{kind=link}
![]()
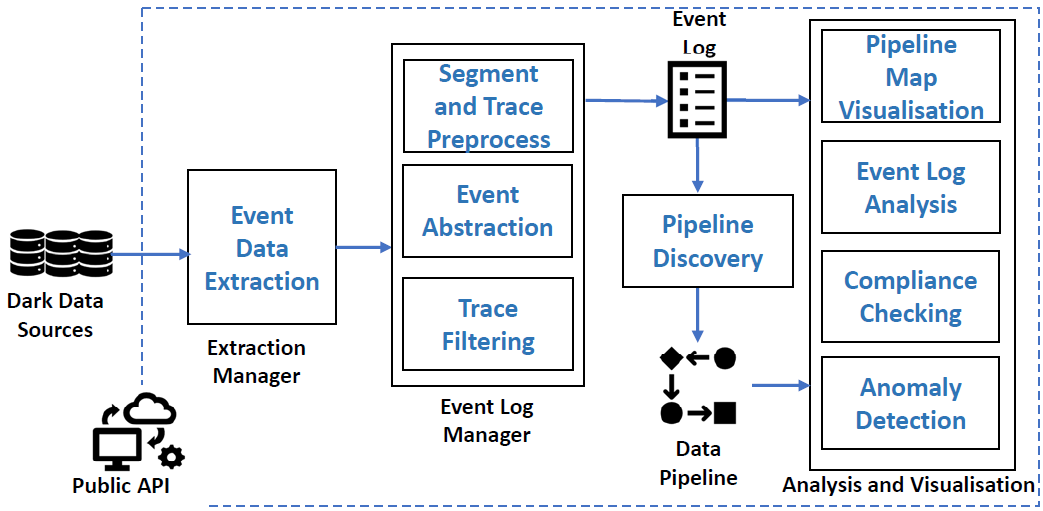
DIS-PIPE provides scalable integration of process mining techniques and artificial intelligence algorithms to learn the structure of Big Data pipelines by extracting, processing, and interpreting vast amounts of event data collected from several data sources. Furthermore, DIS-PIPE supports a variety of analytics techniques for visualizing the discovered pipelines together with detailed diagnostics information about their execution.
In particular, the functionalities provided by DIS-PIPE include:
- Event data extraction: which analyzes data sources to detect the main constituents of a data pipeline execution [DONE];
- Segmentation: which clusters together the events belonging to the same pipeline executions [DONE];
- Abstraction: which reduces the complexity of the event data set by merging multiple events into larger ones [DONE];
- Filtering: which removes potential outliers and infrequent events from the data set [DONE];
- Pipeline discovery: which learns the structure of a data pipeline by interpreting an event log generated by applying the previous functionalities over the event data set [DONE];
- Pipeline map visualization: providing an understandable flowchart view of a discovered pipeline, which facilitates the analysis of execution metrics, such as duration, frequent paths, or exceptional behaviors [DONE];
- Event log analysis: which enables inspecting the history of relevant pipeline executions collected in the event log and understanding specific aspects, including timeframe, variation, attributes, event relationships, and many more [DONE];
- Compliance checking: of the pipeline executions as observed into the event log with the organization’s business rules, policies, and regulations [DONE];
- Anomaly detection: which interprets the compliance checking outcomes signaling nonconforming deviations and providing repair solutions [DONE].
DIS-PIPE consists of a Web API implemented using Python and Flask1:
- backend.py: uses the PM4PY library2 and Process Discovery algorithms to find a suitable process model that describes the order of events/activities of a given event log. In particular, for Process Discovery it has been used the DFG3 algorithm, that, together with some input parameters, returns a Digraph in DOT language format. It also exposes a web application implemented using html, css and javascript. It uses the Viz.js4 library to represents the DOT language format.
Specifically, it provides a graphical user interface for importing event logs in the IEEE Standard for eXtensible Event Stream (XES) format and executing the functionalities by leveraging a drag-and-drop workbench. The architecture of DIS-PIPE can be summarized in the figure below.
The code has been tested using Python 3.8.12, Java 11, GCC compiler, conda 4.10.3, PostgreSQL 12. Other versions are not guaranteed to work properly.
Follow these links:
<br />
https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html
<br />
Or go directly to Miniconda: https://docs.conda.io/en/latest/miniconda.html
It should work also on Anaconda: https://docs.anaconda.com/anaconda/install/index.html
It is really suggested to use the already existing environment.
<br />
After downloading the file "environment.yml", open the terminal or an Anaconda Prompt, change directory to go to the location where the file is located and do the following steps:
- Create the environment from the environment.yml file:
conda env create -f environment.yml
The first line of the yml file sets the new environment's name, in this case "pm4py_env"
<br />
- Activate the new environment:
conda activate pm4py_env
- Verify that the new environment was installed correctly:
conda env list
or
conda info --envs.
- Open terminal or Anaconda Prompt.
- Activate "pm4py_env".
- Change directory to go in the "api" folder downloaded.
- Run:
python cleanCompiler.pyin terminal or prompt; - Run:
python configDatabase.pyto define the configuration of your Postgres server or use the default settings; - Run:
python backend.pyin terminal or prompt; - Go to your browser on http://127.0.0.1:7778/ or http://localhost:7778/
If there is an error saying <br />
from graphviz.dot import Digraph ImportError: cannot import name 'Digraph' from 'graphviz.dot'
<br /> try changing the line 21 of file "gview.py" through path <br />
C:\Users\<username>\<miniconda3|anaconda3>\envs\pm4py_env2\lib\site-packages\pm4py\visualization\common\gview.py
<br />with this line
<br /> from graphviz import Digraph
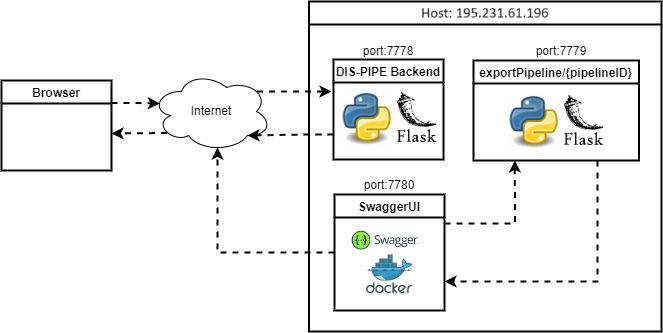
The DIS-PIPE tool is deployed on a single host as shown in the figure below. From the browser is possible to access DIS-PIPE at the following link: https://195.231.61.196:7778/. As the request comes in the backend will process it and the user is able to perform the functionalities provided above.
See the example folder for instructions on how to run your first data pipeline discovery.
Before raising a pull request, please read our contributing guide.
DIS-PIPE is released as open source software under the Apache License 2.0.
Footnotes
-
For further information how to create Web APIs with Python and Flask, please refer to the following link: https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask#setting-up . ↩
-
Directly-Follows graphs are graphs where the nodes represent the events/activities in the log and directed edges are present between nodes if there is at least a trace in the log where the source event/activity is followed by the target event/activity. On top of these directed edges, it is easy to represent metrics like frequency (counting the number of times the source event/activity is followed by the target event/activity) and performance (some aggregation, for example, the mean, of time inter-lapsed between the two events/activities). ↩