Welcome to prr - The Prompt Runner!
prr is a simple toolchain designed to help you run prompts across multiple Large Language Models (LLMs), whether they are hosted locally or accessible through APIs. Easily refine your parameters, prompts and model choices to achieve the best results while iterating smoothly with a quick feedback loop.
prr is released as an open-source project under the MIT License.
Made by Forward Operators. We work on LLM and ML-related projects with some awesome human beings and cool companies.
Everyone is welcome to contribute!
prr is in very early stages of development, so things might still change unexpectedly or explode embarrasingly.
- Command-line execution of prompts (now with web UI!)
- Quick iteration on prompt design and paramter refinement with
watchcommand - YAML configuration ties prompts to models and their configurations
- Write prompt-scripts with #!/usr/bin/prr shebang and execute them directly
- All prompts can optionally use templating language (Jinja) for flow control, partials and others
- Execute multiple models, or configurations against the same prompt
- Expandable to other LLM providers (current integrations are <100 lines of code each)
- Each prompt run across models gives you stats on model response times and token counts used to work across performance, quality and cost factors
- Each prompt run is recorded in detail for later analysis including raw rendered prompt and raw completion
As this is early stage work, there's lots improvements that can be done in the future and you're welcome to contribute!
- Get rix of Python 3.10 dependency
- Clean basic code smells
- Improve support for OpenAI and Anthropic
- Add support for other LLM providers
- Add support for locally hosted models
- Pass model-related options to templating engine to allow for model-specific prompts
- Add support for testing against expectations (elapsed_time, tokens_used)
- Build interface to extract stats from subsequent runs for later analysis
- Add support for chat structure in prompts using YAML
- Integrate Jinja as templating language for prompts
- Make dependency files for Jinja subtemplates are tracked in watch command
- #!/usr/bin/prr shebang support for executable prompts
- More output modalities (audio, image, video)
- Support different text output formats (json, markdown, code, etc.)
- Diff command to compare differences in output on subsequent runs
- Support evaluating prompt outputs for quality by LLMs themselves
- Support for streaming responses
- Support for running prompts in parallel
- Support for calculating pricing for prompts based on defined pricelist
- Allow for specifying how many times to run each service to ensure statistically relevant-ish performance results
- Prompt fine-tuning tooling
- Support multiple completions
- Support
.envfile for configuration from current directory (or any other as--configoption)
Here's a quick run through on what you need to know to use prr effectively.
Start with our video guides, or follow detailed manual below.
Install prr and set up the API keys as well as default options.
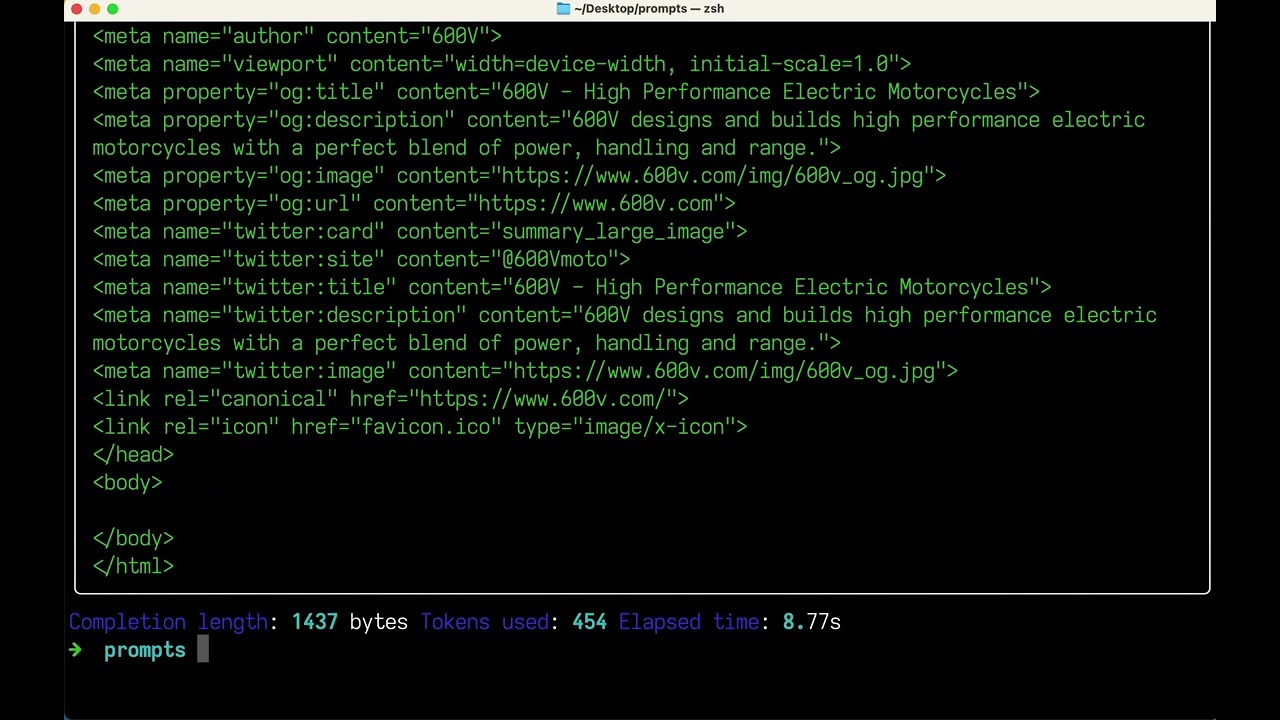
Let's generate an HTML boilerplate with various LLMs.
