This script is the primary mechanism for adding new content (quotes, authors and tags). It takes a list of quotes from an input file, filters out any duplicates, then adds the new quotes to the collection. It will also identify any authors and tags that do not already exist, create them and add them to their respective collections.
The default location for the input file is input/quotes.json. If you use the default location you can omit the <inputFile> argument.
$ node cli/addQuotes <inputFile>| name | default | description |
|---|---|---|
<inputFile> |
quotes.json |
Path to input file (relative to <projectRoot>/input/) |
--dryRun, -d |
false |
If true, script will run without modifying files |
--verbose, -v |
false |
Script will output details about the data being added |
--cleanup, -c |
false |
If true, deletes input file after operation is complete |
--dataDir |
data/source |
Only for testing purposes. Use the default value |
The input file should be a JSON file containing an array of quotes that you want to add. Each item should be an object with the following properties. All other fields will be added automatically.
interface QuoteInput {
// The quote content
content: string
// The author's name (as it appears on their wikipedia page)
author: string
// A list of tag names
tags?: string[]
}
type inputFile = QuoteInput[]It starts by filtering out any duplicate quotes that already exist. When comparing quotes, it ignores punctuation, case, and stopwords to avoid multiple variations of the same quote.
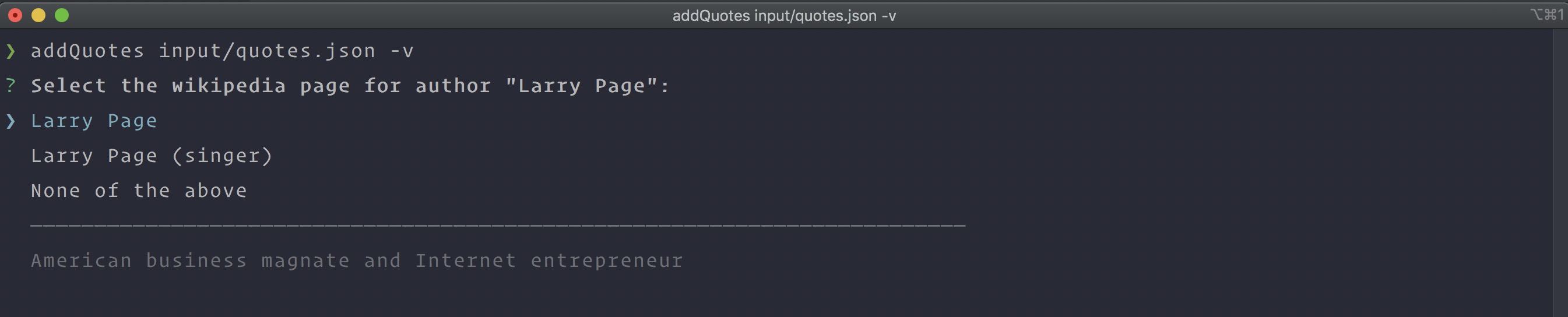
It starts by matching each author name in the input data to a wikipedia page. If it does not find an exact match for a given author name, the script will prompt the user to select the intended person from a list of suggestions. If the author name in the input data is different than the name on the person's wikipedia page, it will use the name on the wikipedia page. This avoids duplicate authors caused by different name variations ("John Kennedy" and "John F. Kennedy") or misspellings.
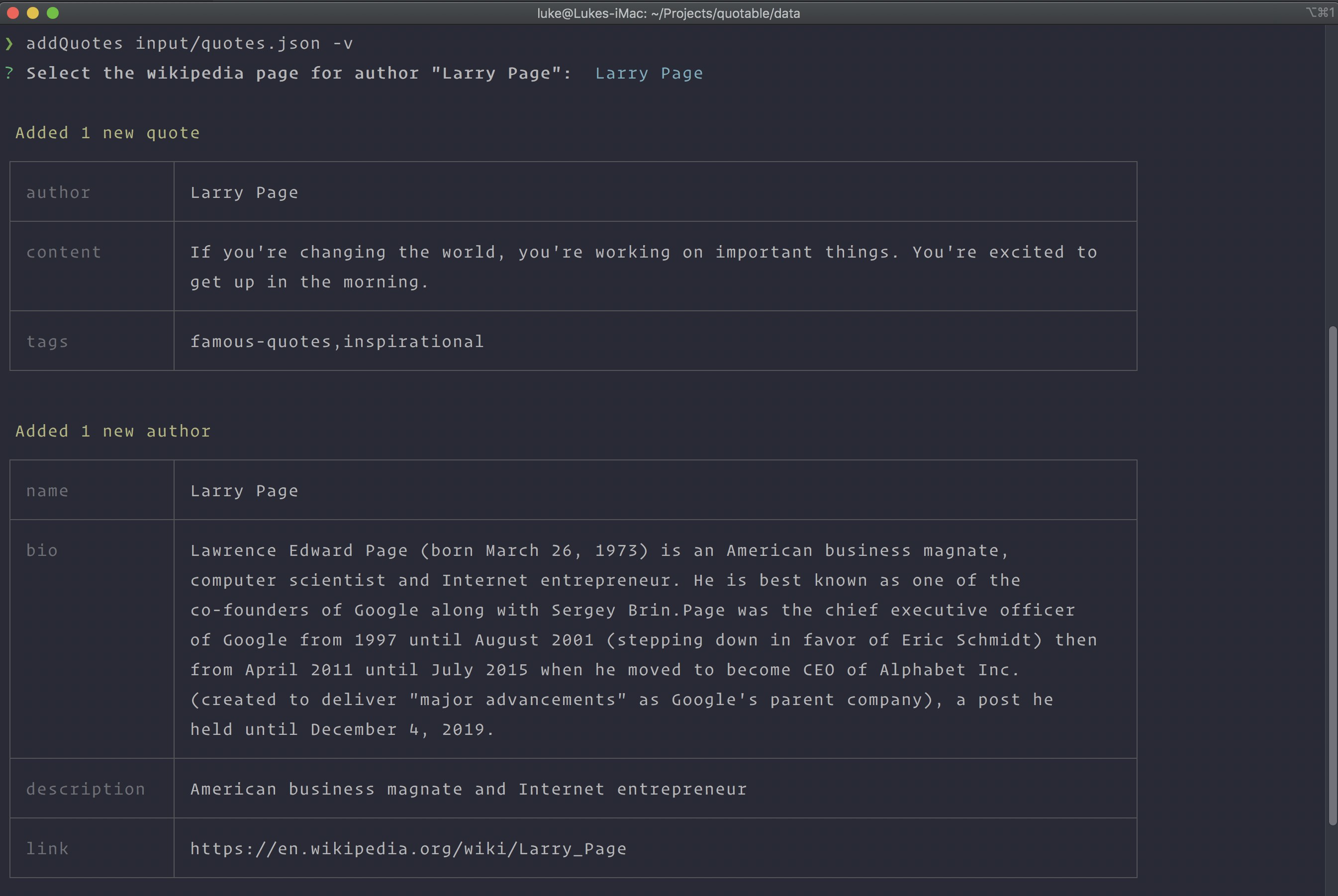
The script will create the necessary Author objects, using data from the wiki API to get the values for bio, description, link, etc.
TODO: this does not currently handle author profile images
Any new tags will be created and added to the tags collection. Please try to avoid creating duplicate tags (ie "inspiration" and "inspirational").
// input/quotes.json
[
{
"content": "If you're changing the world, you're working on important things. You're excited to get up in the morning.",
"author": "Larry Page",
"tags": ["famous-quotes", "inspirational"]
}
]$ node cli/addQuotes input/quotes.json -vIn this example, there are two people on wikipedia named "Larry Page", so the script will prompt us to choose the correct person.