EXIF inconsistencies for "UserComment" tag #5254
Comments
|
Hi. If your goal is just to be able to read the comment, rather than changing the output of Is that what you're after? Or would you like to solve this Exif consistency? |
|
Exif spec says that 8 null bytes are used to indicate an "Undefined" character code, so the Android image is perfectly valid in that sense.
|
I wasn't really trying to accomplish anything, but rather debugging some corrupted images and comparing valid ones from multiple devices. After some testing, I noticed this inconsistency and wondered why Pillow wasn't parsing that key every time, so decided to report it. Do you think it's an expected behaviour? For me, it really looks like a bug. @kmilos you are right, the android one is also "perfectly fine", although in my testing, the payload was always ascii, and using any unicode character would end up as "??", so my guess is that Android also uses ascii encoding, but fails to set the encoding. Therefore, it would be "better implemented" if Android also included the same bytes iOS does. Either way, you are both right, both images are properly encoded. So why does Pillow fail to decode one of them? |
|
Sorry @cristianoccazinsp on second look I am now also confused... For the Android image, exiv2 (or exiftool) reports only 120 bytes for that field, and just the content as you see it (plus the null termination character), and there is no required 8 bytes for character code preceding the message - i.e. the null bytes your hex editor screenshot were just a coincidence and that threw me off... The filed type is however already set as ASCII and that's how any app knows in advance how to decode it... iPhone reports 135 bytes which indeed include 8 bytes of code + 127 bytes of (unterminated) message, but the field type is UNDEFINED, and that's why a binary stream is returned, the app needs to decode it itself. The current Exif 2.32 spec clearly says the filed type should be UNDEFINED and the 8 byte code included at the start, so the Android must be implementing some older version of the spec, or they're just betting on apps doing the right thing when they see a plain old ASCII field... So I don't really think Pillow is doing anything wrong, it just returns what it grabs from the field directly. |
|
Now I'm a bit confused as well! So, does PIL parse the values correctly? I was also testing with another exif library (https://github.com/ianare/exif-py), and in that case, both parse the UserComment just fine (no binary data returned). |
|
That library might go through the extra trouble to introduce another level of decoding when it comes across a byte stream returned. |
|
Yep, it does. 0x9286: ('UserComment', make_string_uc),def make_string_uc(seq) -> str:
"""
Special version to deal with the code in the first 8 bytes of a user comment.
First 8 bytes gives coding system e.g. ASCII vs. JIS vs Unicode.
"""
if not isinstance(seq, str):
seq = seq[8:]
# Of course, this is only correct if ASCII, and the standard explicitly
# allows JIS and Unicode.
return make_string(seq) |
|
So you're just trying to point out a bug, but the discussion here has concluded that there is no bug. Can this be closed then? |
|
Yes, not a bug, but perhaps a possible improvement for this special case? |
|
Pillow not only reads EXIF tags, but also allows them to be written. To bring it back to my original comment, I'd be more interested in adding a "comment" key to the image's |
|
Ah, I'm wrong. I've been talking about adding a "comment" to TIFFs, but these aren't TIFFs, they're JPEGs - that format already has a "comment". |
|
My next idea would be to add a dedicated |
|
Since
I think it is best to keep the behaviour as is. If there is no interest in another method of obtaining that data in a handier way, then I'm going to close this for now. |
What did you do?
Read an image's exif with
im.getexif.items().What did you expect to happen?
"UserComment" (tag 37510) should be properly decoded from images,
What actually happened?
An image captured on an Android device was decoded just fine. However, a similar image generated by the same app from iOS, failed to correctly parse the exif tag, and ended up as binary.
What are your OS, Python and Pillow versions?
Output:
tobytesoutput:Hex view of the android image:

Hex view of the iOS image:
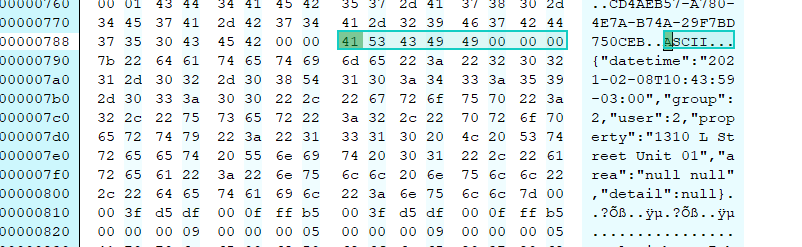
For me, it seems like the iOS image is the "correct" one, including the encoding as per the exif documentation (https://www.awaresystems.be/imaging/tiff/tifftags/privateifd/exif/usercomment.html). Whereas, the android one seems a bit invalid (no encoding info), but yet Pillow parses it fine.
I'm also attaching the two images I've used for testing:
The text was updated successfully, but these errors were encountered: