diff --git a/README.md b/README.md
index 4aa7e6c882ea4..f2d65752d67a2 100644
--- a/README.md
+++ b/README.md
@@ -279,6 +279,7 @@ Current number of checkpoints: ** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
diff --git a/README_es.md b/README_es.md
index c08ec500892d5..32156a08e2674 100644
--- a/README_es.md
+++ b/README_es.md
@@ -279,6 +279,7 @@ Número actual de puntos de control: ** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
diff --git a/README_ja.md b/README_ja.md
index eed7d204f8368..edb49ce9d5c91 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -314,6 +314,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
diff --git a/README_ko.md b/README_ko.md
index 28a2e2aa46434..33bcdda6b6193 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -229,6 +229,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 7f877c2bed209..dbf8c8b8e21ef 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -253,6 +253,7 @@ conda install -c huggingface transformers
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (来自 Inria/Facebook/Sorbonne) 伴随论文 [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) 由 Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot 发布。
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (来自 Google Research) 伴随论文 [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) 由 Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting 发布。
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (来自 OpenAI) 伴随论文 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 由 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 发布。
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (来自 University of Göttingen) 伴随论文 [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) 由 Timo Lüddecke and Alexander Ecker 发布。
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (来自 Salesforce) 伴随论文 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 由 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 发布。
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (来自 Microsoft Research Asia) 伴随论文 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 由 Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 发布。
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (来自 YituTech) 伴随论文 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 由 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index e5764c6ce8f15..92ca90cecdd8e 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -265,6 +265,7 @@ conda install -c huggingface transformers
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/main/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index a6706cb774664..1cd287130db48 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -466,6 +466,8 @@
sections:
- local: model_doc/clip
title: CLIP
+ - local: model_doc/clipseg
+ title: CLIPSeg
- local: model_doc/data2vec
title: Data2Vec
- local: model_doc/donut
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index bcc832a250ded..5f446f21b5365 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -67,6 +67,7 @@ The documentation is organized into five sections:
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
@@ -223,6 +224,7 @@ Flax), PyTorch, and/or TensorFlow.
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
diff --git a/docs/source/en/model_doc/clipseg.mdx b/docs/source/en/model_doc/clipseg.mdx
new file mode 100644
index 0000000000000..c72154883d63b
--- /dev/null
+++ b/docs/source/en/model_doc/clipseg.mdx
@@ -0,0 +1,93 @@
+
+
+# CLIPSeg
+
+## Overview
+
+The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
+and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen [CLIP](clip) model for zero- and one-shot image segmentation.
+
+The abstract from the paper is the following:
+
+*Image segmentation is usually addressed by training a
+model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive
+as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system
+that can generate image segmentations based on arbitrary
+prompts at test time. A prompt can be either a text or an
+image. This approach enables us to create a unified model
+(trained once) for three common segmentation tasks, which
+come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation.
+We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense
+prediction. After training on an extended version of the
+PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on
+an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail.
+This novel hybrid input allows for dynamic adaptation not
+only to the three segmentation tasks mentioned above, but
+to any binary segmentation task where a text or image query
+can be formulated. Finally, we find our system to adapt well
+to generalized queries involving affordances or properties*
+
+Tips:
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
+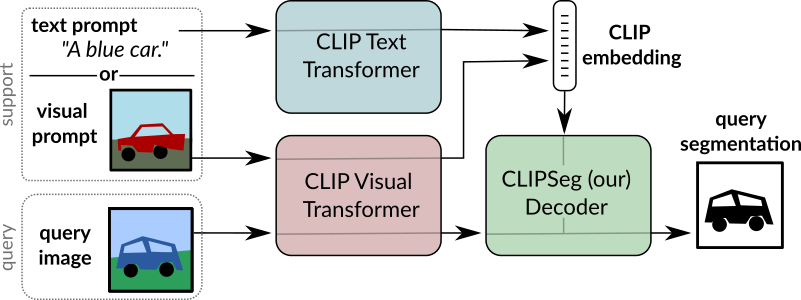 +
+ CLIPSeg overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/timojl/clipseg).
+
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index a3ce3fd1eb2ee..b377395a9046c 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -171,6 +171,13 @@
"CLIPTokenizer",
"CLIPVisionConfig",
],
+ "models.clipseg": [
+ "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "CLIPSegConfig",
+ "CLIPSegProcessor",
+ "CLIPSegTextConfig",
+ "CLIPSegVisionConfig",
+ ],
"models.codegen": ["CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP", "CodeGenConfig", "CodeGenTokenizer"],
"models.conditional_detr": ["CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConditionalDetrConfig"],
"models.convbert": ["CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvBertConfig", "ConvBertTokenizer"],
@@ -1074,6 +1081,16 @@
"CLIPVisionModel",
]
)
+ _import_structure["models.clipseg"].extend(
+ [
+ "CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "CLIPSegModel",
+ "CLIPSegPreTrainedModel",
+ "CLIPSegTextModel",
+ "CLIPSegVisionModel",
+ "CLIPSegForImageSegmentation",
+ ]
+ )
_import_structure["models.x_clip"].extend(
[
"XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3225,6 +3242,13 @@
CLIPTokenizer,
CLIPVisionConfig,
)
+ from .models.clipseg import (
+ CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ CLIPSegConfig,
+ CLIPSegProcessor,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ )
from .models.codegen import CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP, CodeGenConfig, CodeGenTokenizer
from .models.conditional_detr import CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP, ConditionalDetrConfig
from .models.convbert import CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvBertConfig, ConvBertTokenizer
@@ -3993,6 +4017,14 @@
CLIPTextModel,
CLIPVisionModel,
)
+ from .models.clipseg import (
+ CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST,
+ CLIPSegForImageSegmentation,
+ CLIPSegModel,
+ CLIPSegPreTrainedModel,
+ CLIPSegTextModel,
+ CLIPSegVisionModel,
+ )
from .models.codegen import (
CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST,
CodeGenForCausalLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 86a775a1eb2b8..03153725125cc 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -37,6 +37,7 @@
camembert,
canine,
clip,
+ clipseg,
codegen,
conditional_detr,
convbert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 68f29f89ae50e..d8b59f123f676 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -42,6 +42,7 @@
("camembert", "CamembertConfig"),
("canine", "CanineConfig"),
("clip", "CLIPConfig"),
+ ("clipseg", "CLIPSegConfig"),
("codegen", "CodeGenConfig"),
("conditional_detr", "ConditionalDetrConfig"),
("convbert", "ConvBertConfig"),
@@ -182,6 +183,7 @@
("camembert", "CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("canine", "CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("clip", "CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("clipseg", "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("codegen", "CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("conditional_detr", "CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("convbert", "CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -315,6 +317,7 @@
("camembert", "CamemBERT"),
("canine", "CANINE"),
("clip", "CLIP"),
+ ("clipseg", "CLIPSeg"),
("codegen", "CodeGen"),
("conditional_detr", "Conditional DETR"),
("convbert", "ConvBERT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 76d38f95ab151..bc30cc21b60d0 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -39,6 +39,7 @@
[
("beit", "BeitFeatureExtractor"),
("clip", "CLIPFeatureExtractor"),
+ ("clipseg", "ViTFeatureExtractor"),
("conditional_detr", "ConditionalDetrFeatureExtractor"),
("convnext", "ConvNextFeatureExtractor"),
("cvt", "ConvNextFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 3da1dc1790572..7b6e701175859 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -41,6 +41,7 @@
("camembert", "CamembertModel"),
("canine", "CanineModel"),
("clip", "CLIPModel"),
+ ("clipseg", "CLIPSegModel"),
("codegen", "CodeGenModel"),
("conditional_detr", "ConditionalDetrModel"),
("convbert", "ConvBertModel"),
@@ -813,6 +814,7 @@
[
# Model for Zero Shot Image Classification mapping
("clip", "CLIPModel"),
+ ("clipseg", "CLIPSegModel"),
]
)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index 3e31a14d25817..f7bb87e25e2d7 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -40,6 +40,7 @@
PROCESSOR_MAPPING_NAMES = OrderedDict(
[
("clip", "CLIPProcessor"),
+ ("clipseg", "CLIPSegProcessor"),
("flava", "FlavaProcessor"),
("groupvit", "CLIPProcessor"),
("layoutlmv2", "LayoutLMv2Processor"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 46e57ac58bd4c..d5374e6f42e00 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -93,6 +93,13 @@
"CLIPTokenizerFast" if is_tokenizers_available() else None,
),
),
+ (
+ "clipseg",
+ (
+ "CLIPTokenizer",
+ "CLIPTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
("codegen", ("CodeGenTokenizer", "CodeGenTokenizerFast" if is_tokenizers_available() else None)),
("convbert", ("ConvBertTokenizer", "ConvBertTokenizerFast" if is_tokenizers_available() else None)),
(
diff --git a/src/transformers/models/clipseg/__init__.py b/src/transformers/models/clipseg/__init__.py
new file mode 100644
index 0000000000000..f6b09b9af9757
--- /dev/null
+++ b/src/transformers/models/clipseg/__init__.py
@@ -0,0 +1,75 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_clipseg": [
+ "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "CLIPSegConfig",
+ "CLIPSegTextConfig",
+ "CLIPSegVisionConfig",
+ ],
+ "processing_clipseg": ["CLIPSegProcessor"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_clipseg"] = [
+ "CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "CLIPSegModel",
+ "CLIPSegPreTrainedModel",
+ "CLIPSegTextModel",
+ "CLIPSegVisionModel",
+ "CLIPSegForImageSegmentation",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_clipseg import (
+ CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ CLIPSegConfig,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ )
+ from .processing_clipseg import CLIPSegProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_clipseg import (
+ CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST,
+ CLIPSegForImageSegmentation,
+ CLIPSegModel,
+ CLIPSegPreTrainedModel,
+ CLIPSegTextModel,
+ CLIPSegVisionModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/clipseg/configuration_clipseg.py b/src/transformers/models/clipseg/configuration_clipseg.py
new file mode 100644
index 0000000000000..1fe27b0d0b0f0
--- /dev/null
+++ b/src/transformers/models/clipseg/configuration_clipseg.py
@@ -0,0 +1,383 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" CLIPSeg model configuration"""
+
+import copy
+import os
+from typing import Union
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "CIDAS/clipseg-rd64": "https://huggingface.co/CIDAS/clipseg-rd64/resolve/main/config.json",
+}
+
+
+class CLIPSegTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
+ CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 49408):
+ Vocabulary size of the CLIPSeg text model. Defines the number of different tokens that can be represented
+ by the `inputs_ids` passed when calling [`CLIPSegModel`].
+ hidden_size (`int`, *optional*, defaults to 512):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 2048):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ max_position_embeddings (`int`, *optional*, defaults to 77):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float``, *optional*, defaults to 1):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegTextConfig, CLIPSegTextModel
+
+ >>> # Initializing a CLIPSegTextConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegTextConfig()
+
+ >>> # Initializing a CLIPSegTextModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "clipseg_text_model"
+
+ def __init__(
+ self,
+ vocab_size=49408,
+ hidden_size=512,
+ intermediate_size=2048,
+ num_hidden_layers=12,
+ num_attention_heads=8,
+ max_position_embeddings=77,
+ hidden_act="quick_gelu",
+ layer_norm_eps=0.00001,
+ dropout=0.0,
+ attention_dropout=0.0,
+ initializer_range=0.02,
+ initializer_factor=1.0,
+ pad_token_id=1,
+ bos_token_id=0,
+ eos_token_id=2,
+ **kwargs
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.max_position_embeddings = max_position_embeddings
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.attention_dropout = attention_dropout
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the text config dict if we are loading from CLIPSegConfig
+ if config_dict.get("model_type") == "clipseg":
+ config_dict = config_dict["text_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class CLIPSegVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
+ CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 32):
+ The size (resolution) of each patch.
+ hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float``, *optional*, defaults to 1):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegVisionConfig, CLIPSegVisionModel
+
+ >>> # Initializing a CLIPSegVisionConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegVisionConfig()
+
+ >>> # Initializing a CLIPSegVisionModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "clipseg_vision_model"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ num_channels=3,
+ image_size=224,
+ patch_size=32,
+ hidden_act="quick_gelu",
+ layer_norm_eps=0.00001,
+ dropout=0.0,
+ attention_dropout=0.0,
+ initializer_range=0.02,
+ initializer_factor=1.0,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.image_size = image_size
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.attention_dropout = attention_dropout
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the vision config dict if we are loading from CLIPSegConfig
+ if config_dict.get("model_type") == "clipseg":
+ config_dict = config_dict["vision_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class CLIPSegConfig(PretrainedConfig):
+ r"""
+ [`CLIPSegConfig`] is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to
+ instantiate a CLIPSeg model according to the specified arguments, defining the text model and vision model configs.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`CLIPSegTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`CLIPSegVisionConfig`].
+ projection_dim (`int`, *optional*, defaults to 512):
+ Dimensionality of text and vision projection layers.
+ logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
+ The inital value of the *logit_scale* paramter. Default is used as per the original CLIPSeg implementation.
+ extract_layers (`List[int]`, *optional*, defaults to [3, 6, 9]):
+ Layers to extract when forwarding the query image through the frozen visual backbone of CLIP.
+ reduce_dim (`int`, *optional*, defaults to 64):
+ Dimensionality to reduce the CLIP vision embedding.
+ decoder_num_attention_heads (`int`, *optional*, defaults to 4):
+ Number of attention heads in the decoder of CLIPSeg.
+ decoder_attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ decoder_hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ decoder_intermediate_size (`int`, *optional*, defaults to 2048):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layers in the Transformer decoder.
+ conditional_layer (`int`, *optional*, defaults to 0):
+ The layer to use of the Transformer encoder whose activations will be combined with the condition
+ embeddings using FiLM (Feature-wise Linear Modulation). If 0, the last layer is used.
+ use_complex_transposed_convolution (`bool`, *optional*, defaults to `False`):
+ Whether to use a more complex transposed convolution in the decoder, enabling more fine-grained
+ segmentation.
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegConfig, CLIPSegModel
+
+ >>> # Initializing a CLIPSegConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegConfig()
+
+ >>> # Initializing a CLIPSegModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a CLIPSegConfig from a CLIPSegTextConfig and a CLIPSegVisionConfig
+
+ >>> # Initializing a CLIPSegText and CLIPSegVision configuration
+ >>> config_text = CLIPSegTextConfig()
+ >>> config_vision = CLIPSegVisionConfig()
+
+ >>> config = CLIPSegConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "clipseg"
+ is_composition = True
+
+ def __init__(
+ self,
+ text_config=None,
+ vision_config=None,
+ projection_dim=512,
+ logit_scale_init_value=2.6592,
+ extract_layers=[3, 6, 9],
+ reduce_dim=64,
+ decoder_num_attention_heads=4,
+ decoder_attention_dropout=0.0,
+ decoder_hidden_act="quick_gelu",
+ decoder_intermediate_size=2048,
+ conditional_layer=0,
+ use_complex_transposed_convolution=False,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ text_config_dict = kwargs.pop("text_config_dict", None)
+ vision_config_dict = kwargs.pop("vision_config_dict", None)
+ if text_config_dict is not None:
+ text_config = text_config_dict
+ if vision_config_dict is not None:
+ vision_config = vision_config_dict
+
+ if text_config is None:
+ text_config = {}
+ logger.info("text_config is None. Initializing the CLIPSegTextConfig with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("vision_config is None. initializing the CLIPSegVisionConfig with default values.")
+
+ self.text_config = CLIPSegTextConfig(**text_config)
+ self.vision_config = CLIPSegVisionConfig(**vision_config)
+
+ self.projection_dim = projection_dim
+ self.logit_scale_init_value = logit_scale_init_value
+ self.extract_layers = extract_layers
+ self.reduce_dim = reduce_dim
+ self.decoder_num_attention_heads = decoder_num_attention_heads
+ self.decoder_attention_dropout = decoder_attention_dropout
+ self.decoder_hidden_act = decoder_hidden_act
+ self.decoder_intermediate_size = decoder_intermediate_size
+ self.conditional_layer = conditional_layer
+ self.initializer_factor = 1.0
+ self.use_complex_transposed_convolution = use_complex_transposed_convolution
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: CLIPSegTextConfig, vision_config: CLIPSegVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`CLIPSegConfig`] (or a derived class) from clipseg text model configuration and clipseg vision
+ model configuration.
+
+ Returns:
+ [`CLIPSegConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
+
+ def to_dict(self):
+ """
+ Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
+
+ Returns:
+ `Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ output = copy.deepcopy(self.__dict__)
+ output["text_config"] = self.text_config.to_dict()
+ output["vision_config"] = self.vision_config.to_dict()
+ output["model_type"] = self.__class__.model_type
+ return output
diff --git a/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py b/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
new file mode 100644
index 0000000000000..778dbca299678
--- /dev/null
+++ b/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
@@ -0,0 +1,264 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Convert CLIPSeg checkpoints from the original repository. URL: https://github.com/timojl/clipseg."""
+
+import argparse
+
+import torch
+from PIL import Image
+
+import requests
+from transformers import (
+ CLIPSegConfig,
+ CLIPSegForImageSegmentation,
+ CLIPSegProcessor,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ CLIPTokenizer,
+ ViTFeatureExtractor,
+)
+
+
+def get_clipseg_config(model_name):
+ text_config = CLIPSegTextConfig()
+ vision_config = CLIPSegVisionConfig(patch_size=16)
+
+ use_complex_transposed_convolution = True if "refined" in model_name else False
+ reduce_dim = 16 if "rd16" in model_name else 64
+
+ config = CLIPSegConfig.from_text_vision_configs(
+ text_config,
+ vision_config,
+ use_complex_transposed_convolution=use_complex_transposed_convolution,
+ reduce_dim=reduce_dim,
+ )
+ return config
+
+
+def rename_key(name):
+ # update prefixes
+ if "clip_model" in name:
+ name = name.replace("clip_model", "clip")
+ if "transformer" in name:
+ if "visual" in name:
+ name = name.replace("visual.transformer", "vision_model")
+ else:
+ name = name.replace("transformer", "text_model")
+ if "resblocks" in name:
+ name = name.replace("resblocks", "encoder.layers")
+ if "ln_1" in name:
+ name = name.replace("ln_1", "layer_norm1")
+ if "ln_2" in name:
+ name = name.replace("ln_2", "layer_norm2")
+ if "c_fc" in name:
+ name = name.replace("c_fc", "fc1")
+ if "c_proj" in name:
+ name = name.replace("c_proj", "fc2")
+ if "attn" in name and "self" not in name:
+ name = name.replace("attn", "self_attn")
+ # text encoder
+ if "token_embedding" in name:
+ name = name.replace("token_embedding", "text_model.embeddings.token_embedding")
+ if "positional_embedding" in name and "visual" not in name:
+ name = name.replace("positional_embedding", "text_model.embeddings.position_embedding.weight")
+ if "ln_final" in name:
+ name = name.replace("ln_final", "text_model.final_layer_norm")
+ # vision encoder
+ if "visual.class_embedding" in name:
+ name = name.replace("visual.class_embedding", "vision_model.embeddings.class_embedding")
+ if "visual.conv1" in name:
+ name = name.replace("visual.conv1", "vision_model.embeddings.patch_embedding")
+ if "visual.positional_embedding" in name:
+ name = name.replace("visual.positional_embedding", "vision_model.embeddings.position_embedding.weight")
+ if "visual.ln_pre" in name:
+ name = name.replace("visual.ln_pre", "vision_model.pre_layrnorm")
+ if "visual.ln_post" in name:
+ name = name.replace("visual.ln_post", "vision_model.post_layernorm")
+ # projection layers
+ if "visual.proj" in name:
+ name = name.replace("visual.proj", "visual_projection.weight")
+ if "text_projection" in name:
+ name = name.replace("text_projection", "text_projection.weight")
+ # decoder
+ if "trans_conv" in name:
+ name = name.replace("trans_conv", "transposed_convolution")
+ if "film_mul" in name or "film_add" in name or "reduce" in name or "transposed_convolution" in name:
+ name = "decoder." + name
+ if "blocks" in name:
+ name = name.replace("blocks", "decoder.layers")
+ if "linear1" in name:
+ name = name.replace("linear1", "mlp.fc1")
+ if "linear2" in name:
+ name = name.replace("linear2", "mlp.fc2")
+ if "norm1" in name and "layer_" not in name:
+ name = name.replace("norm1", "layer_norm1")
+ if "norm2" in name and "layer_" not in name:
+ name = name.replace("norm2", "layer_norm2")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if key.startswith("clip_model") and "attn.in_proj" in key:
+ key_split = key.split(".")
+ if "visual" in key:
+ layer_num = int(key_split[4])
+ dim = config.vision_config.hidden_size
+ prefix = "vision_model"
+ else:
+ layer_num = int(key_split[3])
+ dim = config.text_config.hidden_size
+ prefix = "text_model"
+
+ if "weight" in key:
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.q_proj.weight"] = val[:dim, :]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.k_proj.weight"] = val[
+ dim : dim * 2, :
+ ]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.v_proj.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.q_proj.bias"] = val[:dim]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.k_proj.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.v_proj.bias"] = val[-dim:]
+ elif "self_attn" in key and "out_proj" not in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[1])
+ dim = config.reduce_dim
+ if "weight" in key:
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.q_proj.weight"] = val[:dim, :]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.k_proj.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.v_proj.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.q_proj.bias"] = val[:dim]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.k_proj.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.v_proj.bias"] = val[-dim:]
+ else:
+ new_name = rename_key(key)
+ if "visual_projection" in new_name or "text_projection" in new_name:
+ val = val.T
+ orig_state_dict[new_name] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+def convert_clipseg_checkpoint(model_name, checkpoint_path, pytorch_dump_folder_path, push_to_hub):
+ config = get_clipseg_config(model_name)
+ model = CLIPSegForImageSegmentation(config)
+ model.eval()
+
+ state_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ # remove some keys
+ for key in state_dict.copy().keys():
+ if key.startswith("model"):
+ state_dict.pop(key, None)
+
+ # rename some keys
+ state_dict = convert_state_dict(state_dict, config)
+ missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
+
+ if missing_keys != ["clip.text_model.embeddings.position_ids", "clip.vision_model.embeddings.position_ids"]:
+ raise ValueError("Missing keys that are not expected: {}".format(missing_keys))
+ if unexpected_keys != ["decoder.reduce.weight", "decoder.reduce.bias"]:
+ raise ValueError(f"Unexpected keys: {unexpected_keys}")
+
+ feature_extractor = ViTFeatureExtractor(size=352)
+ tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
+ processor = CLIPSegProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ image = prepare_img()
+ text = ["a glass", "something to fill", "wood", "a jar"]
+
+ inputs = processor(text=text, images=[image] * len(text), padding="max_length", return_tensors="pt")
+
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify values
+ expected_conditional = torch.tensor([0.1110, -0.1882, 0.1645])
+ expected_pooled_output = torch.tensor([0.2692, -0.7197, -0.1328])
+ if model_name == "clipseg-rd64-refined":
+ expected_masks_slice = torch.tensor(
+ [[-10.0407, -9.9431, -10.2646], [-9.9751, -9.7064, -9.9586], [-9.6891, -9.5645, -9.9618]]
+ )
+ elif model_name == "clipseg-rd64":
+ expected_masks_slice = torch.tensor(
+ [[-7.2877, -7.2711, -7.2463], [-7.2652, -7.2780, -7.2520], [-7.2239, -7.2204, -7.2001]]
+ )
+ elif model_name == "clipseg-rd16":
+ expected_masks_slice = torch.tensor(
+ [[-6.3955, -6.4055, -6.4151], [-6.3911, -6.4033, -6.4100], [-6.3474, -6.3702, -6.3762]]
+ )
+ else:
+ raise ValueError(f"Model name {model_name} not supported.")
+
+ assert torch.allclose(outputs.logits[0, :3, :3], expected_masks_slice, atol=1e-3)
+ assert torch.allclose(outputs.conditional_embeddings[0, :3], expected_conditional, atol=1e-3)
+ assert torch.allclose(outputs.pooled_output[0, :3], expected_pooled_output, atol=1e-3)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and processor to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print(f"Pushing model and processor for {model_name} to the hub")
+ model.push_to_hub(f"CIDAS/{model_name}")
+ processor.push_to_hub(f"CIDAS/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="clipseg-rd64",
+ type=str,
+ choices=["clipseg-rd16", "clipseg-rd64", "clipseg-rd64-refined"],
+ help=(
+ "Name of the model. Supported models are: clipseg-rd64, clipseg-rd16 and clipseg-rd64-refined (rd meaning"
+ " reduce dimension)"
+ ),
+ )
+ parser.add_argument(
+ "--checkpoint_path",
+ default="/Users/nielsrogge/Documents/CLIPSeg/clip_plus_rd64-uni.pth",
+ type=str,
+ help=(
+ "Path to the original checkpoint. Note that the script assumes that the checkpoint includes both CLIP and"
+ " the decoder weights."
+ ),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_clipseg_checkpoint(args.model_name, args.checkpoint_path, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/clipseg/modeling_clipseg.py b/src/transformers/models/clipseg/modeling_clipseg.py
new file mode 100644
index 0000000000000..87caf24ed4bf6
--- /dev/null
+++ b/src/transformers/models/clipseg/modeling_clipseg.py
@@ -0,0 +1,1493 @@
+# coding=utf-8
+# Copyright 2022 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch CLIPSeg model."""
+
+import copy
+import math
+from dataclasses import dataclass
+from typing import Any, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_clipseg import CLIPSegConfig, CLIPSegTextConfig, CLIPSegVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+_CHECKPOINT_FOR_DOC = "CIDAS/clipseg-rd64-refined"
+
+CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "CIDAS/clipseg-rd64-refined",
+ # See all CLIPSeg models at https://huggingface.co/models?filter=clipseg
+]
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# contrastive loss function, adapted from
+# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIPSeg.html
+def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
+ return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
+
+
+# Copied from transformers.models.clip.modeling_clip.clip_loss with clip->clipseg
+def clipseg_loss(similarity: torch.Tensor) -> torch.Tensor:
+ caption_loss = contrastive_loss(similarity)
+ image_loss = contrastive_loss(similarity.t())
+ return (caption_loss + image_loss) / 2.0
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->CLIPSeg
+class CLIPSegOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`CLIPSegTextModel`].
+ image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The image embeddings obtained by applying the projection layer to the pooled output of
+ [`CLIPSegVisionModel`].
+ text_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegTextModel`].
+ vision_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: torch.FloatTensor = None
+ logits_per_text: torch.FloatTensor = None
+ text_embeds: torch.FloatTensor = None
+ image_embeds: torch.FloatTensor = None
+ text_model_output: BaseModelOutputWithPooling = None
+ vision_model_output: BaseModelOutputWithPooling = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+@dataclass
+class CLIPSegDecoderOutput(ModelOutput):
+ """
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Classification scores for each pixel.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class CLIPSegImageSegmentationOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ ...
+ vision_model_output (`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ conditional_embeddings: torch.FloatTensor = None
+ pooled_output: torch.FloatTensor = None
+ vision_model_output: BaseModelOutputWithPooling = None
+ decoder_output: CLIPSegDecoderOutput = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["vision_model_output", "decoder_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+class CLIPSegVisionEmbeddings(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings.__init__
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size, bias=False
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches + 1
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)))
+
+ def interpolate_position_embeddings(self, new_size):
+ if len(new_size) != 2:
+ raise ValueError("new_size should consist of 2 values")
+
+ num_patches_one_direction = int(self.num_patches**0.5)
+ # we interpolate the position embeddings in 2D
+ a = self.position_embedding.weight[1:].T.view(
+ 1, self.config.hidden_size, num_patches_one_direction, num_patches_one_direction
+ )
+ b = (
+ nn.functional.interpolate(a, new_size, mode="bicubic", align_corners=False)
+ .squeeze(0)
+ .view(self.config.hidden_size, new_size[0] * new_size[1])
+ .T
+ )
+ result = torch.cat([self.position_embedding.weight[:1], b])
+
+ return result
+
+ def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
+ batch_size = pixel_values.shape[0]
+ patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
+ patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
+
+ class_embeds = self.class_embedding.expand(batch_size, 1, -1)
+ embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
+
+ if embeddings.shape[1] != self.num_positions:
+ new_shape = int(math.sqrt(embeddings.shape[1] - 1))
+ embeddings = embeddings + self.interpolate_position_embeddings((new_shape, new_shape))
+ embeddings = embeddings.to(embeddings.dtype)
+ else:
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->CLIPSeg
+class CLIPSegTextEmbeddings(nn.Module):
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__()
+ embed_dim = config.hidden_size
+
+ self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
+ self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ ) -> torch.Tensor:
+ seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, :seq_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.token_embedding(input_ids)
+
+ position_embeddings = self.position_embedding(position_ids)
+ embeddings = inputs_embeds + position_embeddings
+
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPAttention with CLIP->CLIPSeg
+class CLIPSegAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scale
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ # apply the causal_attention_mask first
+ if causal_attention_mask is not None:
+ if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
+ f" {causal_attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if output_attentions:
+ # this operation is a bit akward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->CLIPSeg
+class CLIPSegMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->CLIPSeg
+class CLIPSegEncoderLayer(nn.Module):
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = CLIPSegAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim)
+ self.mlp = CLIPSegMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPPreTrainedModel with CLIP->CLIPSeg
+class CLIPSegPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = CLIPSegConfig
+ base_model_prefix = "clip"
+ supports_gradient_checkpointing = True
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ factor = self.config.initializer_factor
+ if isinstance(module, CLIPSegTextEmbeddings):
+ module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
+ module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
+ elif isinstance(module, CLIPSegVisionEmbeddings):
+ factor = self.config.initializer_factor
+ nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
+ nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
+ nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
+ elif isinstance(module, CLIPSegAttention):
+ factor = self.config.initializer_factor
+ in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ out_proj_std = (module.embed_dim**-0.5) * factor
+ nn.init.normal_(module.q_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.k_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.v_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.out_proj.weight, std=out_proj_std)
+ elif isinstance(module, CLIPSegMLP):
+ factor = self.config.initializer_factor
+ in_proj_std = (
+ (module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ )
+ fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
+ nn.init.normal_(module.fc1.weight, std=fc_std)
+ nn.init.normal_(module.fc2.weight, std=in_proj_std)
+ elif isinstance(module, CLIPSegModel):
+ nn.init.normal_(
+ module.text_projection.weight,
+ std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+ nn.init.normal_(
+ module.visual_projection.weight,
+ std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+
+ if isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, CLIPSegEncoder):
+ module.gradient_checkpointing = value
+
+
+CLIPSEG_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`CLIPSegConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+CLIPSEG_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+CLIPSEG_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+CLIPSEG_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->CLIPSeg
+class CLIPSegEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`CLIPSegEncoderLayer`].
+
+ Args:
+ config: CLIPSegConfig
+ """
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([CLIPSegEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Causal mask for the text model. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(encoder_layer),
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class CLIPSegTextTransformer(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+ self.embeddings = CLIPSegTextEmbeddings(config)
+ self.encoder = CLIPSegEncoder(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim)
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
+ # Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.forward with clip->clipseg, CLIP->CLIPSeg
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is None:
+ raise ValueError("You have to specify either input_ids")
+
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+
+ hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
+
+ bsz, seq_len = input_shape
+ # CLIPSeg's text model uses causal mask, prepare it here.
+ # https://github.com/openai/CLIPSeg/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clipseg/model.py#L324
+ causal_attention_mask = self._build_causal_attention_mask(bsz, seq_len, hidden_states.dtype).to(
+ hidden_states.device
+ )
+ # expand attention_mask
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _expand_mask(attention_mask, hidden_states.dtype)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.final_layer_norm(last_hidden_state)
+
+ # text_embeds.shape = [batch_size, sequence_length, transformer.width]
+ # take features from the eot embedding (eot_token is the highest number in each sequence)
+ # casting to torch.int for onnx compatibility: argmax doesn't support int64 inputs with opset 14
+ pooled_output = last_hidden_state[
+ torch.arange(last_hidden_state.shape[0], device=input_ids.device), input_ids.to(torch.int).argmax(dim=-1)
+ ]
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+ def _build_causal_attention_mask(self, bsz, seq_len, dtype):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # pytorch uses additive attention mask; fill with -inf
+ mask = torch.empty(bsz, seq_len, seq_len, dtype=dtype)
+ mask.fill_(torch.tensor(torch.finfo(dtype).min))
+ mask.triu_(1) # zero out the lower diagonal
+ mask = mask.unsqueeze(1) # expand mask
+ return mask
+
+
+class CLIPSegTextModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegTextConfig
+
+ _no_split_modules = ["CLIPSegEncoderLayer"]
+
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__(config)
+ self.text_model = CLIPSegTextTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.text_model.embeddings.token_embedding
+
+ def set_input_embeddings(self, value):
+ self.text_model.embeddings.token_embedding = value
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPTokenizer, CLIPSegTextModel
+
+ >>> tokenizer = CLIPTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegTextModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled (EOS token) states
+ ```"""
+ return self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+class CLIPSegVisionTransformer(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = CLIPSegVisionEmbeddings(config)
+ self.pre_layrnorm = nn.LayerNorm(embed_dim)
+ self.encoder = CLIPSegEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim)
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.forward
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ hidden_states = self.embeddings(pixel_values)
+ hidden_states = self.pre_layrnorm(hidden_states)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ pooled_output = last_hidden_state[:, 0, :]
+ pooled_output = self.post_layernorm(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class CLIPSegVisionModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegVisionConfig
+ main_input_name = "pixel_values"
+
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__(config)
+ self.vision_model = CLIPSegVisionTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegVisionModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegVisionModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+@add_start_docstrings(CLIPSEG_START_DOCSTRING)
+class CLIPSegModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegConfig
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ if not isinstance(config.text_config, CLIPSegTextConfig):
+ raise ValueError(
+ "config.text_config is expected to be of type CLIPSegTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ if not isinstance(config.vision_config, CLIPSegVisionConfig):
+ raise ValueError(
+ "config.vision_config is expected to be of type CLIPSegVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.projection_dim = config.projection_dim
+ self.text_embed_dim = text_config.hidden_size
+ self.vision_embed_dim = vision_config.hidden_size
+
+ self.text_model = CLIPSegTextTransformer(text_config)
+ self.vision_model = CLIPSegVisionTransformer(vision_config)
+
+ self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=False)
+ self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False)
+ self.logit_scale = nn.Parameter(torch.ones([]) * self.config.logit_scale_init_value)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`CLIPSegTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPTokenizer, CLIPSegModel
+
+ >>> tokenizer = CLIPTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+ >>> text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = text_outputs[1]
+ text_features = self.text_projection(pooled_output)
+
+ return text_features
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`CLIPSegVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = vision_outputs[1] # pooled_output
+ image_features = self.visual_projection(pooled_output)
+
+ return image_features
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CLIPSegOutput, config_class=CLIPSegConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CLIPSegOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(
+ ... text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True
+ ... )
+
+ >>> outputs = model(**inputs)
+ >>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+ >>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ image_embeds = self.visual_projection(image_embeds)
+
+ text_embeds = text_outputs[1]
+ text_embeds = self.text_projection(text_embeds)
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
+ logits_per_image = logits_per_text.t()
+
+ loss = None
+ if return_loss:
+ loss = clipseg_loss(logits_per_text)
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return CLIPSegOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
+
+
+class CLIPSegDecoderLayer(nn.Module):
+ """
+ CLIPSeg decoder layer, which is identical to `CLIPSegEncoderLayer`, except that normalization is applied after
+ self-attention/MLP, rather than before.
+ """
+
+ # Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = CLIPSegAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim)
+ self.mlp = CLIPSegMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = residual + hidden_states
+ hidden_states = self.layer_norm1(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class CLIPSegDecoder(CLIPSegPreTrainedModel):
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ self.conditional_layer = config.conditional_layer
+
+ self.film_mul = nn.Linear(config.projection_dim, config.reduce_dim)
+ self.film_add = nn.Linear(config.projection_dim, config.reduce_dim)
+
+ if config.use_complex_transposed_convolution:
+ transposed_kernels = (config.vision_config.patch_size // 4, config.vision_config.patch_size // 4)
+
+ self.transposed_convolution = nn.Sequential(
+ nn.Conv2d(config.reduce_dim, config.reduce_dim, kernel_size=3, padding=1),
+ nn.ReLU(),
+ nn.ConvTranspose2d(
+ config.reduce_dim,
+ config.reduce_dim // 2,
+ kernel_size=transposed_kernels[0],
+ stride=transposed_kernels[0],
+ ),
+ nn.ReLU(),
+ nn.ConvTranspose2d(
+ config.reduce_dim // 2, 1, kernel_size=transposed_kernels[1], stride=transposed_kernels[1]
+ ),
+ )
+ else:
+ self.transposed_convolution = nn.ConvTranspose2d(
+ config.reduce_dim, 1, config.vision_config.patch_size, stride=config.vision_config.patch_size
+ )
+
+ depth = len(config.extract_layers)
+ self.reduces = nn.ModuleList(
+ [nn.Linear(config.vision_config.hidden_size, config.reduce_dim) for _ in range(depth)]
+ )
+
+ decoder_config = copy.deepcopy(config.vision_config)
+ decoder_config.hidden_size = config.reduce_dim
+ decoder_config.num_attention_heads = config.decoder_num_attention_heads
+ decoder_config.intermediate_size = config.decoder_intermediate_size
+ decoder_config.hidden_act = "relu"
+ self.layers = nn.ModuleList([CLIPSegDecoderLayer(decoder_config) for _ in range(len(config.extract_layers))])
+
+ def forward(
+ self,
+ hidden_states: Tuple[torch.Tensor],
+ conditional_embeddings: torch.Tensor,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = True,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ activations = hidden_states[::-1]
+
+ output = None
+ for i, (activation, layer, reduce) in enumerate(zip(activations, self.layers, self.reduces)):
+ if output is not None:
+ output = reduce(activation) + output
+ else:
+ output = reduce(activation)
+
+ if i == self.conditional_layer:
+ output = self.film_mul(conditional_embeddings) * output.permute(1, 0, 2) + self.film_add(
+ conditional_embeddings
+ )
+ output = output.permute(1, 0, 2)
+
+ layer_outputs = layer(
+ output, attention_mask=None, causal_attention_mask=None, output_attentions=output_attentions
+ )
+
+ output = layer_outputs[0]
+
+ if output_hidden_states:
+ all_hidden_states += (output,)
+
+ if output_attentions:
+ all_attentions += (layer_outputs[1],)
+
+ output = output[:, 1:, :].permute(0, 2, 1) # remove cls token and reshape to [batch_size, reduce_dim, seq_len]
+
+ size = int(math.sqrt(output.shape[2]))
+
+ batch_size = conditional_embeddings.shape[0]
+ output = output.view(batch_size, output.shape[1], size, size)
+
+ logits = self.transposed_convolution(output).squeeze()
+
+ if not return_dict:
+ return tuple(v for v in [logits, all_hidden_states, all_attentions] if v is not None)
+
+ return CLIPSegDecoderOutput(
+ logits=logits,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ CLIPSeg model with a Transformer-based decoder on top for zero-shot and one-shot image segmentation.
+ """,
+ CLIPSEG_START_DOCSTRING,
+)
+class CLIPSegForImageSegmentation(CLIPSegPreTrainedModel):
+ config_class = CLIPSegConfig
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ self.config = config
+
+ self.clip = CLIPSegModel(config)
+ self.extract_layers = config.extract_layers
+
+ self.decoder = CLIPSegDecoder(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_conditional_embeddings(
+ self,
+ batch_size: int = None,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ conditional_pixel_values: Optional[torch.Tensor] = None,
+ ):
+ if input_ids is not None:
+ # compute conditional embeddings from texts
+ if len(input_ids) != batch_size:
+ raise ValueError("Make sure to pass as many prompt texts as there are query images")
+ with torch.no_grad():
+ conditional_embeddings = self.clip.get_text_features(
+ input_ids, attention_mask=attention_mask, position_ids=position_ids
+ )
+ elif conditional_pixel_values is not None:
+ # compute conditional embeddings from images
+ if len(conditional_pixel_values) != batch_size:
+ raise ValueError("Make sure to pass as many prompt images as there are query images")
+ with torch.no_grad():
+ conditional_embeddings = self.clip.get_image_features(conditional_pixel_values)
+ else:
+ raise ValueError(
+ "Invalid conditional, should be either provided as `input_ids` or `conditional_pixel_values`"
+ )
+
+ return conditional_embeddings
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CLIPSegImageSegmentationOutput, config_class=CLIPSegTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.FloatTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ conditional_pixel_values: Optional[torch.FloatTensor] = None,
+ conditional_embeddings: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CLIPSegOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> texts = ["a cat", "a remote", "a blanket"]
+ >>> inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+
+ >>> logits = outputs.logits
+ >>> print(logits.shape)
+ torch.Size([3, 352, 352])
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # step 1: forward the query images through the frozen CLIP vision encoder
+ with torch.no_grad():
+ vision_outputs = self.clip.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=True, # we need the intermediate hidden states
+ return_dict=return_dict,
+ )
+ pooled_output = self.clip.visual_projection(vision_outputs[1])
+
+ hidden_states = vision_outputs.hidden_states if return_dict else vision_outputs[2]
+ # we add +1 here as the hidden states also include the initial embeddings
+ activations = [hidden_states[i + 1] for i in self.extract_layers]
+
+ # update vision_outputs
+ if return_dict:
+ vision_outputs = BaseModelOutputWithPooling(
+ last_hidden_state=vision_outputs.last_hidden_state,
+ pooler_output=vision_outputs.pooler_output,
+ hidden_states=vision_outputs.hidden_states if output_hidden_states else None,
+ attentions=vision_outputs.attentions,
+ )
+ else:
+ vision_outputs = (
+ vision_outputs[:2] + vision_outputs[3:] if not output_hidden_states else vision_outputs
+ )
+
+ # step 2: compute conditional embeddings, either from text, images or an own provided embedding
+ if conditional_embeddings is None:
+ conditional_embeddings = self.get_conditional_embeddings(
+ batch_size=pixel_values.shape[0],
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ conditional_pixel_values=conditional_pixel_values,
+ )
+ else:
+ if conditional_embeddings.shape[0] != pixel_values.shape[0]:
+ raise ValueError(
+ "Make sure to pass as many conditional embeddings as there are query images in the batch"
+ )
+ if conditional_embeddings.shape[1] != self.config.projection_dim:
+ raise ValueError(
+ "Make sure that the feature dimension of the conditional embeddings matches"
+ " `config.projection_dim`."
+ )
+
+ # step 3: forward both the pooled output and the activations through the lightweight decoder to predict masks
+ decoder_outputs = self.decoder(
+ activations,
+ conditional_embeddings,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ logits = decoder_outputs.logits if return_dict else decoder_outputs[0]
+
+ loss = None
+ if labels is not None:
+ loss_fn = nn.BCEWithLogitsLoss()
+ loss = loss_fn(logits, labels)
+
+ if not return_dict:
+ output = (logits, conditional_embeddings, pooled_output, vision_outputs, decoder_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return CLIPSegImageSegmentationOutput(
+ loss=loss,
+ logits=logits,
+ conditional_embeddings=conditional_embeddings,
+ pooled_output=pooled_output,
+ vision_model_output=vision_outputs,
+ decoder_output=decoder_outputs,
+ )
diff --git a/src/transformers/models/clipseg/processing_clipseg.py b/src/transformers/models/clipseg/processing_clipseg.py
new file mode 100644
index 0000000000000..4a18e4ba7a902
--- /dev/null
+++ b/src/transformers/models/clipseg/processing_clipseg.py
@@ -0,0 +1,108 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for CLIPSeg
+"""
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding
+
+
+class CLIPSegProcessor(ProcessorMixin):
+ r"""
+ Constructs a CLIPSeg processor which wraps a CLIPSeg feature extractor and a CLIP tokenizer into a single
+ processor.
+
+ [`CLIPSegProcessor`] offers all the functionalities of [`ViTFeatureExtractor`] and [`CLIPTokenizerFast`]. See the
+ [`~CLIPSegProcessor.__call__`] and [`~CLIPSegProcessor.decode`] for more information.
+
+ Args:
+ feature_extractor ([`ViTFeatureExtractor`]):
+ The feature extractor is a required input.
+ tokenizer ([`CLIPTokenizerFast`]):
+ The tokenizer is a required input.
+ """
+ feature_extractor_class = "ViTFeatureExtractor"
+ tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
+
+ def __init__(self, feature_extractor, tokenizer):
+ super().__init__(feature_extractor, tokenizer)
+ self.current_processor = self.feature_extractor
+
+ def __call__(self, text=None, images=None, return_tensors=None, **kwargs):
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to CLIPTokenizerFast's [`~CLIPTokenizerFast.__call__`] if `text` is not `None` to encode
+ the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
+ ViTFeatureExtractor's [`~ViTFeatureExtractor.__call__`] if `images` is not `None`. Please refer to the
+ doctsring of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+
+ if text is None and images is None:
+ raise ValueError("You have to specify either text or images. Both cannot be none.")
+
+ if text is not None:
+ encoding = self.tokenizer(text, return_tensors=return_tensors, **kwargs)
+
+ if images is not None:
+ image_features = self.feature_extractor(images, return_tensors=return_tensors, **kwargs)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to CLIPTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to CLIPTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/transformers/processing_utils.py b/src/transformers/processing_utils.py
index 569e9975b16c9..5cc41c447b7bd 100644
--- a/src/transformers/processing_utils.py
+++ b/src/transformers/processing_utils.py
@@ -56,7 +56,7 @@ def __init__(self, *args, **kwargs):
# Sanitize args and kwargs
for key in kwargs:
if key not in self.attributes:
- raise TypeError(f"Unexepcted keyword argument {key}.")
+ raise TypeError(f"Unexpected keyword argument {key}.")
for arg, attribute_name in zip(args, self.attributes):
if attribute_name in kwargs:
raise TypeError(f"Got multiple values for argument {attribute_name}.")
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index cb2f93be0fc90..755f1af0a665c 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -1207,6 +1207,44 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class CLIPSegForImageSegmentation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegTextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegVisionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/tests/models/clipseg/__init__.py b/tests/models/clipseg/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/tests/models/clipseg/test_modeling_clipseg.py b/tests/models/clipseg/test_modeling_clipseg.py
new file mode 100644
index 0000000000000..3a338ddbf820a
--- /dev/null
+++ b/tests/models/clipseg/test_modeling_clipseg.py
@@ -0,0 +1,735 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch CLIPSeg model. """
+
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+
+import requests
+import transformers
+from transformers import MODEL_MAPPING, CLIPSegConfig, CLIPSegProcessor, CLIPSegTextConfig, CLIPSegVisionConfig
+from transformers.models.auto import get_values
+from transformers.testing_utils import (
+ is_flax_available,
+ is_pt_flax_cross_test,
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import CLIPSegForImageSegmentation, CLIPSegModel, CLIPSegTextModel, CLIPSegVisionModel
+ from transformers.models.clipseg.modeling_clipseg import CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+if is_flax_available():
+ import jax.numpy as jnp
+ from transformers.modeling_flax_pytorch_utils import (
+ convert_pytorch_state_dict_to_flax,
+ load_flax_weights_in_pytorch_model,
+ )
+
+
+class CLIPSegVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return CLIPSegVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = CLIPSegVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as CLIPSeg does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (CLIPSegVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = CLIPSegVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=CLIPSegVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="CLIPSeg does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_training(self):
+ pass
+
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class CLIPSegTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return CLIPSegTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = CLIPSegTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegTextModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (CLIPSegTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = CLIPSegTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=CLIPSegTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_training(self):
+ pass
+
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="CLIPSeg does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegTextModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegTextModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class CLIPSegModelTester:
+ def __init__(self, parent, is_training=True):
+ self.parent = parent
+ self.text_model_tester = CLIPSegTextModelTester(parent)
+ self.vision_model_tester = CLIPSegVisionModelTester(parent)
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return CLIPSegConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(),
+ self.vision_model_tester.get_config(),
+ projection_dim=64,
+ reduce_dim=32,
+ extract_layers=[1, 2, 3],
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = CLIPSegModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def create_and_check_model_for_image_segmentation(self, config, input_ids, attention_maks, pixel_values):
+ model = CLIPSegForImageSegmentation(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values)
+ self.parent.assertEqual(
+ result.logits.shape,
+ (
+ self.vision_model_tester.batch_size,
+ self.vision_model_tester.image_size,
+ self.vision_model_tester.image_size,
+ ),
+ )
+ self.parent.assertEqual(
+ result.conditional_embeddings.shape, (self.text_model_tester.batch_size, config.projection_dim)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (CLIPSegModel, CLIPSegForImageSegmentation) if is_torch_available() else ()
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ # CLIPSegForImageSegmentation requires special treatment
+ if return_labels:
+ if model_class.__name__ == "CLIPSegForImageSegmentation":
+ batch_size, _, height, width = inputs_dict["pixel_values"].shape
+ inputs_dict["labels"] = torch.zeros(
+ [batch_size, height, width], device=torch_device, dtype=torch.float
+ )
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = CLIPSegModelTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_for_image_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_for_image_segmentation(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegModel does not have input/output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ # override as the some parameters require custom initialization
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initilized as per the original implementation
+ if "logit_scale" in name:
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif "film" in name or "transposed_conv" in name or "reduce" in name:
+ # those parameters use PyTorch' default nn.Linear initialization scheme
+ pass
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ return
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # CLIPSeg needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save CLIPSegConfig and check if we can load CLIPSegVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = CLIPSegVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save CLIPSegConfig and check if we can load CLIPSegTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = CLIPSegTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ # overwrite from common since FlaxCLIPSegModel returns nested output
+ # which is not supported in the common test
+ @is_pt_flax_cross_test
+ def test_equivalence_pt_to_flax(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ with self.subTest(model_class.__name__):
+
+ # load PyTorch class
+ pt_model = model_class(config).eval()
+ # Flax models don't use the `use_cache` option and cache is not returned as a default.
+ # So we disable `use_cache` here for PyTorch model.
+ pt_model.config.use_cache = False
+
+ fx_model_class_name = "Flax" + model_class.__name__
+
+ if not hasattr(transformers, fx_model_class_name):
+ return
+
+ fx_model_class = getattr(transformers, fx_model_class_name)
+
+ # load Flax class
+ fx_model = fx_model_class(config, dtype=jnp.float32)
+ # make sure only flax inputs are forward that actually exist in function args
+ fx_input_keys = inspect.signature(fx_model.__call__).parameters.keys()
+
+ # prepare inputs
+ pt_inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ # remove function args that don't exist in Flax
+ pt_inputs = {k: v for k, v in pt_inputs.items() if k in fx_input_keys}
+
+ fx_state = convert_pytorch_state_dict_to_flax(pt_model.state_dict(), fx_model)
+ fx_model.params = fx_state
+
+ with torch.no_grad():
+ pt_outputs = pt_model(**pt_inputs).to_tuple()
+
+ # convert inputs to Flax
+ fx_inputs = {k: np.array(v) for k, v in pt_inputs.items() if torch.is_tensor(v)}
+ fx_outputs = fx_model(**fx_inputs).to_tuple()
+ self.assertEqual(len(fx_outputs), len(pt_outputs), "Output lengths differ between Flax and PyTorch")
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pt_model.save_pretrained(tmpdirname)
+ fx_model_loaded = fx_model_class.from_pretrained(tmpdirname, from_pt=True)
+
+ fx_outputs_loaded = fx_model_loaded(**fx_inputs).to_tuple()
+ self.assertEqual(
+ len(fx_outputs_loaded), len(pt_outputs), "Output lengths differ between Flax and PyTorch"
+ )
+ for fx_output_loaded, pt_output in zip(fx_outputs_loaded[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output_loaded, pt_output.numpy(), 4e-2)
+
+ # overwrite from common since FlaxCLIPSegModel returns nested output
+ # which is not supported in the common test
+ @is_pt_flax_cross_test
+ def test_equivalence_flax_to_pt(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ with self.subTest(model_class.__name__):
+ # load corresponding PyTorch class
+ pt_model = model_class(config).eval()
+
+ # So we disable `use_cache` here for PyTorch model.
+ pt_model.config.use_cache = False
+
+ fx_model_class_name = "Flax" + model_class.__name__
+
+ if not hasattr(transformers, fx_model_class_name):
+ # no flax model exists for this class
+ return
+
+ fx_model_class = getattr(transformers, fx_model_class_name)
+
+ # load Flax class
+ fx_model = fx_model_class(config, dtype=jnp.float32)
+ # make sure only flax inputs are forward that actually exist in function args
+ fx_input_keys = inspect.signature(fx_model.__call__).parameters.keys()
+
+ pt_model = load_flax_weights_in_pytorch_model(pt_model, fx_model.params)
+
+ # make sure weights are tied in PyTorch
+ pt_model.tie_weights()
+
+ # prepare inputs
+ pt_inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ # remove function args that don't exist in Flax
+ pt_inputs = {k: v for k, v in pt_inputs.items() if k in fx_input_keys}
+
+ with torch.no_grad():
+ pt_outputs = pt_model(**pt_inputs).to_tuple()
+
+ fx_inputs = {k: np.array(v) for k, v in pt_inputs.items() if torch.is_tensor(v)}
+
+ fx_outputs = fx_model(**fx_inputs).to_tuple()
+ self.assertEqual(len(fx_outputs), len(pt_outputs), "Output lengths differ between Flax and PyTorch")
+
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ fx_model.save_pretrained(tmpdirname)
+ pt_model_loaded = model_class.from_pretrained(tmpdirname, from_flax=True)
+
+ with torch.no_grad():
+ pt_outputs_loaded = pt_model_loaded(**pt_inputs).to_tuple()
+
+ self.assertEqual(
+ len(fx_outputs), len(pt_outputs_loaded), "Output lengths differ between Flax and PyTorch"
+ )
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs_loaded[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class in get_values(MODEL_MAPPING):
+ continue
+
+ print("Model class:", model_class)
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ for k, v in inputs.items():
+ print(k, v.shape)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+class CLIPSegModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_image_segmentation(self):
+ model_name = "CIDAS/clipseg-rd64-refined"
+ processor = CLIPSegProcessor.from_pretrained(model_name)
+ model = CLIPSegForImageSegmentation.from_pretrained(model_name).to(torch_device)
+
+ image = prepare_img()
+ texts = ["a cat", "a remote", "a blanket"]
+ inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the predicted masks
+ self.assertEqual(
+ outputs.logits.shape,
+ torch.Size((3, 352, 352)),
+ )
+ expected_masks_slice = torch.tensor(
+ [[-7.4577, -7.4952, -7.4072], [-7.3115, -7.0969, -7.1624], [-6.9472, -6.7641, -6.8911]]
+ )
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_masks_slice, atol=1e-3))
+
+ # verify conditional and pooled output
+ expected_conditional = torch.tensor([0.5601, -0.0314, 0.1980])
+ expected_pooled_output = torch.tensor([0.2692, -0.7197, -0.1328])
+ self.assertTrue(torch.allclose(outputs.conditional_embeddings[0, :3], expected_conditional, atol=1e-3))
+ self.assertTrue(torch.allclose(outputs.pooled_output[0, :3], expected_pooled_output, atol=1e-3))
diff --git a/tests/models/clipseg/test_processor_clipseg.py b/tests/models/clipseg/test_processor_clipseg.py
new file mode 100644
index 0000000000000..6da7345f6a6c9
--- /dev/null
+++ b/tests/models/clipseg/test_processor_clipseg.py
@@ -0,0 +1,188 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+
+from transformers import CLIPTokenizer, CLIPTokenizerFast
+from transformers.models.clip.tokenization_clip import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_vision
+from transformers.utils import FEATURE_EXTRACTOR_NAME, is_vision_available
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import CLIPSegProcessor, ViTFeatureExtractor
+
+
+@require_vision
+class CLIPSegProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.tmpdirname = tempfile.mkdtemp()
+
+ # fmt: off
+ vocab = ["l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "lo", "l", "w", "r", "t", "low", "er", "lowest", "newer", "wider", "", "<|startoftext|>", "<|endoftext|>"]
+ # fmt: on
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "l o", "lo w", "e r", ""]
+ self.special_tokens_map = {"unk_token": ""}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ feature_extractor_map = {
+ "do_resize": True,
+ "size": 20,
+ "do_center_crop": True,
+ "crop_size": 18,
+ "do_normalize": True,
+ "image_mean": [0.48145466, 0.4578275, 0.40821073],
+ "image_std": [0.26862954, 0.26130258, 0.27577711],
+ }
+ self.feature_extractor_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(self.feature_extractor_file, "w", encoding="utf-8") as fp:
+ json.dump(feature_extractor_map, fp)
+
+ def get_tokenizer(self, **kwargs):
+ return CLIPTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs):
+ return CLIPTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return ViTFeatureExtractor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def prepare_image_inputs(self):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True."""
+
+ image_inputs = [np.random.randint(255, size=(3, 30, 400), dtype=np.uint8)]
+
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ return image_inputs
+
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+
+ processor_slow = CLIPSegProcessor(tokenizer=tokenizer_slow, feature_extractor=feature_extractor)
+ processor_slow.save_pretrained(self.tmpdirname)
+ processor_slow = CLIPSegProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = CLIPSegProcessor(tokenizer=tokenizer_fast, feature_extractor=feature_extractor)
+ processor_fast.save_pretrained(self.tmpdirname)
+ processor_fast = CLIPSegProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, CLIPTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, CLIPTokenizerFast)
+
+ self.assertEqual(processor_slow.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertEqual(processor_fast.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor_slow.feature_extractor, ViTFeatureExtractor)
+ self.assertIsInstance(processor_fast.feature_extractor, ViTFeatureExtractor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = CLIPSegProcessor(tokenizer=self.get_tokenizer(), feature_extractor=self.get_feature_extractor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_normalize=False, padding_value=1.0)
+
+ processor = CLIPSegProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, CLIPTokenizerFast)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, ViTFeatureExtractor)
+
+ def test_feature_extractor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = feature_extractor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "attention_mask", "pixel_values"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
diff --git a/utils/check_repo.py b/utils/check_repo.py
index 4b7ec38e80799..8b02185fa9bd5 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -46,6 +46,7 @@
# Being in this list is an exception and should **not** be the rule.
IGNORE_NON_TESTED = PRIVATE_MODELS.copy() + [
# models to ignore for not tested
+ "CLIPSegDecoder", # Building part of bigger (tested) model.
"TableTransformerEncoder", # Building part of bigger (tested) model.
"TableTransformerDecoder", # Building part of bigger (tested) model.
"TimeSeriesTransformerEncoder", # Building part of bigger (tested) model.
@@ -140,6 +141,9 @@
# should **not** be the rule.
IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
# models to ignore for model xxx mapping
+ "CLIPSegForImageSegmentation",
+ "CLIPSegVisionModel",
+ "CLIPSegTextModel",
"EsmForProteinFolding",
"TimeSeriesTransformerForPrediction",
"PegasusXEncoder",
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 53a74703d9659..18c7894da8312 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -35,6 +35,7 @@ src/transformers/models/bloom/configuration_bloom.py
src/transformers/models/camembert/configuration_camembert.py
src/transformers/models/canine/configuration_canine.py
src/transformers/models/clip/configuration_clip.py
+src/transformers/models/clipseg/modeling_clipseg.py
src/transformers/models/codegen/configuration_codegen.py
src/transformers/models/conditional_detr/configuration_conditional_detr.py
src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -187,4 +188,4 @@ src/transformers/models/xlnet/configuration_xlnet.py
src/transformers/models/yolos/configuration_yolos.py
src/transformers/models/yolos/modeling_yolos.py
src/transformers/models/x_clip/modeling_x_clip.py
-src/transformers/models/yoso/configuration_yoso.py
+src/transformers/models/yoso/configuration_yoso.py
\ No newline at end of file
+
+ CLIPSeg overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/timojl/clipseg).
+
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index a3ce3fd1eb2ee..b377395a9046c 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -171,6 +171,13 @@
"CLIPTokenizer",
"CLIPVisionConfig",
],
+ "models.clipseg": [
+ "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "CLIPSegConfig",
+ "CLIPSegProcessor",
+ "CLIPSegTextConfig",
+ "CLIPSegVisionConfig",
+ ],
"models.codegen": ["CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP", "CodeGenConfig", "CodeGenTokenizer"],
"models.conditional_detr": ["CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConditionalDetrConfig"],
"models.convbert": ["CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvBertConfig", "ConvBertTokenizer"],
@@ -1074,6 +1081,16 @@
"CLIPVisionModel",
]
)
+ _import_structure["models.clipseg"].extend(
+ [
+ "CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "CLIPSegModel",
+ "CLIPSegPreTrainedModel",
+ "CLIPSegTextModel",
+ "CLIPSegVisionModel",
+ "CLIPSegForImageSegmentation",
+ ]
+ )
_import_structure["models.x_clip"].extend(
[
"XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3225,6 +3242,13 @@
CLIPTokenizer,
CLIPVisionConfig,
)
+ from .models.clipseg import (
+ CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ CLIPSegConfig,
+ CLIPSegProcessor,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ )
from .models.codegen import CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP, CodeGenConfig, CodeGenTokenizer
from .models.conditional_detr import CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP, ConditionalDetrConfig
from .models.convbert import CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvBertConfig, ConvBertTokenizer
@@ -3993,6 +4017,14 @@
CLIPTextModel,
CLIPVisionModel,
)
+ from .models.clipseg import (
+ CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST,
+ CLIPSegForImageSegmentation,
+ CLIPSegModel,
+ CLIPSegPreTrainedModel,
+ CLIPSegTextModel,
+ CLIPSegVisionModel,
+ )
from .models.codegen import (
CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST,
CodeGenForCausalLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 86a775a1eb2b8..03153725125cc 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -37,6 +37,7 @@
camembert,
canine,
clip,
+ clipseg,
codegen,
conditional_detr,
convbert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 68f29f89ae50e..d8b59f123f676 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -42,6 +42,7 @@
("camembert", "CamembertConfig"),
("canine", "CanineConfig"),
("clip", "CLIPConfig"),
+ ("clipseg", "CLIPSegConfig"),
("codegen", "CodeGenConfig"),
("conditional_detr", "ConditionalDetrConfig"),
("convbert", "ConvBertConfig"),
@@ -182,6 +183,7 @@
("camembert", "CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("canine", "CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("clip", "CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("clipseg", "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("codegen", "CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("conditional_detr", "CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("convbert", "CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -315,6 +317,7 @@
("camembert", "CamemBERT"),
("canine", "CANINE"),
("clip", "CLIP"),
+ ("clipseg", "CLIPSeg"),
("codegen", "CodeGen"),
("conditional_detr", "Conditional DETR"),
("convbert", "ConvBERT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 76d38f95ab151..bc30cc21b60d0 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -39,6 +39,7 @@
[
("beit", "BeitFeatureExtractor"),
("clip", "CLIPFeatureExtractor"),
+ ("clipseg", "ViTFeatureExtractor"),
("conditional_detr", "ConditionalDetrFeatureExtractor"),
("convnext", "ConvNextFeatureExtractor"),
("cvt", "ConvNextFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 3da1dc1790572..7b6e701175859 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -41,6 +41,7 @@
("camembert", "CamembertModel"),
("canine", "CanineModel"),
("clip", "CLIPModel"),
+ ("clipseg", "CLIPSegModel"),
("codegen", "CodeGenModel"),
("conditional_detr", "ConditionalDetrModel"),
("convbert", "ConvBertModel"),
@@ -813,6 +814,7 @@
[
# Model for Zero Shot Image Classification mapping
("clip", "CLIPModel"),
+ ("clipseg", "CLIPSegModel"),
]
)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index 3e31a14d25817..f7bb87e25e2d7 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -40,6 +40,7 @@
PROCESSOR_MAPPING_NAMES = OrderedDict(
[
("clip", "CLIPProcessor"),
+ ("clipseg", "CLIPSegProcessor"),
("flava", "FlavaProcessor"),
("groupvit", "CLIPProcessor"),
("layoutlmv2", "LayoutLMv2Processor"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 46e57ac58bd4c..d5374e6f42e00 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -93,6 +93,13 @@
"CLIPTokenizerFast" if is_tokenizers_available() else None,
),
),
+ (
+ "clipseg",
+ (
+ "CLIPTokenizer",
+ "CLIPTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
("codegen", ("CodeGenTokenizer", "CodeGenTokenizerFast" if is_tokenizers_available() else None)),
("convbert", ("ConvBertTokenizer", "ConvBertTokenizerFast" if is_tokenizers_available() else None)),
(
diff --git a/src/transformers/models/clipseg/__init__.py b/src/transformers/models/clipseg/__init__.py
new file mode 100644
index 0000000000000..f6b09b9af9757
--- /dev/null
+++ b/src/transformers/models/clipseg/__init__.py
@@ -0,0 +1,75 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_clipseg": [
+ "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "CLIPSegConfig",
+ "CLIPSegTextConfig",
+ "CLIPSegVisionConfig",
+ ],
+ "processing_clipseg": ["CLIPSegProcessor"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_clipseg"] = [
+ "CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "CLIPSegModel",
+ "CLIPSegPreTrainedModel",
+ "CLIPSegTextModel",
+ "CLIPSegVisionModel",
+ "CLIPSegForImageSegmentation",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_clipseg import (
+ CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ CLIPSegConfig,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ )
+ from .processing_clipseg import CLIPSegProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_clipseg import (
+ CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST,
+ CLIPSegForImageSegmentation,
+ CLIPSegModel,
+ CLIPSegPreTrainedModel,
+ CLIPSegTextModel,
+ CLIPSegVisionModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/clipseg/configuration_clipseg.py b/src/transformers/models/clipseg/configuration_clipseg.py
new file mode 100644
index 0000000000000..1fe27b0d0b0f0
--- /dev/null
+++ b/src/transformers/models/clipseg/configuration_clipseg.py
@@ -0,0 +1,383 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" CLIPSeg model configuration"""
+
+import copy
+import os
+from typing import Union
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "CIDAS/clipseg-rd64": "https://huggingface.co/CIDAS/clipseg-rd64/resolve/main/config.json",
+}
+
+
+class CLIPSegTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
+ CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 49408):
+ Vocabulary size of the CLIPSeg text model. Defines the number of different tokens that can be represented
+ by the `inputs_ids` passed when calling [`CLIPSegModel`].
+ hidden_size (`int`, *optional*, defaults to 512):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 2048):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ max_position_embeddings (`int`, *optional*, defaults to 77):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float``, *optional*, defaults to 1):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegTextConfig, CLIPSegTextModel
+
+ >>> # Initializing a CLIPSegTextConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegTextConfig()
+
+ >>> # Initializing a CLIPSegTextModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "clipseg_text_model"
+
+ def __init__(
+ self,
+ vocab_size=49408,
+ hidden_size=512,
+ intermediate_size=2048,
+ num_hidden_layers=12,
+ num_attention_heads=8,
+ max_position_embeddings=77,
+ hidden_act="quick_gelu",
+ layer_norm_eps=0.00001,
+ dropout=0.0,
+ attention_dropout=0.0,
+ initializer_range=0.02,
+ initializer_factor=1.0,
+ pad_token_id=1,
+ bos_token_id=0,
+ eos_token_id=2,
+ **kwargs
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.max_position_embeddings = max_position_embeddings
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.attention_dropout = attention_dropout
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the text config dict if we are loading from CLIPSegConfig
+ if config_dict.get("model_type") == "clipseg":
+ config_dict = config_dict["text_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class CLIPSegVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to instantiate an
+ CLIPSeg model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 32):
+ The size (resolution) of each patch.
+ hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float``, *optional*, defaults to 1):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegVisionConfig, CLIPSegVisionModel
+
+ >>> # Initializing a CLIPSegVisionConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegVisionConfig()
+
+ >>> # Initializing a CLIPSegVisionModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "clipseg_vision_model"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ num_channels=3,
+ image_size=224,
+ patch_size=32,
+ hidden_act="quick_gelu",
+ layer_norm_eps=0.00001,
+ dropout=0.0,
+ attention_dropout=0.0,
+ initializer_range=0.02,
+ initializer_factor=1.0,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.image_size = image_size
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.attention_dropout = attention_dropout
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the vision config dict if we are loading from CLIPSegConfig
+ if config_dict.get("model_type") == "clipseg":
+ config_dict = config_dict["vision_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class CLIPSegConfig(PretrainedConfig):
+ r"""
+ [`CLIPSegConfig`] is the configuration class to store the configuration of a [`CLIPSegModel`]. It is used to
+ instantiate a CLIPSeg model according to the specified arguments, defining the text model and vision model configs.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the CLIPSeg
+ [CIDAS/clipseg-rd64](https://huggingface.co/CIDAS/clipseg-rd64) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`CLIPSegTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`CLIPSegVisionConfig`].
+ projection_dim (`int`, *optional*, defaults to 512):
+ Dimensionality of text and vision projection layers.
+ logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
+ The inital value of the *logit_scale* paramter. Default is used as per the original CLIPSeg implementation.
+ extract_layers (`List[int]`, *optional*, defaults to [3, 6, 9]):
+ Layers to extract when forwarding the query image through the frozen visual backbone of CLIP.
+ reduce_dim (`int`, *optional*, defaults to 64):
+ Dimensionality to reduce the CLIP vision embedding.
+ decoder_num_attention_heads (`int`, *optional*, defaults to 4):
+ Number of attention heads in the decoder of CLIPSeg.
+ decoder_attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ decoder_hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported. layer_norm_eps (`float`, *optional*,
+ defaults to 1e-5): The epsilon used by the layer normalization layers.
+ decoder_intermediate_size (`int`, *optional*, defaults to 2048):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layers in the Transformer decoder.
+ conditional_layer (`int`, *optional*, defaults to 0):
+ The layer to use of the Transformer encoder whose activations will be combined with the condition
+ embeddings using FiLM (Feature-wise Linear Modulation). If 0, the last layer is used.
+ use_complex_transposed_convolution (`bool`, *optional*, defaults to `False`):
+ Whether to use a more complex transposed convolution in the decoder, enabling more fine-grained
+ segmentation.
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import CLIPSegConfig, CLIPSegModel
+
+ >>> # Initializing a CLIPSegConfig with CIDAS/clipseg-rd64 style configuration
+ >>> configuration = CLIPSegConfig()
+
+ >>> # Initializing a CLIPSegModel (with random weights) from the CIDAS/clipseg-rd64 style configuration
+ >>> model = CLIPSegModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a CLIPSegConfig from a CLIPSegTextConfig and a CLIPSegVisionConfig
+
+ >>> # Initializing a CLIPSegText and CLIPSegVision configuration
+ >>> config_text = CLIPSegTextConfig()
+ >>> config_vision = CLIPSegVisionConfig()
+
+ >>> config = CLIPSegConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "clipseg"
+ is_composition = True
+
+ def __init__(
+ self,
+ text_config=None,
+ vision_config=None,
+ projection_dim=512,
+ logit_scale_init_value=2.6592,
+ extract_layers=[3, 6, 9],
+ reduce_dim=64,
+ decoder_num_attention_heads=4,
+ decoder_attention_dropout=0.0,
+ decoder_hidden_act="quick_gelu",
+ decoder_intermediate_size=2048,
+ conditional_layer=0,
+ use_complex_transposed_convolution=False,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ text_config_dict = kwargs.pop("text_config_dict", None)
+ vision_config_dict = kwargs.pop("vision_config_dict", None)
+ if text_config_dict is not None:
+ text_config = text_config_dict
+ if vision_config_dict is not None:
+ vision_config = vision_config_dict
+
+ if text_config is None:
+ text_config = {}
+ logger.info("text_config is None. Initializing the CLIPSegTextConfig with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("vision_config is None. initializing the CLIPSegVisionConfig with default values.")
+
+ self.text_config = CLIPSegTextConfig(**text_config)
+ self.vision_config = CLIPSegVisionConfig(**vision_config)
+
+ self.projection_dim = projection_dim
+ self.logit_scale_init_value = logit_scale_init_value
+ self.extract_layers = extract_layers
+ self.reduce_dim = reduce_dim
+ self.decoder_num_attention_heads = decoder_num_attention_heads
+ self.decoder_attention_dropout = decoder_attention_dropout
+ self.decoder_hidden_act = decoder_hidden_act
+ self.decoder_intermediate_size = decoder_intermediate_size
+ self.conditional_layer = conditional_layer
+ self.initializer_factor = 1.0
+ self.use_complex_transposed_convolution = use_complex_transposed_convolution
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: CLIPSegTextConfig, vision_config: CLIPSegVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`CLIPSegConfig`] (or a derived class) from clipseg text model configuration and clipseg vision
+ model configuration.
+
+ Returns:
+ [`CLIPSegConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
+
+ def to_dict(self):
+ """
+ Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
+
+ Returns:
+ `Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ output = copy.deepcopy(self.__dict__)
+ output["text_config"] = self.text_config.to_dict()
+ output["vision_config"] = self.vision_config.to_dict()
+ output["model_type"] = self.__class__.model_type
+ return output
diff --git a/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py b/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
new file mode 100644
index 0000000000000..778dbca299678
--- /dev/null
+++ b/src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
@@ -0,0 +1,264 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Convert CLIPSeg checkpoints from the original repository. URL: https://github.com/timojl/clipseg."""
