{kind=link}
{kind=link}
{kind=link}
| page_type | languages | products | description | urlFragment | ||||
|---|---|---|---|---|---|---|---|---|
sample |
|
|
The goal of this project is to show how to leverage Apache cTAKES along with Azure Search to build an effective document search application. |
search-dotnet-medical-ner |
The goal of this project is to show how to leverage Apache cTAKES along with Azure Search to build an effective document search application.
One of the most important things in building an effective search application is to have as much metadata about the content as possible. Unfortunately with medical documents, this is typically a very unstructured piece of content where you usually only have the block of text from the content. For that reason, it is very important to "enrich" this content by analyzing it to extract meaningful metadata about the content, such as what diseases were mentioned, or what parts of the anatomy were discussed. By doing this, you start to put structure to your content which greatly helps what you can do with a search based application. Both Apache cTAKES as well as Azure Cognitive Search leverage AI and Machine Learning techniques to do this enrichment of content. By combining these technologies we can build applications such as this PubMed Search Demo
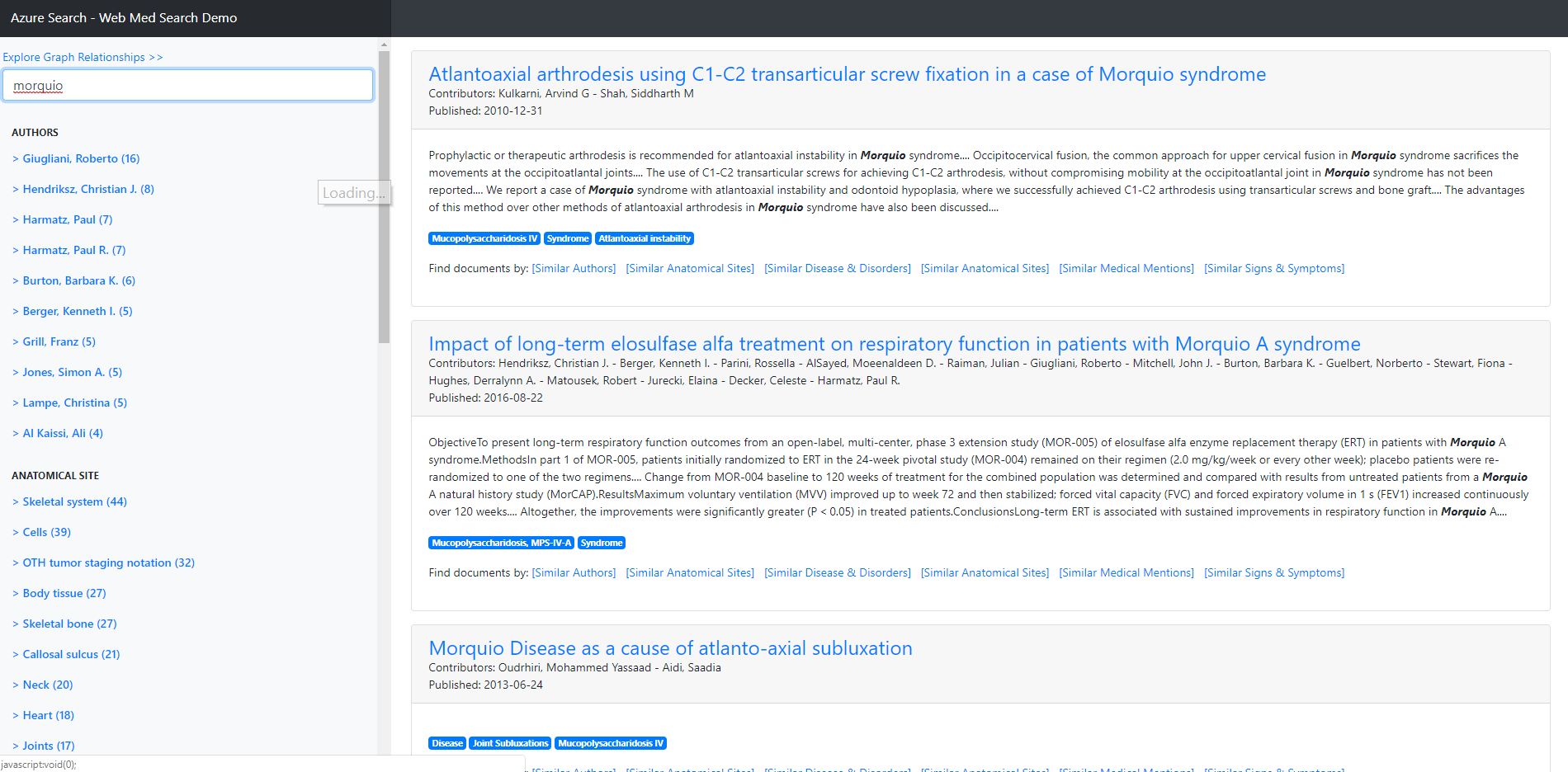
as well as create graph visualizations that shows correlations such as:

This tutorial assumes that you will be leveraging Windows.
