Future of osx GPU support #2489
Comments
|
They've officially declared OpenCL to be "deprecated", but it's not clear what that means. They also declared OpenGL to be deprecated, but it's hard to imagine them actually removing it. After all, it's the basis of WebGL, a standard that every browser needs to support. So it's not clear whether Apple really plans to remove either one, or if this is just a publicity move to push people toward Metal. Given that uncertainty, I'm hesitant to take any concrete moves right now. Hopefully at some point it will become clear what their real plans are. If it turns out they really do plan to remove OpenCL, we can evaluate options at that point, which could include adopting a third party OpenCL implementation, adding Metal support, or just dropping support for GPUs on Macs. |
|
@peastman @jchodera I joined F@H after I read that F@H was doing COVID-19 research. I have a 2017 MacBook Pro with a built-in Radeon Pro 560 that's idling because F@H doesn't at this moment support OSX GPU. I'm sure there's a bunch of people who bought Radeon-integrated MBP's as well who would love to partially dedicate their GPUs to this effort. (Yes I didread the posts about how support was discontinued and how Apple is deprecating OpenCL and replacing it with Metal). I would do the fixes myself but my only experience with hardware programming is Arduino -- I'm primarily a web engineer / dev ops. Who can I lobby to get movement on this? I can be very politely persistent. Is there a specific person I can lobby at ATI and/or Apple to get a move on? Paste from my System Info below with exact details of my hardware: |
|
@theschles: Thanks for your interest in helping out in the Folding@Home effort! While OpenMM currently supports |
|
How's this for starters? |
|
Another thought: should I try booting a Linux LiveUSB distribution that offers support for AMD GPUs and then run the F@H client from there? I could run that overnight... |
|
That certainly ought to work. I'd be curious what sort of performance it gets. |
|
Folks, there's something wrong; according to Folding@Home's own "OS Stats" page, there are exactly 65 MacOSX active AMD GPUs right now:
How come?! Whatever it is that these folks are doing, I want in too: I sysadmin a MacOSX server with two very capable AMD GPUs that are completely idle because the machine is headless (ie, has no keyboard/mouse/display) and is only used remotely via SSH... would love to contribute this otherwise wasted resource to the F@H COVID-19 effort. And I know some other people in the same situation... |

|
Huh! We'll look into the stats to see what's going on here. I'm certainly super excited to build an |
|
@jchodera Thanks for your response.
That makes it two of us! ;-)
Please count me in! Just sent you an email with my contact info and experience details. Cheers, So |
|
Hello @jchodera,
More data has been posted at a FAH@forum thread discussing the matter; please see from this post on: https://foldingforum.org/viewtopic.php?f=83&t=32895&p=325535#p325008 Cheers, |
|
Hi all, I bit the bullet and decided to take the bootcamp plunge until native MacOS support is ready. I'm now running FAH on Windows with ~1.5x the points/day with full use of my MBP 2017's Radeon Pro 560. GPU-Z showing ~100% load on the GPU. |
Hi @jchodera -- any luck since April to build-in GPU-on-MacOS support? |
|
@peastman, closed why? Is is implemented? |
|
There's nothing to implement. We decided to stick with OpenCL, and Apple has given no indication they plan to remove it. It's even supported on the new ARM based Macs. So unless something changes in the future, there's nothing we need to do. |
|
@peastman hang on -- if it continues to work on MacOS Catalina and Big Sur, why doesn't Folding@Home then use my AMD GPU? |
|
@theschles : We haven't yet had a chance to build an |
|
@jchodera ok good! If you need a beta tester, please let me know! |
|
@theschles : Thanks to @dotsdl, we have migrated the build infrastructure to use the OpenMM conda-forge packages, which do support both osx-64 and osx-arm64 architectures! We'll be able to give osx builds a try shortly after we tackle the update of win/linux cores to the latest OpenMM 7.6.0. If you're still willing to be a beta tester, please reach out to me at my email address listed here and we'll hook you up! |
Hi John, what's the current status of the above? I reached out via email few months ago but never heard back... |
Ditto here. After not hearing anything back, I thought the Mac port has just been abandoned. Even through I'm about to lose access to my 2-GPU Mac Pro, I'd love to hear otherwise... |
|
The osx ***@***.*** core hasn't been abandoned! We can only afford a
fraction of a developer working on core22, but this is actually next on our
list to do!
|
|
If anyone wants to help us test the osx core22 builds, shoot me an email at
***@***.*** with the subject "osx core22 testing" and I'll
pull you into our testing slack.
|
I want a vanity email address, too! |
|
Whoops, in case the email didn't render, you can see it at
http://choderalab.org/members
|
|
I'd be interested in helping you guys maintain support for Apple GPUs. What would it take to help you test it? |
|
It would be great if we could get the M1 test runner working again so it would be tested on CI. I do a lot of my development on a Macbook M1 Pro, so it still gets a lot of testing. |
|
I have an M1 Max MacBook Pro, and I'm quite skilled at debugging software. I also have a lot of expertise with Metal and plans for highly performant FP64 emulation. It's best to just hyperlink so I don't repeat myself: https://gromacs.bioexcel.eu/t/gpu-acceleration-on-mac-m1-mini/2938/5 I don't think OpenMM is going to deprecate OpenCL, but I would like to see if there's any pain points I could alleviate for your team. I read that Apple's Metal team tried getting you to switch to Metal - did they help you with CI stuff? |
Yes please help. I have a 2017 MBP with a Radeon Pro 560 4GB that's been waiting for someone to get this going again. Please look for @jchodera 's email address at https://www.choderalab.org/members to get involved. |
We had a lot of discussions about performance, and I assumed you had 14 cores the entire time. Did you purchase a model with 6 or 8 performance CPU cores activated? |
|
Eight performance cores plus two efficiency cores. |
That's a great tip! I haven't really explored custom integrators before, but looking at it now it seems the sensible thing would be to have the CustomIntegrator just find the speed of the fastest-moving atom and write that to a global variable that I can query in my control code? Looks really neat - will give it a go. |
|
Getting well off topic from the subject of this thread, but the other thing that happens at those "velocity check" steps is an update of an exponential moving average of the coordinates (which is what's actually shown to the user, to help see through the thermal jitter). That generally has to happen at a rate that's independent of the graphics update interval (otherwise things get really weird if the user sets a particularly long period between updates). It looks like I could also do that in a |
|
Oh - and for the fast-moving atoms: if I understand correctly I can get a count of the fast-moving atoms with something like: ... with the factor of 3 in the denominator appearing because of this warning in the documentation:
Am I on the right track? |
|
I tried implementing both fast-atom count and smoothing as I did notice that in my initial smoothing implementation that two sequentially declared operations ( |
|
Sorry... make that |
|
That approach looks correct. Steps should always be executed in exactly the order you specify. |
@tristanic are you using LocalEnergyMinimizer? I just got a test failure on AMD GPUs. Everything else is fine though (except the "very long tests", which I haven't gotten data for yet). |
|
No I'm not - although the minimizer I'm using is fairly heavily based on
that. Seems a bit weird though - as far as I know the only thing it uses
the GPU for is to compute forces for the current coords. Unless things have
changed since I last saw it, the actual minimization calculations happen on
the CPU using `lbfgs.c`.
…On Tue, Apr 25, 2023 at 8:57 PM Philip Turner ***@***.***> wrote:
Very nice! Just compiled this into universal dylibs and tried out in ISOLDE
@tristanic <https://github.com/tristanic> are you using
LocalEnergyMinimizer? I just got a test failure on AMD GPUs. Everything
else is fine though (except the "very long tests", which I haven't gotten
data for yet).
—
Reply to this email directly, view it on GitHub
<#2489 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFM54YFD4IBMA5YBSRS3DZLXDAUEDANCNFSM4JSW5NIQ>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
|
I found where LocalEnergyMinimizer is failing in AMD GPUs. Could somebody reproduce this failure on the OpenCL platform with another AMD GPU? void testLargeForces() {
// Create a set of particles that are almost on top of each other so the initial
// forces are huge.
const int numParticles = 10;
System system;
NonbondedForce* nonbonded = new NonbondedForce();
system.addForce(nonbonded);
for (int i = 0; i < numParticles; i++) {
system.addParticle(1.0);
nonbonded->addParticle(1.0, 0.2, 1.0);
}
vector<Vec3> positions(numParticles);
OpenMM_SFMT::SFMT sfmt;
init_gen_rand(0, sfmt);
for (int i = 0; i < numParticles; i++)
positions[i] = Vec3(genrand_real2(sfmt), genrand_real2(sfmt), genrand_real2(sfmt))*1e-10;
// Minimize it and verify that it didn't blow up.
VerletIntegrator integrator(0.01);
Context context(system, integrator, platform);
context.setPositions(positions);
LocalEnergyMinimizer::minimize(context, 1.0);
State state = context.getState(State::Positions);
double maxdist = 0.0;
for (int i = 0; i < numParticles; i++) {
Vec3 r = state.getPositions()[i];
maxdist = max(maxdist, sqrt(r.dot(r)));
}
ASSERT(maxdist > 0.1);
ASSERT(maxdist < 10.0);
} |
|
I've tested on MI210 (OpenCL from ROCm 5.4.2), LocalEnergyMinimizer tests pass. Only one test of 164 OpenCL tests fails: TestOpenCLDrudeNoseHooverMixed: "Expected 300, found 309.221 (This test is stochastic and may occasionally fail)" (but it is always 309.221:)) |
|
@peastman would you be able to run the test with Mac AMD, OpenCL in-tree backend? It's kind of tedious to get to where you can compile OpenMM from source (e.g. missing something like this that runs out of the box), otherwise I could ask @theschles. |
|
Hi @philipturner you want me to pull a particular branch of openmm, compile it, then try your metal plugin? |
|
It takes a bit of setup to configure the build. Plus, the tests aren’t sorted by length, so even a simple sanity check could take minutes. |
|
Which branch of which repository do you want me to test? |
|
Let's start with the 8.0 release currently on Conda, then try again with the main branch. |
|
I can reproduce the problem. It's from the conversion between floating point and fixed point. Here's the routine that does it: inline long realToFixedPoint(real x) {
return (long) (x * 0x100000000);
}And here's what it produces for some values of x.
Its handling of overflows clearly isn't IEEE compliant. I'm not sure what we can do about it. |
real scaled_x = x * real(0x100000000);
#if VENDOR_AMD
if (abs(scaled_x) > real(LONG_MAX) - epsilon) {
return (scaled_x > 0) ? LONG_MAX : -LONG_MAX;
}
#endif
return (long) scaled_x; |
|
Yeah, I thought of doing something like that. But I worry it could add significant overhead. And there are a few reasons it may not be worth it.
|
|
For what it's worth this would have been a problem for ISOLDE ~6 months ago, but since I updated it to use softcore nonbonded potentials it's virtually impossible for force components to exceed the FP32 max. In case it's useful/interesting, I've attached the results of some benchmarking runs in ISOLDE, comparing CUDA vs. OpenCL in Windows (on an RTX 3070) and Metal vs. OpenCL on a borrowed M2 Mac (I'm also running them on my M1 Pro - difference looks to be ~10-15% compared to the M2). Three different conditions ("high", "medium" and "low" fidelity varying in the cutoff distances and use of implicit solvent). These are somewhat less informative than pure simulations in some respects given the amount of overhead going into graphics updates etc., but the short story is that the Metal plugin gives a substantial real-world improvement in this context. While the absolute numbers are of course nowhere comparable, the relative speedup for Metal vs. OpenCL is pretty similar to CUDA vs. OpenCL on my Windows machine. Will significantly improve usability on the Macs. |
|
@tristanic your usage pattern might be activating a low-power state, where the GPU throttles clock speed. When rendering, it decreases the clock speed to ensure the frame finishes just in time, with minimum power consumption. It might think you're rendering a graphics application because of the repetitive periods of idleness. If that's true, utilization is not proportional to power, it is proportional to sqrt(power). 16 W might be 80% peak FLOPS and 25 W is 100%. Can you run |
|
For a cryo-EM model (i.e. with a static, unchanging volumetric map) GPU active residency is sitting pretty comfortably at 98-99% residency on the 1296 MHz clock speed, with idle residency at 1-2% (and ~0.05% at 389 MHz - all zeros in between) GPU power is around 14W, package power 20W. For my small crystallographic test case where the maps update ~3x per second the GPU residency drops to ~90% (GPU power ~7W, package power 27.5W). That's not surprising - there's a lot more CPU-bound activity in this case that can't easily/safely be farmed off to other threads (initiating structure factor calculations, collecting the results, recontouring and remasking the maps for display...). All in all, I'm happy with that. |
|
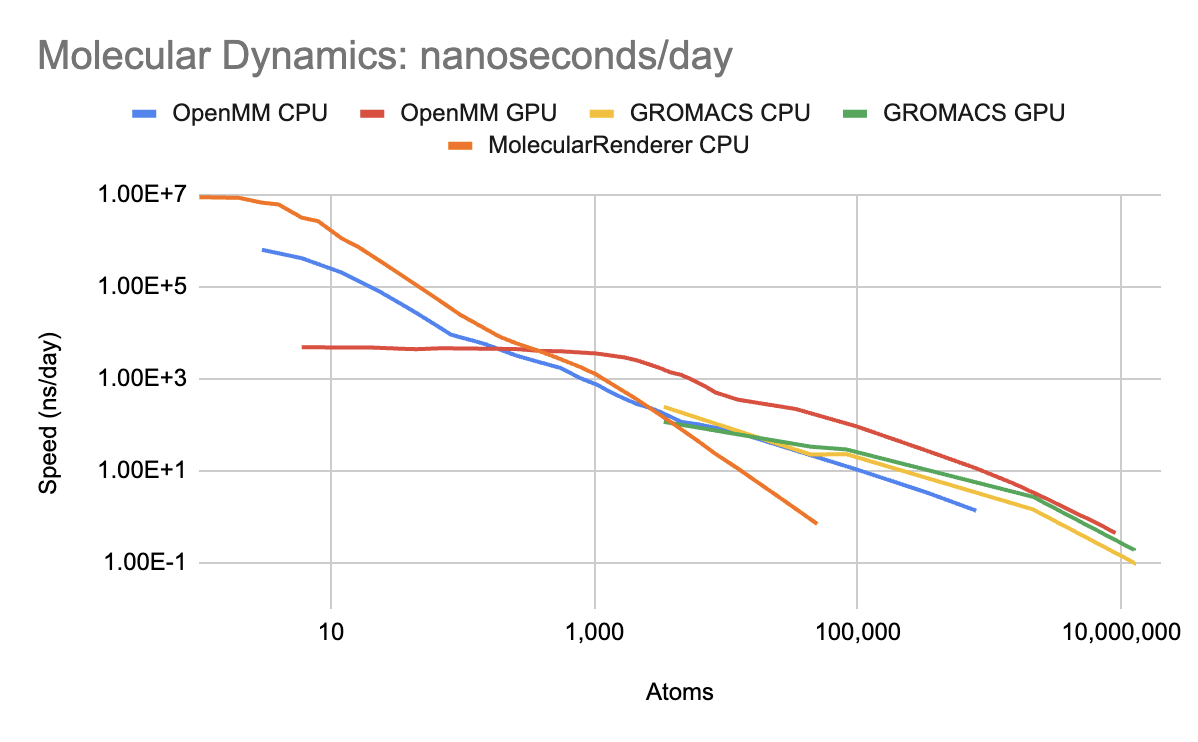
I'm investigating a significant optimization for very small (0-2K atoms) and medium-large (5K-20K atoms) systems. Look at the red curve, at 100K-1M atoms, where it's scaling linearly. Project the tangent line all the way until it intersects 60,000* ns/day.

@tristanic can you state the system sizes you work with (atoms), time step (fs), and asymptotic nonbonded force complexity (ns/day @ 100K, 1M, and 10M atoms)? I also need to know the typical input to Here are predictions for water, M1 Max. "Before" is the current Metal plugin with no cutoff (<8K atoms) and cutoff (>8K atoms). If you're currently using a cutoff/PME, removing that provides a 4x speedup for asymptotically small systems. My prediction assumes you already employed the no-cutoff optimization.
|
|
That sounds like a very worthy goal, but I'm not sure how well it would
apply to ISOLDE. In ISOLDE simulations the coords need to be updated in the
GUI at regular intervals to maintain smooth interactivity. By default the
update interval is 50 timesteps, but that's a user-adjustable parameter -
and in most cases the user would want to go to smaller intervals rather
than larger. Beyond that, behind the scenes every 10 timesteps it runs two
custom integrators: one to check current velocities to make sure nothings
out of control, one to maintain a smoothed version of the trajectory
(what's actually shown in the GUI) to iron out some of the thermal jitter.
So batching in the way you suggest would be somewhat involved. For time
stepping I use the `VariableLangevinIntegrator` - testing showed this was
by far the most stable in the face of aggressive user interaction (it takes
just about any abuse I can throw at it, where the standard integrators
explode). The trade-off, of course, is that I can't give an answer on the
length of each time step. A typical interactive simulation on the Mac would
be in the ballpark of 3,000 atoms (if it makes a difference, in most cases
about half of these would be fixed in space). I'm not sure how to interpret
your question on asymptotic nonbonded force complexity.
…On Thu, May 11, 2023 at 8:00 PM Philip Turner ***@***.***> wrote:
I'm investigating a significant optimization for very small (0-2K atoms)
and medium-large (5K-20K atoms) systems. Look at the red curve, at 100K-1M
atoms, where it's scaling linearly. Project the tangent line all the way
until it intersects 59,000* ns/day.
* This is theory, achieved with noble gases (2 Metal kernels/step).
Reality is probably 10,000 ns/day.
[image: Molecular Simulation Speed]
<https://user-images.githubusercontent.com/71743241/237775664-319bbcef-e17e-45f2-88ac-1635a63ac1ee.png>
@tristanic <https://github.com/tristanic> can you state the system sizes
you work with (atoms), time step (fs), and asymptotic nonbonded force
complexity (ns/day @ 100K, 1M, and 10M atoms)? I also need to know the
typical input to system.step; the optimization works by encoding
100-1,000 steps into a single Metal command buffer.
Here are predictions for water, M1 Max. "Before" is the current Metal
plugin with no cutoff (<8K atoms) and cutoff (>8K atoms). If you're
currently using a cutoff/PME, removing that provides a 4x speedup for
asymptotically small systems. My prediction assumes you already employed
the no-cutoff optimization.
Atoms Before ns/day After ns/day Speedup
355025 27.2 27.2 $~1.000\times$
98880 91.3 <92.2 $<1.009\times$
33840 220 <269 $<1.22\times$
12255 351 <743 $<2.11\times$
8301 504 <1097 $<2.18\times$
7221 638 <1261 $<1.98\times$
6282 787 <1450 $<1.84\times$
5310 1000 <1716 $<1.72\times$
4527 1220 <2133 $<1.75\times$
3762 1380 <2422 $<1.76\times$
3222 1660 <2828 $<1.70\times$
2661 2010 <3424 $<1.70\times$
2094 2510 <4351 $<1.70\times$
1692 2900 <5386 $<1.86\times$
1335 3190 <6825 $<2.14\times$
1038 3530 <8779 $<2.49\times$
774 3720 <11773 $<3.16\times$
555 3950 <16419 $<4.16\times$
387 4010 <23546 $<5.87\times$
255 4410 <35736 $<8.10\times$
—
Reply to this email directly, view it on GitHub
<#2489 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFM54YAEVSEBB776GJ3JDPTXFUZMPANCNFSM4JSW5NIQ>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
{kind=link}
Even 10 timesteps would provide some speedup (theoretically up to 10x), but it's possible to squeeze out a little extra performance by going to 1,000. Afterward, there is no difference.
Basically, how complex is the nonbonded part relative to 12-6 Lennard Jones? For example, adding the Coulomb interaction would roughly double the cost for large-enough systems. I need to quantify the ratio of compute cost compared to my reference implementation.
A reasonable estimate might be 50-100% speedup, depending on whether you use a cutoff for nonbonded forces. |
|
The nonbonded force implementation is at https://github.com/tristanic/isolde/blob/8a7a84a95e5f8ee7f645615be19c72ef513d7ee5/isolde/src/openmm/custom_forces.py#L1749. It's not incredibly costly compared to the standard I wasn't actually aware that things could run faster for small systems without a nonbonded cutoff. Currently ISOLDE uses either 1.7 or 0.9 nm depending on the user's choice (on a widget allowing them to trade off fidelity for speed). |
|
The nonbonded force seems quite cheap, so a lot of my performance claims from noble gases should apply. The only limiter is the |
|
I managed to make the plateau sharper. 20,279 ns/day @ 1K atoms. 20,279 with 5 digits. 
@peastman this is what Apple meant when asking you to switch to Metal. Driver latency is an Achilles heel - the reason PyTorch is so slow on Apple GPUs. |
Now that Apple deprecated OpenCL support in
osx10.12 and NVIDIA will no longer provide CUDA support forosxafter CUDA 10.2, OpenMM will provide no officially supported GPU-accelerated platforms going forward.What's our plan for future GPU support on
osx? Should it be to examine implementing a Metal platform, or extending the new unified OpenCL/CUDA platform to support it?cc: #2486 #2471
The text was updated successfully, but these errors were encountered: