Return proper exit code for TERM signal #1337
Conversation
eddad58
to
3fa684d
Compare
08f16c9
to
fd38f5c
Compare
|
Note if this is merged (or #1183 is fixed as intended) that systemd service configs, as in /docs/systemd, should be updated to include: SuccessExitStatus=143...to avoid normal shutdown/restart reporting warning and a failed state. I'm assuming this isn't a systemd default because traditional, forked unix daemons only return an exit status during startup (before forking away). |
|
@dekellum Thanks for the review! I believe both
Source: https://www.freedesktop.org/software/systemd/man/systemd.service.html So, for instance, if we were to run a systemd service, with Existing implementations still wont be affected, because the exit status being returned until this PR was Let me know if I missed something :) and/or if you think it might be worth adding a note about success exit handlers in https://github.com/puma/puma/blob/master/docs/systemd.md ? |
|
I agree that your interpretation of the systemd docs is plausible and that the docs are not particularly clear. I've assumed that But perhaps the JVM is doing something wrong, while your PR does it correctly? Next I've gone ahead and setup a direct test of your changes, using MRI ruby. Here is the complete tree for this test application (branch 'puma'): https://github.com/dekellum/lionfish With this setup if I use your exact PR branch, it fails on startup here: If I instead cherrypick fd38f5c onto a new testing branch rooted at the v3.9.1 tag, it starts correctly but I get this error on stop: So in summary, I'm finding other problems on the master branch and/or your change that occur before I can even determine if the |
|
The Again with the workaround, if I merge this PR to master it also works. My cherry-picked variant based on v3.9.1 has that other error, but I don't think its relevant to this PR and current master. So I guess the JVM has it wrong and you have it right, at least for MRI. Thanks @shayonj. Next I want to check this with jruby (on JVM). |
|
OK this PR seems to also work fine under jruby with systemd (without socket activation), and |
|
Thanks so much for such a thorough review @dekellum 🎉 . Yes, I have puma running using systemd config on my VPS, now that I am thinking, I should have perhaps shared the config here :). And yes MRI ruby. Another quick way to test Lastly, exit(143) is different than kill("TERM"). |
|
TL;DR on the above: No additional changes to the existing implementation was introduced and |
|
Please add test for this |
|
@stereobooster do you mean tests for making sure the right exit status code is returned? I suppose, verifying the exit status of a server (or process) exit from within an existing process (test suite) could be tricky ( I am going to attempt it and also look into any other additional way to expect/assert the trapping of Signal |
|
It is supposed to integration test. By idea you should launch instance of puma in subshell and capture return status from it. need to google on how to capture respond code in this scenario |
3928781
to
f43ceea
Compare
|
@stereobooster yes I am going for integration tests. I was looking for a way to working with sub process. I have added some integration tests, they pass locally for me, but appears to be failing in TravisCI. Looks like re-raising/killing the process might be causing an exception to be raised. I will follow up on this soon. Also, the |
test/test_integration.rb
Outdated
| _, status = Process.wait2(@server.pid) | ||
| assert_equal 15, status | ||
|
|
||
| @server = nil |
There was a problem hiding this comment.
@server.close
@server = nil8db6ee5
to
c9eca37
Compare
96fa815
to
d4b5ad2
Compare
|
r? @schneems (I see you worked on the launcher migration) or @nateberkopec || @stereobooster |
|
We can do something like this to re-raise the exact exception https://stackoverflow.com/questions/29568298/run-code-when-signal-is-sent-but-do-not-trap-the-signal-in-ruby |
Attempt at returning the proper exit code (128+15) when TERM signal is sent to the server, for both single and clustered mode. The changes are achieved by restoring signal from within the trap and accordingly killing the process using TERM event. Added plus, stopping single mode gracefully now.
d4b5ad2
to
2f4c7ba
Compare
|
TIL, we can re-raise the same signal exception instead of restoring signal and killing the process. Updated 🙂 |
|
Hi, with the applied changes (3.10) I get an error on heroku during a restart:
is this intended (in terms of me having to catch the exception somehow)? |
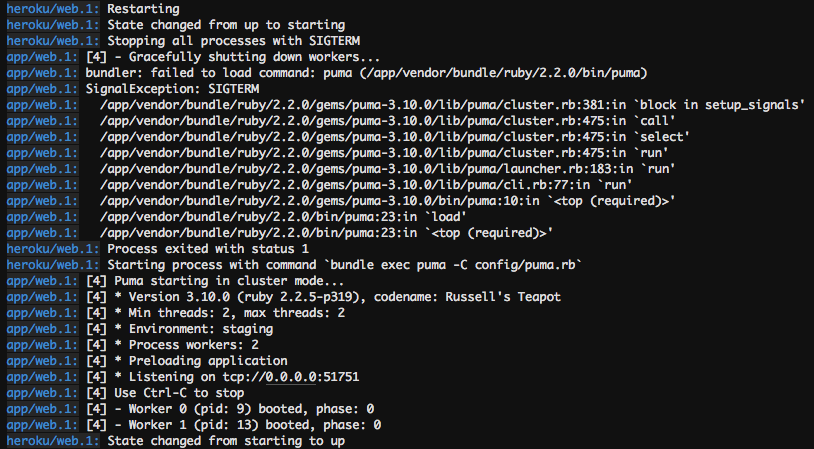
|
This PR was merged. I suggest you (@wodka) please create a new issue for this, including the text of the error. I do believe the change of this PR has uncovered a bug, but the bug probably resides with how bundler's |
Attempt at returning the proper exit code (128+15) when TERM signal
is sent to the server, for both single and clustered mode.
The changes are achieved by restoring signal from within the trap
and accordingly killing the process using TERM event.
Added plus, stopping single mode gracefully now.
Potential fix for : #1183