actual ONTAP, SolidFire, or E-Series deployment. (Usebackend-ontap-nas.jsonto provision NFS volumes from ONTAP andbackend-ontap-san.jsonfor iSCSI volumes).If multiple clusters will be running Trident against the same backend, add the storagePrefix attribute, with a value that will be unique to your cluster, e.g.,
storagePrefix="username". See the Caveats section for further details.If using ONTAP-SAN or SolidFire or E-Series, make sure all hosts in the Kubernetes cluster are mapped into the
tridentiGroup, AccessGroups, or Host Group, respectively, as described in the Requirements section. -
Copy the backend configuration file from step 6 to the
setup/directory and name itbackend.json. -
Run the Trident installation script:
./install_trident.sh -n trident
where the
-nargument is optional and specifies the namespace for the Trident deployment. If not specified, namespace defaults to the current namespace; however, it is highly recommended to run Trident in its own namespace so that it is isolated from other applications in the cluster. Trident's REST API and thetridentctlCLI tool are intended to be used by IT administrators only, so exposing such functionalities to unprivileged users in the same namespace can pose security risks and can potentially result in loss of data and disruption to operations.The install script first configures the Trident deployment and Trident launcher pod definitions, found in
setup/trident-deployment.yamlandlauncher-pod.yaml. It then starts the Trident launcher pod, which provisions a PVC and PV on which Trident will store its data, using the provided backend. The launcher then starts a deployment for Trident itself, using the defintion insetup/. For an overview of steps carried out by the installer script, please see Install Script and Using the Trident Launcher. When the installer completes,kubectl get deployment tridentshould show a deployment namedtridentwith a single live replica. Runningkubectl get podshould show a pod with a name starting withtrident-with 2/2 containers running. From here, runningkubectl logs <trident-pod-name> -c trident-mainwill allow you to inspect the log for the Trident pod. If no problem was encountered, the log should include"trident bootstrapped successfully.". If you run into problems at this stage--for instance, if atrident-ephemeralpod remains in the running state for a long period--see the Troubleshooting section for some advice on how to deal with some of the pitfalls that can occur during this step. -
Copy the
tridentctlCLI tool from thetrident-installerdirectory to any location reflected in the environment$PATH. -
Register the backend from step 6 with Trident once Trident is running. Run
tridentctl create backend -f setup/backend.jsonNote that if desired you could configure and register a different backend instead; registering the backend used to provision the etcd volume is not mandatory.
-
Configure a storage class that uses this backend. This will allow Trident to provision volumes on top of that backend.
Edit the
backendTypeparameter ofsample-input/storage-class-basic.yaml.templand replace__BACKEND_TYPE__with eitherontap-nas,ontap-san,solidfire-san, oreseries-iscsidepending on the backend created in the previous steps. Save it assample-input/storage-class-basic.yaml. -
Create the storage class. Run
kubectl create -f sample-input/storage-class-basic.yamlVolumes that refer to this storage class will be provisioned on top of the backend registered in step 10.
Once this is done, Trident will be ready to provision storage, either by
creating
PVCs
in Kubernetes (see sample-input/pvc-basic.yaml for an example) or through the
REST API using cat <json-file> | kubectl exec -i <trident-pod-name> -- post.sh volume (see sample-input/sample-volume.json for an example configuration).
Detailed information on creating Volume configurations for the REST API is
available in Volume Configurations, and
Volumes describes how to create them using PVCs. If you are
unfamiliar with the PersistentVolume interface in Kubernetes, a walkthrough
is available
here.
Unlike the nDVP, Trident supports managing multiple backends with a single instance. To add an additional backend, create a new configuration file and add it using tridentctl, as shown in step 10. See Backends for the different configuration parameters and REST API for details about the REST API. Similarly, more storage classes can be added, either via Kubernetes, as in step 12, or via POSTing JSON configuration files to Trident's REST API. Storage Class Configurations describes the parameters that storage classes take. Instructions for creating them via Kubernetes are available in the Storage Classes section. For more details on how Trident chooses storage pools from a storage class to provision its volumes, see Provisioning Workflow.
- Trident v1.0: This tutorial presents an in-depth overview of Trident
and demonstrates some advanced use cases (please see
CHANGELOG for the
changes since v1.0).
Trident has relatively few dependencies, most of which can be resolved by using a prebuilt image and the deployment definition we provide. The binary does have the following requirements, however:
- ONTAP 8.3 or later: needed for any ONTAP backends used by Trident.
- SolidFire Element OS 7 (Nitrogen) or later: needed for any SolidFire backends used by Trident.
- etcd v3.1.3 or later: Required, used to store metadata about the storage Trident manages. This is provided by the deployment definition.
- Kubernetes 1.4/OpenShift Enterprise 3.4/OpenShift Origin 1.4 or greater: Optional, but necessary for the integrations with Kubernetes. While Trident can be run independently and managed via its CLI or REST API, users will benefit the most from its functionality as an external provisioner for Kubernetes storage. This is required to use the Trident deployment defintion, the Trident launcher, and the installation script.
- Service accounts: To use the default pod and deployment definitions and for Trident to communicate securely with the Kubernetes API server, the Kubernetes cluster must have service accounts enabled. If they are not available, Trident can only communicate with the API server over the server's insecure port. See here for additional details on service accounts.
We provide several helper scripts for the REST API in scripts/. These
require:
- curl: Needed by all scripts for communicating with the API server.
- jq: Used by
json-get.shto pretty-print its output. - If used in Kubernetes, these scripts can automatically detect Trident's IP
address. Doing so is optional, but requires:
- kubectl: present in
$PATHand configured to connect to the Kubernetes API server. - The ability to access the Kubernetes cluster network from the host machine where the utilities are being run.
- kubectl: present in
Alternatively, these scripts are included in the main Trident image with all of their dependencies and can be run from within it. See the REST API section for more details.
SolidFire backends enable connectivity between host and Volume via Access Groups. These Groups must be created BEFORE creating volumes on the backend and must include the IQN's of the host that will mount Trident volumes. Each AccessGroup has allows a max of 64 initiator entries, so for deployments >64 you'll need to split up your initiators into groups of 64 and specify all of the groups that you configure (up to 4).
ONTAP SAN backends create LUNs using an iGroup named trident. The iGroup
must be created before creating volumes on the backend, and it must have the IQN of
each host that will mount Trident volumes mapped to it. ONTAP SAN backends
allow the administrator to specify a different iGroup for Trident to use (see
ONTAP Configurations for further details); any such
iGroup must also have the same hosts mapped into it. An example for how to
create an ONTAP SAN iGroup is available
here.
E-Series iSCSI backends create LUNs using a Host Group named trident. The Host
Group must contain a Host definition for each member of the cluster. Both the
Hosts and Host Group must exist before creating volumes on the backend.
While running Trident is generally straightforward, there are several parameters that need to be configured before it can be successfully launched. Using the Trident Launcher describes the Trident launcher utility, which comprises the easiest way to start Trident from a new deployment. Deploying As a Pod describes the necessary configuration when using the provided Kubernetes deployment definition, and Command-line Options describes the run-time flags available when launching it manually.
The Trident launcher, located in ./launcher, can be used to start a Trident
deployment, either for the first time or after shutting it down. When the
launcher starts, it checks whether a PVC named trident exists; if one does
not, it creates one and launches an ephemeral version of Trident that creates a
PV and backing volume for it. Once this is complete, it starts the Trident
deployment, using the PVC to store Trident's metadata. The launcher takes a
few parameters:
-backend: The path to a configuration file defining the backend on which the launcher should provision Trident's metadata volume. Defaults to/etc/config/backend.json.-deployment_file: The path to a Trident deployment definition, as described in Deploying As a Pod. Defaults to/etc/config/trident-deployment.yaml.-apiserver: The IP address and insecure port for the Kubernetes API server. Optional; if specified, the launcher uses this to communicate with the API server. If omitted, the launcher will assume it is being launched as a Kubernetes pod and connect using the service account for that pod.-volume_name: The name of the volume provisioned by launcher on the storage backend. If omitted, it defaults to "trident".-volume_size: The size of the volume provisioned by launcher in GB. If omitted, it defaults to 1GB.-pvc_name: The name of the PVC created by launcher. If omitted, it defaults to "trident".-pv_name: The name of the PV created by launcher. If omitted, it defaults to "trident".-trident_timeout: The number of seconds to wait before the launcher times out on a Trident connection. If omitted, it defaults to 10 seconds.-k8s_timeout: The number of seconds to wait before timing out on Kubernetes operations. If omitted, it defaults to 60 seconds.-debug: Optional; enables debugging output.
As with Trident itself, the launcher can be deployed as a pod using the
template provided in launcher/kubernetes-yaml/launcher-pod.yaml.templ;
substitute __IMAGE_NAME__ with netapp/trident-launcher, if using the
prebuilt version from Docker Hub, or the tag of a locally built image. The
template assumes that the backend and Trident deployment definitions will be
injected via a ConfigMap object with the following key-value pairs:
backend.json: the backend configuration file used by-backendtrident-deployment.yaml: the deployment definition file used by-deployment_file
The ConfigMap can be created by copying the backend and deployment definition
files to a directory and running kubectl create configmap trident-launcher-config --from-file <config-directory>, as described
here. Alternatively, the
Makefile contains targets that automate this; see
Building Trident.
To facilitate getting started with Trident, we offer
Trident installer bundle
containing an installation script, the deployment and pod definitions for
Trident, the Trident launcher, Trident CLI, and several sample input files for
Trident. Additionally, the installer bundle includes definitions for service
accounts, cluster roles, and cluster role bindings that are used by Trident
and Trident launcher. The main objective with the installer script is to have
a single script that configures Kubernetes or OpenShift deployments in the most
secure manner possible without requiring intimate knowledge of Kubernetes or
OpenShift internals. If you are deploying Trident in OpenShift, please make
sure oc is present in $PATH.
The install script requires a backend configuration named backend.json to be added to the
setup/ directory. Once this has been done, it will create the ConfigMap
described above using the files in setup/ and then launch the Trident
deployment. This script can be run from any directory and from any namespace.
$ ./install_trident.sh -h
Usage:
-n <namespace> Specifies the namespace for the Trident deployment; defaults to the current namespace.
-i Enables the insecure mode to disable RBAC configuration for Trident and Trident launcher.
-h Prints this usage guide.
Example:
./install_trident.sh -n trident Installs the Trident deployment in namespace "trident".It is highly recommended to run Trident in its own namespace
(./install_trident.sh -n trident) so that it is isolated from other
applications in the Kubernetes cluster. Otherwise, there is a risk of deletion
of Trident-provisioned volumes and disruption to provisioning operations.
If you are using the install script with Kubernetes 1.4, use the -i option due to lack of support for RBAC.
The uninstall script deletes almost all artifacts of the install script. This
script can be run from any directory and from any namespace. If you are
deploying Trident in OpenShift, please make sure oc is present in $PATH.
$ ./uninstall_trident.sh -h
Usage:
-n <namespace> Specifies the namespace for the Trident deployment; defaults to the current namespace.
-a Deletes almost all artifacts of Trident, including the PVC and PV used by Trident; however, it doesn't delete the volume used by Trident from the storage backend. Use with caution!
-h Prints this usage guide.
Example:
./uninstall_trident.sh -n trident Deletes artifacts of Trident from namespace "trident".The update script can be used to update or rollback container images in the Trident deployment.
$ ./update_trident.sh -h
Usage:
-n <namespace> Specifies the namespace for the Trident deployment; defaults to the current namespace.
-t <trident_image> Specifies the new image for the "trident-main" container in the Trident deployment.
-e <etcd_image> Specifies the new image for the "etcd" container in the Trident deployment.
-d <deployment> Specifies the name of the deployment; defaults to "trident".
-h Prints this usage guide.
Example:
./update_trident.sh -n trident -t netapp/trident:17.04.1 Updates the Trident deployment in namespace "trident" to use image "netapp/trident:17.04.1".We recommend deploying Trident as a pod in Kubernetes and, to this end, have
provided a PVC definition, kubernetes-yaml/trident-pvc.yaml, and a deployment
template, kubernetes-yaml/trident-deployment.yaml.templ, for doing so. The
PVC can be used as-is; however, the deployment template requires modification:
- Substitute
__TRIDENT_IMAGE__with the registry tag of a Trident image, eithernetapp/tridentor the tag for a locally built image.make podwill do this automatically. - If the Kubernetes cluster does not have service accounts enabled, configure
direct HTTP access to the API Server:
- Comment out line 20 (
-k8s-pod) and remove the comments from lines 21 (-k8s-apiserver) and 22. - Replace
__KUBERNETES_SERVER__with the IP address or DNS name of the Kubernetes API server. - Replace
__KUBERNETES_PORT__with its insecure port. Note that we do not currently support TLS connections that do not use service accounts.
- Comment out line 20 (
Once the deployment definition is properly configured, ensure that a Trident image has been created and pushed to your local registry. Then, create the PVC:
kubectl create -f kubernetes-yaml/trident-pvc.yamlOnce the PVC is bound (this may require setting up an initial PV and backing storage), start Trident with
kubectl create -f <deployment-file>where <deployment-file> is the configured deployment definition. The pod in
the deployment contains an etcd instance that stores its data in the
PVC, providing everything that is necessary for Trident to run.
Note that these steps are unnecessary when using the
launcher, as it automates them. The install
script uses default templates for the Trident deployment; however, should you
wish to use direct HTTP access, you can modify the template as described above
and run one of the Makefile targets for the launcher (make launch if using
default images, or make build_and_launch if building your own).
Trident exposes a number of command line options. These are as follows:
-etcd_v2 <address>: Required; use this to specify the etcd v2 deployment that Trident should use.-k8s_pod: Optional; however, either this or-k8s_api_servermust be set to enable Kubernetes support. Setting this will cause Trident to use its containing pod's Kubernetes service account credentials to contact the API server. This only works when Trident runs as a pod in a Kubernetes cluster with service accounts enabled.-k8s_api_server <insecure-address:insecure-port>: Optional; however, either this or-k8s_podmust be to enable Kubernetes support. When specified, Trident will connect to the Kubernetes API server using the provided insecure address and port. This allows Trident to be deployed outside of a pod; however, it only supports insecure connections to the API server. To connect securely, deploy Trident in a pod with the-k8s_podoption.-address <ip-or-host>: Optional; specifies the address on which Trident's REST server should listen. Defaults to localhost. When listening on localhost and running inside a Kubernetes pod, the REST interface will not be directly accessible from outside the pod. Use '-address ""' to make the REST interface accessible from the pod IP address.-port <port-number>: Optional; specifies the port on which Trident's REST server should listen. Defaults to 8000.-debug: Optional; enables debugging output.
Once Trident is installed and running, it can be managed directly via the tridentctl CLI or the Trident REST API, and indirectly via interactions with Kubernetes. These interfaces allow users and administrators to create, view, update, and delete the objects that Trident uses to abstract storage. This section explains the objects and how they are configured, and then provides details on how to use the two interfaces to manage them.
Trident keeps track of four principal object types: backends, storage pools, storage classes, and volumes. This section provides a brief overview of each of these types and the function they serve.
-
Backends: Backends represent the storage providers on top of which Trident provisions volumes; a single Trident instance can manage any number of backends. Trident currently supports ONTAP, SolidFire, and E-Series backends.
-
Storage Pools: Storage pools represent the distinct locations available for provisioning on each backend. For ONTAP, these correspond to aggregates in SVMs; for SolidFire, these correspond to admin-specified QoS bands. Each storage pool has a set of distinct storage attributes, which define its performance characteristics and data protection characteristics.
Unlike the other object types, which are registered and described by users, Trident automatically detects the storage pools available for a given backend. Users can inspect the attributes of a backend's storage pools via the tridentctl CLI or the REST interface, as described in the REST API section. Storage attributes describes the different storage attributes that can be associated with a given storage pool.
-
Storage Classes: Storage classes comprise a set of performance requirements for volumes. Trident matches these requirements with the attributes present in each storage pool; if they match, that storage pool is a valid target for provisioning volumes using that storage class. In addition, storage classes can explicitly specify storage pools that should be used for provisioning. In Kubernetes, these correspond directly to
StorageClassobjects.Storage Class Configurations describes how these storage classes are configured and used. Matching Storage Attributes goes into more detail on how Trident matches the attributes that storage classes request to those offered by storage pools. Finally, Storage Classes discusses how Trident storage classes can be created via Kubernetes
StorageClasses. -
Volumes: Volumes are the basic unit of provisioning, comprising backend endpoints such as NFS shares and iSCSI LUNs. In Kubernetes, these correspond directly to
PersistentVolumes. Each volume must be created with a storage class, which determines where that volume can be provisioned, along with a size. The desired type of protocol for the volume--file or block--can either be explicitly specified by the user or omitted, in which case the type of protocol will be determined by the backend on which the volume is provisioned.We describe these parameters further in Volume Configurations and discuss how to create them using
PersistentVolumeClaimsin Kubernetes in Volumes.
Each of the user-manipulable API objects (backends, storage classes, and volumes) is defined by a JSON configuration. These configurations can either be implicitly created from Kubernetes API objects or they can be posted to the Trident REST API to create objects of the corresponding types. This section describes these configurations and their attributes; we discuss how configurations are created from Kubernetes objects in the Kubernetes API section.
Backend configurations define the parameters needed to connect to and provision volumes from a specific backend. Some of these parameters are common across all backends; however, each backend has its own set of proprietary parameters that must be configured separately. Thus, separate configurations exist for each backend type. In general, these correspond to those used by the nDVP.
This backend provides connection data for ONTAP backends. Separate backends must be created for NAS and SAN.
IMPORTANT NOTE
Use of Kubernetes 1.5 (or OpenShift 3.5) or earlier with the iSCSI protocol and ONTAP is not recommended. See caveats for more information.
| Attribute | Type | Required | Description |
|---|---|---|---|
| version | int | No | Version of the nDVP API in use. |
| storageDriverName | string | Yes | Must be either "ontap-nas" or "ontap-san". |
| storagePrefix | string | No | Prefix to prepend to volumes created on the backend. The format of the resultant volume name will be <prefix>_<volumeName>; this prefix should be chosen so that volume names are unique. If unspecified, this defaults to trident. |
| managementLIF | string | Yes | IP address of the cluster or SVM management LIF. |
| dataLIF | string | Yes | IP address of the SVM data LIF to use for connecting to provisioned volumes. |
| igroupName | string | No | iGroup to add all provisioned LUNs to. If using Kubernetes, the iGroup must be preconfigured to include all nodes in the cluster. If empty, defaults to trident. |
| svm | string | Yes | SVM from which to provision volumes. |
| username | string | Yes | Username for the provisioning account. |
| password | string | Yes | Password for the provisioning account. |
Any ONTAP backend must have one or more aggregates assigned to the configured SVM.
ONTAP 9.0 or later backends may operate with either cluster- or SVM-scoped credentials. ONTAP 8.3 backends must be configured with cluster-scoped credentials; otherwise Trident will still function but will be unable to discover physical attributes such as the aggregate media type. In all cases, Trident may be configured with a limited user account that is restricted to only those APIs used by Trident.
Any ONTAP SAN backend must have either an iGroup named trident or an iGroup
corresponding to the one specified in igroupName. The IQNs of all hosts that
may mount Trident volumes (e.g., all nodes in the Kubernetes cluster that
Trident monitors) must be mapped into this iGroup. This must be configured
before these hosts can mount and attach Trident volumes from this backend.
sample-input/backend-ontap-nas.json provides an example of an ONTAP NAS
backend configuration. sample-input/backend-ontap-san.json and
sample-input/backend-ontap-san-full.json provide the same for an ONTAP SAN
backend; the latter includes all available configuration options.
This backend configuration provides connection data for SolidFire iSCSI deployments.
| Attribute | Type | Required | Description |
|---|---|---|---|
| version | int | No | Version of the nDVP API in use |
| storageDriverName | string | Yes | Must be "solidfire-san" |
| storagePrefix | string | No | Prefix to prepend to created volumes on the backend. The format of the resultant volume name will be <prefix>-<volumeName>; this prefix should be chosen so that volume names are unique. If unspecified, this defaults to trident. |
| TenantName | string | Yes | Tenant name for created volumes. |
| EndPoint | string | Yes | Management endpoint for the SolidFire cluster. Should include username and password (e.g., https://user@password:sf-address/json-rpc/7.0). |
| SVIP | string | Yes | SolidFire SVIP (IP address for iSCSI connections). |
| InitiatorIFace | string | No | ISCI interface to use for connecting to volumes via Kubernetes. Defaults to "default" (TCP). |
| Types | VolType array | No | JSON array of possible volume types. Each of these will be created as a StoragePool for the SolidFire backend. See below for the specification. |
Any SolidFire backend must have a VAG named trident with the IQN of each host
that may mount Trident volumes (e.g., all hosts in the Kubernetes cluster that
Trident manages) mapped into it. This must be configured before hosts can
attach and mount any volumes provisioned from the backend.
We provide an example SolidFire backend configuration under
sample-input/backend-solidfire.json.
VolType associates a set of QoS attributes with volumes provisioned on SolidFire. This is only used in the Types array of a SolidFire configuration.
| Attribute | Type | Required | Description |
|---|---|---|---|
| Type | string | Yes | Name for the VolType. |
| Qos | Qos | Yes | QoS descriptor for the VolType. |
Qos defines the QoS IOPS for volumes provisioned on SolidFire. This is only used within the QoS attribute of each VolType as part of a SolidFire configuration.
| Attribute | Type | Required | Description |
|---|---|---|---|
| minIOPS | int64 | No | Minimum IOPS for provisioned volumes. |
| maxIOPS | int64 | No | Maximum IOPS for provisioned volumes. |
| burstIOPS | int64 | No | Burst IOPS for provisioned volumes. |
This backend provides connection data for E-Series iSCSI backends.
IMPORTANT NOTE
Use of Kubernetes 1.5 (or OpenShift 3.5) or earlier with the iSCSI protocol and E-Series is not recommended. See caveats for more information.
| Attribute | Type | Required | Description |
|---|---|---|---|
| version | int | No | Version of the nDVP API in use. |
| storageDriverName | string | Yes | Must be "eseries-iscsi". |
| controllerA | string | Yes | IP address of controller A. |
| controllerB | string | Yes | IP address of controller B. |
| hostDataIP | string | Yes | Host iSCSI IP address (if multipathing choose either one). |
| username | string | Yes | Username for Web Services Proxy. |
| password | string | Yes | Password for Web Services Proxy. |
| passwordArray | string | Yes | Password for storage array (if set). |
| webProxyHostname | string | Yes | Hostname or IP address of Web Services Proxy. |
| webProxyPort | string | No | Port number of the Web Services Proxy. |
| webProxyUseHTTP | bool | No | Use HTTP instead of HTTPS for Web Services Proxy. |
| webProxyVerifyTLS | bool | No | Verify server's certificate chain and hostname. |
| poolNameSearchPattern | string | No | Regular expression for matching storage pools available for Trident volumes (default = .+). |
The IQNs of all hosts that may mount Trident volumes (e.g., all nodes in the Kubernetes cluster that Trident monitors) must be defined on the storage array as Host objects in the same Host Group. Trident assigns LUNs to the Host Group, so that they are accessible by each host in the cluster. The Hosts and Host Group must exist before using Trident to provision storage.
sample-input/backend-eseries-iscsi.json provides an example of an E-Series backend configuration.
A volume configuration defines the properties that a provisioned volume should have. Unlike backends, these are, for the most part, platform-agnostic. Volume configurations are unique to Trident and are unused in the nDVP.
| Attribute | Type | Required | Description |
|---|---|---|---|
| version | string | No | Version of the Trident API in use. |
| name | string | Yes | Name of volume to create. |
| storageClass | string | Yes | Storage Class to use when provisioning the volume. |
| size | string | Yes | Size of the volume to provision. |
| protocol | string | No | Class of protocol to use for the volume. Users can specify either "file" for file-based protocols (currently NFS) or "block" for SAN protocols (currently iSCSI). If omitted, Trident will use either. |
| internalName | string | No | Name of volume to use on the backend. This will be generated by Trident when the volume is created; if the user specifies something in this field, Trident will ignore it. Its value is reported when GETing the created volume from the REST API, however. |
| snapshotPolicy | string | No | For ONTAP backends, specifies the snapshot policy to use. Ignored for SolidFire and E-Series. |
| exportPolicy | string | No | For ONTAP backends, specifies the export policy to use. Ignored for SolidFire and E-Series. |
| snapshotDirectory | bool | No | For ONTAP backends, specifies whether the snapshot directory should be visible. Ignored for SolidFire and E-Series. |
| unixPermissions | string | No | For ONTAP backends, initial NFS permissions to set on the created volume. Ignored for SolidFire and E-Series. |
As mentioned, Trident generates internalName when creating the volume. This
consists of two steps. First, it prepends the storage prefix--either the
default, trident, or the prefix specified for the chosen backend--to the
volume name, resulting in a name of the form <prefix>-<volume-name>. It then
proceeds to sanitize the name, replacing characters not permitted in the
backend. For ONTAP backends, it replaces hyphens with underscores (thus, the
internal name becomes <prefix>_<volume-name>), and for SolidFire, it replaces
underscores with hyphens. For E-Series, which imposes a 30-character limit on
all object names, Trident generates a random string for the internal name of each
volume on the array; the mappings between names (as seen in Kubernetes) and the
internal names (as seen on the E-Series storage array) may be obtained via the
Trident CLI or REST interface.
See sample-input/volume.json for an example of a basic volume configuration
and sample-input/volume-full.json for a volume configuration with all options
specified.
Storage class configurations define the parameters for a storage class. Unlike the other configurations, which are fairly rigid, storage class configurations consist primarily of a collection of requests of specific storage attributes from different backends. The specification for both storage classes and requests follows below.
| Attribute | Type | Required | Description |
|---|---|---|---|
| version | string | No | Version of the Trident API in use. |
| name | string | Yes | Storage class name. |
| attributes | map[string]string |
No | Map of attribute names to requested values for that attribute. These attribute requests will be matched against the offered attributes from each backend storage pool to determine which targets are valid for provisioning. See Storage Attributes for possible names and values, and Matching Storage Attributes for a description of how Trident uses them. |
| requiredStorage | map[string]StringList |
No | Map of backend names to lists of storage pool names for that backend. Storage pools specified here will be used by this storage class regardless of whether they match the attributes requested above. |
See sample-input/storage-class-bronze.json for an example of a storage class
configuration.
Storage attributes are used in the attributes field of storage class configurations, as described above; they are also associated with offers reported by storage pools. Although their values are specified as strings in storage class configurations, each attribute is typed, as described below; failing to conform to the type will cause an error. The current attributes and their possible values are below:
| Attribute | Type | Values | Description for Offer | Description for Request |
|---|---|---|---|---|
| media | string | hdd, hybrid, ssd | Type of media used by the storage pool. Hybrid indicates both HDD and SSD. | Type of media desired for the volume. |
| provisioningType | string | thin, thick | Types of provisioning supported by the storage pool. | Whether volumes will be created with thick or thin provisioning. |
| backendType | string | ontap-nas, ontap-san, solidfire-san, eseries-iscsi | Backend to which the storage pool belongs. | Specific type of backend on which to provision volumes. |
| snapshots | bool | true, false | Whether the backend supports snapshots. | Whether volumes must have snapshot support. |
| IOPS | int | positive integers | IOPS range the storage pool is capable of providing. | Target IOPS for the volume to be created. |
Each storage pool on a storage backend will specify one or more storage attributes as offers. For boolean offers, these will either be true or false; for string offers, these will consist of a set of the allowable values; and for int offers, these will consist of the allowable integer range. Requests use the following rules for matching: string requests match if the value requested is present in the offered set and int requests match if the requested value falls in the offered range. Booleans are slightly more involved: true requests will only match true offers, while false requests will match either true or false offers. Thus, a storage class that does not require snapshots (specifying false for the snapshot attribute) will still match backends that provide snapshots.
In most cases, the values requested will directly influence provisioning; for instance, requesting thick provisioning will result in a thickly provisioned volume. However, a SolidFire storage pool will use its offered IOPS minimum and maximum to set QoS values, rather than the requested value. In this case, the requested value is used only to select the storage pool.
Trident includes a command-line utility, tridentctl, that provides simple
access to Trident, even if Trident is running inside a pod. Kubernetes users
with sufficient privileges to manage the namespace that contains the Trident
pod may use tridentctl. The tridentctl utility can add storage backends, and
it can list and remove backends, storage classes, and volumes. You can get
more information by running tridentctl --help.
While tridentctl is the preferred method of interacting with Trident, and
Trident's REST API is not exposed by default when running inside a pod,
Trident exposes all of its functionality through a REST API with endpoints
corresponding to each of the user-controlled object types (i.e., backend,
storageclass, and volume) as well as a version endpoint for retrieving
Trident's version. The API works as follows:
GET <trident-address>/trident/v1/<object-type>: Lists all objects of that type.GET <trident-address>/trident/v1/<object-type>/<object-name>: Gets the details of the named object.POST <trident-address>/trident/v1/<object-type>: Creates an object of the specified type. Requires a JSON configuration for the object to be created; see the previous section for the specification of each object type. If the object already exists, behavior varies: backends update the existing object, while all other object types will fail the operation.DELETE <trident-address>/trident/v1/<object-type>/<object-name>: Deletes the named resource. Note that volumes associated with backends or storage classes will continue to exist; these must be deleted separately. See the section on backend deletion below.
Trident provides helper scripts under the scripts/ directory for each of
these verbs. These scripts automatically attempt to discover Trident's IP
address, using kubectl and docker commands to attempt to get Trident's IP
address. Users can also specify Trident's IP address by setting $TRIDENT_IP,
bypassing the discovery process; this may be useful if running Trident as a
binary or if users need to access it from a Kubernetes Ingress endpoint. All
scripts assume Trident listens on port 8000. These scripts are as follows:
-
get.sh <object-type> <object-name>: If<object-name>is omitted, lists all objects of that type. If<object-name>is provided, it describes the details of that object. Wrapper for GET. Sample usage:./scripts/get.sh backend
-
json-get.sh <object-type> <object-name>: Asget.sh, but pretty-prints the output JSON. Requires Python. Sample usage:./scripts/json-get.sh backend ontapnas_10.0.0.1
-
post.sh <object-type>: POSTs a JSON configuration provided on stdin for an object of type<object-type>. Wrapper for POST. Sample usage:cat storageclass.json | ./scripts/post.sh storageclass -
delete.sh <object-type> <object-name>: Deletes the named object of the specified type. Wrapper for DELETE. Sample usage:./scripts/delete.sh volume vol1
All of these scripts are included in the Trident Docker image and can be executed within it. For example, to view the bronze storage class when Trident is deployed in a Kubernetes pod, use
kubectl exec <trident-pod-name> -- get.sh storageclass <bronze>where <trident-pod-name> is the name of the pod containing Trident.
To register a new backend, use
cat backend.json | kubectl exec -i <trident-pod-name> -- post.sh backendUnlike the other API objects, a DELETE call for a backend does not immediately
remove that backend from Trident. Volumes may still exist for that backend,
and Trident must retain metadata for the backend in order to delete those
volumes at a later time. Instead of removing the backend from Trident's
catalog, then, a DELETE call on a backend causes Trident to remove that
backend's storage pools from all storage classes and mark the backend offline
by setting online to false. Once offline, a backend will never be reported
when listing the current backends, nor will Trident provision new volumes atop
it. GET calls for that specific backend, however, will still return its
details, and its existing volumes will remain. Trident will fully delete the
backend object only once its last volume is deleted.
Trident also translates Kubernetes objects directly into its internal objects
as part of its dynamic provisioning capabilities. Specifically, it creates
storage classes to correspond to Kubernetes
StorageClasses,
and it manages volumes based on user interactions with
PersistentVolumeClaims
(PVCs) and
PersistentVolumes
(PVs).
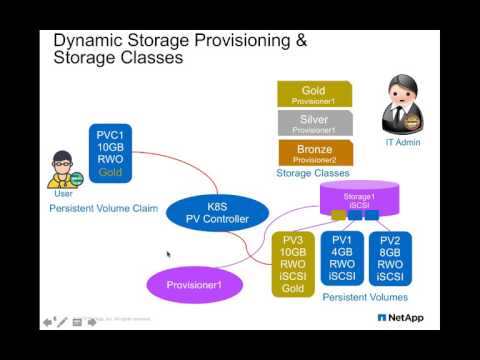
Trident creates matching storage classes for Kubernetes StorageClass objects
that specify netapp.io/trident in their provisioner field. The storage
class's name will match that of the StorageClass, and the parameters will
be parsed as follows, based on their key:
requiredStorage: This corresponds to the requiredStorage parameter for storage classes and consists of a semi-colon separated list. Each entry is of the form<backend>:<storagePoolList>, where<storagePoolList>is a comma-separated list of storage pools for the specified backend. For example, a value for requiredStorage might look likeontapnas_192.168.1.100:aggr1,aggr2;solidfire_192.168.1.101:bronze-type. See Storage Class Configurations for a description of this parameter.<RequestName>: Any other parameter key is interpreted as the name of a request, with the request's value corresponding to that of the parameter. Thus, a request for HDD provisioning would have the keymediaand valuehdd. Requests can be any of the storage attributes described in the storage attributes section.
Deleting a Kubernetes StorageClass will cause the corresponding Trident
storage class to be deleted as well.
We provide an example StorageClass definition for use with Trident in
sample-input/storage-class-bronze.yaml
Trident follows the proposal for external Kubernetes Dynamic Provisioners found
here.
Thus, when a user creates a PVC that refers to a Trident-based StorageClass,
Trident will provision a new volume using the corresponding storage class and
register a new PV for that volume. In configuring the provisioned volume and
corresponding PV, Trident follows the following rules:
- The volume name (and thus, the PV name) takes the form
<PVC-namespace>-<PVC-name>-<uid-prefix>, where<uid-prefix>consists of the first five characters of the PVC's UID. For example, a PVC namedsql-01with a UID starting withaa9e7c4c-created in thedefaultnamespace would receive a volume and PV nameddefault-sql-01-aa9e7. - The size of the volume matches the requested size in the PVC as closely as possible, though it may be rounded up to the nearest allocatable quantity, depending on the platform.
- The specified AccessMethods on the PVC determine the protocol type that the volume will use: ReadWriteMany and ReadOnlyMany PVCs will only receive file-based volumes, while ReadWriteOnce PVCs may also receive block-based volumes. This may be overridden by explicitly specifying the protocol in an annotation, as described below.
- Other volume configuration parameters can be specified using the following PVC annotations:
| Annotation | Volume Parameter |
|---|---|
trident.netapp.io/protocol |
protocol |
trident.netapp.io/exportPolicy |
exportPolicy |
trident.netapp.io/snapshotPolicy |
snapshotPolicy |
trident.netapp.io/snapshotDirectory |
snapshotDirectory |
trident.netapp.io/unixPermissions |
unixPermissions |
The reclaim policy for the created PV can be determined by setting the
annotation trident.netapp.io/reclaimPolicy in the PVC to either Delete or
Retain; this value will then be set in the PV's ReclaimPolicy field. When
the annotation is left unspecified, Trident will use the Delete policy. If
the created PV has the Delete reclaim policy, Trident will delete both the PV
and the backing volume when the PV becomes released (i.e., when the user
deletes the PVC). Should the delete action fail, Trident will mark the PV
failed and periodically retry the operation until it succeeds or the PV is
manually deleted. If the PV uses the Retain policy, Trident ignores it and
assumes the administrator will clean it up from Kubernetes and the backend,
allowing the volume to be backed up or inspected before its removal. Note that
deleting the PV will not cause Trident to delete the backing volume; it must be
removed manually via the REST API.
sample-input/pvc-basic.yaml and sample-input/pvc-full.yaml contain examples
of PVC definitions for use with Trident. See Volume
Configurations for a full description of the
parameters and settings associated with Trident volumes.
Provisioning in Trident has two primary phases. The first of these associates a storage class with the set of suitable backend storage pools and occurs as a necessary preparation before provisioning. The second encompasses the volume creation itself and requires choosing a storage pool from those associated with the pending volume's storage class. This section explains both of these phases and the considerations involved in them, so that users can better understand how Trident handles their storage.
Associating backend storage pools with a storage class relies on both the
storage class's requested attributes and its requiredStorage list. When a user
creates a storage class, Trident compares the attributes offered by each of its
backends to those requested by the storage class. If a storage pool's
attributes match all of the requested attributes, Trident adds that storage
pool to the set of suitable storage pools for that storage class. In addition,
Trident adds all storage pools listed in the requiredStorage list to that
set, even if their attributes do not fulfill all or any of the storage classes
requested attributes. Trident performs a similar process every time a user
adds a new backend, checking whether its storage pools satisfy those of the
existing storage classes and whether any of its storage pools are present in
the requiredStorage list of any of the existing storage classes.
Trident then uses the associations between storage classes and storage pools to determine where to provision volumes. When a user creates a volume, Trident first gets the set of storage pools for that volume's storage class, and, if the user specifies a protocol for the volume, it removes those storage pools that cannot provide the requested protocol (a SolidFire backend cannot provide a file-based volume while an ONTAP NAS backend cannot provide a block-based volume, for instance). Trident randomizes the order of this resulting set, to facilitate an even distribution of volumes, and then iterates through it, attempting to provision the volume on each storage pool in turn. If it succeeds on one, it returns successfully, logging any failures encountered in the process. Trident returns a failure if and only if it fails to provision on all of the storage pools available for the requested storage class and protocol.
- If Trident launcher fails during install, you should inspect the logs via
kubectl logs trident-launcher. The log may prompt you to inspect the logs for the trident-ephemeral pod or take other corrective measures. kubectl logs <trident-pod-name> -c trident-mainshows the logs for the Trident pod. Trident is operational once you see"trident bootstrapped successfully."In the absence of any errors in the log, it would be helpful to inspect the logs for the etcd container:kubectl logs <trident-pod-name> -c etcd.- ONTAP backends will ignore anything specified in the aggregate parameter of the configuration.
- If service accounts are not available,
kubectl logs trident -c trident-mainwill report an error that/var/run/secrets/kubernetes.io/serviceaccount/tokendoes not exist. In this case, you will either need to enable service accounts or connect to the API server using the insecure address and port, as described in Command-line Options. - The Uninstall Script can help with cleaning up the state after a failure.
Trident is in an early stage of development, and thus, there are several outstanding issues to be aware of when using it:
- Due to known issues in Kubernetes 1.5 (or OpenShift 3.5) and earlier, use of iSCSI with ONTAP or E-Series in production deployments is not recommended. See Kubernetes issues #40941, #41041 and #39202. ONTAP NAS and SolidFire are unaffected. These issues are fixed in Kubernetes 1.6.
- Although we provide a deployment for Trident, it should never be scaled beyond a single replica. Similarly, only one instance of Trident should be run per cluster. Trident cannot communicate with other instances and cannot discover other volumes that they have created, which will lead to unexpected and incorrect behavior if more than one instance runs within a cluster.
- Volumes and storage classes created in the REST API will not have
corresponding objects (PVCs or
StorageClasses) created in Kubernetes; however, storage classes created viatridentctlor the REST API will be usable by PVCs created in Kubernetes. - If Trident-based
StorageClassobjects are deleted from Kubernetes while Trident is offline, Trident will not remove the corresponding storage classes from its database when it comes back online. Any such storage classes must be deleted manually usingtridentctlor the REST API. - If a user deletes a PV provisioned by Trident before deleting the
corresponding PVC, Trident will not automatically delete the backing volume.
In this case, the user must remove the volume manually via
tridentctlor the REST API. - Trident will not boot unless it can successfully communicate with an etcd instance. If it loses communication with etcd during the bootstrap process, it will halt; communication must be restored before Trident will come online. Once fully booted, however, etcd outages should not cause Trident to crash.
- When using a backend across multiple Trident instances, it is recommended that each backend configuration file specifies a different storagePrefix value. Trident cannot detect volumes that other instances of Trident has created, and attempting to create an existing volume on either ONTAP or SolidFire backends succeeds as Trident treats volume creation as an idempotent operation. Thus, if the storagePrefixes do not differ, there is a very slim chance to have name collisions for volumes created on the same backend.