Visual speech recognition, or more commonly known as lip reading, is the task of perceiving speech solely from the visual information of the speaker. Speech itself is auditory in nature. Trying to perceive this through just vision alone makes this task extremely difficult, with many deaf people refusing to learn due to its extreme difficulty. Ques provided by the speaker’s mouth, teeth, tongue, and even facial muscles all help in lipreading.
This task lies at the intersection of both computer vision and NLP. As such, the system in question will be bringing together architectures from both these fields in an end-to-end neural network. The proposed architecture is shown below. This model consists of 3 stages; the 3D CNN front-end, the ResNet-18 feature extractor, and the seq2seq back-end. Implementation of this model is done in Python through the PyTorch library.

For the training and testing of this model, the LRS2 dataset has been used which consists of 144,482 video clips from the BBC, with each video clip being one spoken sentence. The video clips also come with audio files, but for the purposes of this study they shall not be used. Since each clip is taken directly from real world broadcasts there is a lot of natural variation in the data distribution. Training our model on LRS2 generates a lipreadiing system capible of generalising well to the real world. To access the dataset a special request must be sent to Rob Cooper at the BBC.
Training lipreading models is very hard so to combat this some techniques are employed to help training:
- Teacher force ratio is used to send the actual target token as the next input to the decoder instead of the previous prediction
- Curriculum learning is used such that the number of words per video clip increases with the next currriculum
- Freezing of layers is used in the middle ResNet-18 layers to speed up training
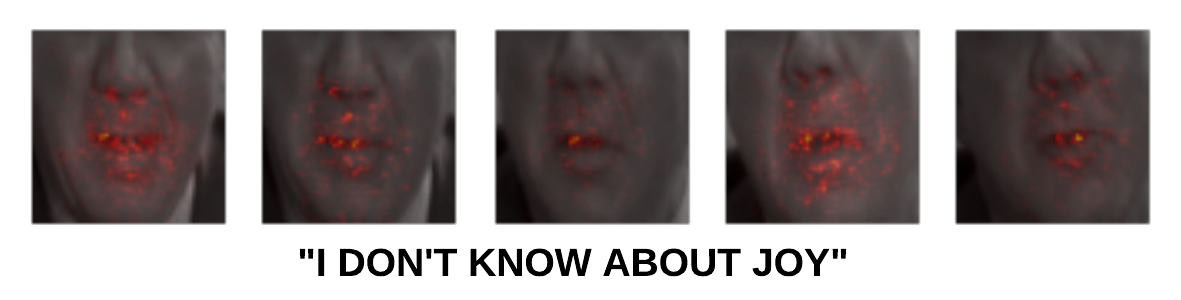
The model proposed yields a WER of 86.26% and a CER of 81.44% on the LRS2 dataset. This indicates there is room for improvment in some of the modules. Below are some visualisations of the training curves and saliency maps produced by the model.

Data: Contains custom made dataset class with accompanying data loader for the LRS2 dataset
Model Modules: Contains all modules used to build the model (3D CNN, ResNet-18, encoder-decoder)
Final Model: Contains the final model class, load this to get the model used in the paper
Training: Contains the curriculum and full training loops used
Testing: Contains file to calculate test WER/CER and also code to produce saliency maps plots and loss plots
Utils: Contains miscellaneous processing functions to be used on model predictions and text
To use the model only the Data, Model Modules, and Final Model files are required. However, to train and test the model, all files are required.