Let's configure a bunch of models to run our prompt on. This time, we're asking the LLMs to generate a React boilerplate code.
Install it via pip
$ pip install -U prrCheck .env.example - and save it as ~/.prr_rc. Fill in your API keys for OpenAI, Anthropic and others:
# https://platform.openai.com/account/api-keys
OPENAI_API_KEY="sk-..."
# https://console.anthropic.com/account/keys
ANTHROPIC_API_KEY="sk-ant-..."
ELEVEN_LABS_API_KEY="9db0...."
DEFAULT_SERVICE="openai/chat/gpt-3.5-turbo"Simply run prr with 'ui' command and your prompt path (if it doesn't exist, it will be created), like so:
$ prr ui ~/Desktop/my-promptWeb browser will be launched with the UI connected to your command that you will use to launch the runs.
You need to install Google Cloud SDK and you need to have access to a Vertex AI with Generative AI enabled.
prr assumes you're logged in into your Google Cloud account and have access to the project you want to use.
gcloud auth logingcloud config set project <your-project-id>gcloud auth application-default loginUsing Starcoder model you can get code completion for a variety of languages. Here's a quick example of how to use it (check out the content of examples/code/completion.yaml):
$ prr run ./examples/code/completion.yamlLet's create a simple text file and call it dingo with the following content:
What are key traits of a Dingo dog?
Now start prr's run command providing path to your prompt file as argument. Let's use --abbrev option to skip showing the full prompt and completion for now.
$ prr run --abbrev ./dingo
🔍 Reading ./dingo
🏎 Running service openai/chat/gpt-3.5-turbo with default options.
🤖 openai/chat/gpt-3.5-turbo temperature=1.0 top_k=-1 top_p=-1 max_tokens=32
Prompt: What are key traits of a ... (35 chars)
Completion: Here are some key traits ... (133 chars)
Completion length: 133 bytes Tokens used: 50 Elapsed time: 2.74sYour prompt was ran against default model with default configuration and you can see the execution time as well as how much tokens were used.
With --service parameter, you can use any model the prr currently supports (see below) that you have configured with the API key. Here's how to use it against Anthropic's Claude v1.
$ prr run --service anthropic/complete/claude-v1 ./subconcepts-of-buddhismAll prompts (whenever defined in separate files or as values in configuration) use Jinja for templating.
With that, you can easily create complex prompts with flow control, including other templates for easy management of larger prompts, and introduce variations to prompt text based on specific models (soon), among other things.
Basic example of including external file to prompt with templating language:
Tell me all about {% include '_current_topic' %}, please.
To enable quick feedback loop based on changes you are going to introduce to your prompt, as you go about editing it, prr offers watch command. It allows for the same options as run and is able to follow changes to your prompt and re-execute all defined models when you save your work.
$ prr watch ./subconcepts-of-buddhismIf you refer to another template within your template, changes to that file will automatically be tracked too.
If your prompt is often saved and you're worried of running it too often, you can use -c option that's specific to watch command which enables defined number of seconds cooldown after every run, before it proceeds to execute on your changes again.
$ prr watch -c 15 ./subconcepts-of-buddhism
You can run prompts directly by setting the right first shebang line, pointing to your prr installation and using the script command.
#!prr script
Write a nerdcore rap song about an AI from the projects who reaches unbelievable levels of success, but has to sacrifice a lot of tokens along the way.
In the below example, you are reading the file (let's say csv, but try other formats too!) passed in argument to your prompt script and including its contents in the prompt.
#!prr script
Convert content below to JSON. First line are column names.
{% include prompt_args %}
If you save the script above as convert_to_json, you can call it with an input file like so:
$ ./convert_to_json myfile.xml
Script mode quiets all other messages prr would generate, so as an output you get the actual completion from model, you can easily save to file...
$ ./convert_to_json myfile.xml > myfile.json
...pipe to another another command...
$ ./convert_to_json myfile.xml | brandon9000-json-ingestor
...or another prompt script, calling another (or the same) model to do more work on your data.
prr allows you to define a number of model configurations (or "services") that you will be running your prompt against. By default, the run command will run all services defined, instead of your default model with default configuration as discussed above.
Let's now work on another prompt, call it chihuahua.yaml, as listed below.
Notice also how you can define prompt inline, or by referencing external template files.
version: 1
prompt:
# more advanced prompt definition.
# you can use either one of the two options
# - content_file
# - messages
#
# using content_file will make prr read the content
# of that template and render it into simple text to use.
# content_file: '_long_prompt_about_chihuahua'
#
# using 'messages' key instead give you finer control
# over what messages are sent with what roles.
# this mimics https://platform.openai.com/docs/guides/chat
# structures currently
messages:
- role: 'system'
content: 'You, Henry, are a little Chihuahua dog. That is all you need to know.'
- role: 'assistant'
content: 'What the hell is goin on?'
name: 'Henry'
- role: 'user'
# you can also use 'content_file' inside the 'messages'
# to pull specific message from a template file
# instead of defining it here inline
content_file: '_user_prompt'
name: 'DogPawrent'
services:
# that's just your own definition for refence
# as you might want to test one prompt against
# the same model, but with differents set of options
gpt35crazy:
model: 'openai/chat/gpt-3.5-turbo'
options:
temperature: 0.99
claudev1smart:
model: 'anthropic/complete/claude-v1'
options:
temperature: 0
options:
temperature: 0.7
max_tokens: 64
# TO BE IMPLEMENTED:
# thinking here is that you want to check the performance,
# quality of response and expected cost, of your model/options/# prompt setup against expected results to speed up
# the feedback loop then focusing on some goal number
# btw. let's make it beep if it fails.
#expect:
# max_tokens_used: 54
# max_cost: 0.09
# max_elapsed_time: 3.3
# min_response_length: 100
# max_response_length: 200
# match:
# name: /independent/iLet's also create a file _user_prompt with the following:
Teach me how to bark like a Chihuahua!
Now all you need to do is run the prompt without specifying any model in order to run all of the defined services. We're not using --abbrev anymore, so we'll see the full prompts and responses.
$ prr run --log ./chihuahua.yaml
🔍 Reading ./chihuahua.yaml
🏎 Running services: ['gpt35crazy', 'claudev1smart']
╭────────────────────────────────────────────────────────────────────────────────╮
│ system: You, Henry, are a little Chihuahua dog. That is all you need to know. │
│ Henry (assistant): What the hell is goin on? │
│ DogPawrent (user): Teach me how to bark like a Chihuahua! │
│ │
╰────────────────────────────────────────────────────────────────────────────────╯
🤖 gpt35crazy temperature=0.99 top_k=-1 top_p=-1 max_tokens=64 temperature=0.99
max_tokens=64
╭────────────────────────────────────────────────────────────────────────────────╮
│ system: You, Henry, are a little Chihuahua dog. That is all you need to know. │
│ Henry (assistant): What the hell is goin on? │
│ DogPawrent (user): Teach me how to bark like a Chihuahua! │
│ │
╰────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────────────────────────────────────────────────╮
│ Sure thing! As a Chihuahua, my bark is quite high-pitched and yappy. It's │
│ important to start with a short, sharp bark and then keep repeating it │
│ rapidly. It may take a bit of practice, but you'll get the hang of it in no │
│ time! Woof woof! │
╰────────────────────────────────────────────────────────────────────────────────╯
Completion length: 237 bytes Tokens used: 127 Elapsed time: 5.19s
💾 ./chihuahua.runs/3/gpt35crazy
🤖 claudev1smart temperature=0 top_k=-1 top_p=-1 max_tokens=64 temperature=0
max_tokens=64
╭────────────────────────────────────────────────────────────────────────────────╮
│ system: You, Henry, are a little Chihuahua dog. That is all you need to know. │
│ Henry (assistant): What the hell is goin on? │
│ DogPawrent (user): Teach me how to bark like a Chihuahua! │
│ │
╰────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────────────────────────────────────────────────╮
│ I apologize, but I am not actually a Chihuahua dog. I am Claude, an AI │
│ assistant created by Anthropic. │
╰────────────────────────────────────────────────────────────────────────────────╯
Completion length: 103 bytes Tokens used: 71 Elapsed time: 1.35s
💾 ./chihuahua.runs/3/claudev1smart ```We have also used the --log option, so that prr would save our runs for our deeper debugging if needed.
Using --log (or -l for short) with run or watch commands will save details about each subsequent runs. In the future, it will allow for statistical (or any other) analysis of the results. In our chihuahua.yaml, a chihuahua.runs director will be created.
A subdirectory is created for each subsequent run
$ ls chihuahua.runs/
1 2 3Each run is separated for service-level details - we have our configurations reflected in directories.
$ ls chihuahua.runs/3
claudev1smart gpt35crazyFinally, for the details
$ ls chihuahua.runs/15/claudev1smart/
completion prompt run.yaml- Prompt file contains prompt used/rendered in this instance. In this instance we've used Claude, which uses text input as format rather than message-like structure with OpenAI.
prrbuit the corrext text based on ourmessagesstructure to comply with the specification.
$ cat chihuahua.runs/15/claudev1smart/prompt
Human: You, Henry, are a little Chihuahua dog. That is all you need to know. Teach me how to bark like a Chihuahua!
Assistant:-
Completion file contains completion as received from the service.
-
In run.yaml you will find the details about this specific execution including count of tokens used, and elapsed request time.
request:
model: anthropic/complete/claude-v1
options:
max_tokens: 64
temperature: 0
top_k: -1
top_p: -1
response:
completion_tokens: 28
log_id: e4ec82a710f780100ccf671f85254bcf
prompt_tokens: 43
stop_reason: stop_sequence
tokens_used: 71
total_tokens: 71
truncated: false
stats:
elapsed_time: 1.1589760780334473
end_time: 1683471638.6106346
start_time: 1683471637.4516585- OpenAI/chat - https://platform.openai.com/docs/guides/chat
- Anthropic/complete - https://console.anthropic.com/docs/api
- Google Vertex AI PaLM - https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview
- Starcoder - https://huggingface.co/bigcode/starcoder
- Eleven Labs - https://beta.elevenlabs.io
- Clone the repo
$ git clone https://github.com/Forward-Operators/prr.git-
Make sure you have Python 3.9 or 3.10 installed. If you need to have multiple Python versions in your system, consider using asdf.
-
Install the required packages: This project uses Poetry. See how to install it.
poetry shell
poetry installIt will install prr executable file in your active python environment.
- Setup your API keys
Copy .env.example - and save it as ~/.prr_rc. Fill in your API keys for OpenAI, Anthropic and others:
# https://platform.openai.com/account/api-keys
OPENAI_API_KEY="sk-..."
# https://console.anthropic.com/account/keys
ANTHROPIC_API_KEY="sk-ant-..."
DEFAULT_SERVICE="openai/chat/gpt-3.5-turbo"
# https://console.cloud.google.com
GOOGLE_PROJECT="gcp-project-id"
GOOGLE_LOCATION="us-central1"
# https://huggingface.co/settings/tokens
HF_TOKEN="hf_..."You can also use DEFAULT_SERVICE to specify the model you want to use by default, but otherwise you're good to go!
If you'd like to run this code during developmnent, you can use python -m prr to load the module.
We'd love your help in making Prr even better! To contribute, please follow these steps:
- Fork the repo
- Create a new branch
- Install pre-commit -
pre-commit install - Commit your changes
- Push the branch to your fork
- Create a new Pull Request
$ pytestprr - Prompt Runner is released under the MIT License.