+
+import argparse
+
+import torch
+from PIL import Image
+
+import requests
+from transformers import (
+ CLIPSegConfig,
+ CLIPSegForImageSegmentation,
+ CLIPSegProcessor,
+ CLIPSegTextConfig,
+ CLIPSegVisionConfig,
+ CLIPTokenizer,
+ ViTFeatureExtractor,
+)
+
+
+def get_clipseg_config(model_name):
+ text_config = CLIPSegTextConfig()
+ vision_config = CLIPSegVisionConfig(patch_size=16)
+
+ use_complex_transposed_convolution = True if "refined" in model_name else False
+ reduce_dim = 16 if "rd16" in model_name else 64
+
+ config = CLIPSegConfig.from_text_vision_configs(
+ text_config,
+ vision_config,
+ use_complex_transposed_convolution=use_complex_transposed_convolution,
+ reduce_dim=reduce_dim,
+ )
+ return config
+
+
+def rename_key(name):
+ # update prefixes
+ if "clip_model" in name:
+ name = name.replace("clip_model", "clip")
+ if "transformer" in name:
+ if "visual" in name:
+ name = name.replace("visual.transformer", "vision_model")
+ else:
+ name = name.replace("transformer", "text_model")
+ if "resblocks" in name:
+ name = name.replace("resblocks", "encoder.layers")
+ if "ln_1" in name:
+ name = name.replace("ln_1", "layer_norm1")
+ if "ln_2" in name:
+ name = name.replace("ln_2", "layer_norm2")
+ if "c_fc" in name:
+ name = name.replace("c_fc", "fc1")
+ if "c_proj" in name:
+ name = name.replace("c_proj", "fc2")
+ if "attn" in name and "self" not in name:
+ name = name.replace("attn", "self_attn")
+ # text encoder
+ if "token_embedding" in name:
+ name = name.replace("token_embedding", "text_model.embeddings.token_embedding")
+ if "positional_embedding" in name and "visual" not in name:
+ name = name.replace("positional_embedding", "text_model.embeddings.position_embedding.weight")
+ if "ln_final" in name:
+ name = name.replace("ln_final", "text_model.final_layer_norm")
+ # vision encoder
+ if "visual.class_embedding" in name:
+ name = name.replace("visual.class_embedding", "vision_model.embeddings.class_embedding")
+ if "visual.conv1" in name:
+ name = name.replace("visual.conv1", "vision_model.embeddings.patch_embedding")
+ if "visual.positional_embedding" in name:
+ name = name.replace("visual.positional_embedding", "vision_model.embeddings.position_embedding.weight")
+ if "visual.ln_pre" in name:
+ name = name.replace("visual.ln_pre", "vision_model.pre_layrnorm")
+ if "visual.ln_post" in name:
+ name = name.replace("visual.ln_post", "vision_model.post_layernorm")
+ # projection layers
+ if "visual.proj" in name:
+ name = name.replace("visual.proj", "visual_projection.weight")
+ if "text_projection" in name:
+ name = name.replace("text_projection", "text_projection.weight")
+ # decoder
+ if "trans_conv" in name:
+ name = name.replace("trans_conv", "transposed_convolution")
+ if "film_mul" in name or "film_add" in name or "reduce" in name or "transposed_convolution" in name:
+ name = "decoder." + name
+ if "blocks" in name:
+ name = name.replace("blocks", "decoder.layers")
+ if "linear1" in name:
+ name = name.replace("linear1", "mlp.fc1")
+ if "linear2" in name:
+ name = name.replace("linear2", "mlp.fc2")
+ if "norm1" in name and "layer_" not in name:
+ name = name.replace("norm1", "layer_norm1")
+ if "norm2" in name and "layer_" not in name:
+ name = name.replace("norm2", "layer_norm2")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if key.startswith("clip_model") and "attn.in_proj" in key:
+ key_split = key.split(".")
+ if "visual" in key:
+ layer_num = int(key_split[4])
+ dim = config.vision_config.hidden_size
+ prefix = "vision_model"
+ else:
+ layer_num = int(key_split[3])
+ dim = config.text_config.hidden_size
+ prefix = "text_model"
+
+ if "weight" in key:
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.q_proj.weight"] = val[:dim, :]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.k_proj.weight"] = val[
+ dim : dim * 2, :
+ ]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.v_proj.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.q_proj.bias"] = val[:dim]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.k_proj.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"clip.{prefix}.encoder.layers.{layer_num}.self_attn.v_proj.bias"] = val[-dim:]
+ elif "self_attn" in key and "out_proj" not in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[1])
+ dim = config.reduce_dim
+ if "weight" in key:
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.q_proj.weight"] = val[:dim, :]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.k_proj.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.v_proj.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.q_proj.bias"] = val[:dim]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.k_proj.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"decoder.layers.{layer_num}.self_attn.v_proj.bias"] = val[-dim:]
+ else:
+ new_name = rename_key(key)
+ if "visual_projection" in new_name or "text_projection" in new_name:
+ val = val.T
+ orig_state_dict[new_name] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+def convert_clipseg_checkpoint(model_name, checkpoint_path, pytorch_dump_folder_path, push_to_hub):
+ config = get_clipseg_config(model_name)
+ model = CLIPSegForImageSegmentation(config)
+ model.eval()
+
+ state_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ # remove some keys
+ for key in state_dict.copy().keys():
+ if key.startswith("model"):
+ state_dict.pop(key, None)
+
+ # rename some keys
+ state_dict = convert_state_dict(state_dict, config)
+ missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
+
+ if missing_keys != ["clip.text_model.embeddings.position_ids", "clip.vision_model.embeddings.position_ids"]:
+ raise ValueError("Missing keys that are not expected: {}".format(missing_keys))
+ if unexpected_keys != ["decoder.reduce.weight", "decoder.reduce.bias"]:
+ raise ValueError(f"Unexpected keys: {unexpected_keys}")
+
+ feature_extractor = ViTFeatureExtractor(size=352)
+ tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
+ processor = CLIPSegProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ image = prepare_img()
+ text = ["a glass", "something to fill", "wood", "a jar"]
+
+ inputs = processor(text=text, images=[image] * len(text), padding="max_length", return_tensors="pt")
+
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify values
+ expected_conditional = torch.tensor([0.1110, -0.1882, 0.1645])
+ expected_pooled_output = torch.tensor([0.2692, -0.7197, -0.1328])
+ if model_name == "clipseg-rd64-refined":
+ expected_masks_slice = torch.tensor(
+ [[-10.0407, -9.9431, -10.2646], [-9.9751, -9.7064, -9.9586], [-9.6891, -9.5645, -9.9618]]
+ )
+ elif model_name == "clipseg-rd64":
+ expected_masks_slice = torch.tensor(
+ [[-7.2877, -7.2711, -7.2463], [-7.2652, -7.2780, -7.2520], [-7.2239, -7.2204, -7.2001]]
+ )
+ elif model_name == "clipseg-rd16":
+ expected_masks_slice = torch.tensor(
+ [[-6.3955, -6.4055, -6.4151], [-6.3911, -6.4033, -6.4100], [-6.3474, -6.3702, -6.3762]]
+ )
+ else:
+ raise ValueError(f"Model name {model_name} not supported.")
+
+ assert torch.allclose(outputs.logits[0, :3, :3], expected_masks_slice, atol=1e-3)
+ assert torch.allclose(outputs.conditional_embeddings[0, :3], expected_conditional, atol=1e-3)
+ assert torch.allclose(outputs.pooled_output[0, :3], expected_pooled_output, atol=1e-3)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and processor to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print(f"Pushing model and processor for {model_name} to the hub")
+ model.push_to_hub(f"CIDAS/{model_name}")
+ processor.push_to_hub(f"CIDAS/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="clipseg-rd64",
+ type=str,
+ choices=["clipseg-rd16", "clipseg-rd64", "clipseg-rd64-refined"],
+ help=(
+ "Name of the model. Supported models are: clipseg-rd64, clipseg-rd16 and clipseg-rd64-refined (rd meaning"
+ " reduce dimension)"
+ ),
+ )
+ parser.add_argument(
+ "--checkpoint_path",
+ default="/Users/nielsrogge/Documents/CLIPSeg/clip_plus_rd64-uni.pth",
+ type=str,
+ help=(
+ "Path to the original checkpoint. Note that the script assumes that the checkpoint includes both CLIP and"
+ " the decoder weights."
+ ),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_clipseg_checkpoint(args.model_name, args.checkpoint_path, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/clipseg/modeling_clipseg.py b/src/transformers/models/clipseg/modeling_clipseg.py
new file mode 100644
index 0000000000000..87caf24ed4bf6
--- /dev/null
+++ b/src/transformers/models/clipseg/modeling_clipseg.py
@@ -0,0 +1,1493 @@
+# coding=utf-8
+# Copyright 2022 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch CLIPSeg model."""
+
+import copy
+import math
+from dataclasses import dataclass
+from typing import Any, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_clipseg import CLIPSegConfig, CLIPSegTextConfig, CLIPSegVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+_CHECKPOINT_FOR_DOC = "CIDAS/clipseg-rd64-refined"
+
+CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "CIDAS/clipseg-rd64-refined",
+ # See all CLIPSeg models at https://huggingface.co/models?filter=clipseg
+]
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# contrastive loss function, adapted from
+# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIPSeg.html
+def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
+ return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
+
+
+# Copied from transformers.models.clip.modeling_clip.clip_loss with clip->clipseg
+def clipseg_loss(similarity: torch.Tensor) -> torch.Tensor:
+ caption_loss = contrastive_loss(similarity)
+ image_loss = contrastive_loss(similarity.t())
+ return (caption_loss + image_loss) / 2.0
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->CLIPSeg
+class CLIPSegOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`CLIPSegTextModel`].
+ image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The image embeddings obtained by applying the projection layer to the pooled output of
+ [`CLIPSegVisionModel`].
+ text_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegTextModel`].
+ vision_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: torch.FloatTensor = None
+ logits_per_text: torch.FloatTensor = None
+ text_embeds: torch.FloatTensor = None
+ image_embeds: torch.FloatTensor = None
+ text_model_output: BaseModelOutputWithPooling = None
+ vision_model_output: BaseModelOutputWithPooling = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+@dataclass
+class CLIPSegDecoderOutput(ModelOutput):
+ """
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Classification scores for each pixel.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class CLIPSegImageSegmentationOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ ...
+ vision_model_output (`BaseModelOutputWithPooling`):
+ The output of the [`CLIPSegVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ conditional_embeddings: torch.FloatTensor = None
+ pooled_output: torch.FloatTensor = None
+ vision_model_output: BaseModelOutputWithPooling = None
+ decoder_output: CLIPSegDecoderOutput = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["vision_model_output", "decoder_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+class CLIPSegVisionEmbeddings(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings.__init__
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size, bias=False
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches + 1
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)))
+
+ def interpolate_position_embeddings(self, new_size):
+ if len(new_size) != 2:
+ raise ValueError("new_size should consist of 2 values")
+
+ num_patches_one_direction = int(self.num_patches**0.5)
+ # we interpolate the position embeddings in 2D
+ a = self.position_embedding.weight[1:].T.view(
+ 1, self.config.hidden_size, num_patches_one_direction, num_patches_one_direction
+ )
+ b = (
+ nn.functional.interpolate(a, new_size, mode="bicubic", align_corners=False)
+ .squeeze(0)
+ .view(self.config.hidden_size, new_size[0] * new_size[1])
+ .T
+ )
+ result = torch.cat([self.position_embedding.weight[:1], b])
+
+ return result
+
+ def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
+ batch_size = pixel_values.shape[0]
+ patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
+ patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
+
+ class_embeds = self.class_embedding.expand(batch_size, 1, -1)
+ embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
+
+ if embeddings.shape[1] != self.num_positions:
+ new_shape = int(math.sqrt(embeddings.shape[1] - 1))
+ embeddings = embeddings + self.interpolate_position_embeddings((new_shape, new_shape))
+ embeddings = embeddings.to(embeddings.dtype)
+ else:
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->CLIPSeg
+class CLIPSegTextEmbeddings(nn.Module):
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__()
+ embed_dim = config.hidden_size
+
+ self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
+ self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ ) -> torch.Tensor:
+ seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, :seq_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.token_embedding(input_ids)
+
+ position_embeddings = self.position_embedding(position_ids)
+ embeddings = inputs_embeds + position_embeddings
+
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPAttention with CLIP->CLIPSeg
+class CLIPSegAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scale
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ # apply the causal_attention_mask first
+ if causal_attention_mask is not None:
+ if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
+ f" {causal_attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if output_attentions:
+ # this operation is a bit akward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->CLIPSeg
+class CLIPSegMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->CLIPSeg
+class CLIPSegEncoderLayer(nn.Module):
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = CLIPSegAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim)
+ self.mlp = CLIPSegMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPPreTrainedModel with CLIP->CLIPSeg
+class CLIPSegPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = CLIPSegConfig
+ base_model_prefix = "clip"
+ supports_gradient_checkpointing = True
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ factor = self.config.initializer_factor
+ if isinstance(module, CLIPSegTextEmbeddings):
+ module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
+ module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
+ elif isinstance(module, CLIPSegVisionEmbeddings):
+ factor = self.config.initializer_factor
+ nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
+ nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
+ nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
+ elif isinstance(module, CLIPSegAttention):
+ factor = self.config.initializer_factor
+ in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ out_proj_std = (module.embed_dim**-0.5) * factor
+ nn.init.normal_(module.q_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.k_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.v_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.out_proj.weight, std=out_proj_std)
+ elif isinstance(module, CLIPSegMLP):
+ factor = self.config.initializer_factor
+ in_proj_std = (
+ (module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ )
+ fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
+ nn.init.normal_(module.fc1.weight, std=fc_std)
+ nn.init.normal_(module.fc2.weight, std=in_proj_std)
+ elif isinstance(module, CLIPSegModel):
+ nn.init.normal_(
+ module.text_projection.weight,
+ std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+ nn.init.normal_(
+ module.visual_projection.weight,
+ std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+
+ if isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, CLIPSegEncoder):
+ module.gradient_checkpointing = value
+
+
+CLIPSEG_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`CLIPSegConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+CLIPSEG_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+CLIPSEG_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+CLIPSEG_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->CLIPSeg
+class CLIPSegEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`CLIPSegEncoderLayer`].
+
+ Args:
+ config: CLIPSegConfig
+ """
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([CLIPSegEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Causal mask for the text model. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(encoder_layer),
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class CLIPSegTextTransformer(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+ self.embeddings = CLIPSegTextEmbeddings(config)
+ self.encoder = CLIPSegEncoder(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim)
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
+ # Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.forward with clip->clipseg, CLIP->CLIPSeg
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is None:
+ raise ValueError("You have to specify either input_ids")
+
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+
+ hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
+
+ bsz, seq_len = input_shape
+ # CLIPSeg's text model uses causal mask, prepare it here.
+ # https://github.com/openai/CLIPSeg/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clipseg/model.py#L324
+ causal_attention_mask = self._build_causal_attention_mask(bsz, seq_len, hidden_states.dtype).to(
+ hidden_states.device
+ )
+ # expand attention_mask
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _expand_mask(attention_mask, hidden_states.dtype)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.final_layer_norm(last_hidden_state)
+
+ # text_embeds.shape = [batch_size, sequence_length, transformer.width]
+ # take features from the eot embedding (eot_token is the highest number in each sequence)
+ # casting to torch.int for onnx compatibility: argmax doesn't support int64 inputs with opset 14
+ pooled_output = last_hidden_state[
+ torch.arange(last_hidden_state.shape[0], device=input_ids.device), input_ids.to(torch.int).argmax(dim=-1)
+ ]
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+ def _build_causal_attention_mask(self, bsz, seq_len, dtype):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # pytorch uses additive attention mask; fill with -inf
+ mask = torch.empty(bsz, seq_len, seq_len, dtype=dtype)
+ mask.fill_(torch.tensor(torch.finfo(dtype).min))
+ mask.triu_(1) # zero out the lower diagonal
+ mask = mask.unsqueeze(1) # expand mask
+ return mask
+
+
+class CLIPSegTextModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegTextConfig
+
+ _no_split_modules = ["CLIPSegEncoderLayer"]
+
+ def __init__(self, config: CLIPSegTextConfig):
+ super().__init__(config)
+ self.text_model = CLIPSegTextTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.text_model.embeddings.token_embedding
+
+ def set_input_embeddings(self, value):
+ self.text_model.embeddings.token_embedding = value
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPTokenizer, CLIPSegTextModel
+
+ >>> tokenizer = CLIPTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegTextModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled (EOS token) states
+ ```"""
+ return self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+class CLIPSegVisionTransformer(nn.Module):
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = CLIPSegVisionEmbeddings(config)
+ self.pre_layrnorm = nn.LayerNorm(embed_dim)
+ self.encoder = CLIPSegEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim)
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
+ # Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.forward
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ hidden_states = self.embeddings(pixel_values)
+ hidden_states = self.pre_layrnorm(hidden_states)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ pooled_output = last_hidden_state[:, 0, :]
+ pooled_output = self.post_layernorm(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class CLIPSegVisionModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegVisionConfig
+ main_input_name = "pixel_values"
+
+ def __init__(self, config: CLIPSegVisionConfig):
+ super().__init__(config)
+ self.vision_model = CLIPSegVisionTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegVisionModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegVisionModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+@add_start_docstrings(CLIPSEG_START_DOCSTRING)
+class CLIPSegModel(CLIPSegPreTrainedModel):
+ config_class = CLIPSegConfig
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ if not isinstance(config.text_config, CLIPSegTextConfig):
+ raise ValueError(
+ "config.text_config is expected to be of type CLIPSegTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ if not isinstance(config.vision_config, CLIPSegVisionConfig):
+ raise ValueError(
+ "config.vision_config is expected to be of type CLIPSegVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.projection_dim = config.projection_dim
+ self.text_embed_dim = text_config.hidden_size
+ self.vision_embed_dim = vision_config.hidden_size
+
+ self.text_model = CLIPSegTextTransformer(text_config)
+ self.vision_model = CLIPSegVisionTransformer(vision_config)
+
+ self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=False)
+ self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False)
+ self.logit_scale = nn.Parameter(torch.ones([]) * self.config.logit_scale_init_value)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`CLIPSegTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPTokenizer, CLIPSegModel
+
+ >>> tokenizer = CLIPTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+ >>> text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = text_outputs[1]
+ text_features = self.text_projection(pooled_output)
+
+ return text_features
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`CLIPSegVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = vision_outputs[1] # pooled_output
+ image_features = self.visual_projection(pooled_output)
+
+ return image_features
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CLIPSegOutput, config_class=CLIPSegConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CLIPSegOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import CLIPSegProcessor, CLIPSegModel
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(
+ ... text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True
+ ... )
+
+ >>> outputs = model(**inputs)
+ >>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+ >>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+ ```"""
+ # Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ image_embeds = self.visual_projection(image_embeds)
+
+ text_embeds = text_outputs[1]
+ text_embeds = self.text_projection(text_embeds)
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
+ logits_per_image = logits_per_text.t()
+
+ loss = None
+ if return_loss:
+ loss = clipseg_loss(logits_per_text)
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return CLIPSegOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
+
+
+class CLIPSegDecoderLayer(nn.Module):
+ """
+ CLIPSeg decoder layer, which is identical to `CLIPSegEncoderLayer`, except that normalization is applied after
+ self-attention/MLP, rather than before.
+ """
+
+ # Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer.__init__ with CLIP->CLIPSeg
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = CLIPSegAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim)
+ self.mlp = CLIPSegMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = residual + hidden_states
+ hidden_states = self.layer_norm1(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class CLIPSegDecoder(CLIPSegPreTrainedModel):
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ self.conditional_layer = config.conditional_layer
+
+ self.film_mul = nn.Linear(config.projection_dim, config.reduce_dim)
+ self.film_add = nn.Linear(config.projection_dim, config.reduce_dim)
+
+ if config.use_complex_transposed_convolution:
+ transposed_kernels = (config.vision_config.patch_size // 4, config.vision_config.patch_size // 4)
+
+ self.transposed_convolution = nn.Sequential(
+ nn.Conv2d(config.reduce_dim, config.reduce_dim, kernel_size=3, padding=1),
+ nn.ReLU(),
+ nn.ConvTranspose2d(
+ config.reduce_dim,
+ config.reduce_dim // 2,
+ kernel_size=transposed_kernels[0],
+ stride=transposed_kernels[0],
+ ),
+ nn.ReLU(),
+ nn.ConvTranspose2d(
+ config.reduce_dim // 2, 1, kernel_size=transposed_kernels[1], stride=transposed_kernels[1]
+ ),
+ )
+ else:
+ self.transposed_convolution = nn.ConvTranspose2d(
+ config.reduce_dim, 1, config.vision_config.patch_size, stride=config.vision_config.patch_size
+ )
+
+ depth = len(config.extract_layers)
+ self.reduces = nn.ModuleList(
+ [nn.Linear(config.vision_config.hidden_size, config.reduce_dim) for _ in range(depth)]
+ )
+
+ decoder_config = copy.deepcopy(config.vision_config)
+ decoder_config.hidden_size = config.reduce_dim
+ decoder_config.num_attention_heads = config.decoder_num_attention_heads
+ decoder_config.intermediate_size = config.decoder_intermediate_size
+ decoder_config.hidden_act = "relu"
+ self.layers = nn.ModuleList([CLIPSegDecoderLayer(decoder_config) for _ in range(len(config.extract_layers))])
+
+ def forward(
+ self,
+ hidden_states: Tuple[torch.Tensor],
+ conditional_embeddings: torch.Tensor,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = True,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ activations = hidden_states[::-1]
+
+ output = None
+ for i, (activation, layer, reduce) in enumerate(zip(activations, self.layers, self.reduces)):
+ if output is not None:
+ output = reduce(activation) + output
+ else:
+ output = reduce(activation)
+
+ if i == self.conditional_layer:
+ output = self.film_mul(conditional_embeddings) * output.permute(1, 0, 2) + self.film_add(
+ conditional_embeddings
+ )
+ output = output.permute(1, 0, 2)
+
+ layer_outputs = layer(
+ output, attention_mask=None, causal_attention_mask=None, output_attentions=output_attentions
+ )
+
+ output = layer_outputs[0]
+
+ if output_hidden_states:
+ all_hidden_states += (output,)
+
+ if output_attentions:
+ all_attentions += (layer_outputs[1],)
+
+ output = output[:, 1:, :].permute(0, 2, 1) # remove cls token and reshape to [batch_size, reduce_dim, seq_len]
+
+ size = int(math.sqrt(output.shape[2]))
+
+ batch_size = conditional_embeddings.shape[0]
+ output = output.view(batch_size, output.shape[1], size, size)
+
+ logits = self.transposed_convolution(output).squeeze()
+
+ if not return_dict:
+ return tuple(v for v in [logits, all_hidden_states, all_attentions] if v is not None)
+
+ return CLIPSegDecoderOutput(
+ logits=logits,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ CLIPSeg model with a Transformer-based decoder on top for zero-shot and one-shot image segmentation.
+ """,
+ CLIPSEG_START_DOCSTRING,
+)
+class CLIPSegForImageSegmentation(CLIPSegPreTrainedModel):
+ config_class = CLIPSegConfig
+
+ def __init__(self, config: CLIPSegConfig):
+ super().__init__(config)
+
+ self.config = config
+
+ self.clip = CLIPSegModel(config)
+ self.extract_layers = config.extract_layers
+
+ self.decoder = CLIPSegDecoder(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_conditional_embeddings(
+ self,
+ batch_size: int = None,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ conditional_pixel_values: Optional[torch.Tensor] = None,
+ ):
+ if input_ids is not None:
+ # compute conditional embeddings from texts
+ if len(input_ids) != batch_size:
+ raise ValueError("Make sure to pass as many prompt texts as there are query images")
+ with torch.no_grad():
+ conditional_embeddings = self.clip.get_text_features(
+ input_ids, attention_mask=attention_mask, position_ids=position_ids
+ )
+ elif conditional_pixel_values is not None:
+ # compute conditional embeddings from images
+ if len(conditional_pixel_values) != batch_size:
+ raise ValueError("Make sure to pass as many prompt images as there are query images")
+ with torch.no_grad():
+ conditional_embeddings = self.clip.get_image_features(conditional_pixel_values)
+ else:
+ raise ValueError(
+ "Invalid conditional, should be either provided as `input_ids` or `conditional_pixel_values`"
+ )
+
+ return conditional_embeddings
+
+ @add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CLIPSegImageSegmentationOutput, config_class=CLIPSegTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.FloatTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ conditional_pixel_values: Optional[torch.FloatTensor] = None,
+ conditional_embeddings: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CLIPSegOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
+ >>> model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> texts = ["a cat", "a remote", "a blanket"]
+ >>> inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+
+ >>> logits = outputs.logits
+ >>> print(logits.shape)
+ torch.Size([3, 352, 352])
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # step 1: forward the query images through the frozen CLIP vision encoder
+ with torch.no_grad():
+ vision_outputs = self.clip.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=True, # we need the intermediate hidden states
+ return_dict=return_dict,
+ )
+ pooled_output = self.clip.visual_projection(vision_outputs[1])
+
+ hidden_states = vision_outputs.hidden_states if return_dict else vision_outputs[2]
+ # we add +1 here as the hidden states also include the initial embeddings
+ activations = [hidden_states[i + 1] for i in self.extract_layers]
+
+ # update vision_outputs
+ if return_dict:
+ vision_outputs = BaseModelOutputWithPooling(
+ last_hidden_state=vision_outputs.last_hidden_state,
+ pooler_output=vision_outputs.pooler_output,
+ hidden_states=vision_outputs.hidden_states if output_hidden_states else None,
+ attentions=vision_outputs.attentions,
+ )
+ else:
+ vision_outputs = (
+ vision_outputs[:2] + vision_outputs[3:] if not output_hidden_states else vision_outputs
+ )
+
+ # step 2: compute conditional embeddings, either from text, images or an own provided embedding
+ if conditional_embeddings is None:
+ conditional_embeddings = self.get_conditional_embeddings(
+ batch_size=pixel_values.shape[0],
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ conditional_pixel_values=conditional_pixel_values,
+ )
+ else:
+ if conditional_embeddings.shape[0] != pixel_values.shape[0]:
+ raise ValueError(
+ "Make sure to pass as many conditional embeddings as there are query images in the batch"
+ )
+ if conditional_embeddings.shape[1] != self.config.projection_dim:
+ raise ValueError(
+ "Make sure that the feature dimension of the conditional embeddings matches"
+ " `config.projection_dim`."
+ )
+
+ # step 3: forward both the pooled output and the activations through the lightweight decoder to predict masks
+ decoder_outputs = self.decoder(
+ activations,
+ conditional_embeddings,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ logits = decoder_outputs.logits if return_dict else decoder_outputs[0]
+
+ loss = None
+ if labels is not None:
+ loss_fn = nn.BCEWithLogitsLoss()
+ loss = loss_fn(logits, labels)
+
+ if not return_dict:
+ output = (logits, conditional_embeddings, pooled_output, vision_outputs, decoder_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return CLIPSegImageSegmentationOutput(
+ loss=loss,
+ logits=logits,
+ conditional_embeddings=conditional_embeddings,
+ pooled_output=pooled_output,
+ vision_model_output=vision_outputs,
+ decoder_output=decoder_outputs,
+ )
diff --git a/src/transformers/models/clipseg/processing_clipseg.py b/src/transformers/models/clipseg/processing_clipseg.py
new file mode 100644
index 0000000000000..4a18e4ba7a902
--- /dev/null
+++ b/src/transformers/models/clipseg/processing_clipseg.py
@@ -0,0 +1,108 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for CLIPSeg
+"""
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding
+
+
+class CLIPSegProcessor(ProcessorMixin):
+ r"""
+ Constructs a CLIPSeg processor which wraps a CLIPSeg feature extractor and a CLIP tokenizer into a single
+ processor.
+
+ [`CLIPSegProcessor`] offers all the functionalities of [`ViTFeatureExtractor`] and [`CLIPTokenizerFast`]. See the
+ [`~CLIPSegProcessor.__call__`] and [`~CLIPSegProcessor.decode`] for more information.
+
+ Args:
+ feature_extractor ([`ViTFeatureExtractor`]):
+ The feature extractor is a required input.
+ tokenizer ([`CLIPTokenizerFast`]):
+ The tokenizer is a required input.
+ """
+ feature_extractor_class = "ViTFeatureExtractor"
+ tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
+
+ def __init__(self, feature_extractor, tokenizer):
+ super().__init__(feature_extractor, tokenizer)
+ self.current_processor = self.feature_extractor
+
+ def __call__(self, text=None, images=None, return_tensors=None, **kwargs):
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to CLIPTokenizerFast's [`~CLIPTokenizerFast.__call__`] if `text` is not `None` to encode
+ the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
+ ViTFeatureExtractor's [`~ViTFeatureExtractor.__call__`] if `images` is not `None`. Please refer to the
+ doctsring of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+
+ if text is None and images is None:
+ raise ValueError("You have to specify either text or images. Both cannot be none.")
+
+ if text is not None:
+ encoding = self.tokenizer(text, return_tensors=return_tensors, **kwargs)
+
+ if images is not None:
+ image_features = self.feature_extractor(images, return_tensors=return_tensors, **kwargs)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to CLIPTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to CLIPTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/transformers/processing_utils.py b/src/transformers/processing_utils.py
index 569e9975b16c9..5cc41c447b7bd 100644
--- a/src/transformers/processing_utils.py
+++ b/src/transformers/processing_utils.py
@@ -56,7 +56,7 @@ def __init__(self, *args, **kwargs):
# Sanitize args and kwargs
for key in kwargs:
if key not in self.attributes:
- raise TypeError(f"Unexepcted keyword argument {key}.")
+ raise TypeError(f"Unexpected keyword argument {key}.")
for arg, attribute_name in zip(args, self.attributes):
if attribute_name in kwargs:
raise TypeError(f"Got multiple values for argument {attribute_name}.")
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index cb2f93be0fc90..755f1af0a665c 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -1207,6 +1207,44 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class CLIPSegForImageSegmentation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegTextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class CLIPSegVisionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/tests/models/clipseg/__init__.py b/tests/models/clipseg/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/tests/models/clipseg/test_modeling_clipseg.py b/tests/models/clipseg/test_modeling_clipseg.py
new file mode 100644
index 0000000000000..3a338ddbf820a
--- /dev/null
+++ b/tests/models/clipseg/test_modeling_clipseg.py
@@ -0,0 +1,735 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch CLIPSeg model. """
+
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+
+import requests
+import transformers
+from transformers import MODEL_MAPPING, CLIPSegConfig, CLIPSegProcessor, CLIPSegTextConfig, CLIPSegVisionConfig
+from transformers.models.auto import get_values
+from transformers.testing_utils import (
+ is_flax_available,
+ is_pt_flax_cross_test,
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import CLIPSegForImageSegmentation, CLIPSegModel, CLIPSegTextModel, CLIPSegVisionModel
+ from transformers.models.clipseg.modeling_clipseg import CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+if is_flax_available():
+ import jax.numpy as jnp
+ from transformers.modeling_flax_pytorch_utils import (
+ convert_pytorch_state_dict_to_flax,
+ load_flax_weights_in_pytorch_model,
+ )
+
+
+class CLIPSegVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return CLIPSegVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = CLIPSegVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as CLIPSeg does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (CLIPSegVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = CLIPSegVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=CLIPSegVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="CLIPSeg does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_training(self):
+ pass
+
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class CLIPSegTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return CLIPSegTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = CLIPSegTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegTextModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (CLIPSegTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = CLIPSegTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=CLIPSegTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_training(self):
+ pass
+
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="CLIPSeg does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegTextModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegTextModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class CLIPSegModelTester:
+ def __init__(self, parent, is_training=True):
+ self.parent = parent
+ self.text_model_tester = CLIPSegTextModelTester(parent)
+ self.vision_model_tester = CLIPSegVisionModelTester(parent)
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return CLIPSegConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(),
+ self.vision_model_tester.get_config(),
+ projection_dim=64,
+ reduce_dim=32,
+ extract_layers=[1, 2, 3],
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = CLIPSegModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def create_and_check_model_for_image_segmentation(self, config, input_ids, attention_maks, pixel_values):
+ model = CLIPSegForImageSegmentation(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values)
+ self.parent.assertEqual(
+ result.logits.shape,
+ (
+ self.vision_model_tester.batch_size,
+ self.vision_model_tester.image_size,
+ self.vision_model_tester.image_size,
+ ),
+ )
+ self.parent.assertEqual(
+ result.conditional_embeddings.shape, (self.text_model_tester.batch_size, config.projection_dim)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class CLIPSegModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (CLIPSegModel, CLIPSegForImageSegmentation) if is_torch_available() else ()
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ # CLIPSegForImageSegmentation requires special treatment
+ if return_labels:
+ if model_class.__name__ == "CLIPSegForImageSegmentation":
+ batch_size, _, height, width = inputs_dict["pixel_values"].shape
+ inputs_dict["labels"] = torch.zeros(
+ [batch_size, height, width], device=torch_device, dtype=torch.float
+ )
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = CLIPSegModelTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_for_image_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_for_image_segmentation(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="CLIPSegModel does not have input/output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ # override as the some parameters require custom initialization
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initilized as per the original implementation
+ if "logit_scale" in name:
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif "film" in name or "transposed_conv" in name or "reduce" in name:
+ # those parameters use PyTorch' default nn.Linear initialization scheme
+ pass
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ return
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # CLIPSeg needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save CLIPSegConfig and check if we can load CLIPSegVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = CLIPSegVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save CLIPSegConfig and check if we can load CLIPSegTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = CLIPSegTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ # overwrite from common since FlaxCLIPSegModel returns nested output
+ # which is not supported in the common test
+ @is_pt_flax_cross_test
+ def test_equivalence_pt_to_flax(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ with self.subTest(model_class.__name__):
+
+ # load PyTorch class
+ pt_model = model_class(config).eval()
+ # Flax models don't use the `use_cache` option and cache is not returned as a default.
+ # So we disable `use_cache` here for PyTorch model.
+ pt_model.config.use_cache = False
+
+ fx_model_class_name = "Flax" + model_class.__name__
+
+ if not hasattr(transformers, fx_model_class_name):
+ return
+
+ fx_model_class = getattr(transformers, fx_model_class_name)
+
+ # load Flax class
+ fx_model = fx_model_class(config, dtype=jnp.float32)
+ # make sure only flax inputs are forward that actually exist in function args
+ fx_input_keys = inspect.signature(fx_model.__call__).parameters.keys()
+
+ # prepare inputs
+ pt_inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ # remove function args that don't exist in Flax
+ pt_inputs = {k: v for k, v in pt_inputs.items() if k in fx_input_keys}
+
+ fx_state = convert_pytorch_state_dict_to_flax(pt_model.state_dict(), fx_model)
+ fx_model.params = fx_state
+
+ with torch.no_grad():
+ pt_outputs = pt_model(**pt_inputs).to_tuple()
+
+ # convert inputs to Flax
+ fx_inputs = {k: np.array(v) for k, v in pt_inputs.items() if torch.is_tensor(v)}
+ fx_outputs = fx_model(**fx_inputs).to_tuple()
+ self.assertEqual(len(fx_outputs), len(pt_outputs), "Output lengths differ between Flax and PyTorch")
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pt_model.save_pretrained(tmpdirname)
+ fx_model_loaded = fx_model_class.from_pretrained(tmpdirname, from_pt=True)
+
+ fx_outputs_loaded = fx_model_loaded(**fx_inputs).to_tuple()
+ self.assertEqual(
+ len(fx_outputs_loaded), len(pt_outputs), "Output lengths differ between Flax and PyTorch"
+ )
+ for fx_output_loaded, pt_output in zip(fx_outputs_loaded[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output_loaded, pt_output.numpy(), 4e-2)
+
+ # overwrite from common since FlaxCLIPSegModel returns nested output
+ # which is not supported in the common test
+ @is_pt_flax_cross_test
+ def test_equivalence_flax_to_pt(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ with self.subTest(model_class.__name__):
+ # load corresponding PyTorch class
+ pt_model = model_class(config).eval()
+
+ # So we disable `use_cache` here for PyTorch model.
+ pt_model.config.use_cache = False
+
+ fx_model_class_name = "Flax" + model_class.__name__
+
+ if not hasattr(transformers, fx_model_class_name):
+ # no flax model exists for this class
+ return
+
+ fx_model_class = getattr(transformers, fx_model_class_name)
+
+ # load Flax class
+ fx_model = fx_model_class(config, dtype=jnp.float32)
+ # make sure only flax inputs are forward that actually exist in function args
+ fx_input_keys = inspect.signature(fx_model.__call__).parameters.keys()
+
+ pt_model = load_flax_weights_in_pytorch_model(pt_model, fx_model.params)
+
+ # make sure weights are tied in PyTorch
+ pt_model.tie_weights()
+
+ # prepare inputs
+ pt_inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ # remove function args that don't exist in Flax
+ pt_inputs = {k: v for k, v in pt_inputs.items() if k in fx_input_keys}
+
+ with torch.no_grad():
+ pt_outputs = pt_model(**pt_inputs).to_tuple()
+
+ fx_inputs = {k: np.array(v) for k, v in pt_inputs.items() if torch.is_tensor(v)}
+
+ fx_outputs = fx_model(**fx_inputs).to_tuple()
+ self.assertEqual(len(fx_outputs), len(pt_outputs), "Output lengths differ between Flax and PyTorch")
+
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ fx_model.save_pretrained(tmpdirname)
+ pt_model_loaded = model_class.from_pretrained(tmpdirname, from_flax=True)
+
+ with torch.no_grad():
+ pt_outputs_loaded = pt_model_loaded(**pt_inputs).to_tuple()
+
+ self.assertEqual(
+ len(fx_outputs), len(pt_outputs_loaded), "Output lengths differ between Flax and PyTorch"
+ )
+ for fx_output, pt_output in zip(fx_outputs[:4], pt_outputs_loaded[:4]):
+ self.assert_almost_equals(fx_output, pt_output.numpy(), 4e-2)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class in get_values(MODEL_MAPPING):
+ continue
+
+ print("Model class:", model_class)
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ for k, v in inputs.items():
+ print(k, v.shape)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = CLIPSegModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+class CLIPSegModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_image_segmentation(self):
+ model_name = "CIDAS/clipseg-rd64-refined"
+ processor = CLIPSegProcessor.from_pretrained(model_name)
+ model = CLIPSegForImageSegmentation.from_pretrained(model_name).to(torch_device)
+
+ image = prepare_img()
+ texts = ["a cat", "a remote", "a blanket"]
+ inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the predicted masks
+ self.assertEqual(
+ outputs.logits.shape,
+ torch.Size((3, 352, 352)),
+ )
+ expected_masks_slice = torch.tensor(
+ [[-7.4577, -7.4952, -7.4072], [-7.3115, -7.0969, -7.1624], [-6.9472, -6.7641, -6.8911]]
+ )
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_masks_slice, atol=1e-3))
+
+ # verify conditional and pooled output
+ expected_conditional = torch.tensor([0.5601, -0.0314, 0.1980])
+ expected_pooled_output = torch.tensor([0.2692, -0.7197, -0.1328])
+ self.assertTrue(torch.allclose(outputs.conditional_embeddings[0, :3], expected_conditional, atol=1e-3))
+ self.assertTrue(torch.allclose(outputs.pooled_output[0, :3], expected_pooled_output, atol=1e-3))
diff --git a/tests/models/clipseg/test_processor_clipseg.py b/tests/models/clipseg/test_processor_clipseg.py
new file mode 100644
index 0000000000000..6da7345f6a6c9
--- /dev/null
+++ b/tests/models/clipseg/test_processor_clipseg.py
@@ -0,0 +1,188 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+
+from transformers import CLIPTokenizer, CLIPTokenizerFast
+from transformers.models.clip.tokenization_clip import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_vision
+from transformers.utils import FEATURE_EXTRACTOR_NAME, is_vision_available
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import CLIPSegProcessor, ViTFeatureExtractor
+
+
+@require_vision
+class CLIPSegProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.tmpdirname = tempfile.mkdtemp()
+
+ # fmt: off
+ vocab = ["l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "lo", "l", "w", "r", "t", "low", "er", "lowest", "newer", "wider", "", "<|startoftext|>", "<|endoftext|>"]
+ # fmt: on
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "l o", "lo w", "e r", ""]
+ self.special_tokens_map = {"unk_token": ""}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ feature_extractor_map = {
+ "do_resize": True,
+ "size": 20,
+ "do_center_crop": True,
+ "crop_size": 18,
+ "do_normalize": True,
+ "image_mean": [0.48145466, 0.4578275, 0.40821073],
+ "image_std": [0.26862954, 0.26130258, 0.27577711],
+ }
+ self.feature_extractor_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(self.feature_extractor_file, "w", encoding="utf-8") as fp:
+ json.dump(feature_extractor_map, fp)
+
+ def get_tokenizer(self, **kwargs):
+ return CLIPTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs):
+ return CLIPTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return ViTFeatureExtractor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def prepare_image_inputs(self):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True."""
+
+ image_inputs = [np.random.randint(255, size=(3, 30, 400), dtype=np.uint8)]
+
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ return image_inputs
+
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+
+ processor_slow = CLIPSegProcessor(tokenizer=tokenizer_slow, feature_extractor=feature_extractor)
+ processor_slow.save_pretrained(self.tmpdirname)
+ processor_slow = CLIPSegProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = CLIPSegProcessor(tokenizer=tokenizer_fast, feature_extractor=feature_extractor)
+ processor_fast.save_pretrained(self.tmpdirname)
+ processor_fast = CLIPSegProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, CLIPTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, CLIPTokenizerFast)
+
+ self.assertEqual(processor_slow.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertEqual(processor_fast.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor_slow.feature_extractor, ViTFeatureExtractor)
+ self.assertIsInstance(processor_fast.feature_extractor, ViTFeatureExtractor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = CLIPSegProcessor(tokenizer=self.get_tokenizer(), feature_extractor=self.get_feature_extractor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_normalize=False, padding_value=1.0)
+
+ processor = CLIPSegProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, CLIPTokenizerFast)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, ViTFeatureExtractor)
+
+ def test_feature_extractor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = feature_extractor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "attention_mask", "pixel_values"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = CLIPSegProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
diff --git a/utils/check_repo.py b/utils/check_repo.py
index 4b7ec38e80799..8b02185fa9bd5 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -46,6 +46,7 @@
# Being in this list is an exception and should **not** be the rule.
IGNORE_NON_TESTED = PRIVATE_MODELS.copy() + [
# models to ignore for not tested
+ "CLIPSegDecoder", # Building part of bigger (tested) model.
"TableTransformerEncoder", # Building part of bigger (tested) model.
"TableTransformerDecoder", # Building part of bigger (tested) model.
"TimeSeriesTransformerEncoder", # Building part of bigger (tested) model.
@@ -140,6 +141,9 @@
# should **not** be the rule.
IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
# models to ignore for model xxx mapping
+ "CLIPSegForImageSegmentation",
+ "CLIPSegVisionModel",
+ "CLIPSegTextModel",
"EsmForProteinFolding",
"TimeSeriesTransformerForPrediction",
"PegasusXEncoder",
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 53a74703d9659..18c7894da8312 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -35,6 +35,7 @@ src/transformers/models/bloom/configuration_bloom.py
src/transformers/models/camembert/configuration_camembert.py
src/transformers/models/canine/configuration_canine.py
src/transformers/models/clip/configuration_clip.py
+src/transformers/models/clipseg/modeling_clipseg.py
src/transformers/models/codegen/configuration_codegen.py
src/transformers/models/conditional_detr/configuration_conditional_detr.py
src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -187,4 +188,4 @@ src/transformers/models/xlnet/configuration_xlnet.py
src/transformers/models/yolos/configuration_yolos.py
src/transformers/models/yolos/modeling_yolos.py
src/transformers/models/x_clip/modeling_x_clip.py
-src/transformers/models/yoso/configuration_yoso.py
+src/transformers/models/yoso/configuration_yoso.py
\ No newline at end of file