Lunr throws in Safari sometimes when calling the query method #279
Comments
|
@olivernn, I work with @imaustink and we’d like to contribute to get this bug fixed, but I’m not sure where to start in determining why either the Our project is open source and we are happy to provide any info that’s useful, or if you can point us in the right direction we will happily work on it. Thanks for the great project and for your help. 🙏 |
Work around for olivernn#279
|
We’re using a fork with this commit (reference above) until we can figure out the root issue. |
|
@imaustink @chasenlehara thanks for taking the time to help with this issue, its a real help! I think the first step is to get a reduced test case. Without that its going to be really tricky to track this down. Even a non-reduced test case would be a start. From the looks of it, it seems the bug is being triggered by some specific combination of query and document content. Why this would only happen in Safari I don't know, there isn't anything particularly special happening. |
|
What does the ideal reduced test case look like? A sample project that has data, sets up indexing and querying, and reproduces the exception? Or should we look into modifying any of the current tests? |
|
In the past people have put together reproductions with jsfiddle. The ideal would be having an index with a single document and a query that triggers the bug. An example fiddle for some inspiration - https://jsfiddle.net/of54k0uk/14/ |
|
EDIT : not sure if related, if it can help other peoples, fixed it by adding a condition on keywords Hello, if it can help, it's not only with safari, I reproduce the error in react native / android too. searchMerchant(keywords) } I generate or load the index if not in cache, the error seem to trig only when the index is generated, when loaded from cache with lunr.Index.load() the error seems to never trig.
|
|
@Julinar interesting, so you're workaround was to prevent empty searches? Was this what was causing the issue. As I mentioned earlier in the issue, without more details to go on, specifically a simple reproduction, its very difficult for me to try and provide a fix. If you can put together a simple test case that shows the issue I can get to fixing it straight away. |
|
@chasenlehara and I were able to create a reduced test case. Open this jsfiddle in Safari and you will see the error. I hope this helps. |
|
@imaustink thanks, that is super useful! I've only had a very quick look, but certainly something strange is happening! You are searching for So somehow I'll do some more digging and let you know what I find. |
|
Hmm, where did that unicode come from? I pasted that directly from the debugger, so maybe that is the cause of the weirdness.... |
|
So I've been trying to understand what is going on in Safari using the debugger, if I pause on exceptions I can see that the expanded terms that are being looked for are This might be tricky... |
|
I've tried to reduce the test case some more (no doubt it can be reduced further later) and I'm very confused - https://jsfiddle.net/23fujmvf/1/ By alerting the results of the Without the alert we get something that looks like "can-centa" which looks like it has dropped the "ompon" part of "can-componenta". Perhaps |
|
@olivernn, thanks for jumping on this so quickly! I did some experimentation as well before making the test case, and I also noticed the unicode characters, and the fact that observing the string seems to fix the problem. Merely testing the string with RegEx is one example of this, comparing the string is another example. In addition, I just discovered that even inspecting a copy of the string seems to fix the problem. This behavior is very unexpected indeed. This definitely seems like a bug in Safari rather than Lunr. Although I am curious how Lunr seems to be the only library having issues with this currently. Perhaps there is a very obscure bug that Lunr is somehow invoking? Please let me know if there is anything I can do to help with this issue. 🍻 |
|
@imaustink no problem, its certainly an interesting case! I'm pretty sure this is a bug in Safari, not that that helps us much, Lunr will need to work around it somehow and I don't think using To be able to get any traction with a browser bug we're going to have to have a much reduced test case, ideally one that does not involve any Lunr code at all. My current theory is that it is an issue with how Lunr is getting characters from strings, and how it is then putting those characters back together again to form a string, perhaps it isn't correctly handling multi byte characters? That is just a guess though. I think the interesting thing is how something like I'm going to carry on poking around with the debugger, but please let me know if you come up with something too. |
|
