The Reactor project main artifact is reactor-core, a reactive library that focuses on
the Reactive Streams specification and targets Java 8.
Reactor introduces composable reactive types that implement Publisher but also provide
a rich vocabulary of operators: Flux and Mono. A Flux object
represents a reactive sequence of 0..N items, while a Mono object represents a
single-value-or-empty (0..1) result.
This distinction carries a bit of semantic information into the type, indicating the
rough cardinality of the asynchronous processing. For instance, an HTTP request produces
only one response, so there is not much sense in doing a count operation. Expressing
the result of such an HTTP call as a Mono<HttpResponse> thus makes more sense than
expressing it as a Flux<HttpResponse>, as it offers only operators that are relevant to
a context of zero items or one item.
Operators that change the maximum cardinality of the processing also switch to the
relevant type. For instance, the count operator exists in Flux, but it returns a
Mono<Long>.
The following image shows how a Flux transforms items:

A Flux<T> is a standard Publisher<T> that represents an asynchronous sequence of 0 to N
emitted items, optionally terminated by either a completion signal or an error.
As in the Reactive Streams spec, these three types of signal translate to calls to a downstream
Subscriber’s onNext, onComplete, and onError methods.
With this large scope of possible signals, Flux is the general-purpose reactive type.
Note that all events, even terminating ones, are optional: no onNext event but an
onComplete event represents an empty finite sequence, but remove the onComplete and
you have an infinite empty sequence (not particularly useful, except for tests around cancellation).
Similarly, infinite sequences are not necessarily empty. For example, Flux.interval(Duration)
produces a Flux<Long> that is infinite and emits regular ticks from a clock.
The following image shows how a Mono transforms an item:
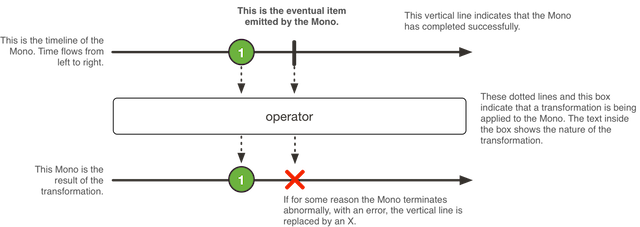
A Mono<T> is a specialized Publisher<T> that emits at most one item and then
(optionally) terminates with an onComplete signal or an onError signal.
It offers only a subset of the operators that are available for a Flux, and
some operators (notably those that combine the Mono with another Publisher)
switch to a Flux.
For example, Mono#concatWith(Publisher) returns a Flux while Mono#then(Mono)
returns another Mono.
Note that you can use a Mono to represent no-value asynchronous processes that only
have the concept of completion (similar to a Runnable). To create one, you can use an empty
Mono<Void>.
The easiest way to get started with Flux and Mono is to use one of the numerous
factory methods found in their respective classes.
For instance, to create a sequence of String, you can either enumerate them or put them
in a collection and create the Flux from it, as follows:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);Other examples of factory methods include the following:
Mono<String> noData = Mono.empty(); (1)
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3); (2)-
Notice the factory method honors the generic type even though it has no value.
-
The first parameter is the start of the range, while the second parameter is the number of items to produce.
When it comes to subscribing, Flux and Mono make use of Java 8 lambdas. You
have a wide choice of .subscribe() variants that take lambdas for different
combinations of callbacks, as shown in the following method signatures:
Fluxsubscribe(); (1)
subscribe(Consumer<? super T> consumer); (2)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer); (3)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer); (4)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer); (5)-
Subscribe and trigger the sequence.
-
Do something with each produced value.
-
Deal with values but also react to an error.
-
Deal with values and errors but also run some code when the sequence successfully completes.
-
Deal with values and errors and successful completion but also do something with the
Subscriptionproduced by thissubscribecall.
|
Tip
|
These variants return a reference to the subscription that you can use to cancel the
subscription when no more data is needed. Upon cancellation, the source should stop
producing values and clean up any resources it created. This cancel-and-clean-up behavior
is represented in Reactor by the general-purpose Disposable interface.
|
Reactor, like RxJava, can be considered to be concurrency-agnostic. That is, it does not enforce a concurrency model. Rather, it leaves you, the developer, in command. However, that does not prevent the library from helping you with concurrency.
Obtaining a Flux or a Mono does not necessarily mean that it runs in a dedicated
Thread. Instead, most operators continue working in the Thread on which the
previous operator executed. Unless specified, the topmost operator (the source)
itself runs on the Thread in which the subscribe() call was made. The following
example runs a Mono in a new thread:
public static void main(String[] args) throws InterruptedException {
final Mono<String> mono = Mono.just("hello "); //(1)
Thread t = new Thread(() -> mono
.map(msg -> msg + "thread ")
.subscribe(v -> //(2)
System.out.println(v + Thread.currentThread().getName()) //(3)
)
)
t.start();
t.join();
}-
The
Mono<String>is assembled in threadmain. -
However, it is subscribed to in thread
Thread-0. -
As a consequence, both the
mapand theonNextcallback actually run inThread-0
The preceding code produces the following output:
hello thread Thread-0In Reactor, the execution model and where the execution happens is determined by the
Scheduler that is used. A
Scheduler
has scheduling responsibilities similar to an ExecutorService, but having a
dedicated abstraction lets it do more, notably acting as a clock and enabling
a wider range of implementations (virtual time for tests, trampolining or
immediate scheduling, and so on).
The Schedulers
class has static methods that give access to the following execution contexts:
-
No execution context (
Schedulers.immediate()): at processing time, the submittedRunnablewill be directly executed, effectively running them on the currentThread(can be seen as a "null object" or no-opScheduler). -
A single, reusable thread (
Schedulers.single()). Note that this method reuses the same thread for all callers, until the Scheduler is disposed. If you want a per-call dedicated thread, useSchedulers.newSingle()for each call. -
An unbounded elastic thread pool (
Schedulers.elastic()). This one is no longer preferred with the introduction ofSchedulers.boundedElastic(), as it has a tendency to hide backpressure problems and lead to too many threads (see below). -
A bounded elastic thread pool (
Schedulers.boundedElastic()). Like its predecessorelastic(), it creates new worker pools as needed and reuses idle ones. Worker pools that stay idle for too long (the default is 60s) are also disposed. Unlike itselastic()predecessor, it has a cap on the number of backing threads it can create (default is number of CPU cores x 10). Up to 100 000 tasks submitted after the cap has been reached are enqueued and will be re-scheduled when a thread becomes available (when scheduling with a delay, the delay starts when the thread becomes available). This is a better choice for I/O blocking work.Schedulers.boundedElastic()is a handy way to give a blocking process its own thread so that it does not tie up other resources. See [faq.wrap-blocking], but doesn’t pressure the system too much with new threads. -
A fixed pool of workers that is tuned for parallel work (
Schedulers.parallel()). It creates as many workers as you have CPU cores.
Additionally, you can create a Scheduler out of any pre-existing ExecutorService by
using Schedulers.fromExecutorService(ExecutorService). (You can also create one from an
Executor, although doing so is discouraged.)
You can also create new instances of the various scheduler types by using the newXXX
methods. For example, Schedulers.newParallel(yourScheduleName) creates a new parallel
scheduler named yourScheduleName.
|
Warning
|
While Custom |
Some operators use a specific scheduler from Schedulers by default (and usually give
you the option of providing a different one). For instance, calling the
Flux.interval(Duration.ofMillis(300)) factory method produces a Flux<Long> that ticks every 300ms.
By default, this is enabled by Schedulers.parallel(). The following line changes the
Scheduler to a new instance similar to Schedulers.single():
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"))Reactor offers two means of switching the execution context (or Scheduler) in a
reactive chain: publishOn and subscribeOn. Both take a Scheduler and let you switch
the execution context to that scheduler. But the placement of publishOn in the chain
matters, while the placement of subscribeOn does not. To understand that difference,
you first have to remember that nothing happens until you
subscribe.
In Reactor, when you chain operators, you can wrap as many Flux and Mono
implementations inside one another as you need. Once you subscribe, a chain of
Subscriber objects is created, backward (up the chain) to the first
publisher. This is effectively hidden from you. All you can see is the outer layer of
Flux (or Mono) and Subscription, but these intermediate operator-specific
subscribers are where the real work happens.
With that knowledge, we can have a closer look at the publishOn and subscribeOn
operators:
publishOn applies in the same way as any other operator, in the middle of the
subscriber chain. It takes signals from upstream and replays them downstream while
executing the callback on a worker from the associated Scheduler. Consequently, it
affects where the subsequent operators execute (until another publishOn is
chained in), as follows:
-
Changes the execution context to one
Threadpicked by theScheduler -
as per the specification,
onNextcalls happen in sequence, so this uses up a single thread -
unless they work on a specific
Scheduler, operators afterpublishOncontinue execution on that same thread
The following example uses the publishOn method:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); //(1)
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) //(2)
.publishOn(s) //(3)
.map(i -> "value " + i); //(4)
new Thread(() -> flux.subscribe(System.out::println)); //(5)-
Creates a new
Schedulerbacked by fourThreadinstances. -
The first
mapruns on the anonymous thread in <5>. -
The
publishOnswitches the whole sequence on aThreadpicked from <1>. -
The second
mapruns on theThreadfrom <1>. -
This anonymous
Threadis the one where the subscription happens. The print happens on the latest execution context, which is the one frompublishOn.
subscribeOn applies to the subscription process, when that backward chain is
constructed. As a consequence, no matter where you place the subscribeOn in the chain,
it always affects the context of the source emission. However, this does not affect the
behavior of subsequent calls to publishOn — they still switch the execution context for
the part of the chain after them.
-
Changes the
Threadfrom which the whole chain of operators subscribes -
Picks one thread from the
Scheduler
|
Note
|
Only the earliest subscribeOn call in the chain is actually taken into account.
|
The following example uses the subscribeOn method:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); //(1)
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) //(2)
.subscribeOn(s) //(3)
.map(i -> "value " + i); //(4)
new Thread(() -> flux.subscribe(System.out::println)); //(5)-
Creates a new
Schedulerbacked by fourThread. -
The first
mapruns on one of these four threads… -
…because
subscribeOnswitches the whole sequence right from subscription time (<5>). -
The second
mapalso runs on same thread. -
This anonymous
Threadis the one where the subscription initially happens, butsubscribeOnimmediately shifts it to one of the four scheduler threads.
|
Tip
|
For a quick look at the available operators for error handling, see the relevant operator decision tree. |
In Reactive Streams, errors are terminal events. As soon as an error occurs, it stops the
sequence and gets propagated down the chain of operators to the last step, the
Subscriber you defined and its onError method.
Such errors should still be dealt with at the application level. For instance, you might
display an error notification in a UI or send a meaningful error payload in a REST
endpoint. For this reason, the subscriber’s onError method should always be defined.
|
Warning
|
If not defined, onError throws an UnsupportedOperationException. You can
further detect and triage it with the Exceptions.isErrorCallbackNotImplemented method.
|
Reactor also offers alternative means of dealing with errors in the middle of the chain, as error-handling operators. The following example shows how to do so:
Flux.just(1, 2, 0)
.map(i -> "100 / " + i + " = " + (100 / i)) //this triggers an error with 0
.onErrorReturn("Divided by zero :("); // error handling example|
Important
|
Before you learn about error-handling operators, you must keep in mind that
any error in a reactive sequence is a terminal event. Even if an error-handling
operator is used, it does not let the original sequence continue. Rather, it
converts the onError signal into the start of a new sequence (the fallback one). In
other words, it replaces the terminated sequence upstream of it.
|
Now we can consider each means of error handling one-by-one. When relevant, we make a
parallel with imperative programming’s try patterns.
You may be familiar with several ways of dealing with exceptions in a try-catch block. Most notably, these include the following:
-
Catch and return a static default value.
-
Catch and execute an alternative path with a fallback method.
-
Catch and dynamically compute a fallback value.
-
Catch, wrap to a
BusinessException, and re-throw. -
Catch, log an error-specific message, and re-throw.
-
Use the
finallyblock to clean up resources or a Java 7 “try-with-resource” construct.
All of these have equivalents in Reactor, in the form of error-handling operators. Before looking into these operators, we first want to establish a parallel between a reactive chain and a try-catch block.
When subscribing, the onError callback at the end of the chain is akin to a catch
block. There, execution skips to the catch in case an Exception is thrown, as the
following example shows:
Flux<String> s = Flux.range(1, 10)
.map(v -> doSomethingDangerous(v)) // (1)
.map(v -> doSecondTransform(v)); // (2)
s.subscribe(value -> System.out.println("RECEIVED " + value), // (3)
error -> System.err.println("CAUGHT " + error) // (4)
);-
A transformation that can throw an exception is performed.
-
If everything went well, a second transformation is performed.
