Speed up your scikit-learn applications for Intel(R) CPUs and GPUs across single- and multi-node configurations
Releases | Documentation | Examples | Support | License


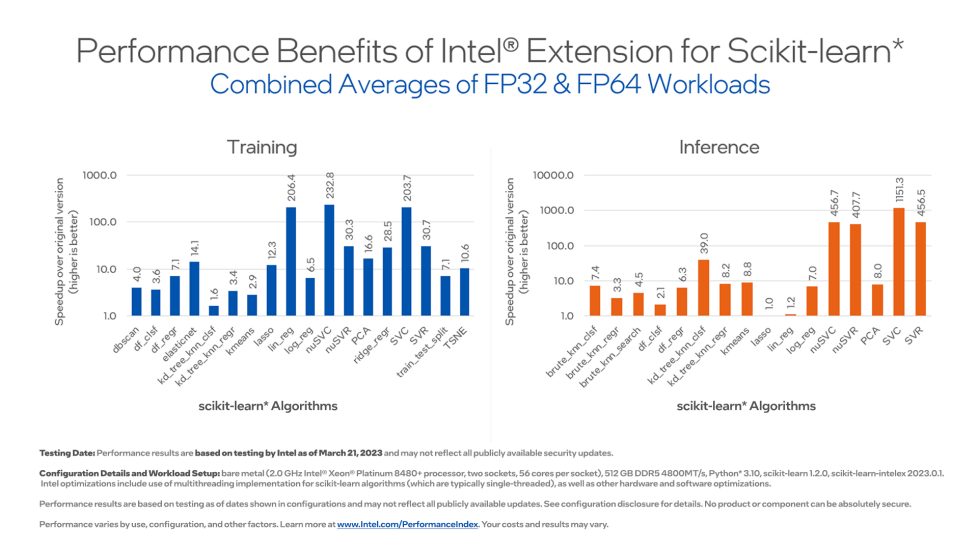
Intel(R) Extension for Scikit-learn is a free software AI accelerator designed to deliver over 10-100X acceleration to your existing scikit-learn code. The software acceleration is achieved with vector instructions, AI hardware-specific memory optimizations, threading, and optimizations for all upcoming Intel(R) platforms at launch time.
With Intel(R) Extension for Scikit-learn, you can:
- Speed up training and inference by up to 100x with the equivalent mathematical accuracy
- Benefit from performance improvements across different Intel(R) hardware configurations
- Integrate the extension into your existing Scikit-learn applications without code modifications
- Continue to use the open-source scikit-learn API
- Enable and disable the extension with a couple of lines of code or at the command line
Intel(R) Extension for Scikit-learn is also a part of Intel(R) AI Tools.
-
Enable Intel(R) CPU optimizations
import numpy as np from sklearnex import patch_sklearn patch_sklearn() from sklearn.cluster import DBSCAN X = np.array([[1., 2.], [2., 2.], [2., 3.], [8., 7.], [8., 8.], [25., 80.]], dtype=np.float32) clustering = DBSCAN(eps=3, min_samples=2).fit(X)
-
Enable Intel(R) GPU optimizations
import numpy as np import dpctl from sklearnex import patch_sklearn, config_context patch_sklearn() from sklearn.cluster import DBSCAN X = np.array([[1., 2.], [2., 2.], [2., 3.], [8., 7.], [8., 8.], [25., 80.]], dtype=np.float32) with config_context(target_offload="gpu:0"): clustering = DBSCAN(eps=3, min_samples=2).fit(X)
👀 Check out available notebooks for more examples.
To install Intel(R) Extension for Scikit-learn, run:
pip install scikit-learn-intelex
See all installation instructions in the Installation Guide.
The software acceleration is achieved through patching. It means, replacing the stock scikit-learn algorithms with their optimized versions provided by the extension.
The patching only affects supported algorithms and their parameters. You can still use not supported ones in your code, the package simply fallbacks into the stock version of scikit-learn.
TIP: Enable verbose mode to see which implementation of the algorithm is currently used.
To patch scikit-learn, you can:
- Use the following command-line flag:
python -m sklearnex my_application.py - Add the following lines to the script:
from sklearnex import patch_sklearn patch_sklearn()
👀 Read about other ways to patch scikit-learn.
The acceleration is achieved through the use of the Intel(R) oneAPI Data Analytics Library (oneDAL). Learn more:
We welcome community contributions, check our Contributing Guidelines to learn more.
* The Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.