Fix handling of surrogates on encoding #530
Conversation
Codecov Report
@@ Coverage Diff @@
## main #530 +/- ##
==========================================
- Coverage 91.76% 91.68% -0.08%
==========================================
Files 6 6
Lines 1821 1828 +7
==========================================
+ Hits 1671 1676 +5
- Misses 150 152 +2
Continue to review full report at Codecov.
|
|
Regarding the change of the |
abc7a7d
to
c9df712
Compare
|
@JustAnotherArchivist I ran benchmarks on this branch and on main to compare them. Trying to compare those number really made we wish I had any easy way to dump the numbers from specific runs into a file and then reload them so I can compare across versions using t-tests instead of trying to look at these pointwise measurements. I ran each benchmark 4 times. Here are the results from the main branch: And here are the results from this branch: Overall, I think there might be a slight performance regression here, but it's hard to be sure without the t-test. The "Array with 256 UTF-8" test does seem to be ~16% slower. |
|
So it does seem that there is a very slight, but measurable performance regression. I suppose this is to be expected given that this is doing strictly more than the previous code. I'm not sure if there is any way around it. But I did 104 paired t-tests and got that (impl_version=5.2.1.dev51 without this PR) performs better than (impl_version=5.2.1.dev9 with this PR) on average (p=0.00001616). Here is an example plot:
Might need to run it a few more times to buff up the stats because I'm getting a high std on the times for this PR. It's probably a fluke, but more stats will help figure that out.
|


This allows surrogates anywhere in the input, compatible with the json module from the standard library. This also refactors two interfaces: - The `PyUnicode` to `char*` conversion is moved into its own function, separated from the `JSONTypeContext` handling, so it can be reused for other things in the future (e.g. indentation and separators) which don't have a type context. - Converting the `char*` output to a Python string with surrogates intact requires the string length for `PyUnicode_Decode` & Co. While `strlen` could be used, the length is already known inside the encoder, so the encoder function now also takes an extra `size_t` pointer argument to return that and no longer NUL-terminates the string. This also permits output that contains NUL bytes (even though that would be invalid JSON), e.g. if an object's `__json__` method return value were to contain them. Fixes ultrajson#156 Fixes ultrajson#447 Fixes ultrajson#537 Supersedes ultrajson#284
…code_AsEncodedString
|
@Erotemic Thank you! It's good that you see a difference between the two because there should be one in the code so far as it does extra work (the encoding string comparison, in particular). :-) I've also run my own benchmarks tonight and noticed that I appear to have introduced a memory leak here (which, of course, would also have a performance impact via constant allocations).
Edit: Nevermind, I realised what's going on. I need to pass the |
c9df712
to
98321fa
Compare
One of my FOSS goals to accomplish on my vacation was to get nice benchmarks for this. I went a bit overboard and started writing a very general benchmark and analysis framework (#542), and I scrambled a bit on Sunday night to get something out the door for this PR. As such, I wouldn't be surprised if I just didn't run enough iterations or use robust enough outlier rejection. Next change I get to work on this, I'll run a more thorough set of measurements. Another clue that this could be the case is that Python's json also has a high std for some values of I could also see a memory leak messing with cache efficiency, so perhaps now that that's fixed the high std will go away. |
|
I ran the stats again 10 times on However, when updating the branch to the latest (which is now
With the fix to the memory leak, the benchmarks are much closer. The openskill win probs give this branch a 33.5% and main a 37.4%. Overall they are very close:
|
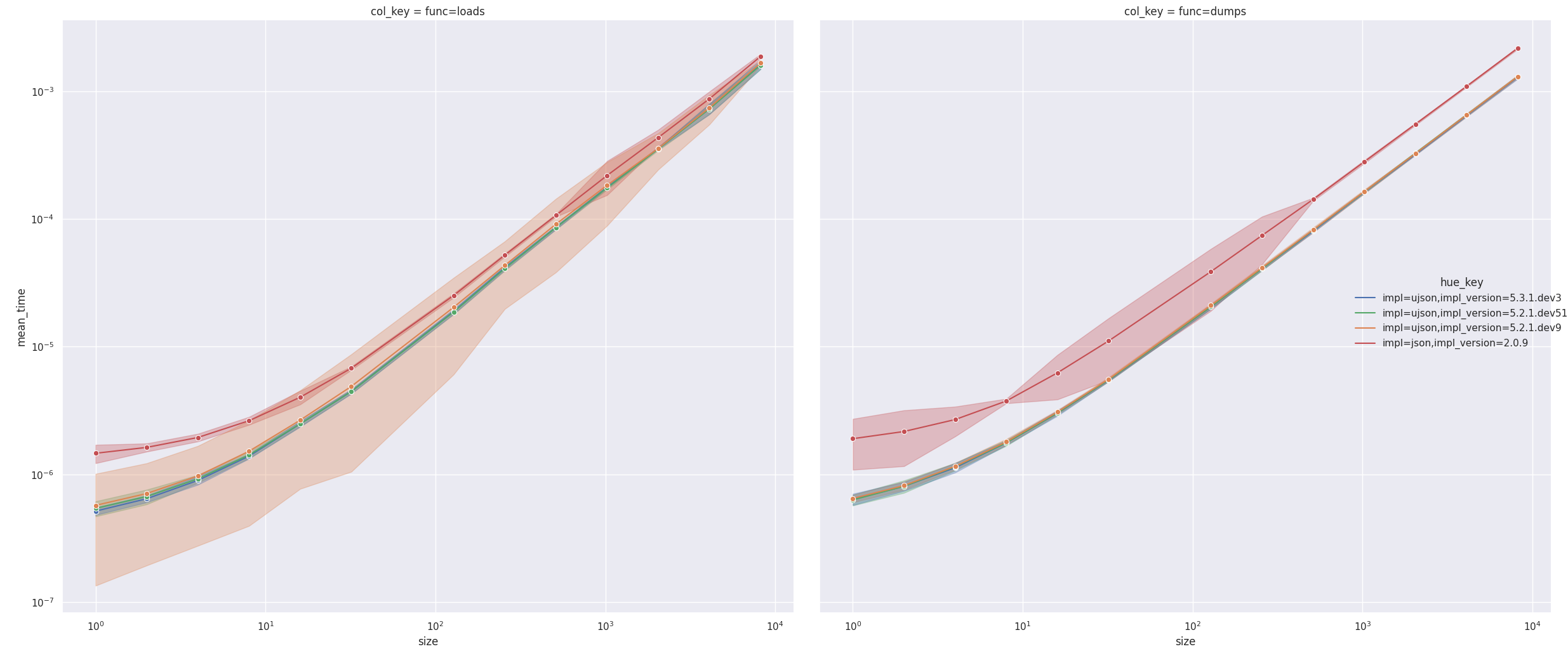
|
@Erotemic Thank you! This does match what I'm seeing in my own benchmarks as well: very similar timings and no statistically significant differences, though I'm not very confident in my statistics, so I'll exclude that here. I wrote my own small script rather than using the existing benchmarks for that. I'm specifically focusing only on dumps involving strings since anything else should be unaffected. I'm comparing main and this PR with CodeWarning: poor and dirty code ahead. Building from three branches in the repo: main (b300d64), fix-encode-surrogates (59aa3bf), and fix-encode-surrogates-with-string-comp (9b9af1a plus cherry-pick 59aa3bf) for branch in main fix-encode-surrogates fix-encode-surrogates-with-string-comp; do git switch ${branch} && make clean && make build && mv -nv ujson.cpython-310-x86_64-linux-gnu.so ujson.cpython-310-x86_64-linux-gnu.so_${branch}_debug && make clean && make build-prod && mv -nv ujson.cpython-310-x86_64-linux-gnu.so ujson.cpython-310-x86_64-linux-gnu.so_${branch}_prod; donewith this simple clean:
rm -rf build/ ujson.cpython-*.so
build:
CFLAGS='-DDEBUG' python3 setup.py develop
build-prod:
python3 setup.py developThis results in six .so files: Test driver script ( #!/bin/bash
set -e
strings=(
'""'
'"a"'
'"a" * 10'
'"a" * 1000'
'"‽"'
'"‽" * 10'
'"‽" * 1000'
)
os=("${strings[@]}")
for string in "${strings[@]}"
do
os+=(
"[${string}]"
"[${string} for i in range(10)]"
"[${string} for i in range(100)]"
"{${string}: ${string}}"
"{${string} + str(i): ${string} for i in range(10)}"
"{${string} + str(i): ${string} for i in range(100)}"
)
done
for o in "${os[@]}"
do
num=
for extra in '' sort
do
for so in ujson.cpython-310-x86_64-linux-gnu.so_*
do
echo "${so} ${o} ${extra}" >&2
ln -sf "${so}" ujson.cpython-310-x86_64-linux-gnu.so
if [[ -z "${num}" ]]
then
num=$(python3 test.py --num "${o}")
echo "Repeats: ${num}" >&2
fi
python3 test.py "${so}" "${o}" "${num}" ${extra}
done
if [[ "${o}" != '{'* ]]
then
break
fi
done
doneActual test code: import sys
import timeit
import ujson
o = eval(sys.argv[2])
stmt = 'ujson.dumps(o)'
if sys.argv[4:]:
stmt = 'ujson.dumps(o, sort_keys = True)'
t = timeit.Timer(stmt, globals = globals())
if sys.argv[1] == '--num':
num = None
def cb(number, timeTaken):
global num
num = number
t.autorange(cb)
num = num // 10
print(num)
sys.exit(0)
else:
num = int(sys.argv[3])
out = t.repeat(repeat = 100, number = num)
print(ujson.dumps({'so': sys.argv[1], 'o': sys.argv[2], 'sorted': bool(sys.argv[4:]), 'stmt': stmt, 'num': num, 'times': out}))Aggregation script: import collections
import json
import math
import sys
UNITS = ['s', 'ms', 'μs']
def format_time(t):
for unit in UNITS:
if t >= 1:
return f'{t:.3f} {unit}'
t *= 1000
return f'{t:.3f} ns'
names = {
'ujson.cpython-310-x86_64-linux-gnu.so_fix-encode-surrogates_debug': 'PR dbg',
'ujson.cpython-310-x86_64-linux-gnu.so_fix-encode-surrogates_prod': 'PR',
'ujson.cpython-310-x86_64-linux-gnu.so_fix-encode-surrogates-with-string-comp_debug': 'PR utf-8 dbg',
'ujson.cpython-310-x86_64-linux-gnu.so_fix-encode-surrogates-with-string-comp_prod': 'PR utf-8',
'ujson.cpython-310-x86_64-linux-gnu.so_main_debug': 'main dbg',
'ujson.cpython-310-x86_64-linux-gnu.so_main_prod': 'main',
}
objs = [json.loads(line) for line in sys.stdin]
nums = collections.defaultdict(set)
for obj in objs:
nums[(obj['o'], obj['sorted'])].add(obj['num'])
assert all(len(s) == 1 for s in nums.values()), nums
nums = {k: v.pop() for k, v in nums.items()}
results = collections.defaultdict(dict)
for obj in objs:
results[(obj['o'], obj['sorted'])][names[obj['so']]] = [t / nums[(obj['o'], obj['sorted'])] for t in obj['times']]
assert all(sorted(v.keys()) == sorted(list(results.values())[0].keys()) for v in results.values())
table = []
sos = sorted(list(results.values())[0].keys())
table.append(['object', 'repetitions'] + sos)
for o, sorted_ in sorted(results.keys()):
objStr = f'`{o}`' + (' (sorted)' if sorted_ else '')
num = nums[(o, sorted_)]
row = [objStr, num]
for so in sos:
times = results[(o, sorted_)][so]
avg = sum(times) / len(times)
std = math.sqrt(sum((t - avg) ** 2 for t in times) / (len(times) - 1))
row.append(f'{format_time(avg)} ± {format_time(std)}')
table.append(row)
for row in table:
print(' | '.join(map(str, row)))It isn't pretty, but it gets the job done. :-) Detailed results
The raw output of |
|
Thanks! |
This allows surrogates anywhere in the input, compatible with the json module from the standard library.
This also refactors two interfaces:
PyUnicodetochar*conversion is moved into its own function, separated from theJSONTypeContexthandling, so it can be reused for other things in the future (e.g. indentation and separators) which don't have a type context.char*output to a Python string with surrogates intact requires the string length forPyUnicode_Decode& Co. Whilestrlencould be used, the length is already known inside the encoder, so the encoder function now also takes an extrasize_tpointer argument to return that and no longer NUL-terminates the string. This also permits output that contains NUL bytes (even though that would be invalid JSON), e.g. if an object's__json__method return value were to contain them.Fixes #156
Fixes #447
Fixes #537
Supersedes #284