-
Each successfully transformed value is printed out.
-
In case of an error, the sequence terminates and an error message is displayed.
The preceding example is conceptually similar to the following try-catch block:
try {
for (int i = 1; i < 11; i++) {
String v1 = doSomethingDangerous(i); // (1)
String v2 = doSecondTransform(v1); // (2)
System.out.println("RECEIVED " + v2);
}
} catch (Throwable t) {
System.err.println("CAUGHT " + t); // (3)
}-
If an exception is thrown here…
-
…the rest of the loop is skipped…
-
… and the execution goes straight to here.
Now that we have established a parallel, we can look at the different error handling cases and their equivalent operators.
The equivalent of “Catch and return a static default value” is onErrorReturn.
The following example shows how to use it:
try {
return doSomethingDangerous(10);
}
catch (Throwable error) {
return "RECOVERED";
}The following example shows the Reactor equivalent:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");You also have the option of applying a Predicate on the exception to decided
whether or not to recover, as the folloiwng example shows:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.getMessage().equals("boom10"), "recovered10"); //(1)-
Recover only if the message of the exception is
"boom10"
If you want more than a single default value and you have an alternative (safer) way of
processing your data, you can use onErrorResume. This would be the equivalent of
“Catch and execute an alternative path with a fallback method”.
For example, if your nominal process is fetching data from an external and unreliable service but you also keep a local cache of the same data that can be a bit more out of date but is more reliable, you could do the following:
String v1;
try {
v1 = callExternalService("key1");
}
catch (Throwable error) {
v1 = getFromCache("key1");
}
String v2;
try {
v2 = callExternalService("key2");
}
catch (Throwable error) {
v2 = getFromCache("key2");
}The following example shows the Reactor equivalent:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k) // (1)
.onErrorResume(e -> getFromCache(k)) // (2)
);-
For each key, asynchronously call the external service.
-
If the external service call fails, fall back to the cache for that key. Note that we always apply the same fallback, whatever the source error,
e, is.
Like onErrorReturn, onErrorResume has variants that let you filter which exceptions
to fall back on, based either on the exception’s class or on a Predicate. The fact that it
takes a Function also lets you choose a different fallback sequence to switch to,
depending on the error encountered. The following example shows how to do so:
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(error -> { // (1)
if (error instanceof TimeoutException) // (2)
return getFromCache(k);
else if (error instanceof UnknownKeyException) // (3)
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error); // (4)
})
);-
The function allows dynamically choosing how to continue.
-
If the source times out, hit the local cache.
-
If the source says the key is unknown, create a new entry.
-
In all other cases, “re-throw”.
Even if you do not have an alternative (safer) way of processing your data, you might want to compute a fallback value out of the exception you received. This would be the equivalent of “Catch and dynamically compute a fallback value”.
For instance, if your return type (MyWrapper) has a variant dedicated to holding an exception (think
Future.complete(T success) versus Future.completeExceptionally(Throwable error)), you
could instantiate the error-holding variant and pass the exception.
An imperative example would look like the following:
try {
Value v = erroringMethod();
return MyWrapper.fromValue(v);
}
catch (Throwable error) {
return MyWrapper.fromError(error);
}You can do this reactively in the same way as the fallback method solution,
by using onErrorResume, with a tiny bit of boilerplate, as follows:
erroringFlux.onErrorResume(error -> Mono.just( // (1)
MyWrapper.fromError(error) // (2)
));-
Since you expect a
MyWrapperrepresentation of the error, you need to get aMono<MyWrapper>foronErrorResume. We useMono.just()for that. -
We need to compute the value out of the exception. Here, we achieved that by wrapping the exception with a relevant
MyWrapperfactory method.
"Catch, wrap to a BusinessException, and re-throw" looks like the following in the
imperative world:
try {
return callExternalService(k);
}
catch (Throwable error) {
throw new BusinessException("oops, SLA exceeded", error);
}In the “fallback method” example, the last line inside the flatMap gives us a hint
at achieving the same reactively, as follows:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original))
);However, there is a more straightforward way of achieving the same effect with onErrorMap:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));For cases where you want the error to continue propagating but still want to react to
it without modifying the sequence (logging it, for instance), you can use the doOnError
operator. This is the equivalent of “Catch, log an error-specific message, and re-throw”
pattern, as the following example shows:
try {
return callExternalService(k);
}
catch (RuntimeException error) {
//make a record of the error
log("uh oh, falling back, service failed for key " + k);
throw error;
}The doOnError operator, as well as all operators prefixed with doOn , are sometimes
referred to as having a “side-effect”. They let you peek inside the sequence’s events without
modifying them.
Like the imperative example shown earlier, the following example still propagates the error yet ensures that we at least log that the external service had a failure:
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k) // (1)
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k); // (2)
})
// (3)
);-
The external service call that can fail…
-
…is decorated with a logging and stats side-effect…
-
…after which, it still terminates with an error, unless we use an error-recovery operator here.
We can also imagine we have statistic counters to increment as a second error side-effect.
The last parallel to draw with imperative programming is the cleaning up that can be done
either by using a “Use of the finally block to clean up resources” or by using a
“Java 7 try-with-resource construct”, both shown below:
Stats stats = new Stats();
stats.startTimer();
try {
doSomethingDangerous();
}
finally {
stats.stopTimerAndRecordTiming();
}try (SomeAutoCloseable disposableInstance = new SomeAutoCloseable()) {
return disposableInstance.toString();
}Both have their Reactor equivalents: doFinally and using.
doFinally is about side-effects that you want to be executed whenever the
sequence terminates (with onComplete or onError) or is cancelled.
It gives you a hint as to what kind of termination triggered the side-effect.
The following example shows how to use doFinally:
doFinally()Stats stats = new Stats();
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doOnSubscribe(s -> stats.startTimer())
.doFinally(type -> { // (1)
stats.stopTimerAndRecordTiming();// (2)
if (type == SignalType.CANCEL) // (3)
statsCancel.increment();
})
.take(1); // (4)-
doFinallyconsumes aSignalTypefor the type of termination. -
Similarly to
finallyblocks, we always record the timing. -
Here we also increment statistics in case of cancellation only.
-
take(1)cancels after one item is emitted.
On the other hand, using handles the case where a Flux is derived from a
resource and that resource must be acted upon whenever processing is done.
In the following example, we replace the AutoCloseable interface of “try-with-resource” with a
Disposable:
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true); // (4)
}
@Override
public String toString() {
return "DISPOSABLE";
}
};Now we can do the reactive equivalent of “try-with-resource” on it, which looks like the following:
using()Flux<String> flux =
Flux.using(
() -> disposableInstance, // (1)
disposable -> Flux.just(disposable.toString()), // (2)
Disposable::dispose // (3)
);-
The first lambda generates the resource. Here, we return our mock
Disposable. -
The second lambda processes the resource, returning a
Flux<T>. -
The third lambda is called when the
Fluxfrom <2> terminates or is cancelled, to clean up resources. -
After subscription and execution of the sequence, the
isDisposedatomic boolean becomestrue.
In order to demonstrate that all these operators cause the upstream original sequence to
terminate when an error happens, we can use a more visual example with a
Flux.interval. The interval operator ticks every x units of time with an increasing
Long value. The following example uses an interval operator:
Flux<String> flux =
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.onErrorReturn("Uh oh");
flux.subscribe(System.out::println);
Thread.sleep(2100); // (1)-
Note that
intervalexecutes on a timerSchedulerby default. If we want to run that example in a main class, we would need to add asleepcall here so that the application does not exit immediately without any value being produced.
The preceding example prints out one line every 250ms, as follows:
tick 0
tick 1
tick 2
Uh ohEven with one extra second of runtime, no more tick comes in from the interval. The
sequence was indeed terminated by the error.
There is another operator of interest with regards to error handling, and you might be
tempted to use it in the case described in the previous section. retry, as its name
indicates, lets you retry an error-producing sequence.
The thing to keep in mind is that it works by re-subscribing to the upstream Flux.
This is really a different sequence, and the original one is still terminated.
To verify that, we can re-use the previous example and append a retry(1) to
retry once instead of using onErrorReturn. The following example shows how to do sl:
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.retry(1)
.elapsed() // (1)
.subscribe(System.out::println, System.err::println); // (2)
Thread.sleep(2100); // (3)-
elapsedassociates each value with the duration since previous value was emitted. -
We also want to see when there is an
onError. -
Ensure we have enough time for our 4x2 ticks.
The preceding example produces the following output:
259,tick 0
249,tick 1
251,tick 2
506,tick 0 (1)
248,tick 1
253,tick 2
java.lang.RuntimeException: boom-
A new
intervalstarted, from tick 0. The additional 250ms duration is coming from the 4th tick, the one that causes the exception and subsequent retry.
As you can see from the preceding example, retry(1) merely re-subscribed to the original interval
once, restarting the tick from 0. The second time around, since the exception
still occurs, it gives up and propagates the error downstream.
There is a more advanced version of retry (called retryWhen) that uses a “companion”
Flux to tell whether or not a particular failure should retry. This companion Flux is
created by the operator but decorated by the user, in order to customize the retry
condition.
The companion Flux is a Flux<RetrySignal> that gets passed to a Retry strategy/function,
supplied as the sole parameter of retryWhen. As the user, you define that function and make it return a new
Publisher<?>. The Retry class is an abstract class, but it offers a factory method if you
want to transform the companion with a simple lambda (Retry.fromFunction(Function)).
Retry cycles go as follows:
-
Each time an error happens (giving potential for a retry), a
RetrySignalis emitted into the companionFlux, which has been decorated by your function. Having aFluxhere gives a bird eye’s view of all the attempts so far. TheRetrySignalgives access to the error as well as metadata around it. -
If the companion
Fluxemits a value, a retry happens. -
If the companion
Fluxcompletes, the error is swallowed, the retry cycle stops, and the resulting sequence completes, too. -
If the companion
Fluxproduces an error (e), the retry cycle stops and the resulting sequence errors withe.
The distinction between the previous two cases is important. Simply completing the
companion would effectively swallow an error. Consider the following way of emulating
retry(3) by using retryWhen:
Flux<String> flux = Flux
.<String>error(new IllegalArgumentException()) // (1)
.doOnError(System.out::println) // (2)
.retryWhen(Retry.fromFunction(companion -> // (3)
companion.take(3))); // (4)-
This continuously produces errors, calling for retry attempts.
-
doOnErrorbefore the retry lets us log and see all failures. -
The
Retryis adapted from a very simpleFunctionlambda -
Here, we consider the first three errors as retry-able (
take(3)) and then give up.
In effect, the preceding example results in an empty Flux, but it completes successfully. Since
retry(3) on the same Flux would have terminated with the latest error, this
retryWhen example is not exactly the same as a retry(3).
Getting to the same behavior involves a few additional tricks: snippetRetryWhenRetry.adoc
|
Tip
|
One can use the builders exposed in Retry to achieve the same in a more fluent manner, as
well as more finely tuned retry strategies. For example: errorFlux.retryWhen(Retry.max(3));.
|
|
Tip
|
You can use similar code to implement an “exponential backoff and retry” pattern, as shown in the FAQ. |
The core-provided Retry helpers, RetrySpec and RetryBackoffSpec, both allow advanced customizations like:
-
setting the
filter(Predicate)for the exceptions that can trigger a retry -
modifying such a previously set filter through
modifyErrorFilter(Function) -
triggering a side effect like logging around the retry trigger (ie for backoff before and after the delay), provided the retry is validated (
doBeforeRetry()anddoAfterRetry()are additive) -
triggering an asynchronous
Mono<Void>around the retry trigger, which allows to add asynchronous behavior on top of the base delay but thus further delay the trigger (doBeforeRetryAsyncanddoAfterRetryAsyncare additive) -
customizing the exception in case the maximum number of attempts has been reached, through
onRetryExhaustedThrow(BiFunction). By default,Exceptions.retryExhausted(…)is used, which can be distinguished withExceptions.isRetryExhausted(Throwable) -
activating the handling of transient errors (see below)
Transient error handling in the Retry specs makes use of RetrySignal#totalRetriesInARow(): to check whether to retry or not and to compute the retry delays, the index used is an alternative one that is reset to 0 each time an onNext is emitted.
This has the consequence that if a re-subscribed source generates some data before failing again, previous failures don’t count toward the maximum number of retry attempts.
In the case of exponential backoff strategy, this also means that the next attempt will be back to using the minimum Duration backoff instead of a longer one.
This can be especially useful for long-lived sources that see sporadic bursts of errors (or transient errors), where each burst should be retried with its own backoff.
AtomicInteger errorCount = new AtomicInteger(); // (1)
AtomicInteger transientHelper = new AtomicInteger();
Flux<Integer> transientFlux = Flux.<Integer>generate(sink -> {
int i = transientHelper.getAndIncrement();
if (i == 10) { // (2)
sink.next(i);
sink.complete();
}
else if (i % 3 == 0) { // (3)
sink.next(i);
}
else {
sink.error(new IllegalStateException("Transient error at " + i)); // (4)
}
})
.doOnError(e -> errorCount.incrementAndGet());
transientFlux.retryWhen(Retry.max(2).transientErrors(true)) // (5)
.blockLast();
assertThat(errorCount).hasValue(6); // (6)-
We will count the number of errors in the retried sequence.
-
We
generatea source that has bursts of errors. It will successfully complete when the counter reaches 10. -
If the
transientHelperatomic is at a multiple of3, we emitonNextand thus end the current burst. -
In other cases we emit an
onError. That’s 2 out of 3 times, so bursts of 2onErrorinterrupted by 1onNext. -
We use
retryWhenon that source, configured for at most 2 retry attempts, but intransientErrorsmode. -
At the end, the sequence reaches
onNext(10)and completes, after6errors have been registered inerrorCount.
Without the transientErrors(true), the configured maximum attempt of 2 would be reached by the second burst and the sequence would fail after having emitted onNext(3).
In general, all operators can themselves contain code that potentially trigger an exception or calls to a user-defined callback that can similarly fail, so they all contain some form of error handling.
As a rule of thumb, an unchecked exception is always propagated through onError. For
instance, throwing a RuntimeException inside a map function translates to an
onError event, as the following code shows:
Flux.just("foo")
.map(s -> { throw new IllegalArgumentException(s); })
.subscribe(v -> System.out.println("GOT VALUE"),
e -> System.out.println("ERROR: " + e));The preceding code prints out the following:
ERROR: java.lang.IllegalArgumentException: foo|
Tip
|
You can tune the Exception before it is passed to onError, through the use of a
hook.
|
Reactor, however, defines a set of exceptions (such as OutOfMemoryError) that are
always deemed to be fatal. See the Exceptions.throwIfFatal method. These errors mean that
Reactor cannot keep operating and are thrown rather than propagated.
|
Note
|
Internally, there are also cases where an unchecked exception still cannot be
propagated (most notably during the subscribe and request phases), due to concurrency
races that could lead to double onError or onComplete conditions. When these races
happen, the error that cannot be propagated is “dropped”. These cases can still be
managed to some extent by using customizable hooks. See [hooks-dropping].
|
You may ask: “What about checked exceptions?”
If, for example, you need to call some method that declares it throws exceptions, you
still have to deal with those exceptions in a try-catch block. You have several
options, though:
-
Catch the exception and recover from it. The sequence continues normally.
-
Catch the exception, wrap it into an unchecked exception, and then throw it (interrupting the sequence). The
Exceptionsutility class can help you with that (we get to that next). -
If you need to return a
Flux(for example, you are in aflatMap), wrap the exception in an error-producingFlux, as follows:return Flux.error(checkedException). (The sequence also terminates.)
Reactor has an Exceptions utility class that you can use to ensure that exceptions are
wrapped only if they are checked exceptions:
-
Use the
Exceptions.propagatemethod to wrap exceptions, if necessary. It also callsthrowIfFatalfirst and does not wrapRuntimeException. -
Use the
Exceptions.unwrapmethod to get the original unwrapped exception (going back to the root cause of a hierarchy of reactor-specific exceptions).
Consider the following example of a map that uses a conversion method that can throw an
IOException:
public String convert(int i) throws IOException {
if (i > 3) {
throw new IOException("boom " + i);
}
return "OK " + i;
}Now imagine that you want to use that method in a map. You must now explicitly catch
the exception, and your map function cannot re-throw it. So you can propagate it to the
map’s onError method as a RuntimeException, as follows:
Flux<String> converted = Flux
.range(1, 10)
.map(i -> {
try { return convert(i); }
catch (IOException e) { throw Exceptions.propagate(e); }
});Later on, when subscribing to the preceding Flux and reacting to errors (such as in the
UI), you could revert back to the original exception if you want to do something
special for IOExceptions. The following example shows how to do so:
converted.subscribe(
v -> System.out.println("RECEIVED: " + v),
e -> {
if (Exceptions.unwrap(e) instanceof IOException) {
System.out.println("Something bad happened with I/O");
} else {
System.out.println("Something bad happened");
}
}
);