In this tutorial, we will walk through the following steps:
- Configure Apache cTAKES as a service to receive text and return medical entities
- Configure Azure Cognitive Search to ingest unstructured medical content (PDF's) from Azure Blob Storage into a search index that has important metadata as well as extracted text from the content
- Run an application that processes these PDF's against the Apace cTAKES service to extract medical entities and apply that to the Azure Search index
- Run an application that allows for searching and exploration of this medical content
NOTE: Since a UMLS account is important, you may want to start with the step "Setup UMLS Account" before doing anything else.
cTAKES stands for clinical text analytics and knowledge extraction and is a very effective method of extracting various medical based entities (named entity extraction) from a corpus of text. For example it can identify disease or anatomical terms mentioned within the text. It has been trained using dataources such as UMLS (snomed).
Azure Cognitive Search is a merger of Azure Search which is a platform as a service that makes it easy for developers to build great search experiences over their data with Cognitive Services which has the ability to leverage AI extract meaning from content such as text and images. By combining these technologies, Cognitive Search has the ability to let developer build effective search applications over unstructured content such as medical documents.
This tutorial assumes that your content exists in Azure Blob Storage. Although it is not critical to do this in order to build this type of application, it makes everything much simpler since Azure Search can easily crawl Azure Blob Storage which greatly reduces the amount of code required.
You will find a set of medical files from PubMed that we will use for this purpose.
Create an Azure Blob Storage container and upload these files to your Azure Blob Storage container. If you are not familiar with how to do this, please see this page
Next, we need to create an Azure Search service that will make this content searchable to enable the types of applications show at the top.
To learn more about how to do this, please visit Create an Azure Search service in the portal. For our demo purposes, you can create a Free Azure Search Service.
Once you have created the Azure Search service, you will need to get your Azure Search Service name as you specified in this step as well as the Admin API Key.
In this step we will create an Azure Search index that will consists of the text extracted from the medical documents as well as some useful metadata from this content such as file name, size, authors, etc. We will be leveraging Cognitive Search pipeline to help with this step. One thing to note, is that if the content included images such as scans, or xrays, we could enable OCR to also extract text from these images within the PDF's. However, since our test documents are purely text based, we do not need to do this for this tutorial.
It is highly recommended that you review the documentation on how to Configure Cognitive Search to learn how to point Azure Search at your Blob Storage container.
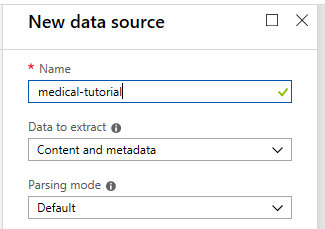
As you configure Cognitive Search, it is important that you:
- Choose the defaults for the data source as shown here:
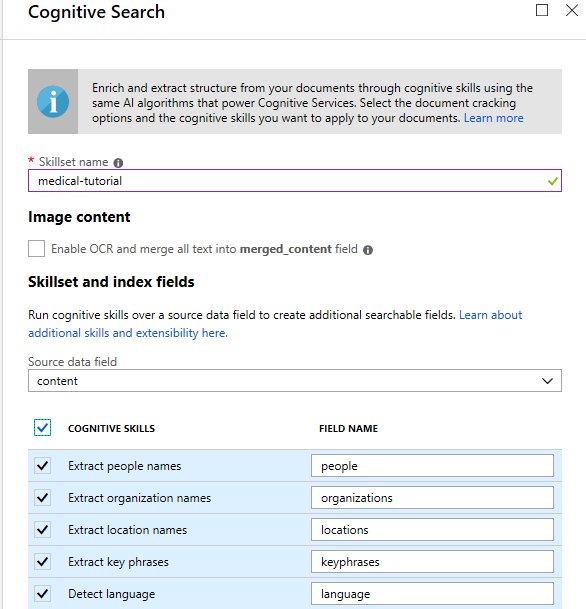
- Choose the following skills:
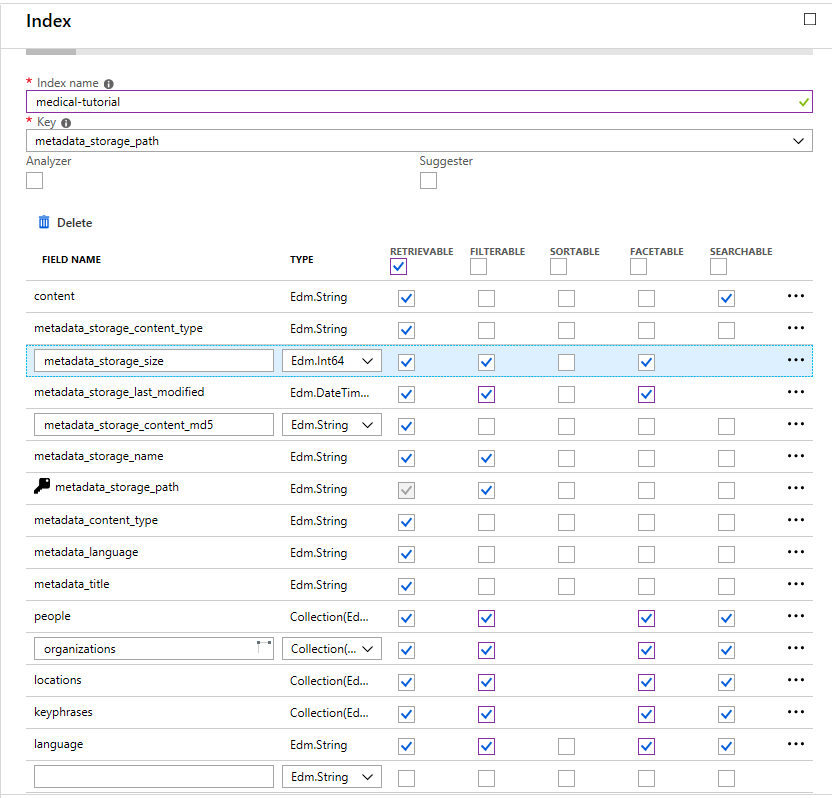
- Configure the Azure Search Index with the following schema and index name:
In this section we will learn how to download and run a JAVA servlet based implimentation of Apache cTAKES that has the ability to receive through an API call a set of text that is processed and returns a set of medical named entities found in the content.
Since cTAKES leverages UMLS, we will need to sign up for a UMLS account. To do this visit the UMSL page and choose Sign Up. Make note of the license restrictions of using this and the fact that the approval is not instantaneous.
We will be using healthnlp's implementation which can be found here. Specifically, we will be using the ctakes-web-client. You can see an example of what the running web app will look like in this demo.
To get this running, you will not only need to download this project, but also install Maven and JAVA. In my case, I have:
- Java JDK 1.8.0
- Maven 3.5.3
After installing this, from my machine I configured JAVA and Maven as follows:
set JAVA_HOME=d:\ctakes\jdk1.8.0_152
set MAVEN_HOME=d:\ctakes\apache-maven-3.5.3
set M2_HOME=d:\ctakes\apache-maven-3.5.3
set path=%path%;d:\ctakes\apache-maven-3.5.3\bin;d:\ctakes\jdk1.8.0_152\bin
After this point I could change to the \examples-master\ctakes-web-client directory and run:
mvn jetty:run
If everything runs properly, you should see something like the following:
[INFO] Started ServerConnector@3cf55e0c{HTTP/1.1}{0.0.0.0:8080}
[INFO] Started @38253ms
[INFO] Started Jetty Server
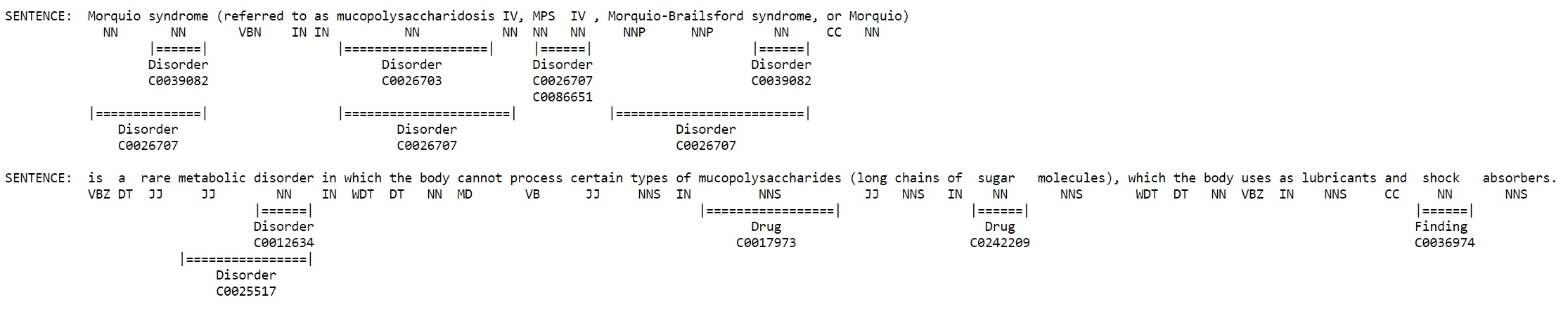
Open a browser and point it to http://localhost:8080/ and then enter some medical content to test the results such as:
Morquio syndrome (referred to as mucopolysaccharidosis IV, MPS IV, Morquio-Brailsford syndrome, or Morquio) is a rare metabolic disorder in which the body cannot process certain types of mucopolysaccharides (long chains of sugar molecules), which the body uses as lubricants and shock absorbers.
The results should look as follows:
The next step will be to take update the Azure Search index schema by adding some new fields that will hold the new medical entities and then take the content and run it through cTAKES to get the medical entities where are then applied to the Azure Search Index.
NOTE: This step requires you to have a valid UMLS account as outlined above.
During this step we will only extracts a few of the possible medical entity types that cTAKES supports including:
- Disease and Disorders
- Medication Mentions
- Sign and Symptom
- Anatomical Sites
Other entity types available can be found here.
To get started,
- Open the MedicalEntityExtraction console application solution in Visual Studio.
- Open the MedicalEntityExtraction project and then open the project file Program.cs.
- Update umlsuser and umlspw values to those obtained from setting up your UMLS account
- Update the SearchServiceName and SearchServiceKey to those of the Azure Search service you created above. NOTE: the search service name should NOT include .search.windows.net, but only the search service name
- Run the application
At this point you will have a complete Azure Search index that includes everything needed to build a search application.
Included in this repo is a sample ASP.NET MVC application that is built to work with the index you just created. You can find this sample in the WebMedSearch directory. In order to use this demo, you should only need to modify the web.config and update the SearchServiceName and SearchServiceApiKey to those of the Azure Search service you created. In addition, if you chose an index name other than medical-tutorial, you will also need to update the SearchServiceIndexName. Once completed you should be able to run the demo web app.
Since the content uploaded is about the disease Morquio, this is a good term to try as your search. You should see some data coming back that shows how effective the entity extraction was, even with this small dataset.
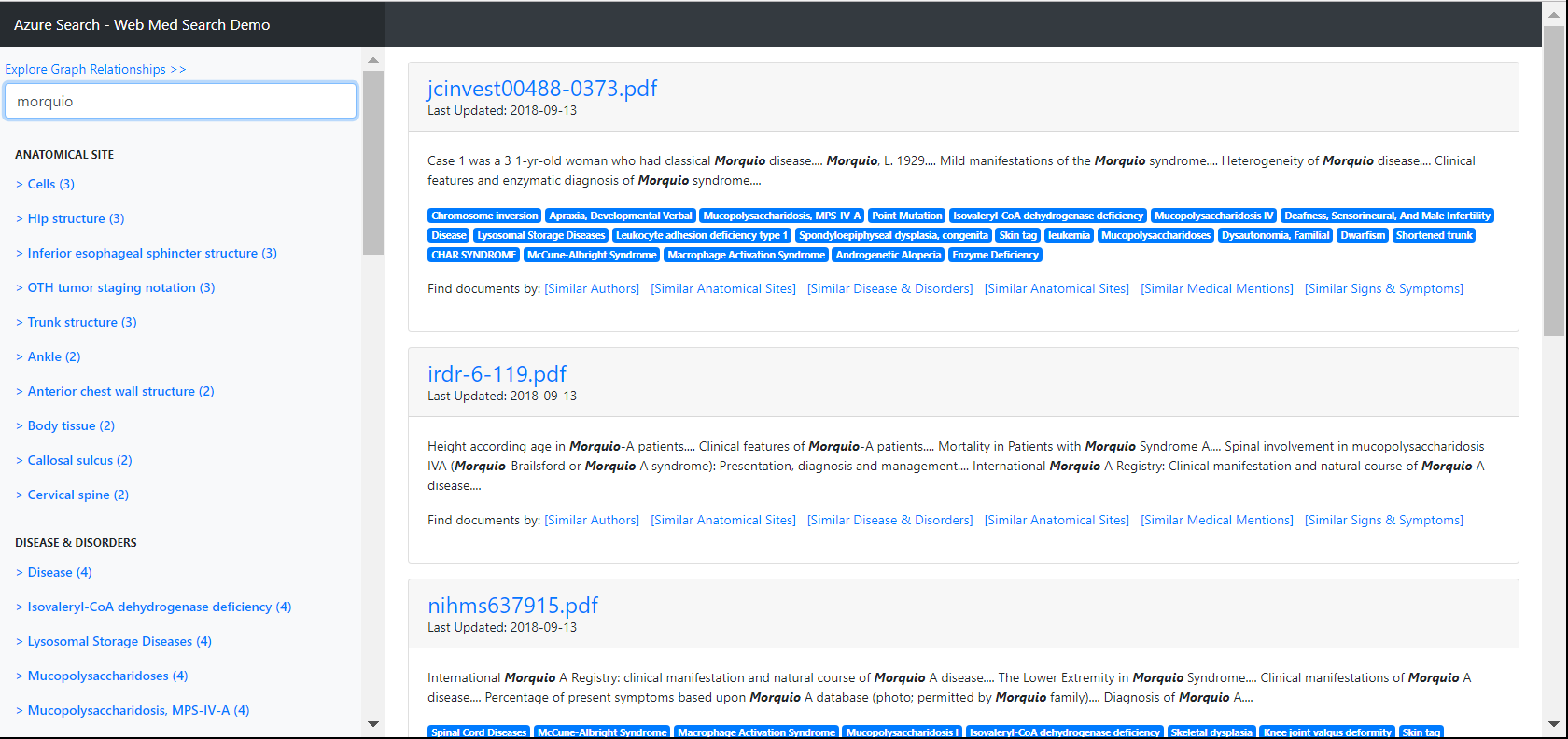
In addition, click where it says "Explore Graph Relationships" and play with the various options in the drop down. Notice once again, even through their are only a few documents it shows some interesting correlations. You can double click on the nodes if you want to drill into them. After this, you can go back to the document search and it will show the documents that correlate to this updated search selection.
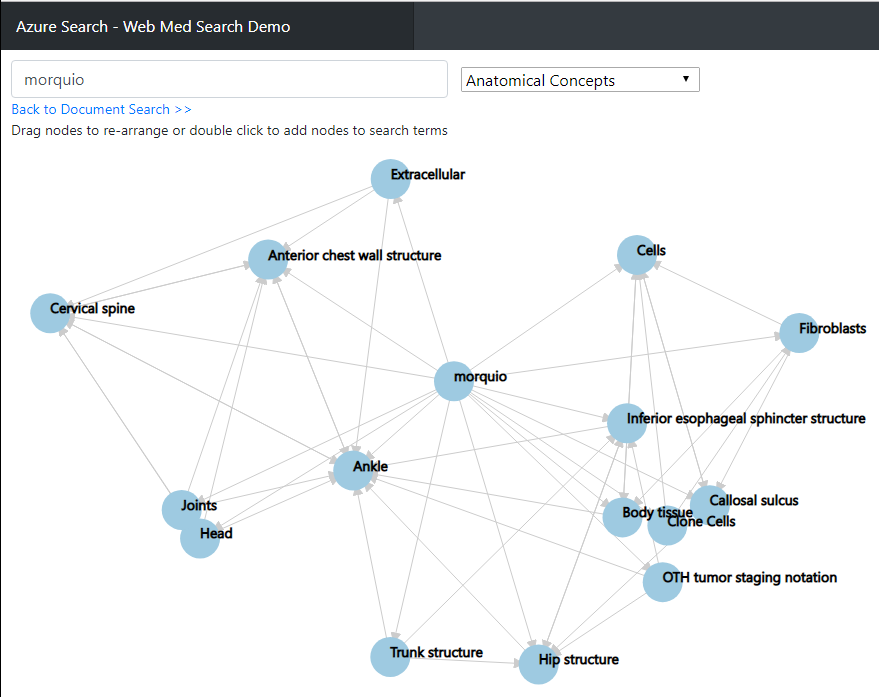
If you are interested in learning more about how to leverage Cognitive Search for your purposes or even if you want to do something similar over a non-medical set of content, feel free to reach out to myself and our team at: azuresearch_contact@microsoft.com
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.