[BUG] Abnormally high CPU usage on Kubernetes 1.24.4 #38816
Comments
|
Can confirm. This is affecting RKE1 clusters, and it doesn't matter whether it's an upgrade or a new installation. Depending on the number of pods, even when there are no state changes, The affected 5.15 kernel is called Unbreakable Enterprise Kernel 7 by Oracle. |
|
It seems this is not caused by OEL or it's kernel, since the same symptoms can be reproduced on a CentOS 7 worker node. Is it possible that the fix for rancher/rke#2938 didn't make it into Rancher 2.6.8 yet? We can see that Additionally, the |
|
This is a known issue: #38214 where we see the unexpected high memory usage of dockerd on OL 8.4 and 8.6 on k8s 1.24 |
|
@jiaqiluo I don't believe this to be the same issue. In our setup, we don't see any if the error messages your linked report contains, and neither is memory consumption of the Docker daemon increased (see screenshots of the initial reporter). EDIT: I stand corrected on the memory consumption, sorry (normally it's around 500-600M): The above is from an 1.23.10 RKE1 cluster with cri-dockerd enabled. If it's of any interest, these are bare metal nodes, not AWS instances. |
|
@jiaqiluo Would it help if we were able to recreate this problem with CentOS 7? If so, I'll setup a new worker node and join it. The above is from an 1.23.10 cluster. |
|
Hi @cite , it would be great if you could try it on CentOS 7 with RKE1 k8s 1.24.x? Can you also share the docker version on the node? |
|
@jiaqiluo This is not easy to pin down. I deployed a completely new RKE1 cluster with Rancher 2.6.8, two nodes OEL 8.6 with the default 4.18 kernel, one node with CentOS 7.9 with it's default 3.18 kernel. After deploying a cluster with version 1.23.10-rancher1 and enabling There was no difference between OEL 8.6 and CentOS 7.9 workers. Furthermore, the Again, there was no difference between the CentOS 7.9 and OEL 8.6 workers. The metrics performance is suprising, because rancher/rke#2938 states that the version of For all nodes, memory consumption of When disabling Upgrading the cluster to 1.24.4 didn't make any difference to the situation of running 1.23.10 with Looking at the code changes for Mirantis/cri-dockerd#38, it seems that metrics are available faster in that case because collecting them is parallelized by distributing the work to several goroutines. Is it possible that with a large number of pods, the parallel queries overwhelm Conclusion: Enabling Do you want me to perform other tests or ship more data? |
|
I've observed the same behavior on Ubuntu 20.04 LTS (RKE 1.24.4 from Rancher 2.6.8) |
|
Same issue, independent of whether I upgrade from 1.23.10 to 1.24.4 or install 1.24.4 right away - CPU usage on the nodes goes through the roof, with dockerd continuously using 290 to 310%. Stopping kube-metrics-server and Prometheus ease the situation somewhat, but CPU usage remains high. Right on the time of the upgrade, error messages appear in metrics server:
|
|
|

|
I tried to reproduce on 2.6.8 Reproduction Steps
Upgrade
Result Update |
|
@thaneunsoo Were you able to reproduce metrics timings (with EDIT: If the problem is related to metrics (or other interactions between |
|
After @thaneunsoo tried to reproduce the issue and failed, I had another go: Rancher 2.6.8, 3-node custom downstream cluster on Azure VMs with v1.23.10-rancher1-1 on Ubuntu 20.04.5 LTS / Docker 20.10.18 with Kernel: Linux rke-6d3730-0 5.15.0-1019-azure #24~20.04.1-Ubuntu SMP Tue Aug 23 15:52:52 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux Top shows minimal CPU consumption, same for Grafana.
|


|
Next step, updating from the Rancher UI to v1.24.4-rancher1-1 CPU consumption goes way up, both in top and in Grafana:
|
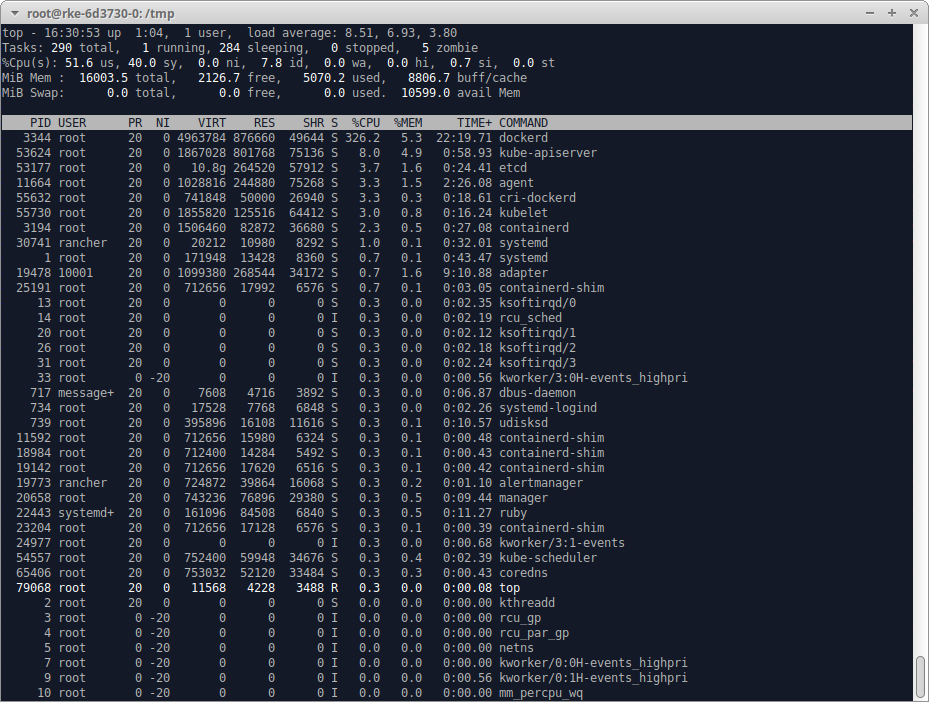

|
Observations: 1/ metrics server complains about: 2/ docker complains a lot about: |
|
dockerd spends most of its time in path/filepath.Clean and runtime.scanobject, according to perf top strace shows that it seems to be iterating/looping around content in/var/lib/rancher-data/local-catalogs/, repeatedly calling lgetxattr() and newfstatat(), with repeated SIGURGs in between |
|
Moved this to v2.7-KDM-For-2.6.11 milestone, the move of changes to correct KDM branch is being done per rancher/kontainer-driver-metadata#1089. |
|
@thaneunsoo please validate on 2.7.1 Rancher using |
|
@kinarashah Will this fix be included in standalone RKE1 clusters, too? If so, do you know which version of RKE1 the changes are targeted for? |
|
@cite Yeah, the standalone RKE versions |
|
thaneunsoo said: ### Test Environment: ### Downstream cluster type: rke1 Testing:Tested this issue with the following steps:
Side note
Cases covered:
Result 1. overlay with native diff true
2. overlay with native diff false
3. overlay2 with native diff true
4. overlay2 with native diff false
Additional Testing
Result |









|
@thaneunsoo @git-ival KDM branch: |
Test Environment:Rancher Cluster Config:Rancher version: v2.7.1 with KDM Downstream Cluster Config:Downstream cluster type: HA RKE1, 5 etcd nodes, 6 control-plane nodes, 10 worker nodes Reproduction Results:I was able to reproduce on Overlay repro:
Overlay2 Native Diff false repro:
Overlay2 Native Diff true repro:
Test Steps:
Notes:
Cases covered:
Test Case Results:Overlay - Test Case Results:Pre Pod Scale-in Phase:
Post Pod Scale-in:
Overlay2 Native Diff false - Test Case Results:Pre Pod Scale-in Phase:
Post Pod Scale-in:
Overlay2 Native Diff true - Test Case Results:Pre Pod Scale-in Phase:
Post Pod Scale-in:
|
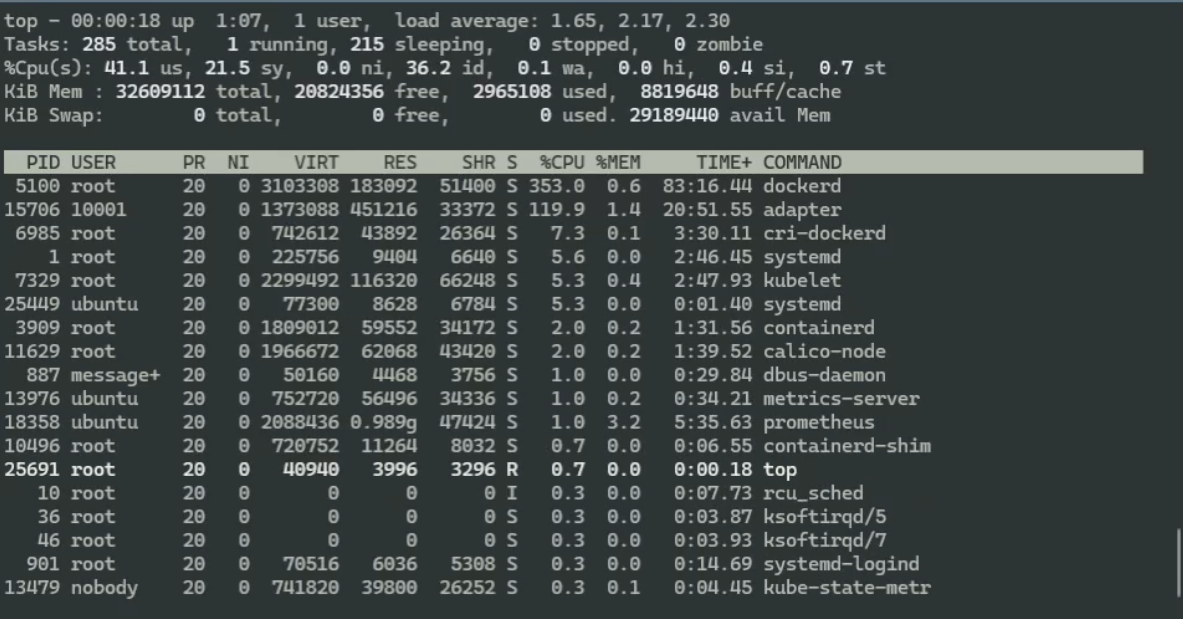








|
Validations completed, closing. |
|
Hi @kinarashah thanks so much for your hard work. I know it's not GA but we've deployed 1.25.6-rancher4-1 to our dev cluster and have seen massive reduction in CPU usage. |
|
Can confirm the CPU issue fixed: upgraded v1.23.16-rancher2-1 -> v1.24.13-rancher2-1 with |
Rancher Server Setup
Information about the Cluster
User Information
Describe the bug
When creating a Custom downstream cluster with Kubernetes v1.24.x and using servers with Oracle Linux 8.6 and the kernel-uek-core 5.15, the CPU usage goes abnormally high. This issue does not occur with the Kernel kernel-core 4.18 and Kubernetes 1.24.x. No extra pods have to be deployed. It will occur immediately after the node is registered into the cluster
To Reproduce
Result
CPU usage goes abnormally high. While only minimum of pods are deployed
Because of this, pods are getting killed because of a shortage on CPU.
Expected Result
Normal CPU usage.
Screenshots





Additional context
SURE-5282
The text was updated successfully, but these errors were encountered: