Prometheus restart very slowly when the size of data folder is huge #611
Comments
I think the loading needs to happen sequentially so that the series Id are loaded first and than the samples can be matched against these series.
I think Fabian mentioned that he experimented with a different buffer sizes, but no harm in experimenting again. |
|
2.6 already includes big improvements. I'd wonder if it's the CPU that got maxed out, or your disk. |
|
Thanks for this quick replay! My prometheus run as pod in KUBERNETES cluster which cpu limit is 30 cores and disk mount to hostPath which is NVME ssd. When i restart prometheus with 50G WAL that will takes too long time to restart. Later on, i will upgrade the prometheus to v2.10.0 and then profiling it also provide the cpu.profile file for us. |
|
Can you show the output of |
|
Below is not k8s cluster that is run as systemd, wal is prometheus version: v2.6.1 Start 2 minutes: Start after about 2 minutes which going to stable: Restart will takes 1 hour Cpu profile |
|
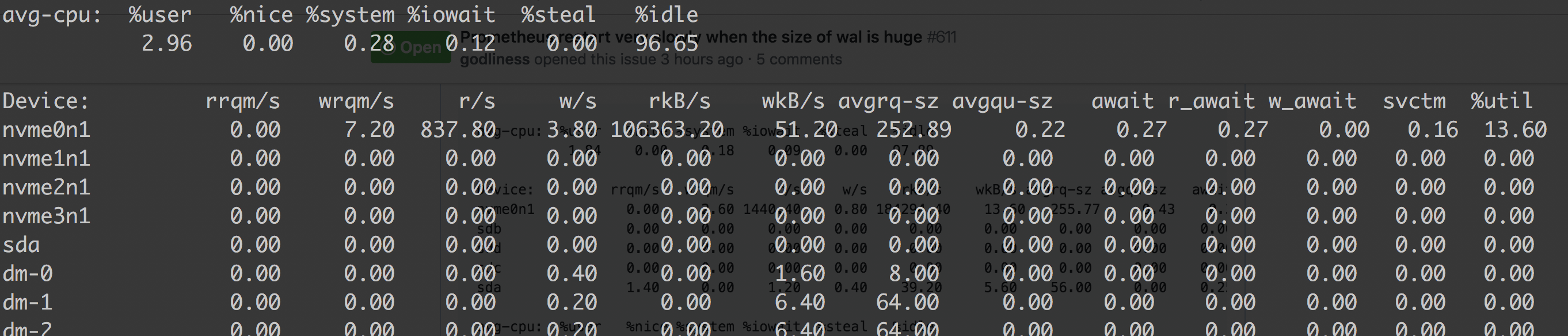
Below is our K8S cluster prometheus run as pod, version is 2.6.0 WAL: It's very stable which is about 100MB/s on the nvme device ssd.
Restart will takes 11 minutes. cpu profile |


|
There's tons of spare CPU there, so this sounds like a throughput issue on your disk. |
|
These are more or less the same timings we see at Prombench. |
|
I have tested my disk device on the k8s node with prometheus pod. Test Disk I/O write: Test Disk I/O Read: So the read speed looks good from testing i think, but when prometheus read from the same device and the speed is about 100MB/s; i guess there are some limits in wal reader, but i'm not sure and still finding evidence to prove it. @krasi-georgiev Do you mean that you hav already find the reading bottleneck of tsdb by Prombench? |
|
I meant that when running benchmarking test on Prombench the startup time after a restart is around 14m which is similar to what you have observed. Here is link to the comment for the startup time of the the last test we did. |
|
How many cores do you have, and is there hyperthreading? |
@krasi-georgiev Thanks, i will look into it. |
|
Try setting GOMAXPROCS to 12 or 24. The hyperthreads tend to result in the goroutines fighting each other a bit. |
|
@brian-brazil I also take a further look into the code that reload and loadWAL both will takes about 10 minutes, not only loadWAL, reload will takes about 5 minutes, and loadWAL will take about 5 minutes also. Below i have two ways wanna to improve the restart speed:
Do you have any ideas about these ideas? |
|
reload should be extremely fast - and we need to wait on it in any case. Large indexes could explain it, that sounds kinda big. |
|
Yes, index file is big, since our Kubernetes cluster has 1500 nodes and multi samples collected(also collect metrics of pods and nodes). I'm not sure why , but i will look the code again.
Do you think this is a good way to reload multi blocks which index file is big?
|
|
Closing this issue if it is not an issue for us, thanks for your help @brian-brazil @krasi-georgiev |
|
reading the index in separate go routines is not a bad idea, but probably a lot of work to make it race conditions free. If anyone has the time to experiment would be happy to review a PR. |
Prometheus need replay the whole wal to provide service, before that we access the prometheus web page which display "service unavailable".
Below is my condition
size of wal: 50G
startup params:
go version: 1.12.5
prometheus version: 2.6.0
When i restart prometheus which will cost me about 9 minutes, use
iostatto check the read speed which is about 100MB/s on device nvme ssd disk.As i know, when prometheus restart that it will load wal synchronously and send the content into input channel and goroutines(cpu counts) will
processWALSamplesconcurrently.loadWALwill load wal one by one and depends on fixed buf size, why we do not load it concurrently or enlarge the buf size to improve the restart efficiency?And do you have any other good ideas to cut down the restart time?
Many thanks for any possible help!
/cc @brian-brazil @krasi-georgiev
The text was updated successfully, but these errors were encountered: