#683 Improve concurrency #1258
#683 Improve concurrency #1258
Conversation
…out on consumer stop(). fix some memory leaks in tests
…rrently usages from runner
… consume in tests
…ling. cleanup fetcher queue on stop
…ffset out of range to non-retriable
…een brokers. move fetch instrumentation emitting to fetchManager. seek all offsets, even if paused
test issues resolved. cleanup TODO.
…ker due to blocking fetch request limitations
separate socket for fetch polls to avoid blocking other concurrent requests fetch all topicPartitions per broker together track and don't fetch nodes that are being processed
|
Yeah that makes perfect sense. @julienvincent: Are you planning to test this branch in your systems? I haven't yet finished setting up a test system at work, so I can't really try it out in the real world until I've got that up and running. I have enough confidence in our tests to trust that this works fine during normal operation, but I'd be a lot more confident if I knew it had been running fine with a 10 broker cluster for a few days. Same goes for Priit, of course. |
|
I’m running it over the weekend on a POC environment under production-like load. |
|
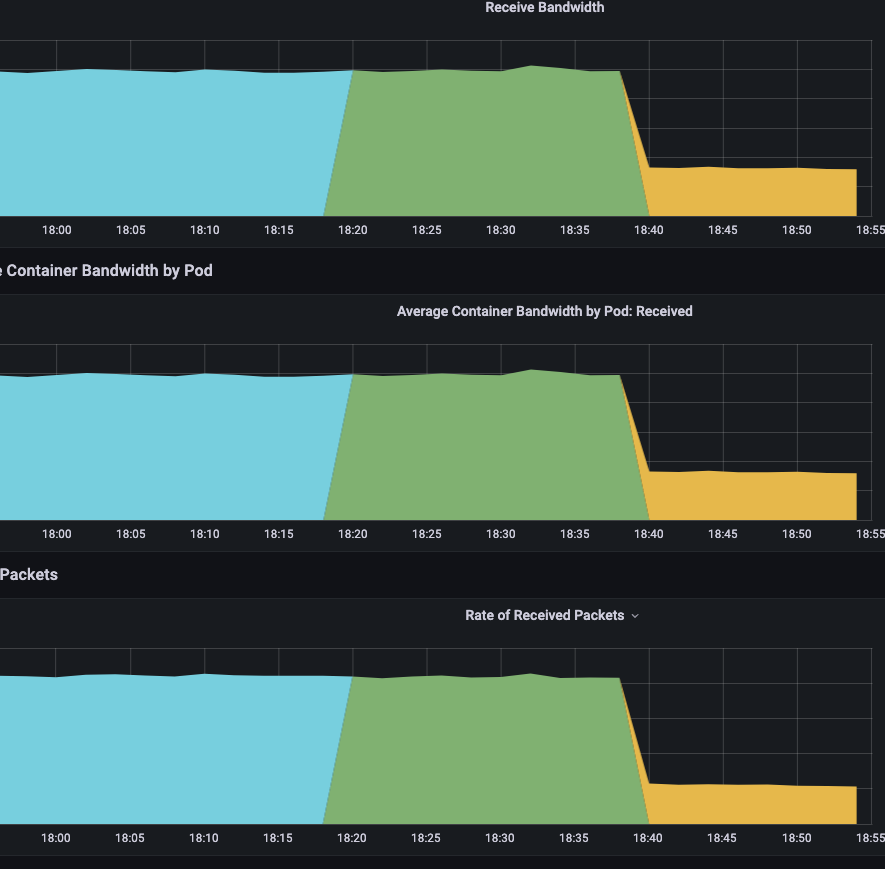
My preliminary testing is done and it seems to function as expected. I will be setting up a few services on our production environment today and tomorrow to run this branch and will let you know if I run into any problems. Edit Ok, I have set up one high-traffic/low-criticality service on production to run this code. So far so good. Per pod idle network and CPU usage fell off a cliff (I can safely increase
I'll get some more services onto this tomorrow |
| } | ||
| preferredReadReplicas[partition] = { | ||
| nodeId: preferredReadReplica, |
There was a problem hiding this comment.
Once we have assigned the partition to a different broker, isn't it the case that a fetch for that broker could now execute before the batch from this broker has been processed and resolved?
There was a problem hiding this comment.
I will focus on this at the end of the week.
On the first look, you might be right, though I'm not sure how often this could trigger, if at all, without rebalance.
There was a problem hiding this comment.
Just to see that I'm on the same page - the scenario you're describing is one where we have partition 1 assigned to broker 1. We fetch a batch from broker 1 and start to process it. While that's being processed, a Kafka admin goes and reassigns partition 1 to broker 2. We fetch from broker 2, and now we're basically processing the same messages in parallel, potentially causing some really strange behavior. Correct?
This does sound plausible. I haven't tried it to see what would happen, but I also can't find any information about how partition reassignment would affect consumer groups (other than if the leader changes), so I'm guessing it's something that needs to be handled client-side.
If so, then it seems a reasonable assertion to make that only one worker can process batches for a particular partition at any given time. Not sure where to enforce that though. Maybe the workers could keep a shared record of which of them is currently processing which partition, and if a worker gets a batch for a partition that some other worker is currently processing, it just drops the batch. That way the original worker gets to finish up their batch and the other worker will take over once the original worker is done.
There was a problem hiding this comment.
Took a stab at improving this in priitkaard#2
I still don't know if this is the right approach, or if we should do something more like the rebalancing when we detect this happening. Even with this, there's still no guarantee that worker 1 won't finish processing a batch for partition 1 just before worker 2 starts to process the same batch from partition 1, in which case they'll still be processing the same messages. The only way I see to avoid that is to look at the resolved offset and skip offsets before the currently resolved one.
There was a problem hiding this comment.
Btw, I asked the data streaming operations team at work if they knew what would happen in this scenario. They tested it out and verified that reassigning a partition to a different broker does not cause a consumer group rebalance, so it is something we have to handle on the client side.
There was a problem hiding this comment.
And for those reading along at home, the solution we went with in priitkaard#2 was to have the FetchManager keep track of which fetcher is assigned to a particular topic-partition at any given time. When a fetcher receives a response, it filters out batches for any topic-partitions it is not currently assigned to. In the scenario we've discussed, this would mean that the second fetcher (which is now fetching from the newly assigned broker) would filter out any topic-partitions that the fetcher processing batches from the previously assigned broker is currently processing or has queued up.
A more elegant solution might be to avoid fetching the topic-partition at all, if it's already assigned to a different fetcher, instead of filtering out the results. But this scenario should be quite rare, so maybe the juice is not worth the squeeze.
|
Is the worker/ worker queue mechanism here equivalent to the old utils/concurrency ? The new code looks ok but I was just wondering if there is a good reason to replace it. |
With the previous concurrency manager, it was not possible to pause the workers or in any way handle the lifecycle of a fetch response. |
Co-authored-by: Priit Käärd <priitkaard123@gmail.com>
If a partition is reassigned to a different broker, it's possible that a fetcher currently has a batch for that topic-partition in the worker queue. This would cause double processing. To avoid this, the fetch manager now keeps track of which fetcher is currently handling each topic-partition, and the fetchers will filter out batches for any topic-partition that is currently being processed by a different fetcher.
…kajs into handle-partition-reassignment
Handle partition reassignment
|
Would love to get this merged unless there are any more issues that appear. @priitkaard / @julienvincent: Let me know your experiences running the latest version of this branch whenever you've had a chance to try it out. |
|
We've been running this in production for around a week now and haven't discovered any additional issues so far. EDIT: Your latest change is running without problems in a POC environment at the moment. Haven't moved it to prod yet. |
I was just about to say that that was before I pushed some commits into this PR. Now all bets are off 😁 |
|
Fixes #1300 |
|
We have not seen any out-of-the-ordinary issues with our deployments running this code, and performance + latency has been very good - as expected! |
|
Alright, this has been marinating for long enough. Let's merge it so we can get a beta release out there and hopefully get some more people testing it out. |
|
kafkajs@1.17.0-beta.5 is now out with this change. Huge thanks to @priitkaard for his patience and dilligence! 🎉 While this change took a while to land, and was quite a bit of work for everyone involved, it was one of the more enjoyable PRs I've been part of in quite a while. Thanks also to @julienvincent for his testing efforts, and @t-d-d for helping out with the review! 👏 |
Notable changes:
partitionsConsumedConcurrentlynumber of independent runnersManually compared consumption times with the scripts below:
Producer:
Consumer:
Slower runners now consume their batches at their own pace, other fetch requests will not be blocked.
Partitions 2 and 3 were consumed in ~70ms (- 4s from delays) compared to the current master version, which took ~9s (-4s delays):