One thing you could try is to use something similar to lunr-unicode-normalizer. That repo is not updated for Lunr 2, but the idea is the same, remove all diacritic marks. Not a fix, but might be a reasonable work around for now. |
|
Okay, this is definitely an issue with unicode, I'm not sure where the issue is, but using I don't think |
|
Very Interesting. |
|
Ok, I think the problem is being caused by This is probably the cause in this case, since one of the terms has some trailing, non-latin, characters. My guess is that it is mangling the final 'character' which by removing half of the code point that makes up the full character. Without any other test cases its difficult to say if this is always the cause. So, as an immediate fix, the trimmer can be removed from the builder pipeline: lunr(function () {
this.pipeline.remove(lunr.trimmer)
})The existing implementation could possibly be made more robust against these cases, I'll have to think about the best way to implement that. In addition, Safari is certainly doing something unexpected (as far as I'm concerned). It's now probably easier to produce a test case that doesn't directly involve Lunr, I'll update here when I've done that. |
|
I've been doing some thinking about this and I think an approach forward is to improve the quality of the implementation of I think an approach based on UAX#29 is probably more robust, though the implementation details are certainly more involved. I'm going to experiment with writing a tokeniser using the rules in the above document, I want to see how much better it is able to deal with these cases, as well as understanding what, if any, impact there is on performance (both speed and library size). In the meantime I'm still interested in seeing if this bug can be isolated enough to show to the Safari developers, as its current behaviour is still weird to me. |
|
i was faced with the same issue and removing the trimmer from the pipeline solved my error as well. |
|
We found that cloning the clause for each term in |
|
I'm seeing the same bug on this I'm working on site. I've tried both work arounds mentioned above: removing the trimmer and cloning the clause for each term - neither worked though. One kludgey thing that did work was to console.log out each expandedTerm here: Line 181 in fd5dccd In my case this was 3000+ terms. And it only works when I log every term. If I set a conditional to log only the index and term that throws the bug, then it breaks. If I log an arbitrary string it still breaks. The index of expanded terms that causes the bug seems to change. In my brief testing it was words that began with 'w' and the strings did not contain non-latin chars.
Talking through this with a coworker, he thought this suggested some kind of race condition - perhaps the logging and evaluating the array index slowed things down just enough to sort itself out. |
LunrJS has some undefined behavoir in Safari, documented here: olivernn/lunr.js#279 This workaround console-logs out the terms which seems to slow down things enough for it to work, suggesting a race condition somewhere. As this is a bug with either Safari or LunrJS, we'll have to wait for them to sort it out.
|
Is there any update on this issue? I also noticed that I have broken search on safari. |
|
Just to add more to this, there is something curious with the "misterious" fixes to this issue. https://jsfiddle.net/egLzL24L/40/ (see the Interestingly, calling methods higher in the prototype chain (like on It would be interesting to understand the underlying cause of this, but the observation offers a possible viable solution for the moment: just call an inexpensive string method on the expanded term before retrieving it from the inverted index. |
Calling any method defined on String.prototype on the expanded term seems to force the string to be properly represented, fixing an issue affecting Safari users. See olivernn#279
|
I think I managed to pinpoint the exact place in https://jsfiddle.net/egLzL24L/77/ (see line 38 and relevant comment) Which corresponds to this line in the repo: Line 309 in f9aeea2 It seems that the string concatenation (no matter if done with As of why this happens, and what exactly triggers it, I have no clue. I would be inclined to think that some underlying memory optimization of string concatenation is buggy in Safari in some corner case. |
it turns out that a specific string concatenation in TokenSet.prototype.toArray sometimes results in a corrupted string in Safari. It is fixed by calling any String.prototype method on it, which forces the string to the correct representation. The previous commit did the same, but this commit moves the fix closer to the source of the problem. It could be applied exactly at the point of the problematic concatenation, but that would result in some unnecessary (if inexpensive) calls, so it is instead when pushing each result string in the returned array.
|
and here is the smallest script where I can reproduce the bug. https://jsfiddle.net/egLzL24L/156/ It seems like it's a combination of the trimmer RegExp, a trailing non-word, a Unicode character in a higher block than Latin-1 Supplement (so unicode of at least 2 bytes), and string concatenation. |
|
And here the bug is reproduced without Lunr, just a short snippet of code similar to the way Lunr builds a TokenSet and then turns it into an array. https://jsfiddle.net/8zn2fj6s/18/ Note that if you copy/paste the output of the alert when the bug occurs, and inspect it's binary content with |
|
Ok, this seems the minimum script that reproduces it. No Lunr code nor any complex data structure is involved: |
|
I took the liberty to file a bug report on Safari, as this is now clearly a browser bug and not a Lunr issue. |
|
@lucaong nice work! Are you able to share the link to the Safari bug report? I think that this is really a bug in the way that Lunr handles (or doesn't) unicode. In both My understanding (mostly from reading this article) is that neither of those methods handle unicode characters particularly well. Safari is certainly doing something different to other browsers here, maybe its a bug. The workaround certainly suggests something odd is happening. I think your workaround is probably the right approach for now, I'll take a look and get a release out in the next day or so. A more long term fix is to make both |
|
@olivernn I filed the bug at https://bugreport.apple.com, it has number 42468541 but does not seem to be publicly visible. No response so far, but I will keep you updated. You're right, unicode handling is mostly lacking in JS, but that should not lead to a corrupted string. Besides, the null characters could be the native string terminator leaking out, so there's the risk that someone more skilled than me could devise a way to leverage this bug to expose more memory content. Regarding the fix, on the good side it should not affect performance nor change the Lunr behavior in any way. It is quite surprising though, so it might be worth writing a test for the By the way, thanks for Lunr, it's really an amazing library! |
|
@lucaong It might be worth reporting a WebKit bug so we have some visibility into their process. Thank you so much for taking the time to debug this issue more! |
* Fix issue #279 (bug with Safari) Calling any method defined on String.prototype on the expanded term seems to force the string to be properly represented, fixing an issue affecting Safari users. See #279 * fix issue #279 at the source, on TokenSet.prototype.toArray it turns out that a specific string concatenation in TokenSet.prototype.toArray sometimes results in a corrupted string in Safari. It is fixed by calling any String.prototype method on it, which forces the string to the correct representation. The previous commit did the same, but this commit moves the fix closer to the source of the problem. It could be applied exactly at the point of the problematic concatenation, but that would result in some unnecessary (if inexpensive) calls, so it is instead when pushing each result string in the returned array. * remove changes to generated distribution file
|
The patch from @lucaong is now on master, so if anyone wants to try out the bleeding edge they can. A proper release will follow shortly. |
|
@chasenlehara thanks for the link, I filed this bug there: https://bugs.webkit.org/show_bug.cgi?id=187947 |
|
I've just pushed 2.3.1 to npm which includes the patch from @lucaong. I'm going to leave this issue open for now until I get around to updating the tokeniser and token store to be more aware of unicode. |
|
With lunr 2.3.6 and the trimmer removed from the pipeline, I still encounter this issue sporadically. The patch in #361 may have been insufficient or too localized. Maybe it should be guaranteed that an undefined I see that the issue was already thoroughly investigated more than I can meaningfully contribute to. Anecdotally, it often happens when the term is empty (or stopwords), but I saw it happen with |
|
Apparently the fix reported by @lucaong has been fixed https://trac.webkit.org/changeset/255975/webkit and it lives now in the Safari Tech. Preview https://webkit.org/blog/10031/release-notes-for-safari-technology-preview-101/ |
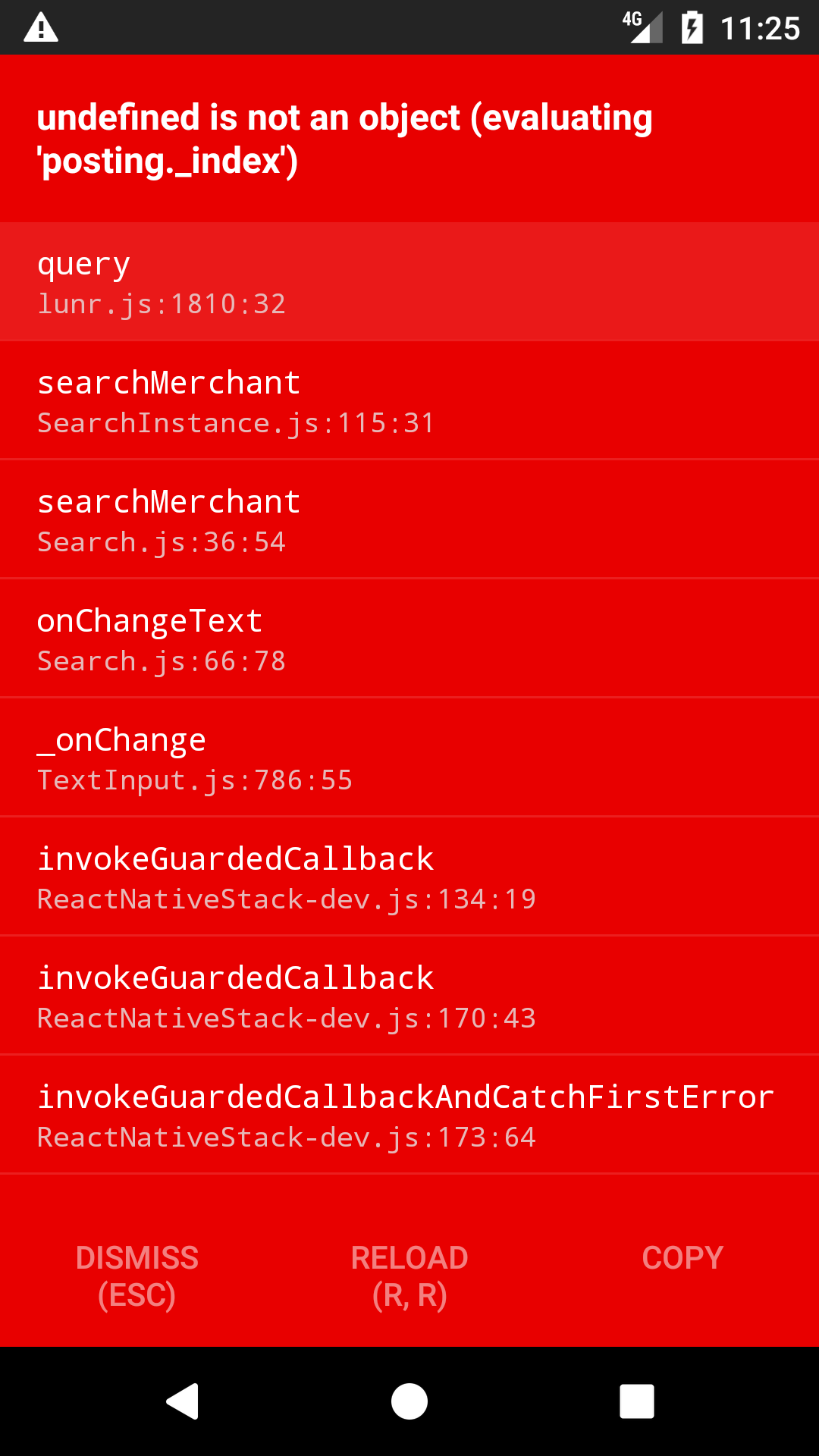
When calling the
.querymethod with certain search terms in Safari, the following error is thrown:The problem is here. Adding an check for
postingsolves the problem but I am almost certain this is a sign of a larger problem and this should be fixed upstream.We found that removing
wildcardoption from all.termcalls fixes the issue but search results suffer.We are aware of this being reported here: #276 (comment). We are working to create a reduced test case.
The text was updated successfully, but these errors were encountered: