By Joël Thieffry, under MIT licence.
This Greasemonkey script adds Instant Search function to Javadoc class frame.
{kind=link}
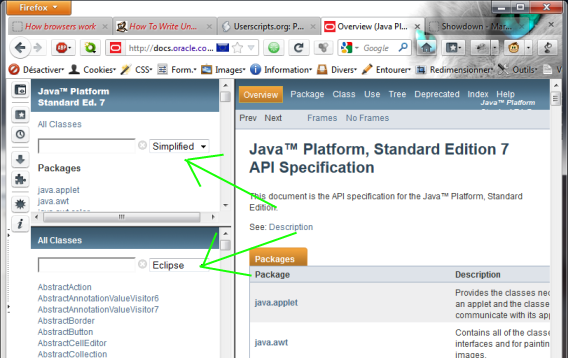
- Three search pattern modes (choose in the selector):
- Eclipse: search around capitals, for exemple
NPExceptionwill showNullPointerException(as in the Eclipse IDE Java's type search). - Simplified:
?to replace one character,*to replace any number of characters, for exampleN???P*Exception. - Regex: for real men, use a plain regex here, for example
^.*C(li)*p+$. - Pattern background becomes:
- white if no pattern;
- blue if active pattern;
- red if error in pattern.
- Button to erase pattern.
- from the Userscripts page
- directly from my website
- fork it from the GitHub page
For use in Mozilla Firefox, you need to install the Greasemonkey plugin. Unless the variable greasemonkey.fileIsGreaseable is set to true in your about:config, the script won't run on local files.
In Google Chrome, userscripts support is native since Chrome v4.
Released 0.5 (2012/11/17)
- Fixed: Issue #1 Incorrect search on doubles. The real reason was a side effect of regex reuse, see Regex/lastIndex - Unexpected behaviour on StackOverflow.
Released 0.4 (2012/04/23)
- Fixed: heavy DOM manipulation caused massive slowdown and even stalled and crashed Google Chrome. As a side effect, also improved browser response.
- Fixed: regexes (improper escaping and bad patterns).
- Modified: Eclipse and Simplified search pattern modes are case-insensitive (as I found in Eclipse IDE).
- Modified: code checked through the excellent JSHint.
Released 0.3 (2012/04/10)
- Added: support for old javadoc versions (see Implementation details).
- Fixed: minor fixes (set focus on startup only if successfully installed; new filename pattern).
Released 0.2 (2012/04/05)
- Fixed: simplified pattern mode was wrong interpreting
?as "0 or 1 any character" instead of "1 any character". - Added: 200-millisecond delay between input in pattern box and search run; this improves responsiveness while typing a pattern.
- Added: clicking on erase, or selecting of regex type, will then set focus on the pattern box.
Released 0.1 (2012/04/03)
- Initial version, written minimal documentation, uploaded to [userscripts.org][Userscripts] page.
I've just learned Javascript and DOM, this script is my first attempt to use it. I wanted to implement the efficient Eclipse search inside Javadoc.
There were three goals:
- A userscript for Greasemonkey plugin : done.
- A doclet extension: can't be done because a new doclet can't reuse standard doclet mecanism.
- A tool to insert the userscript into generated Javadoc : to be done.
Later, I found KOSEKI Kengo's script named Javadoc Incremental Search. This code and webpage inspired me (for example the embedded erase icon comes directly from it), but my implementation is really different: my code is simpler because it does less things.
-
I've found two formats of generated javadoc:
-
The modern hierarchy:
html head body h1 (title) div class="indexContainer" ul (one for interfaces, one for classes) li a (for every item) ... -
The old hierarchy:
HTML HEAD BODY FONT B (title) BR TABLE TR TD FONT A BR (for every item)
Given a corresponding page filename, if we find a div whose class is
indexContainerthen the modern hierarchy is assumed, otherwise we choose the old hierarchy (which is supported from v0.3). -
-
The search component is a paragraph whose id is
javadocInstantSearchElement. This id is looked for to avoid reinstalling the search component. -
The search component is added as a first child of the element whose class is
indexContainer. -
The regex transformation from Eclipse model to full regex follows these steps:
- Neutralize all special caracters:
regex.replace(/([\\\^\$*+\[\]?{}.=!:(|)])/g, "\\$1"). - Prepend
^.*and append.*$to allow search in any position. - Prepend
.*before all capital letters:regex.replace(/([A-Z])/g, "\.\*$1").
-
All regexes are simplified using the following replaces:
regex = regex.replace(/((.[\*\?])+)(?=\2)/g, "") // Replace successive x* and x? to only one .replace(/((.)\*\2\?)+/g, ".*") // Replace x*x? with x* .replace(/((.)\?\2\*)+/g, ".*") // Replace x?x* with x* .replace(/((.)\+\2\*)+/g, ".+") // Replace x+x* with x+ .replace(/((.)\*\2\+)+/g, ".+") // Replace x*x+ with x+ .replace(/((.[\*\?])+)(?=\2)/g, ""); // Replace successive x* and x? to only one