Optimize multiline diff for (some metric of) edit-distance #27
Labels
Comments
|
I agree, that the presentation is confusing - despite being a correct solution, it doesn´t seem to be an optimal solution. You already mentioned, that the current heuristic algorithm is doing two passes and the first is line-based, while the second pass is character-based. That I´m open for suggestions about a better algorithm. ^^ |
|
I deleted a previous comment that was wildly inaccurate. What we actually want here is
Edit: it would also need to implement |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I'm trying to use pretty-assertions for snapshot testing. I compare the snapshotted multiline-string with the new value using the
PrettyStringtrick from #24.When the actual result got indented (compared to the snapshot), the diff output became very confused:
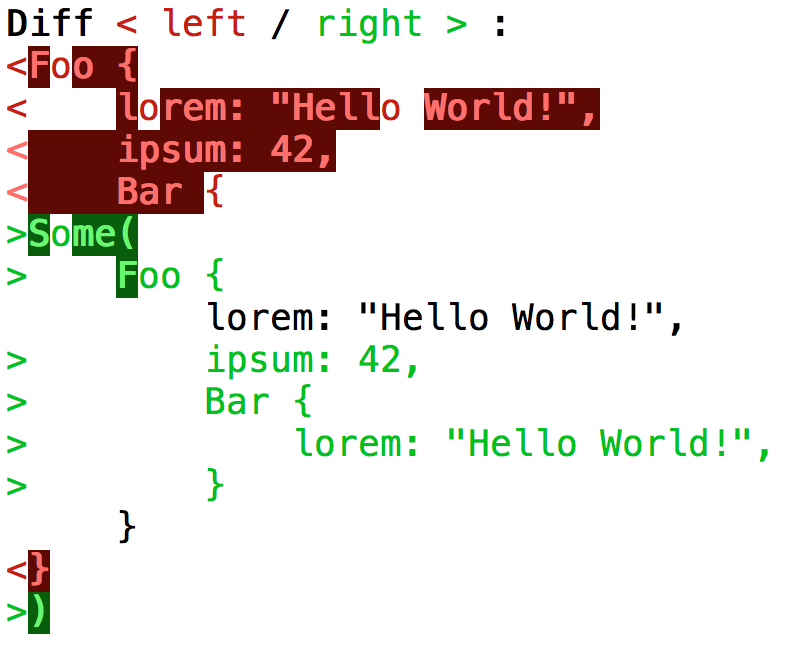
The reason is that two unrelated lines (
Foo's andBar'slorems) got matched up in the first (line-based) comparison pass, which should instead realize there's a new lineSome(, followed by a few modified lines, followed by a new line).The text was updated successfully, but these errors were encountered: