diff --git a/README.md b/README.md
index 74af092f69e14..676689fbc0f66 100644
--- a/README.md
+++ b/README.md
@@ -340,6 +340,7 @@ AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Ch
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
diff --git a/README_ko.md b/README_ko.md
index 7957bf1e57837..a28f036c063c9 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -318,6 +318,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. 새로운 모델을 올리고 싶나요? 우리가 **상세한 가이드와 템플릿** 으로 새로운 모델을 올리도록 도와드릴게요. 가이드와 템플릿은 이 저장소의 [`templates`](./templates) 폴더에서 확인하실 수 있습니다. [컨트리뷰션 가이드라인](./CONTRIBUTING.md)을 꼭 확인해주시고, PR을 올리기 전에 메인테이너에게 연락하거나 이슈를 오픈해 피드백을 받으시길 바랍니다.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 4af288108ba94..ca2c612f8d119 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -342,6 +342,7 @@ conda install -c huggingface transformers
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (来自 Google/CMU) 伴随论文 [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) 由 Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le 发布。
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (来自 Facebook AI) 伴随论文 [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) 由 Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli 发布。
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (来自 Facebook AI) 伴随论文 [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) 由 Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli 发布。
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (来自 Huazhong University of Science & Technology) 伴随论文 [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) 由 Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu 发布。
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (来自 the University of Wisconsin - Madison) 伴随论文 [You Only Sample (Almost) 由 Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh 发布。
1. 想要贡献新的模型?我们这里有一份**详细指引和模板**来引导你添加新的模型。你可以在 [`templates`](./templates) 目录中找到他们。记得查看 [贡献指南](./CONTRIBUTING.md) 并在开始写 PR 前联系维护人员或开一个新的 issue 来获得反馈。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index fc81a1faf8eee..7e26c22c54c88 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -354,6 +354,7 @@ conda install -c huggingface transformers
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. 想要貢獻新的模型?我們這裡有一份**詳細指引和模板**來引導你加入新的模型。你可以在 [`templates`](./templates) 目錄中找到它們。記得查看[貢獻指引](./CONTRIBUTING.md)並在開始寫 PR 前聯繫維護人員或開一個新的 issue 來獲得 feedbacks。
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index c32004ff52142..98b036d30381d 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -376,6 +376,8 @@
title: XLSR-Wav2Vec2
- local: model_doc/xls_r
title: XLS-R
+ - local: model_doc/yolos
+ title: YOLOS
- local: model_doc/yoso
title: YOSO
title: Models
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 08370fae6ecb4..1a5829db217a9 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -160,6 +160,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
@@ -274,6 +275,7 @@ Flax), PyTorch, and/or TensorFlow.
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
new file mode 100644
index 0000000000000..bda65bec91378
--- /dev/null
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -0,0 +1,60 @@
+
+
+# YOLOS
+
+## Overview
+
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
+
+The abstract from the paper is the following:
+
+*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
+
+Tips:
+
+- One can use [`YolosFeatureExtractor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+
+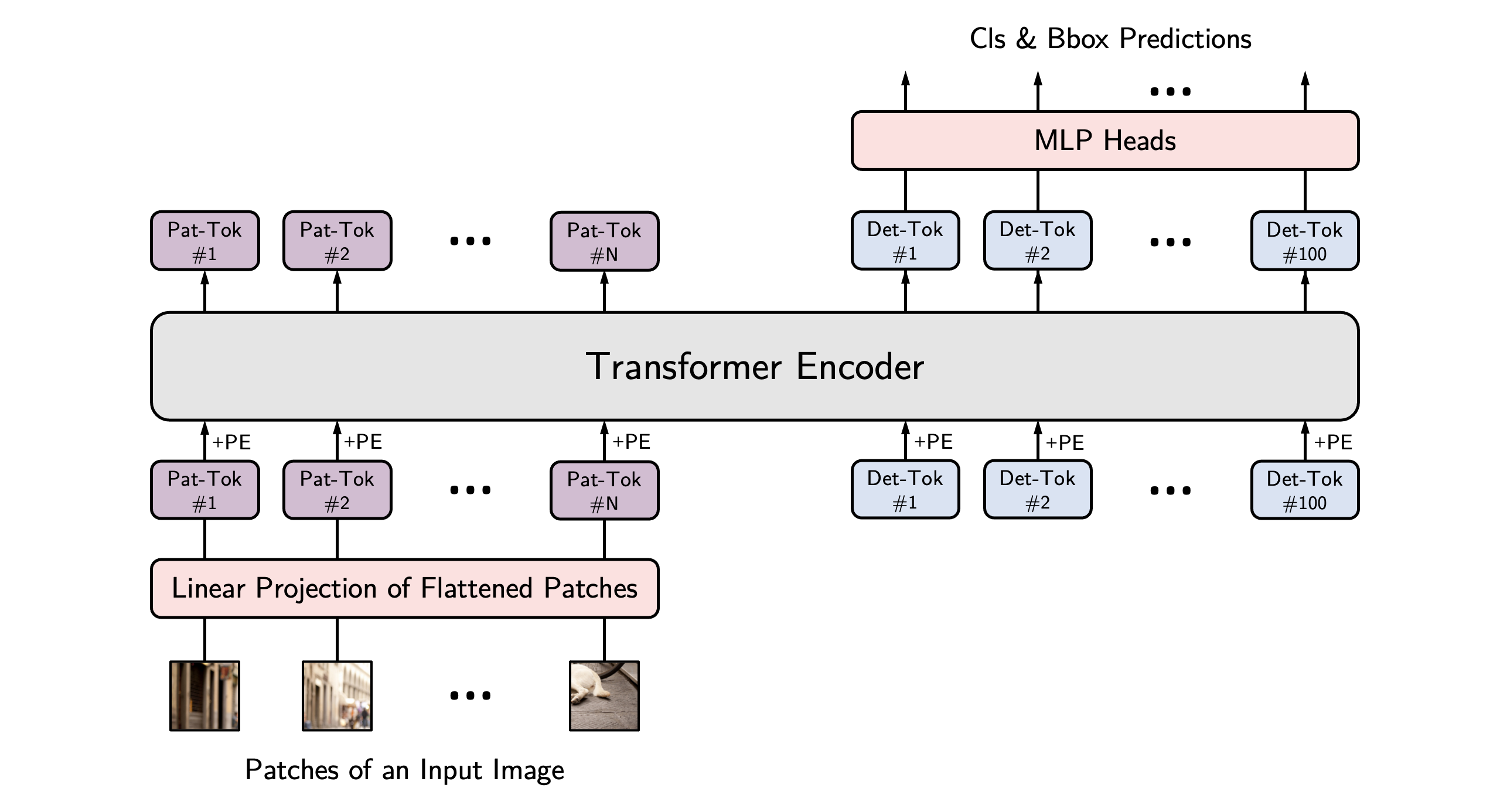 +
+ YOLOS architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+
+## YolosConfig
+
+[[autodoc]] YolosConfig
+
+
+## YolosFeatureExtractor
+
+[[autodoc]] YolosFeatureExtractor
+ - __call__
+ - pad
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+
+## YolosModel
+
+[[autodoc]] YolosModel
+ - forward
+
+
+## YolosForObjectDetection
+
+[[autodoc]] YolosForObjectDetection
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 5695ff57c53b0..05c11d4c54da0 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -320,6 +320,7 @@
"models.xlm_roberta": ["XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLMRobertaConfig"],
"models.xlm_roberta_xl": ["XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLMRobertaXLConfig"],
"models.xlnet": ["XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLNetConfig"],
+ "models.yolos": ["YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP", "YolosConfig"],
"models.yoso": ["YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP", "YosoConfig"],
"onnx": [],
"pipelines": [
@@ -551,6 +552,7 @@
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
_import_structure["models.vit"].append("ViTFeatureExtractor")
+ _import_structure["models.yolos"].append("YolosFeatureExtractor")
else:
from .utils import dummy_vision_objects
@@ -1681,6 +1683,14 @@
"load_tf_weights_in_xlnet",
]
)
+ _import_structure["models.yolos"].extend(
+ [
+ "YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "YolosForObjectDetection",
+ "YolosModel",
+ "YolosPreTrainedModel",
+ ]
+ )
_import_structure["models.yoso"].extend(
[
"YOSO_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2696,6 +2706,7 @@
from .models.xlm_roberta import XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP, XLMRobertaConfig
from .models.xlm_roberta_xl import XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP, XLMRobertaXLConfig
from .models.xlnet import XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP, XLNetConfig
+ from .models.yolos import YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP, YolosConfig
from .models.yoso import YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP, YosoConfig
# Pipelines
@@ -2901,6 +2912,7 @@
from .models.segformer import SegformerFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
+ from .models.yolos import YolosFeatureExtractor
else:
from .utils.dummy_vision_objects import *
@@ -3831,6 +3843,12 @@
XLNetPreTrainedModel,
load_tf_weights_in_xlnet,
)
+ from .models.yolos import (
+ YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST,
+ YolosForObjectDetection,
+ YolosModel,
+ YolosPreTrainedModel,
+ )
from .models.yoso import (
YOSO_PRETRAINED_MODEL_ARCHIVE_LIST,
YosoForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index d21f2789b3d78..8697e4333d67d 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -135,5 +135,6 @@
xlm_roberta,
xlm_roberta_xl,
xlnet,
+ yolos,
yoso,
)
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 210199aec8185..0eaa838d47024 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -29,6 +29,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("yolos", "YolosConfig"),
("tapex", "BartConfig"),
("dpt", "DPTConfig"),
("decision_transformer", "DecisionTransformerConfig"),
@@ -138,6 +139,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here)
+ ("yolos", "YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("dpt", "DPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("glpn", "GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("maskformer", "MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -231,6 +233,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("yolos", "YOLOS"),
("tapex", "TAPEX"),
("dpt", "DPT"),
("decision_transformer", "Decision Transformer"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 79ebbf8015ec7..d385d8cfd3b2f 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -61,6 +61,7 @@
("data2vec-vision", "BeitFeatureExtractor"),
("dpt", "DPTFeatureExtractor"),
("glpn", "GLPNFeatureExtractor"),
+ ("yolos", "YolosFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 78d32ad070891..13f1070c6cc6a 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("yolos", "YolosModel"),
("dpt", "DPTModel"),
("decision_transformer", "DecisionTransformerModel"),
("glpn", "GLPNModel"),
@@ -386,6 +387,7 @@
MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
[
# Model for Object Detection mapping
+ ("yolos", "YolosForObjectDetection"),
("detr", "DetrForObjectDetection"),
]
)
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index b787aebc8aa6f..64f8190d62974 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -1865,30 +1865,31 @@ class DetrLoss(nn.Module):
"""
This class computes the losses for DetrForObjectDetection/DetrForSegmentation. The process happens in two steps: 1)
we compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each pair
- of matched ground-truth / prediction (supervise class and box)
+ of matched ground-truth / prediction (supervise class and box).
+
+ A note on the `num_classes` argument (copied from original repo in detr.py): "the naming of the `num_classes`
+ parameter of the criterion is somewhat misleading. It indeed corresponds to `max_obj_id` + 1, where `max_obj_id` is
+ the maximum id for a class in your dataset. For example, COCO has a `max_obj_id` of 90, so we pass `num_classes` to
+ be 91. As another example, for a dataset that has a single class with `id` 1, you should pass `num_classes` to be 2
+ (`max_obj_id` + 1). For more details on this, check the following discussion
+ https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
+
+
+ Args:
+ matcher (`DetrHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ eos_coef (`float`):
+ Relative classification weight applied to the no-object category.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
"""
def __init__(self, matcher, num_classes, eos_coef, losses):
- """
- Create the criterion.
-
- A note on the num_classes parameter (copied from original repo in detr.py): "the naming of the `num_classes`
- parameter of the criterion is somewhat misleading. it indeed corresponds to `max_obj_id + 1`, where max_obj_id
- is the maximum id for a class in your dataset. For example, COCO has a max_obj_id of 90, so we pass
- `num_classes` to be 91. As another example, for a dataset that has a single class with id 1, you should pass
- `num_classes` to be 2 (max_obj_id + 1). For more details on this, check the following discussion
- https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
-
- Parameters:
- matcher: module able to compute a matching between targets and proposals.
- num_classes: number of object categories, omitting the special no-object category.
- weight_dict: dict containing as key the names of the losses and as values their relative weight.
- eos_coef: relative classification weight applied to the no-object category.
- losses: list of all the losses to be applied. See get_loss for list of available losses.
- """
super().__init__()
- self.num_classes = num_classes
self.matcher = matcher
+ self.num_classes = num_classes
self.eos_coef = eos_coef
self.losses = losses
empty_weight = torch.ones(self.num_classes + 1)
@@ -2017,10 +2018,12 @@ def forward(self, outputs, targets):
"""
This performs the loss computation.
- Parameters:
- outputs: dict of tensors, see the output specification of the model for the format
- targets: list of dicts, such that len(targets) == batch_size.
- The expected keys in each dict depends on the losses applied, see each loss' doc
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs"}
@@ -2086,20 +2089,18 @@ class DetrHungarianMatcher(nn.Module):
For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
"""
def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
- """
- Creates the matcher.
-
- Params:
- class_cost: This is the relative weight of the classification error in the matching cost
- bbox_cost:
- This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
- giou_cost: This is the relative weight of the giou loss of the bounding box in the matching cost
- """
super().__init__()
-
requires_backends(self, ["scipy"])
self.class_cost = class_cost
@@ -2111,25 +2112,25 @@ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float
@torch.no_grad()
def forward(self, outputs, targets):
"""
- Performs the matching.
-
- Params:
- outputs: This is a dict that contains at least these entries:
- "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
- "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
- targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
- "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
- objects in the target) containing the class labels "boxes": Tensor of dim [num_target_boxes, 4]
- containing the target box coordinates
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
Returns:
- A list of size batch_size, containing tuples of (index_i, index_j) where:
-
- - index_i is the indices of the selected predictions (in order)
- - index_j is the indices of the corresponding selected targets (in order)
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
- bs, num_queries = outputs["logits"].shape[:2]
+ batch_size, num_queries = outputs["logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
@@ -2152,7 +2153,7 @@ def forward(self, outputs, targets):
# Final cost matrix
cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
- cost_matrix = cost_matrix.view(bs, num_queries, -1).cpu()
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
@@ -2175,11 +2176,12 @@ def box_area(boxes: Tensor) -> Tensor:
Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
Args:
- boxes (Tensor[N, 4]): boxes for which the area will be computed. They
- are expected to be in (x1, y1, x2, y2) format with `0 <= x1 < x2` and `0 <= y1 < y2`.
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
Returns:
- area (Tensor[N]): area for each box
+ `torch.FloatTensor`: a tensor containing the area for each box.
"""
boxes = _upcast(boxes)
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
@@ -2190,11 +2192,11 @@ def box_iou(boxes1, boxes2):
area1 = box_area(boxes1)
area2 = box_area(boxes2)
- lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
- rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
- wh = (rb - lt).clamp(min=0) # [N,M,2]
- inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
union = area1[:, None] + area2 - inter
@@ -2207,7 +2209,7 @@ def generalized_box_iou(boxes1, boxes2):
Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
Returns:
- a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
"""
# degenerate boxes gives inf / nan results
# so do an early check
@@ -2242,7 +2244,6 @@ def __init__(self, tensors, mask: Optional[Tensor]):
self.mask = mask
def to(self, device):
- # type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
diff --git a/src/transformers/models/yolos/__init__.py b/src/transformers/models/yolos/__init__.py
new file mode 100644
index 0000000000000..fcdf387c68d6e
--- /dev/null
+++ b/src/transformers/models/yolos/__init__.py
@@ -0,0 +1,57 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_yolos": ["YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP", "YolosConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_yolos"] = ["YolosFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_yolos"] = [
+ "YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "YolosForObjectDetection",
+ "YolosModel",
+ "YolosPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_yolos import YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP, YolosConfig
+
+ if is_vision_available():
+ from .feature_extraction_yolos import YolosFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_yolos import (
+ YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST,
+ YolosForObjectDetection,
+ YolosModel,
+ YolosPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/yolos/configuration_yolos.py b/src/transformers/models/yolos/configuration_yolos.py
new file mode 100644
index 0000000000000..cd3414a7f26ee
--- /dev/null
+++ b/src/transformers/models/yolos/configuration_yolos.py
@@ -0,0 +1,153 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" YOLOS model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "hustvl/yolos-small": "https://huggingface.co/hustvl/yolos-small/resolve/main/config.json",
+ # See all YOLOS models at https://huggingface.co/models?filter=yolos
+}
+
+
+class YolosConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`YolosModel`]. It is used to instantiate a YOLOS
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the YOLOS
+ [hustvl/yolos-base](https://huggingface.co/hustvl/yolos-base) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ image_size (`List[int]`, *optional*, defaults to `[512, 864]`):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to `16`):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to `3`):
+ The number of input channels.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ num_detection_tokens (`int`, *optional*, defaults to `100`):
+ The number of detection tokens.
+ use_mid_position_embeddings (`bool`, *optional*, defaults to `True`):
+ Whether to use the mid-layer position encodings.
+ auxiliary_loss (`bool`, *optional*, defaults to `False`):
+ Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
+ class_cost (`float`, *optional*, defaults to 1):
+ Relative weight of the classification error in the Hungarian matching cost.
+ bbox_cost (`float`, *optional*, defaults to 5):
+ Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost.
+ giou_cost (`float`, *optional*, defaults to 2):
+ Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost.
+ bbox_loss_coefficient (`float`, *optional*, defaults to 5):
+ Relative weight of the L1 bounding box loss in the object detection loss.
+ giou_loss_coefficient (`float`, *optional*, defaults to 2):
+ Relative weight of the generalized IoU loss in the object detection loss.
+ eos_coefficient (`float`, *optional*, defaults to 0.1):
+ Relative classification weight of the 'no-object' class in the object detection loss.
+
+ Example:
+
+ ```python
+ >>> from transformers import YolosModel, YolosConfig
+
+ >>> # Initializing a YOLOS hustvl/yolos-base style configuration
+ >>> configuration = YolosConfig()
+
+ >>> # Initializing a model from the hustvl/yolos-base style configuration
+ >>> model = YolosModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "yolos"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ image_size=[512, 864],
+ patch_size=16,
+ num_channels=3,
+ qkv_bias=True,
+ num_detection_tokens=100,
+ use_mid_position_embeddings=True,
+ auxiliary_loss=False,
+ class_cost=1,
+ bbox_cost=5,
+ giou_cost=2,
+ bbox_loss_coefficient=5,
+ giou_loss_coefficient=2,
+ eos_coefficient=0.1,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.qkv_bias = qkv_bias
+ self.num_detection_tokens = num_detection_tokens
+ self.use_mid_position_embeddings = use_mid_position_embeddings
+ self.auxiliary_loss = auxiliary_loss
+ # Hungarian matcher
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ # Loss coefficients
+ self.bbox_loss_coefficient = bbox_loss_coefficient
+ self.giou_loss_coefficient = giou_loss_coefficient
+ self.eos_coefficient = eos_coefficient
diff --git a/src/transformers/models/yolos/convert_yolos_to_pytorch.py b/src/transformers/models/yolos/convert_yolos_to_pytorch.py
new file mode 100644
index 0000000000000..add0ae772db13
--- /dev/null
+++ b/src/transformers/models/yolos/convert_yolos_to_pytorch.py
@@ -0,0 +1,263 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert YOLOS checkpoints from the original repository. URL: https://github.com/hustvl/YOLOS"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import hf_hub_download
+from transformers import YolosConfig, YolosFeatureExtractor, YolosForObjectDetection
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_yolos_config(yolos_name):
+ config = YolosConfig()
+
+ # size of the architecture
+ if "yolos_ti" in yolos_name:
+ config.hidden_size = 192
+ config.intermediate_size = 768
+ config.num_hidden_layers = 12
+ config.num_attention_heads = 3
+ config.image_size = [800, 1333]
+ config.use_mid_position_embeddings = False
+ elif yolos_name == "yolos_s_dWr":
+ config.hidden_size = 330
+ config.num_hidden_layers = 14
+ config.num_attention_heads = 6
+ config.intermediate_size = 1320
+ elif "yolos_s" in yolos_name:
+ config.hidden_size = 384
+ config.intermediate_size = 1536
+ config.num_hidden_layers = 12
+ config.num_attention_heads = 6
+ elif "yolos_b" in yolos_name:
+ config.image_size = [800, 1344]
+
+ config.num_labels = 91
+ repo_id = "datasets/huggingface/label-files"
+ filename = "coco-detection-id2label.json"
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v(state_dict, config, base_model=False):
+ for i in range(config.num_hidden_layers):
+ # read in weights + bias of input projection layer (in timm, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"blocks.{i}.attn.qkv.weight")
+ in_proj_bias = state_dict.pop(f"blocks.{i}.attn.qkv.bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[: config.hidden_size, :]
+ state_dict[f"encoder.layer.{i}.attention.attention.query.bias"] = in_proj_bias[: config.hidden_size]
+ state_dict[f"encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
+ config.hidden_size : config.hidden_size * 2, :
+ ]
+ state_dict[f"encoder.layer.{i}.attention.attention.key.bias"] = in_proj_bias[
+ config.hidden_size : config.hidden_size * 2
+ ]
+ state_dict[f"encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[-config.hidden_size :, :]
+ state_dict[f"encoder.layer.{i}.attention.attention.value.bias"] = in_proj_bias[-config.hidden_size :]
+
+
+def rename_key(name):
+ if "backbone" in name:
+ name = name.replace("backbone", "vit")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "embeddings.cls_token")
+ if "det_token" in name:
+ name = name.replace("det_token", "embeddings.detection_tokens")
+ if "mid_pos_embed" in name:
+ name = name.replace("mid_pos_embed", "encoder.mid_position_embeddings")
+ if "pos_embed" in name:
+ name = name.replace("pos_embed", "embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ if "blocks" in name:
+ name = name.replace("blocks", "encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "class_embed" in name:
+ name = name.replace("class_embed", "class_labels_classifier")
+ if "bbox_embed" in name:
+ name = name.replace("bbox_embed", "bbox_predictor")
+ if "vit.norm" in name:
+ name = name.replace("vit.norm", "vit.layernorm")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, model):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[2])
+ dim = model.vit.encoder.layer[layer_num].attention.attention.all_head_size
+ if "weight" in key:
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.key.weight"] = val[
+ dim : dim * 2, :
+ ]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.query.bias"] = val[:dim]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.key.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.value.bias"] = val[-dim:]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@torch.no_grad()
+def convert_yolos_checkpoint(yolos_name, checkpoint_path, pytorch_dump_folder_path, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our YOLOS structure.
+ """
+ config = get_yolos_config(yolos_name)
+
+ # load original state_dict
+ state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
+
+ # load 🤗 model
+ model = YolosForObjectDetection(config)
+ model.eval()
+ new_state_dict = convert_state_dict(state_dict, model)
+ model.load_state_dict(new_state_dict)
+
+ # Check outputs on an image, prepared by YolosFeatureExtractor
+ size = 800 if yolos_name != "yolos_ti" else 512
+ feature_extractor = YolosFeatureExtractor(format="coco_detection", size=size)
+ encoding = feature_extractor(images=prepare_img(), return_tensors="pt")
+ outputs = model(**encoding)
+ logits, pred_boxes = outputs.logits, outputs.pred_boxes
+
+ expected_slice_logits, expected_slice_boxes = None, None
+ if yolos_name == "yolos_ti":
+ expected_slice_logits = torch.tensor(
+ [[-39.5022, -11.9820, -17.6888], [-29.9574, -9.9769, -17.7691], [-42.3281, -20.7200, -30.6294]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.4021, 0.0836, 0.7979], [0.0184, 0.2609, 0.0364], [0.1781, 0.2004, 0.2095]]
+ )
+ elif yolos_name == "yolos_s_200_pre":
+ expected_slice_logits = torch.tensor(
+ [[-24.0248, -10.3024, -14.8290], [-42.0392, -16.8200, -27.4334], [-27.2743, -11.8154, -18.7148]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.2559, 0.5455, 0.4706], [0.2989, 0.7279, 0.1875], [0.7732, 0.4017, 0.4462]]
+ )
+ elif yolos_name == "yolos_s_300_pre":
+ expected_slice_logits = torch.tensor(
+ [[-36.2220, -14.4385, -23.5457], [-35.6970, -14.7583, -21.3935], [-31.5939, -13.6042, -16.8049]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.7614, 0.2316, 0.4728], [0.7168, 0.4495, 0.3855], [0.4996, 0.1466, 0.9996]]
+ )
+ elif yolos_name == "yolos_s_dWr":
+ expected_slice_logits = torch.tensor(
+ [[-42.8668, -24.1049, -41.1690], [-34.7456, -14.1274, -24.9194], [-33.7898, -12.1946, -25.6495]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.5587, 0.2773, 0.0605], [0.5004, 0.3014, 0.9994], [0.4999, 0.1548, 0.9994]]
+ )
+ elif yolos_name == "yolos_base":
+ expected_slice_logits = torch.tensor(
+ [[-40.6064, -24.3084, -32.6447], [-55.1990, -30.7719, -35.5877], [-51.4311, -33.3507, -35.6462]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.5555, 0.2794, 0.0655], [0.9049, 0.2664, 0.1894], [0.9183, 0.1984, 0.1635]]
+ )
+ else:
+ raise ValueError(f"Unknown yolos_name: {yolos_name}")
+
+ assert torch.allclose(logits[0, :3, :3], expected_slice_logits, atol=1e-4)
+ assert torch.allclose(pred_boxes[0, :3, :3], expected_slice_boxes, atol=1e-4)
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {yolos_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model_mapping = {
+ "yolos_ti": "yolos-tiny",
+ "yolos_s_200_pre": "yolos-small",
+ "yolos_s_300_pre": "yolos-small-300",
+ "yolos_s_dWr": "yolos-small-dwr",
+ "yolos_base": "yolos-base",
+ }
+
+ print("Pushing to the hub...")
+ model_name = model_mapping[yolos_name]
+ feature_extractor.push_to_hub(model_name, organization="hustvl")
+ model.push_to_hub(model_name, organization="hustvl")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--yolos_name",
+ default="yolos_s_200_pre",
+ type=str,
+ help="Name of the YOLOS model you'd like to convert. Should be one of 'yolos_ti', 'yolos_s_200_pre', 'yolos_s_300_pre', 'yolos_s_dWr', 'yolos_base'.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, help="Path to the original state dict (.pth file)."
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_yolos_checkpoint(args.yolos_name, args.checkpoint_path, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/yolos/feature_extraction_yolos.py b/src/transformers/models/yolos/feature_extraction_yolos.py
new file mode 100644
index 0000000000000..76b64ec837753
--- /dev/null
+++ b/src/transformers/models/yolos/feature_extraction_yolos.py
@@ -0,0 +1,916 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for YOLOS."""
+
+import io
+import pathlib
+from collections import defaultdict
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import ImageFeatureExtractionMixin, is_torch_tensor
+from ...utils import TensorType, is_torch_available, logging
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+logger = logging.get_logger(__name__)
+
+
+ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.center_to_corners_format
+def center_to_corners_format(x):
+ """
+ Converts a PyTorch tensor of bounding boxes of center format (center_x, center_y, width, height) to corners format
+ (x_0, y_0, x_1, y_1).
+ """
+ x_c, y_c, w, h = x.unbind(-1)
+ b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
+ return torch.stack(b, dim=-1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.corners_to_center_format
+def corners_to_center_format(x):
+ """
+ Converts a NumPy array of bounding boxes of shape (number of bounding boxes, 4) of corners format (x_0, y_0, x_1,
+ y_1) to center format (center_x, center_y, width, height).
+ """
+ x_transposed = x.T
+ x0, y0, x1, y1 = x_transposed[0], x_transposed[1], x_transposed[2], x_transposed[3]
+ b = [(x0 + x1) / 2, (y0 + y1) / 2, (x1 - x0), (y1 - y0)]
+ return np.stack(b, axis=-1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
+def masks_to_boxes(masks):
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
+
+ Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.rgb_to_id
+def rgb_to_id(color):
+ if isinstance(color, np.ndarray) and len(color.shape) == 3:
+ if color.dtype == np.uint8:
+ color = color.astype(np.int32)
+ return color[:, :, 0] + 256 * color[:, :, 1] + 256 * 256 * color[:, :, 2]
+ return int(color[0] + 256 * color[1] + 256 * 256 * color[2])
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.id_to_rgb
+def id_to_rgb(id_map):
+ if isinstance(id_map, np.ndarray):
+ id_map_copy = id_map.copy()
+ rgb_shape = tuple(list(id_map.shape) + [3])
+ rgb_map = np.zeros(rgb_shape, dtype=np.uint8)
+ for i in range(3):
+ rgb_map[..., i] = id_map_copy % 256
+ id_map_copy //= 256
+ return rgb_map
+ color = []
+ for _ in range(3):
+ color.append(id_map % 256)
+ id_map //= 256
+ return color
+
+
+class YolosFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a YOLOS feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the input to a certain `size`.
+ size (`int`, *optional*, defaults to 800):
+ Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
+ sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
+ the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
+ height / width, size)`.
+ max_size (`int`, *optional*, defaults to `1333`):
+ The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
+ set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
+ image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
+ ImageNet std.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
+ def __init__(
+ self,
+ format="coco_detection",
+ do_resize=True,
+ size=800,
+ max_size=1333,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.format = self._is_valid_format(format)
+ self.do_resize = do_resize
+ self.size = size
+ self.max_size = max_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
+ self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
+ def _is_valid_format(self, format):
+ if format not in ["coco_detection", "coco_panoptic"]:
+ raise ValueError(f"Format {format} not supported")
+ return format
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ if self.format == "coco_detection":
+ image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
+ return image, target
+ elif self.format == "coco_panoptic":
+ image, target = self.prepare_coco_panoptic(image, target, masks_path)
+ return image, target
+ else:
+ raise ValueError(f"Format {self.format} not supported")
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, segmentations, height, width):
+
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
+ def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ w, h = image.size
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # get all COCO annotations for the given image
+ anno = target["annotations"]
+
+ anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ boxes = [obj["bbox"] for obj in anno]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
+
+ classes = [obj["category_id"] for obj in anno]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ if return_segmentation_masks:
+ segmentations = [obj["segmentation"] for obj in anno]
+ masks = self.convert_coco_poly_to_mask(segmentations, h, w)
+
+ keypoints = None
+ if anno and "keypoints" in anno[0]:
+ keypoints = [obj["keypoints"] for obj in anno]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ if num_keypoints:
+ keypoints = keypoints.reshape((-1, 3))
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+ boxes = boxes[keep]
+ classes = classes[keep]
+ if return_segmentation_masks:
+ masks = masks[keep]
+ if keypoints is not None:
+ keypoints = keypoints[keep]
+
+ target = {}
+ target["boxes"] = boxes
+ target["class_labels"] = classes
+ if return_segmentation_masks:
+ target["masks"] = masks
+ target["image_id"] = image_id
+ if keypoints is not None:
+ target["keypoints"] = keypoints
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
+ target["area"] = area[keep]
+ target["iscrowd"] = iscrowd[keep]
+
+ target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+
+ return image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
+ w, h = image.size
+ ann_info = target.copy()
+ ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
+
+ if "segments_info" in ann_info:
+ masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = np.asarray(masks, dtype=np.uint8)
+
+ labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
+
+ target = {}
+ target["image_id"] = np.asarray(
+ [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
+ )
+ if return_masks:
+ target["masks"] = masks
+ target["class_labels"] = labels
+
+ target["boxes"] = masks_to_boxes(masks)
+
+ target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ if "segments_info" in ann_info:
+ target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
+ target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
+
+ return image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
+ def _resize(self, image, size, target=None, max_size=None):
+ """
+ Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
+ edge of the image will be matched to this number.
+
+ If given, also resize the target accordingly.
+ """
+ if not isinstance(image, Image.Image):
+ image = self.to_pil_image(image)
+
+ def get_size_with_aspect_ratio(image_size, size, max_size=None):
+ w, h = image_size
+ if max_size is not None:
+ min_original_size = float(min((w, h)))
+ max_original_size = float(max((w, h)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (w <= h and w == size) or (h <= w and h == size):
+ return (h, w)
+
+ if w < h:
+ ow = size
+ oh = int(size * h / w)
+ else:
+ oh = size
+ ow = int(size * w / h)
+
+ return (oh, ow)
+
+ def get_size(image_size, size, max_size=None):
+ if isinstance(size, (list, tuple)):
+ return size
+ else:
+ # size returned must be (w, h) since we use PIL to resize images
+ # so we revert the tuple
+ return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
+
+ size = get_size(image.size, size, max_size)
+ rescaled_image = self.resize(image, size=size)
+
+ if target is None:
+ return rescaled_image, None
+
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
+ ratio_width, ratio_height = ratios
+
+ target = target.copy()
+ if "boxes" in target:
+ boxes = target["boxes"]
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ target["boxes"] = scaled_boxes
+
+ if "area" in target:
+ area = target["area"]
+ scaled_area = area * (ratio_width * ratio_height)
+ target["area"] = scaled_area
+
+ w, h = size
+ target["size"] = np.asarray([h, w], dtype=np.int64)
+
+ if "masks" in target:
+ # use PyTorch as current workaround
+ # TODO replace by self.resize
+ masks = torch.from_numpy(target["masks"][:, None]).float()
+ interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
+ target["masks"] = interpolated_masks.numpy()
+
+ return rescaled_image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
+ def _normalize(self, image, mean, std, target=None):
+ """
+ Normalize the image with a certain mean and std.
+
+ If given, also normalize the target bounding boxes based on the size of the image.
+ """
+
+ image = self.normalize(image, mean=mean, std=std)
+ if target is None:
+ return image, None
+
+ target = target.copy()
+ h, w = image.shape[-2:]
+
+ if "boxes" in target:
+ boxes = target["boxes"]
+ boxes = corners_to_center_format(boxes)
+ boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
+ target["boxes"] = boxes
+
+ return image, target
+
+ def __call__(
+ self,
+ images: ImageInput,
+ annotations: Union[List[Dict], List[List[Dict]]] = None,
+ return_segmentation_masks: Optional[bool] = False,
+ masks_path: Optional[pathlib.Path] = None,
+ padding: Optional[bool] = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
+ padded up to the largest image in a batch.
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ annotations (`Dict`, `List[Dict]`, *optional*):
+ The corresponding annotations in COCO format.
+
+ In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
+ each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
+ annotations being a list of COCO object annotations.
+
+ In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
+ each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
+ [segment_info]} with segments_info being a list of COCO panoptic annotations.
+
+ return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
+ Whether to also include instance segmentation masks as part of the labels in case `format =
+ "coco_detection"`.
+
+ masks_path (`pathlib.Path`, *optional*):
+ Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
+ relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
+
+ padding (`bool`, *optional*, defaults to `True`):
+ Whether or not to pad images up to the largest image in a batch.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+ - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
+ """
+ # Input type checking for clearer error
+
+ valid_images = False
+ valid_annotations = False
+ valid_masks_path = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ # Check that annotations has a valid type
+ if annotations is not None:
+ if not is_batched:
+ if self.format == "coco_detection":
+ if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
+ if isinstance(annotations["annotations"], (list, tuple)):
+ # an image can have no annotations
+ if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
+ valid_annotations = True
+ elif self.format == "coco_panoptic":
+ if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
+ if isinstance(annotations["segments_info"], (list, tuple)):
+ # an image can have no segments (?)
+ if len(annotations["segments_info"]) == 0 or isinstance(
+ annotations["segments_info"][0], dict
+ ):
+ valid_annotations = True
+ else:
+ if isinstance(annotations, (list, tuple)):
+ if len(images) != len(annotations):
+ raise ValueError("There must be as many annotations as there are images")
+ if isinstance(annotations[0], Dict):
+ if self.format == "coco_detection":
+ if isinstance(annotations[0]["annotations"], (list, tuple)):
+ valid_annotations = True
+ elif self.format == "coco_panoptic":
+ if isinstance(annotations[0]["segments_info"], (list, tuple)):
+ valid_annotations = True
+
+ if not valid_annotations:
+ raise ValueError(
+ """
+ Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
+ detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
+ being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
+ should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
+ of annotations in COCO format.
+ """
+ )
+
+ # Check that masks_path has a valid type
+ if masks_path is not None:
+ if self.format == "coco_panoptic":
+ if isinstance(masks_path, pathlib.Path):
+ valid_masks_path = True
+ if not valid_masks_path:
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a `pathlib.Path` object."
+ )
+
+ if not is_batched:
+ images = [images]
+ if annotations is not None:
+ annotations = [annotations]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ if not isinstance(image, Image.Image):
+ image = self.to_pil_image(image)
+ image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
+ images[idx] = image
+ annotations[idx] = target
+
+ # transformations (resizing + normalization)
+ if self.do_resize and self.size is not None:
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
+ images[idx] = image
+ annotations[idx] = target
+ else:
+ for idx, image in enumerate(images):
+ images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
+
+ if self.do_normalize:
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ image, target = self._normalize(
+ image=image, mean=self.image_mean, std=self.image_std, target=target
+ )
+ images[idx] = image
+ annotations[idx] = target
+ else:
+ images = [
+ self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
+ ]
+
+ if padding:
+ # pad images up to largest image in batch
+ max_size = self._max_by_axis([list(image.shape) for image in images])
+ c, h, w = max_size
+ padded_images = []
+ for image in images:
+ # create padded image
+ padded_image = np.zeros((c, h, w), dtype=np.float32)
+ padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
+ padded_images.append(padded_image)
+ images = padded_images
+
+ # return as BatchFeature
+ data = {}
+ data["pixel_values"] = images
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ if annotations is not None:
+ # Convert to TensorType
+ tensor_type = return_tensors
+ if not isinstance(tensor_type, TensorType):
+ tensor_type = TensorType(tensor_type)
+
+ if not tensor_type == TensorType.PYTORCH:
+ raise ValueError("Only PyTorch is supported for the moment.")
+ else:
+ if not is_torch_available():
+ raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
+
+ encoded_inputs["labels"] = [
+ {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
+ def _max_by_axis(self, the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+ def pad(self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None):
+ """
+ Pad images up to the largest image in a batch.
+
+ Args:
+ pixel_values_list (`List[torch.Tensor]`):
+ List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following field:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+
+ """
+
+ max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
+ c, h, w = max_size
+ padded_images = []
+ for image in pixel_values_list:
+ # create padded image
+ padded_image = np.zeros((c, h, w), dtype=np.float32)
+ padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
+ padded_images.append(padded_image)
+
+ # return as BatchFeature
+ data = {"pixel_values": padded_images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_segmentation
+ def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
+
+ Parameters:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
+ threshold (`float`, *optional*, defaults to 0.9):
+ Threshold to use to filter out queries.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, raw_masks = outputs.logits, outputs.pred_masks
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
+
+ predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
+ preds.append(predictions)
+ return preds
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_instance
+ def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ results (`List[Dict]`):
+ Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
+ added.
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation).
+ max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation).
+ threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
+ image in the batch as predicted by the model.
+ """
+
+ if len(orig_target_sizes) != len(max_target_sizes):
+ raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
+ max_h, max_w = max_target_sizes.max(0)[0].tolist()
+ outputs_masks = outputs.pred_masks.squeeze(2)
+ outputs_masks = nn.functional.interpolate(
+ outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
+ )
+ outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
+
+ for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
+ img_h, img_w = t[0], t[1]
+ results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
+ results[i]["masks"] = nn.functional.interpolate(
+ results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
+ ).byte()
+
+ return results
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_panoptic
+ def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
+
+ Parameters:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
+ augmentation but before batching.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction. If left to
+ None, it will default to the `processed_sizes`.
+ is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
+ Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
+ If not set, defaults to the `is_thing_map` of COCO panoptic.
+ threshold (`float`, *optional*, defaults to 0.85):
+ Threshold to use to filter out queries.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
+ an image in the batch as predicted by the model.
+ """
+ if target_sizes is None:
+ target_sizes = processed_sizes
+ if len(processed_sizes) != len(target_sizes):
+ raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
+
+ if is_thing_map is None:
+ # default to is_thing_map of COCO panoptic
+ is_thing_map = {i: i <= 90 for i in range(201)}
+
+ out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
+ if not len(out_logits) == len(raw_masks) == len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
+ )
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
+ out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
+ ):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_boxes = center_to_corners_format(cur_boxes[keep])
+
+ h, w = cur_masks.shape[-2:]
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.flatten(1)
+ stuff_equiv_classes = defaultdict(lambda: [])
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label.item()]:
+ stuff_equiv_classes[label.item()].append(k)
+
+ def get_ids_area(masks, scores, dedup=False):
+ # This helper function creates the final panoptic segmentation image
+ # It also returns the area of the masks that appears on the image
+
+ m_id = masks.transpose(0, 1).softmax(-1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
+ else:
+ m_id = m_id.argmax(-1).view(h, w)
+
+ if dedup:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ if len(equiv) > 1:
+ for eq_id in equiv:
+ m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
+
+ final_h, final_w = to_tuple(target_size)
+
+ seg_img = Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
+ seg_img = seg_img.resize(size=(final_w, final_h), resample=Image.NEAREST)
+
+ np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
+ np_seg_img = np_seg_img.view(final_h, final_w, 3)
+ np_seg_img = np_seg_img.numpy()
+
+ m_id = torch.from_numpy(rgb_to_id(np_seg_img))
+
+ area = []
+ for i in range(len(scores)):
+ area.append(m_id.eq(i).sum().item())
+ return area, seg_img
+
+ area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
+ if cur_classes.numel() > 0:
+ # We know filter empty masks as long as we find some
+ while True:
+ filtered_small = torch.as_tensor(
+ [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
+ )
+ if filtered_small.any().item():
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ cur_masks = cur_masks[~filtered_small]
+ area, seg_img = get_ids_area(cur_masks, cur_scores)
+ else:
+ break
+
+ else:
+ cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
+
+ segments_info = []
+ for i, a in enumerate(area):
+ cat = cur_classes[i].item()
+ segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
+ del cur_classes
+
+ with io.BytesIO() as out:
+ seg_img.save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+ preds.append(predictions)
+ return preds
diff --git a/src/transformers/models/yolos/modeling_yolos.py b/src/transformers/models/yolos/modeling_yolos.py
new file mode 100755
index 0000000000000..86ef903167d67
--- /dev/null
+++ b/src/transformers/models/yolos/modeling_yolos.py
@@ -0,0 +1,1324 @@
+# coding=utf-8
+# Copyright 2022 School of EIC, Huazhong University of Science & Technology and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch YOLOS model."""
+
+
+import collections.abc
+import math
+from dataclasses import dataclass
+from typing import Dict, List, Optional, Set, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import Tensor, nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_scipy_available,
+ is_vision_available,
+ logging,
+ replace_return_docstrings,
+ requires_backends,
+)
+from .configuration_yolos import YolosConfig
+
+
+if is_scipy_available():
+ from scipy.optimize import linear_sum_assignment
+
+if is_vision_available():
+ from transformers.models.detr.feature_extraction_detr import center_to_corners_format
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "YolosConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "YolosFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "hustvl/yolos-small"
+_EXPECTED_OUTPUT_SHAPE = [1, 3401, 384]
+
+
+YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "hustvl/yolos-small",
+ # See all YOLOS models at https://huggingface.co/models?filter=yolos
+]
+
+
+@dataclass
+class YolosObjectDetectionOutput(ModelOutput):
+ """
+ Output type of [`YolosForObjectDetection`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` are provided)):
+ Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a
+ bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized
+ scale-invariant IoU loss.
+ loss_dict (`Dict`, *optional*):
+ A dictionary containing the individual losses. Useful for logging.
+ logits (`torch.FloatTensor` of shape `(batch_size, num_queries, num_classes + 1)`):
+ Classification logits (including no-object) for all queries.
+ pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
+ values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
+ possible padding). You can use [`~DetrFeatureExtractor.post_process`] to retrieve the unnormalized bounding
+ boxes.
+ auxiliary_outputs (`list[Dict]`, *optional*):
+ Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
+ and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
+ `pred_boxes`) for each decoder layer.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
+ the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ loss_dict: Optional[Dict] = None
+ logits: torch.FloatTensor = None
+ pred_boxes: torch.FloatTensor = None
+ auxiliary_outputs: Optional[List[Dict]] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Copied from transformers.models.vit.modeling_vit.to_2tuple
+def to_2tuple(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return (x, x)
+
+
+class YolosEmbeddings(nn.Module):
+ """
+ Construct the CLS token, detection tokens, position and patch embeddings.
+
+ """
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.detection_tokens = nn.Parameter(torch.zeros(1, config.num_detection_tokens, config.hidden_size))
+ self.patch_embeddings = PatchEmbeddings(
+ image_size=config.image_size,
+ patch_size=config.patch_size,
+ num_channels=config.num_channels,
+ embed_dim=config.hidden_size,
+ )
+ num_patches = self.patch_embeddings.num_patches
+ self.position_embeddings = nn.Parameter(
+ torch.zeros(1, num_patches + config.num_detection_tokens + 1, config.hidden_size)
+ )
+
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.interpolation = InterpolateInitialPositionEmbeddings(config)
+ self.config = config
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ batch_size, num_channels, height, width = pixel_values.shape
+ embeddings = self.patch_embeddings(pixel_values)
+
+ batch_size, seq_len, _ = embeddings.size()
+
+ # add the [CLS] and detection tokens to the embedded patch tokens
+ cls_tokens = self.cls_token.expand(batch_size, -1, -1)
+ detection_tokens = self.detection_tokens.expand(batch_size, -1, -1)
+ embeddings = torch.cat((cls_tokens, embeddings, detection_tokens), dim=1)
+
+ # add positional encoding to each token
+ # this might require interpolation of the existing position embeddings
+ position_embeddings = self.interpolation(self.position_embeddings, (height, width))
+
+ embeddings = embeddings + position_embeddings
+
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class InterpolateInitialPositionEmbeddings(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.config = config
+
+ def forward(self, pos_embed, img_size=(800, 1344)) -> torch.Tensor:
+ cls_pos_embed = pos_embed[:, 0, :]
+ cls_pos_embed = cls_pos_embed[:, None]
+ det_pos_embed = pos_embed[:, -self.config.num_detection_tokens :, :]
+ patch_pos_embed = pos_embed[:, 1 : -self.config.num_detection_tokens, :]
+ patch_pos_embed = patch_pos_embed.transpose(1, 2)
+ batch_size, hidden_size, seq_len = patch_pos_embed.shape
+
+ patch_height, patch_width = (
+ self.config.image_size[0] // self.config.patch_size,
+ self.config.image_size[1] // self.config.patch_size,
+ )
+ patch_pos_embed = patch_pos_embed.view(batch_size, hidden_size, patch_height, patch_width)
+
+ height, width = img_size
+ new_patch_heigth, new_patch_width = height // self.config.patch_size, width // self.config.patch_size
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed, size=(new_patch_heigth, new_patch_width), mode="bicubic", align_corners=False
+ )
+ patch_pos_embed = patch_pos_embed.flatten(2).transpose(1, 2)
+ scale_pos_embed = torch.cat((cls_pos_embed, patch_pos_embed, det_pos_embed), dim=1)
+ return scale_pos_embed
+
+
+class InterpolateMidPositionEmbeddings(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.config = config
+
+ def forward(self, pos_embed, img_size=(800, 1344)) -> torch.Tensor:
+ cls_pos_embed = pos_embed[:, :, 0, :]
+ cls_pos_embed = cls_pos_embed[:, None]
+ det_pos_embed = pos_embed[:, :, -self.config.num_detection_tokens :, :]
+ patch_pos_embed = pos_embed[:, :, 1 : -self.config.num_detection_tokens, :]
+ patch_pos_embed = patch_pos_embed.transpose(2, 3)
+ depth, batch_size, hidden_size, seq_len = patch_pos_embed.shape
+
+ patch_height, patch_width = (
+ self.config.image_size[0] // self.config.patch_size,
+ self.config.image_size[1] // self.config.patch_size,
+ )
+ patch_pos_embed = patch_pos_embed.view(depth * batch_size, hidden_size, patch_height, patch_width)
+ height, width = img_size
+ new_patch_height, new_patch_width = height // self.config.patch_size, width // self.config.patch_size
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed, size=(new_patch_height, new_patch_width), mode="bicubic", align_corners=False
+ )
+ patch_pos_embed = (
+ patch_pos_embed.flatten(2)
+ .transpose(1, 2)
+ .contiguous()
+ .view(depth, batch_size, new_patch_height * new_patch_width, hidden_size)
+ )
+ scale_pos_embed = torch.cat((cls_pos_embed, patch_pos_embed, det_pos_embed), dim=2)
+ return scale_pos_embed
+
+
+# Based on timm implementation, which can be found here:
+# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
+class PatchEmbeddings(nn.Module):
+ """
+ Image to Patch Embedding.
+
+ """
+
+ def __init__(
+ self,
+ image_size: int = 224,
+ patch_size: Union[int, Tuple[int, int]] = 16,
+ num_channels: int = 3,
+ embed_dim: int = 768,
+ ):
+ super().__init__()
+ image_size = to_2tuple(image_size)
+ patch_size = to_2tuple(patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_patches = num_patches
+
+ self.projection = nn.Conv2d(num_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViT->Yolos
+class YolosSelfAttention(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->Yolos
+class YolosSelfOutput(nn.Module):
+ """
+ The residual connection is defined in YolosLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->Yolos
+class YolosAttention(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.attention = YolosSelfAttention(config)
+ self.output = YolosSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->Yolos
+class YolosIntermediate(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->Yolos
+class YolosOutput(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->Yolos
+class YolosLayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = YolosAttention(config)
+ self.intermediate = YolosIntermediate(config)
+ self.output = YolosOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in Yolos, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in Yolos, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+class YolosEncoder(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([YolosLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ seq_length = (
+ 1 + (config.image_size[0] * config.image_size[1] // config.patch_size**2) + config.num_detection_tokens
+ )
+ self.mid_position_embeddings = (
+ nn.Parameter(
+ torch.zeros(
+ config.num_hidden_layers - 1,
+ 1,
+ seq_length,
+ config.hidden_size,
+ )
+ )
+ if config.use_mid_position_embeddings
+ else None
+ )
+
+ self.interpolation = InterpolateMidPositionEmbeddings(config) if config.use_mid_position_embeddings else None
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ height,
+ width,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ if self.config.use_mid_position_embeddings:
+ interpolated_mid_position_embeddings = self.interpolation(self.mid_position_embeddings, (height, width))
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if self.config.use_mid_position_embeddings:
+ if i < (self.config.num_hidden_layers - 1):
+ hidden_states = hidden_states + interpolated_mid_position_embeddings[i]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class YolosPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = YolosConfig
+ base_model_prefix = "vit"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module: YolosEncoder, value: bool = False) -> None:
+ if isinstance(module, YolosEncoder):
+ module.gradient_checkpointing = value
+
+
+YOLOS_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`YolosConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+YOLOS_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare YOLOS Model transformer outputting raw hidden-states without any specific head on top.",
+ YOLOS_START_DOCSTRING,
+)
+class YolosModel(YolosPreTrainedModel):
+ def __init__(self, config: YolosConfig, add_pooling_layer: bool = True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = YolosEmbeddings(config)
+ self.encoder = YolosEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.pooler = YolosPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> PatchEmbeddings:
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model.
+
+ Args:
+ heads_to_prune (`dict` of {layer_num: list of heads to prune in this layer}):
+ See base class `PreTrainedModel`.
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(YOLOS_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ height=pixel_values.shape[-2],
+ width=pixel_values.shape[-1],
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ head_outputs = (sequence_output, pooled_output) if pooled_output is not None else (sequence_output,)
+ return head_outputs + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class YolosPooler(nn.Module):
+ def __init__(self, config: YolosConfig):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+@add_start_docstrings(
+ """
+ YOLOS Model (consisting of a ViT encoder) with object detection heads on top, for tasks such as COCO detection.
+ """,
+ YOLOS_START_DOCSTRING,
+)
+class YolosForObjectDetection(YolosPreTrainedModel):
+ def __init__(self, config: YolosConfig):
+ super().__init__(config)
+
+ # YOLOS (ViT) encoder model
+ self.vit = YolosModel(config, add_pooling_layer=False)
+
+ # Object detection heads
+ # We add one for the "no object" class
+ self.class_labels_classifier = YolosMLPPredictionHead(
+ input_dim=config.hidden_size, hidden_dim=config.hidden_size, output_dim=config.num_labels + 1, num_layers=3
+ )
+ self.bbox_predictor = YolosMLPPredictionHead(
+ input_dim=config.hidden_size, hidden_dim=config.hidden_size, output_dim=4, num_layers=3
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # taken from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+ @torch.jit.unused
+ def _set_aux_loss(self, outputs_class, outputs_coord):
+ # this is a workaround to make torchscript happy, as torchscript
+ # doesn't support dictionary with non-homogeneous values, such
+ # as a dict having both a Tensor and a list.
+ return [{"logits": a, "pred_boxes": b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+
+ @add_start_docstrings_to_model_forward(YOLOS_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=YolosObjectDetectionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ labels=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`List[Dict]` of len `(batch_size,)`, *optional*):
+ Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the
+ following 2 keys: `'class_labels'` and `'boxes'` (the class labels and bounding boxes of an image in the
+ batch respectively). The class labels themselves should be a `torch.LongTensor` of len `(number of bounding
+ boxes in the image,)` and the boxes a `torch.FloatTensor` of shape `(number of bounding boxes in the image,
+ 4)`.
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import YolosFeatureExtractor, YolosForObjectDetection
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = YolosFeatureExtractor.from_pretrained("hustvl/yolos-small")
+ >>> model = YolosForObjectDetection.from_pretrained("hustvl/yolos-small")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+
+ >>> # model predicts bounding boxes and corresponding COCO classes
+ >>> logits = outputs.logits
+ >>> bboxes = outputs.pred_boxes
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # First, sent images through YOLOS base model to obtain hidden states
+ outputs = self.vit(
+ pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Take the final hidden states of the detection tokens
+ sequence_output = sequence_output[:, -self.config.num_detection_tokens :, :]
+
+ # Class logits + predicted bounding boxes
+ logits = self.class_labels_classifier(sequence_output)
+ pred_boxes = self.bbox_predictor(sequence_output).sigmoid()
+
+ loss, loss_dict, auxiliary_outputs = None, None, None
+ if labels is not None:
+ # First: create the matcher
+ matcher = YolosHungarianMatcher(
+ class_cost=self.config.class_cost, bbox_cost=self.config.bbox_cost, giou_cost=self.config.giou_cost
+ )
+ # Second: create the criterion
+ losses = ["labels", "boxes", "cardinality"]
+ criterion = YolosLoss(
+ matcher=matcher,
+ num_classes=self.config.num_labels,
+ eos_coef=self.config.eos_coefficient,
+ losses=losses,
+ )
+ criterion.to(self.device)
+ # Third: compute the losses, based on outputs and labels
+ outputs_loss = {}
+ outputs_loss["logits"] = logits
+ outputs_loss["pred_boxes"] = pred_boxes
+ if self.config.auxiliary_loss:
+ intermediate = outputs.intermediate_hidden_states if return_dict else outputs[4]
+ outputs_class = self.class_labels_classifier(intermediate)
+ outputs_coord = self.bbox_predictor(intermediate).sigmoid()
+ auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_loss["auxiliary_outputs"] = auxiliary_outputs
+
+ loss_dict = criterion(outputs_loss, labels)
+ # Fourth: compute total loss, as a weighted sum of the various losses
+ weight_dict = {"loss_ce": 1, "loss_bbox": self.config.bbox_loss_coefficient}
+ weight_dict["loss_giou"] = self.config.giou_loss_coefficient
+ if self.config.auxiliary_loss:
+ aux_weight_dict = {}
+ for i in range(self.config.decoder_layers - 1):
+ aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
+ weight_dict.update(aux_weight_dict)
+ loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
+
+ if not return_dict:
+ if auxiliary_outputs is not None:
+ output = (logits, pred_boxes) + auxiliary_outputs + outputs
+ else:
+ output = (logits, pred_boxes) + outputs
+ return ((loss, loss_dict) + output) if loss is not None else output
+
+ return YolosObjectDetectionOutput(
+ loss=loss,
+ loss_dict=loss_dict,
+ logits=logits,
+ pred_boxes=pred_boxes,
+ auxiliary_outputs=auxiliary_outputs,
+ last_hidden_state=outputs.last_hidden_state,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.detr.modeling_detr.dice_loss
+def dice_loss(inputs, targets, num_boxes):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.sigmoid_focal_loss
+def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
+ """
+ Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ alpha: (optional) Weighting factor in range (0,1) to balance
+ positive vs negative examples. Default = -1 (no weighting).
+ gamma: Exponent of the modulating factor (1 - p_t) to
+ balance easy vs hard examples.
+
+ Returns:
+ Loss tensor
+ """
+ prob = inputs.sigmoid()
+ ce_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+ p_t = prob * targets + (1 - prob) * (1 - targets)
+ loss = ce_loss * ((1 - p_t) ** gamma)
+
+ if alpha >= 0:
+ alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
+ loss = alpha_t * loss
+
+ return loss.mean(1).sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrLoss with Detr->Yolos
+class YolosLoss(nn.Module):
+ """
+ This class computes the losses for YolosForObjectDetection/YolosForSegmentation. The process happens in two steps:
+ 1) we compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each
+ pair of matched ground-truth / prediction (supervise class and box).
+
+ A note on the `num_classes` argument (copied from original repo in detr.py): "the naming of the `num_classes`
+ parameter of the criterion is somewhat misleading. It indeed corresponds to `max_obj_id` + 1, where `max_obj_id` is
+ the maximum id for a class in your dataset. For example, COCO has a `max_obj_id` of 90, so we pass `num_classes` to
+ be 91. As another example, for a dataset that has a single class with `id` 1, you should pass `num_classes` to be 2
+ (`max_obj_id` + 1). For more details on this, check the following discussion
+ https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
+
+
+ Args:
+ matcher (`YolosHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ eos_coef (`float`):
+ Relative classification weight applied to the no-object category.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
+ """
+
+ def __init__(self, matcher, num_classes, eos_coef, losses):
+ super().__init__()
+ self.matcher = matcher
+ self.num_classes = num_classes
+ self.eos_coef = eos_coef
+ self.losses = losses
+ empty_weight = torch.ones(self.num_classes + 1)
+ empty_weight[-1] = self.eos_coef
+ self.register_buffer("empty_weight", empty_weight)
+
+ # removed logging parameter, which was part of the original implementation
+ def loss_labels(self, outputs, targets, indices, num_boxes):
+ """
+ Classification loss (NLL) targets dicts must contain the key "class_labels" containing a tensor of dim
+ [nb_target_boxes]
+ """
+ if "logits" not in outputs:
+ raise KeyError("No logits were found in the outputs")
+ src_logits = outputs["logits"]
+
+ idx = self._get_src_permutation_idx(indices)
+ target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])
+ target_classes = torch.full(
+ src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device
+ )
+ target_classes[idx] = target_classes_o
+
+ loss_ce = nn.functional.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
+ losses = {"loss_ce": loss_ce}
+
+ return losses
+
+ @torch.no_grad()
+ def loss_cardinality(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the cardinality error, i.e. the absolute error in the number of predicted non-empty boxes.
+
+ This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients.
+ """
+ logits = outputs["logits"]
+ device = logits.device
+ tgt_lengths = torch.as_tensor([len(v["class_labels"]) for v in targets], device=device)
+ # Count the number of predictions that are NOT "no-object" (which is the last class)
+ card_pred = (logits.argmax(-1) != logits.shape[-1] - 1).sum(1)
+ card_err = nn.functional.l1_loss(card_pred.float(), tgt_lengths.float())
+ losses = {"cardinality_error": card_err}
+ return losses
+
+ def loss_boxes(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss.
+
+ Targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]. The target boxes
+ are expected in format (center_x, center_y, w, h), normalized by the image size.
+ """
+ if "pred_boxes" not in outputs:
+ raise KeyError("No predicted boxes found in outputs")
+ idx = self._get_src_permutation_idx(indices)
+ src_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ loss_bbox = nn.functional.l1_loss(src_boxes, target_boxes, reduction="none")
+
+ losses = {}
+ losses["loss_bbox"] = loss_bbox.sum() / num_boxes
+
+ loss_giou = 1 - torch.diag(
+ generalized_box_iou(center_to_corners_format(src_boxes), center_to_corners_format(target_boxes))
+ )
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ def loss_masks(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the masks: the focal loss and the dice loss.
+
+ Targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w].
+ """
+ if "pred_masks" not in outputs:
+ raise KeyError("No predicted masks found in outputs")
+
+ src_idx = self._get_src_permutation_idx(indices)
+ tgt_idx = self._get_tgt_permutation_idx(indices)
+ src_masks = outputs["pred_masks"]
+ src_masks = src_masks[src_idx]
+ masks = [t["masks"] for t in targets]
+ # TODO use valid to mask invalid areas due to padding in loss
+ target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
+ target_masks = target_masks.to(src_masks)
+ target_masks = target_masks[tgt_idx]
+
+ # upsample predictions to the target size
+ src_masks = nn.functional.interpolate(
+ src_masks[:, None], size=target_masks.shape[-2:], mode="bilinear", align_corners=False
+ )
+ src_masks = src_masks[:, 0].flatten(1)
+
+ target_masks = target_masks.flatten(1)
+ target_masks = target_masks.view(src_masks.shape)
+ losses = {
+ "loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
+ "loss_dice": dice_loss(src_masks, target_masks, num_boxes),
+ }
+ return losses
+
+ def _get_src_permutation_idx(self, indices):
+ # permute predictions following indices
+ batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
+ src_idx = torch.cat([src for (src, _) in indices])
+ return batch_idx, src_idx
+
+ def _get_tgt_permutation_idx(self, indices):
+ # permute targets following indices
+ batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
+ tgt_idx = torch.cat([tgt for (_, tgt) in indices])
+ return batch_idx, tgt_idx
+
+ def get_loss(self, loss, outputs, targets, indices, num_boxes):
+ loss_map = {
+ "labels": self.loss_labels,
+ "cardinality": self.loss_cardinality,
+ "boxes": self.loss_boxes,
+ "masks": self.loss_masks,
+ }
+ if loss not in loss_map:
+ raise ValueError(f"Loss {loss} not supported")
+ return loss_map[loss](outputs, targets, indices, num_boxes)
+
+ def forward(self, outputs, targets):
+ """
+ This performs the loss computation.
+
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
+ """
+ outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs"}
+
+ # Retrieve the matching between the outputs of the last layer and the targets
+ indices = self.matcher(outputs_without_aux, targets)
+
+ # Compute the average number of target boxes accross all nodes, for normalization purposes
+ num_boxes = sum(len(t["class_labels"]) for t in targets)
+ num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
+ # (Niels): comment out function below, distributed training to be added
+ # if is_dist_avail_and_initialized():
+ # torch.distributed.all_reduce(num_boxes)
+ # (Niels) in original implementation, num_boxes is divided by get_world_size()
+ num_boxes = torch.clamp(num_boxes, min=1).item()
+
+ # Compute all the requested losses
+ losses = {}
+ for loss in self.losses:
+ losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
+
+ # In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
+ if "auxiliary_outputs" in outputs:
+ for i, auxiliary_outputs in enumerate(outputs["auxiliary_outputs"]):
+ indices = self.matcher(auxiliary_outputs, targets)
+ for loss in self.losses:
+ if loss == "masks":
+ # Intermediate masks losses are too costly to compute, we ignore them.
+ continue
+ l_dict = self.get_loss(loss, auxiliary_outputs, targets, indices, num_boxes)
+ l_dict = {k + f"_{i}": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ return losses
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrMLPPredictionHead with Detr->Yolos
+class YolosMLPPredictionHead(nn.Module):
+ """
+ Very simple multi-layer perceptron (MLP, also called FFN), used to predict the normalized center coordinates,
+ height and width of a bounding box w.r.t. an image.
+
+ Copied from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+
+ """
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = nn.functional.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrHungarianMatcher with Detr->Yolos
+class YolosHungarianMatcher(nn.Module):
+ """
+ This class computes an assignment between the targets and the predictions of the network.
+
+ For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
+ predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
+ un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
+ """
+
+ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
+ super().__init__()
+ requires_backends(self, ["scipy"])
+
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ if class_cost == 0 or bbox_cost == 0 or giou_cost == 0:
+ raise ValueError("All costs of the Matcher can't be 0")
+
+ @torch.no_grad()
+ def forward(self, outputs, targets):
+ """
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
+
+ Returns:
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
+ For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
+ """
+ batch_size, num_queries = outputs["logits"].shape[:2]
+
+ # We flatten to compute the cost matrices in a batch
+ out_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
+ out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
+
+ # Also concat the target labels and boxes
+ tgt_ids = torch.cat([v["class_labels"] for v in targets])
+ tgt_bbox = torch.cat([v["boxes"] for v in targets])
+
+ # Compute the classification cost. Contrary to the loss, we don't use the NLL,
+ # but approximate it in 1 - proba[target class].
+ # The 1 is a constant that doesn't change the matching, it can be ommitted.
+ class_cost = -out_prob[:, tgt_ids]
+
+ # Compute the L1 cost between boxes
+ bbox_cost = torch.cdist(out_bbox, tgt_bbox, p=1)
+
+ # Compute the giou cost between boxes
+ giou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(tgt_bbox))
+
+ # Final cost matrix
+ cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
+
+ sizes = [len(v["boxes"]) for v in targets]
+ indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
+ return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t: Tensor) -> Tensor:
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+# Copied from transformers.models.detr.modeling_detr.box_area
+def box_area(boxes: Tensor) -> Tensor:
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+# Copied from transformers.models.detr.modeling_detr.box_iou
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+# Copied from transformers.models.detr.modeling_detr.generalized_box_iou
+def generalized_box_iou(boxes1, boxes2):
+ """
+ Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
+
+ Returns:
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+ iou, union = box_iou(boxes1, boxes2)
+
+ lt = torch.min(boxes1[:, None, :2], boxes2[:, :2])
+ rb = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])
+
+ wh = (rb - lt).clamp(min=0) # [N,M,2]
+ area = wh[:, :, 0] * wh[:, :, 1]
+
+ return iou - (area - union) / area
+
+
+# Copied from transformers.models.detr.modeling_detr._max_by_axis
+def _max_by_axis(the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+
+# Copied from transformers.models.detr.modeling_detr.NestedTensor
+class NestedTensor(object):
+ def __init__(self, tensors, mask: Optional[Tensor]):
+ self.tensors = tensors
+ self.mask = mask
+
+ def to(self, device):
+ cast_tensor = self.tensors.to(device)
+ mask = self.mask
+ if mask is not None:
+ cast_mask = mask.to(device)
+ else:
+ cast_mask = None
+ return NestedTensor(cast_tensor, cast_mask)
+
+ def decompose(self):
+ return self.tensors, self.mask
+
+ def __repr__(self):
+ return str(self.tensors)
+
+
+# Copied from transformers.models.detr.modeling_detr.nested_tensor_from_tensor_list
+def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
+ if tensor_list[0].ndim == 3:
+ max_size = _max_by_axis([list(img.shape) for img in tensor_list])
+ batch_shape = [len(tensor_list)] + max_size
+ b, c, h, w = batch_shape
+ dtype = tensor_list[0].dtype
+ device = tensor_list[0].device
+ tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
+ mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
+ for img, pad_img, m in zip(tensor_list, tensor, mask):
+ pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
+ m[: img.shape[1], : img.shape[2]] = False
+ else:
+ raise ValueError("Only 3-dimensional tensors are supported")
+ return NestedTensor(tensor, mask)
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 898848d5ba16e..112759671bbfe 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -4697,6 +4697,30 @@ def load_tf_weights_in_xlnet(*args, **kwargs):
requires_backends(load_tf_weights_in_xlnet, ["torch"])
+YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class YolosForObjectDetection(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class YolosModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class YolosPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
YOSO_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 6ffeeb52b3e8f..8ba819156143f 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -141,3 +141,10 @@ class ViTFeatureExtractor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class YolosFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/yolos/__init__.py b/tests/yolos/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/tests/yolos/test_feature_extraction_yolos.py b/tests/yolos/test_feature_extraction_yolos.py
new file mode 100644
index 0000000000000..4fc9217bbe036
--- /dev/null
+++ b/tests/yolos/test_feature_extraction_yolos.py
@@ -0,0 +1,336 @@
+# coding=utf-8
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_vision_available
+
+from ..test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import YolosFeatureExtractor
+
+
+class YolosFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.max_size = max_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "max_size": self.max_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to YolosFeatureExtractor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size * h / w)
+ expected_width = self.size
+ elif w > h:
+ expected_height = self.size
+ expected_width = int(self.size * w / h)
+ else:
+ expected_height = self.size
+ expected_width = self.size
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+
+@require_torch
+@require_vision
+class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = YolosFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = YolosFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "max_size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_equivalence_padding(self):
+ # Initialize feature_extractors
+ feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test whether the method "pad" and calling the feature extractor return the same tensors
+ encoded_images_with_method = feature_extractor_1.pad(image_inputs, return_tensors="pt")
+ encoded_images = feature_extractor_2(image_inputs, return_tensors="pt")
+
+ assert torch.allclose(encoded_images_with_method["pixel_values"], encoded_images["pixel_values"], atol=1e-4)
+
+ @slow
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ # encode them
+ feature_extractor = YolosFeatureExtractor.from_pretrained("hustvl/yolos-small")
+ encoding = feature_extractor(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ assert torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ assert torch.allclose(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ assert torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ assert torch.allclose(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ assert torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ assert torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ assert torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ assert torch.allclose(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ # encode them
+ feature_extractor = YolosFeatureExtractor(format="coco_panoptic")
+ encoding = feature_extractor(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ assert torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ assert torch.allclose(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ assert torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ assert torch.allclose(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ assert torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ assert torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822338
+ self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ assert torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ assert torch.allclose(encoding["labels"][0]["size"], expected_size)
diff --git a/tests/yolos/test_modeling_yolos.py b/tests/yolos/test_modeling_yolos.py
new file mode 100644
index 0000000000000..e64795b1ea011
--- /dev/null
+++ b/tests/yolos/test_modeling_yolos.py
@@ -0,0 +1,373 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch YOLOS model. """
+
+
+import inspect
+import unittest
+
+from transformers import YolosConfig
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ..test_configuration_common import ConfigTester
+from ..test_modeling_common import ModelTesterMixin, floats_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import YolosForObjectDetection, YolosModel
+ from transformers.models.yolos.modeling_yolos import YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoFeatureExtractor
+
+
+class YolosModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=[30, 30],
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ n_targets=8,
+ num_detection_tokens=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+ self.n_targets = n_targets
+ self.num_detection_tokens = num_detection_tokens
+ # we set the expected sequence length (which is used in several tests)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token) + num_detection_tokens
+ image_size = to_2tuple(self.image_size)
+ patch_size = to_2tuple(self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.expected_seq_len = num_patches + 1 + self.num_detection_tokens
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size[0], self.image_size[1]])
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return YolosConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ num_detection_tokens=self.num_detection_tokens,
+ num_labels=self.num_labels,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = YolosModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.expected_seq_len, self.hidden_size)
+ )
+
+ def create_and_check_for_object_detection(self, config, pixel_values, labels):
+ model = YolosForObjectDetection(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_detection_tokens, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_detection_tokens, 4))
+
+ result = model(pixel_values=pixel_values, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_detection_tokens, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_detection_tokens, 4))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class YolosModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as YOLOS does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (YolosModel, YolosForObjectDetection) if is_torch_available() else ()
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torchscript = False
+
+ # special case for head model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "YolosForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = YolosModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=YolosConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_inputs_embeds(self):
+ # YOLOS does not use inputs_embeds
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ # in YOLOS, the seq_len is different
+ seq_len = self.model_tester.expected_seq_len
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # YOLOS has a different seq_length
+ seq_length = self.model_tester.expected_seq_len
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_for_object_detection(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_object_detection(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = YolosModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class YolosModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return AutoFeatureExtractor.from_pretrained("hustvl/yolos-small") if is_vision_available() else None
+
+ @slow
+ def test_inference_object_detection_head(self):
+ model = YolosForObjectDetection.from_pretrained("hustvl/yolos-small").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(inputs.pixel_values)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 100, 92))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice_logits = torch.tensor(
+ [[-24.0248, -10.3024, -14.8290], [-42.0392, -16.8200, -27.4334], [-27.2743, -11.8154, -18.7148]],
+ device=torch_device,
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.2559, 0.5455, 0.4706], [0.2989, 0.7279, 0.1875], [0.7732, 0.4017, 0.4462]], device=torch_device
+ )
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice_logits, atol=1e-4))
+ self.assertTrue(torch.allclose(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, atol=1e-4))
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 12ca41b413a0a..05119b292cbfc 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -18,6 +18,7 @@ src/transformers/models/big_bird/modeling_big_bird.py
src/transformers/models/blenderbot/modeling_blenderbot.py
src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
src/transformers/models/convnext/modeling_convnext.py
+src/transformers/models/ctrl/modeling_ctrl.py
src/transformers/models/data2vec/modeling_data2vec_audio.py
src/transformers/models/data2vec/modeling_data2vec_vision.py
src/transformers/models/deit/modeling_deit.py
@@ -58,5 +59,5 @@ src/transformers/models/vit_mae/modeling_vit_mae.py
src/transformers/models/wav2vec2/modeling_wav2vec2.py
src/transformers/models/wav2vec2/tokenization_wav2vec2.py
src/transformers/models/wav2vec2_with_lm/processing_wav2vec2_with_lm.py
-src/transformers/models/wavlm/modeling_wavlm.py
-src/transformers/models/ctrl/modeling_ctrl.py
+src/transformers/models/wavlm/modeling_wavlm.py
+src/transformers/models/yolos/modeling_yolos.py
+
+ YOLOS architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+
+## YolosConfig
+
+[[autodoc]] YolosConfig
+
+
+## YolosFeatureExtractor
+
+[[autodoc]] YolosFeatureExtractor
+ - __call__
+ - pad
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+
+## YolosModel
+
+[[autodoc]] YolosModel
+ - forward
+
+
+## YolosForObjectDetection
+
+[[autodoc]] YolosForObjectDetection
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 5695ff57c53b0..05c11d4c54da0 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -320,6 +320,7 @@
"models.xlm_roberta": ["XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLMRobertaConfig"],
"models.xlm_roberta_xl": ["XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLMRobertaXLConfig"],
"models.xlnet": ["XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP", "XLNetConfig"],
+ "models.yolos": ["YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP", "YolosConfig"],
"models.yoso": ["YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP", "YosoConfig"],
"onnx": [],
"pipelines": [
@@ -551,6 +552,7 @@
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
_import_structure["models.vit"].append("ViTFeatureExtractor")
+ _import_structure["models.yolos"].append("YolosFeatureExtractor")
else:
from .utils import dummy_vision_objects
@@ -1681,6 +1683,14 @@
"load_tf_weights_in_xlnet",
]
)
+ _import_structure["models.yolos"].extend(
+ [
+ "YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "YolosForObjectDetection",
+ "YolosModel",
+ "YolosPreTrainedModel",
+ ]
+ )
_import_structure["models.yoso"].extend(
[
"YOSO_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2696,6 +2706,7 @@
from .models.xlm_roberta import XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP, XLMRobertaConfig
from .models.xlm_roberta_xl import XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP, XLMRobertaXLConfig
from .models.xlnet import XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP, XLNetConfig
+ from .models.yolos import YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP, YolosConfig
from .models.yoso import YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP, YosoConfig
# Pipelines
@@ -2901,6 +2912,7 @@
from .models.segformer import SegformerFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
+ from .models.yolos import YolosFeatureExtractor
else:
from .utils.dummy_vision_objects import *
@@ -3831,6 +3843,12 @@
XLNetPreTrainedModel,
load_tf_weights_in_xlnet,
)
+ from .models.yolos import (
+ YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST,
+ YolosForObjectDetection,
+ YolosModel,
+ YolosPreTrainedModel,
+ )
from .models.yoso import (
YOSO_PRETRAINED_MODEL_ARCHIVE_LIST,
YosoForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index d21f2789b3d78..8697e4333d67d 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -135,5 +135,6 @@
xlm_roberta,
xlm_roberta_xl,
xlnet,
+ yolos,
yoso,
)
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 210199aec8185..0eaa838d47024 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -29,6 +29,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("yolos", "YolosConfig"),
("tapex", "BartConfig"),
("dpt", "DPTConfig"),
("decision_transformer", "DecisionTransformerConfig"),
@@ -138,6 +139,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here)
+ ("yolos", "YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("dpt", "DPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("glpn", "GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("maskformer", "MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -231,6 +233,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("yolos", "YOLOS"),
("tapex", "TAPEX"),
("dpt", "DPT"),
("decision_transformer", "Decision Transformer"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 79ebbf8015ec7..d385d8cfd3b2f 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -61,6 +61,7 @@
("data2vec-vision", "BeitFeatureExtractor"),
("dpt", "DPTFeatureExtractor"),
("glpn", "GLPNFeatureExtractor"),
+ ("yolos", "YolosFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 78d32ad070891..13f1070c6cc6a 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("yolos", "YolosModel"),
("dpt", "DPTModel"),
("decision_transformer", "DecisionTransformerModel"),
("glpn", "GLPNModel"),
@@ -386,6 +387,7 @@
MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
[
# Model for Object Detection mapping
+ ("yolos", "YolosForObjectDetection"),
("detr", "DetrForObjectDetection"),
]
)
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index b787aebc8aa6f..64f8190d62974 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -1865,30 +1865,31 @@ class DetrLoss(nn.Module):
"""
This class computes the losses for DetrForObjectDetection/DetrForSegmentation. The process happens in two steps: 1)
we compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each pair
- of matched ground-truth / prediction (supervise class and box)
+ of matched ground-truth / prediction (supervise class and box).
+
+ A note on the `num_classes` argument (copied from original repo in detr.py): "the naming of the `num_classes`
+ parameter of the criterion is somewhat misleading. It indeed corresponds to `max_obj_id` + 1, where `max_obj_id` is
+ the maximum id for a class in your dataset. For example, COCO has a `max_obj_id` of 90, so we pass `num_classes` to
+ be 91. As another example, for a dataset that has a single class with `id` 1, you should pass `num_classes` to be 2
+ (`max_obj_id` + 1). For more details on this, check the following discussion
+ https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
+
+
+ Args:
+ matcher (`DetrHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ eos_coef (`float`):
+ Relative classification weight applied to the no-object category.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
"""
def __init__(self, matcher, num_classes, eos_coef, losses):
- """
- Create the criterion.
-
- A note on the num_classes parameter (copied from original repo in detr.py): "the naming of the `num_classes`
- parameter of the criterion is somewhat misleading. it indeed corresponds to `max_obj_id + 1`, where max_obj_id
- is the maximum id for a class in your dataset. For example, COCO has a max_obj_id of 90, so we pass
- `num_classes` to be 91. As another example, for a dataset that has a single class with id 1, you should pass
- `num_classes` to be 2 (max_obj_id + 1). For more details on this, check the following discussion
- https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
-
- Parameters:
- matcher: module able to compute a matching between targets and proposals.
- num_classes: number of object categories, omitting the special no-object category.
- weight_dict: dict containing as key the names of the losses and as values their relative weight.
- eos_coef: relative classification weight applied to the no-object category.
- losses: list of all the losses to be applied. See get_loss for list of available losses.
- """
super().__init__()
- self.num_classes = num_classes
self.matcher = matcher
+ self.num_classes = num_classes
self.eos_coef = eos_coef
self.losses = losses
empty_weight = torch.ones(self.num_classes + 1)
@@ -2017,10 +2018,12 @@ def forward(self, outputs, targets):
"""
This performs the loss computation.
- Parameters:
- outputs: dict of tensors, see the output specification of the model for the format
- targets: list of dicts, such that len(targets) == batch_size.
- The expected keys in each dict depends on the losses applied, see each loss' doc
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs"}
@@ -2086,20 +2089,18 @@ class DetrHungarianMatcher(nn.Module):
For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
"""
def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
- """
- Creates the matcher.
-
- Params:
- class_cost: This is the relative weight of the classification error in the matching cost
- bbox_cost:
- This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
- giou_cost: This is the relative weight of the giou loss of the bounding box in the matching cost
- """
super().__init__()
-
requires_backends(self, ["scipy"])
self.class_cost = class_cost
@@ -2111,25 +2112,25 @@ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float
@torch.no_grad()
def forward(self, outputs, targets):
"""
- Performs the matching.
-
- Params:
- outputs: This is a dict that contains at least these entries:
- "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
- "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
- targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
- "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
- objects in the target) containing the class labels "boxes": Tensor of dim [num_target_boxes, 4]
- containing the target box coordinates
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
Returns:
- A list of size batch_size, containing tuples of (index_i, index_j) where:
-
- - index_i is the indices of the selected predictions (in order)
- - index_j is the indices of the corresponding selected targets (in order)
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
- bs, num_queries = outputs["logits"].shape[:2]
+ batch_size, num_queries = outputs["logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
@@ -2152,7 +2153,7 @@ def forward(self, outputs, targets):
# Final cost matrix
cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
- cost_matrix = cost_matrix.view(bs, num_queries, -1).cpu()
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
@@ -2175,11 +2176,12 @@ def box_area(boxes: Tensor) -> Tensor:
Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
Args:
- boxes (Tensor[N, 4]): boxes for which the area will be computed. They
- are expected to be in (x1, y1, x2, y2) format with `0 <= x1 < x2` and `0 <= y1 < y2`.
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
Returns:
- area (Tensor[N]): area for each box
+ `torch.FloatTensor`: a tensor containing the area for each box.
"""
boxes = _upcast(boxes)
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
@@ -2190,11 +2192,11 @@ def box_iou(boxes1, boxes2):
area1 = box_area(boxes1)
area2 = box_area(boxes2)
- lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
- rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
- wh = (rb - lt).clamp(min=0) # [N,M,2]
- inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
union = area1[:, None] + area2 - inter
@@ -2207,7 +2209,7 @@ def generalized_box_iou(boxes1, boxes2):
Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
Returns:
- a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
"""
# degenerate boxes gives inf / nan results
# so do an early check
@@ -2242,7 +2244,6 @@ def __init__(self, tensors, mask: Optional[Tensor]):
self.mask = mask
def to(self, device):
- # type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
diff --git a/src/transformers/models/yolos/__init__.py b/src/transformers/models/yolos/__init__.py
new file mode 100644
index 0000000000000..fcdf387c68d6e
--- /dev/null
+++ b/src/transformers/models/yolos/__init__.py
@@ -0,0 +1,57 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_yolos": ["YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP", "YolosConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_yolos"] = ["YolosFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_yolos"] = [
+ "YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "YolosForObjectDetection",
+ "YolosModel",
+ "YolosPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_yolos import YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP, YolosConfig
+
+ if is_vision_available():
+ from .feature_extraction_yolos import YolosFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_yolos import (
+ YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST,
+ YolosForObjectDetection,
+ YolosModel,
+ YolosPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/yolos/configuration_yolos.py b/src/transformers/models/yolos/configuration_yolos.py
new file mode 100644
index 0000000000000..cd3414a7f26ee
--- /dev/null
+++ b/src/transformers/models/yolos/configuration_yolos.py
@@ -0,0 +1,153 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" YOLOS model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "hustvl/yolos-small": "https://huggingface.co/hustvl/yolos-small/resolve/main/config.json",
+ # See all YOLOS models at https://huggingface.co/models?filter=yolos
+}
+
+
+class YolosConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`YolosModel`]. It is used to instantiate a YOLOS
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the YOLOS
+ [hustvl/yolos-base](https://huggingface.co/hustvl/yolos-base) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ image_size (`List[int]`, *optional*, defaults to `[512, 864]`):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to `16`):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to `3`):
+ The number of input channels.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ num_detection_tokens (`int`, *optional*, defaults to `100`):
+ The number of detection tokens.
+ use_mid_position_embeddings (`bool`, *optional*, defaults to `True`):
+ Whether to use the mid-layer position encodings.
+ auxiliary_loss (`bool`, *optional*, defaults to `False`):
+ Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
+ class_cost (`float`, *optional*, defaults to 1):
+ Relative weight of the classification error in the Hungarian matching cost.
+ bbox_cost (`float`, *optional*, defaults to 5):
+ Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost.
+ giou_cost (`float`, *optional*, defaults to 2):
+ Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost.
+ bbox_loss_coefficient (`float`, *optional*, defaults to 5):
+ Relative weight of the L1 bounding box loss in the object detection loss.
+ giou_loss_coefficient (`float`, *optional*, defaults to 2):
+ Relative weight of the generalized IoU loss in the object detection loss.
+ eos_coefficient (`float`, *optional*, defaults to 0.1):
+ Relative classification weight of the 'no-object' class in the object detection loss.
+
+ Example:
+
+ ```python
+ >>> from transformers import YolosModel, YolosConfig
+
+ >>> # Initializing a YOLOS hustvl/yolos-base style configuration
+ >>> configuration = YolosConfig()
+
+ >>> # Initializing a model from the hustvl/yolos-base style configuration
+ >>> model = YolosModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "yolos"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ image_size=[512, 864],
+ patch_size=16,
+ num_channels=3,
+ qkv_bias=True,
+ num_detection_tokens=100,
+ use_mid_position_embeddings=True,
+ auxiliary_loss=False,
+ class_cost=1,
+ bbox_cost=5,
+ giou_cost=2,
+ bbox_loss_coefficient=5,
+ giou_loss_coefficient=2,
+ eos_coefficient=0.1,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.qkv_bias = qkv_bias
+ self.num_detection_tokens = num_detection_tokens
+ self.use_mid_position_embeddings = use_mid_position_embeddings
+ self.auxiliary_loss = auxiliary_loss
+ # Hungarian matcher
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ # Loss coefficients
+ self.bbox_loss_coefficient = bbox_loss_coefficient
+ self.giou_loss_coefficient = giou_loss_coefficient
+ self.eos_coefficient = eos_coefficient
diff --git a/src/transformers/models/yolos/convert_yolos_to_pytorch.py b/src/transformers/models/yolos/convert_yolos_to_pytorch.py
new file mode 100644
index 0000000000000..add0ae772db13
--- /dev/null
+++ b/src/transformers/models/yolos/convert_yolos_to_pytorch.py
@@ -0,0 +1,263 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert YOLOS checkpoints from the original repository. URL: https://github.com/hustvl/YOLOS"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import hf_hub_download
+from transformers import YolosConfig, YolosFeatureExtractor, YolosForObjectDetection
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_yolos_config(yolos_name):
+ config = YolosConfig()
+
+ # size of the architecture
+ if "yolos_ti" in yolos_name:
+ config.hidden_size = 192
+ config.intermediate_size = 768
+ config.num_hidden_layers = 12
+ config.num_attention_heads = 3
+ config.image_size = [800, 1333]
+ config.use_mid_position_embeddings = False
+ elif yolos_name == "yolos_s_dWr":
+ config.hidden_size = 330
+ config.num_hidden_layers = 14
+ config.num_attention_heads = 6
+ config.intermediate_size = 1320
+ elif "yolos_s" in yolos_name:
+ config.hidden_size = 384
+ config.intermediate_size = 1536
+ config.num_hidden_layers = 12
+ config.num_attention_heads = 6
+ elif "yolos_b" in yolos_name:
+ config.image_size = [800, 1344]
+
+ config.num_labels = 91
+ repo_id = "datasets/huggingface/label-files"
+ filename = "coco-detection-id2label.json"
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v(state_dict, config, base_model=False):
+ for i in range(config.num_hidden_layers):
+ # read in weights + bias of input projection layer (in timm, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"blocks.{i}.attn.qkv.weight")
+ in_proj_bias = state_dict.pop(f"blocks.{i}.attn.qkv.bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[: config.hidden_size, :]
+ state_dict[f"encoder.layer.{i}.attention.attention.query.bias"] = in_proj_bias[: config.hidden_size]
+ state_dict[f"encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
+ config.hidden_size : config.hidden_size * 2, :
+ ]
+ state_dict[f"encoder.layer.{i}.attention.attention.key.bias"] = in_proj_bias[
+ config.hidden_size : config.hidden_size * 2
+ ]
+ state_dict[f"encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[-config.hidden_size :, :]
+ state_dict[f"encoder.layer.{i}.attention.attention.value.bias"] = in_proj_bias[-config.hidden_size :]
+
+
+def rename_key(name):
+ if "backbone" in name:
+ name = name.replace("backbone", "vit")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "embeddings.cls_token")
+ if "det_token" in name:
+ name = name.replace("det_token", "embeddings.detection_tokens")
+ if "mid_pos_embed" in name:
+ name = name.replace("mid_pos_embed", "encoder.mid_position_embeddings")
+ if "pos_embed" in name:
+ name = name.replace("pos_embed", "embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ if "blocks" in name:
+ name = name.replace("blocks", "encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "class_embed" in name:
+ name = name.replace("class_embed", "class_labels_classifier")
+ if "bbox_embed" in name:
+ name = name.replace("bbox_embed", "bbox_predictor")
+ if "vit.norm" in name:
+ name = name.replace("vit.norm", "vit.layernorm")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, model):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[2])
+ dim = model.vit.encoder.layer[layer_num].attention.attention.all_head_size
+ if "weight" in key:
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.key.weight"] = val[
+ dim : dim * 2, :
+ ]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.query.bias"] = val[:dim]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.key.bias"] = val[dim : dim * 2]
+ orig_state_dict[f"vit.encoder.layer.{layer_num}.attention.attention.value.bias"] = val[-dim:]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@torch.no_grad()
+def convert_yolos_checkpoint(yolos_name, checkpoint_path, pytorch_dump_folder_path, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our YOLOS structure.
+ """
+ config = get_yolos_config(yolos_name)
+
+ # load original state_dict
+ state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
+
+ # load 🤗 model
+ model = YolosForObjectDetection(config)
+ model.eval()
+ new_state_dict = convert_state_dict(state_dict, model)
+ model.load_state_dict(new_state_dict)
+
+ # Check outputs on an image, prepared by YolosFeatureExtractor
+ size = 800 if yolos_name != "yolos_ti" else 512
+ feature_extractor = YolosFeatureExtractor(format="coco_detection", size=size)
+ encoding = feature_extractor(images=prepare_img(), return_tensors="pt")
+ outputs = model(**encoding)
+ logits, pred_boxes = outputs.logits, outputs.pred_boxes
+
+ expected_slice_logits, expected_slice_boxes = None, None
+ if yolos_name == "yolos_ti":
+ expected_slice_logits = torch.tensor(
+ [[-39.5022, -11.9820, -17.6888], [-29.9574, -9.9769, -17.7691], [-42.3281, -20.7200, -30.6294]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.4021, 0.0836, 0.7979], [0.0184, 0.2609, 0.0364], [0.1781, 0.2004, 0.2095]]
+ )
+ elif yolos_name == "yolos_s_200_pre":
+ expected_slice_logits = torch.tensor(
+ [[-24.0248, -10.3024, -14.8290], [-42.0392, -16.8200, -27.4334], [-27.2743, -11.8154, -18.7148]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.2559, 0.5455, 0.4706], [0.2989, 0.7279, 0.1875], [0.7732, 0.4017, 0.4462]]
+ )
+ elif yolos_name == "yolos_s_300_pre":
+ expected_slice_logits = torch.tensor(
+ [[-36.2220, -14.4385, -23.5457], [-35.6970, -14.7583, -21.3935], [-31.5939, -13.6042, -16.8049]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.7614, 0.2316, 0.4728], [0.7168, 0.4495, 0.3855], [0.4996, 0.1466, 0.9996]]
+ )
+ elif yolos_name == "yolos_s_dWr":
+ expected_slice_logits = torch.tensor(
+ [[-42.8668, -24.1049, -41.1690], [-34.7456, -14.1274, -24.9194], [-33.7898, -12.1946, -25.6495]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.5587, 0.2773, 0.0605], [0.5004, 0.3014, 0.9994], [0.4999, 0.1548, 0.9994]]
+ )
+ elif yolos_name == "yolos_base":
+ expected_slice_logits = torch.tensor(
+ [[-40.6064, -24.3084, -32.6447], [-55.1990, -30.7719, -35.5877], [-51.4311, -33.3507, -35.6462]]
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.5555, 0.2794, 0.0655], [0.9049, 0.2664, 0.1894], [0.9183, 0.1984, 0.1635]]
+ )
+ else:
+ raise ValueError(f"Unknown yolos_name: {yolos_name}")
+
+ assert torch.allclose(logits[0, :3, :3], expected_slice_logits, atol=1e-4)
+ assert torch.allclose(pred_boxes[0, :3, :3], expected_slice_boxes, atol=1e-4)
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {yolos_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model_mapping = {
+ "yolos_ti": "yolos-tiny",
+ "yolos_s_200_pre": "yolos-small",
+ "yolos_s_300_pre": "yolos-small-300",
+ "yolos_s_dWr": "yolos-small-dwr",
+ "yolos_base": "yolos-base",
+ }
+
+ print("Pushing to the hub...")
+ model_name = model_mapping[yolos_name]
+ feature_extractor.push_to_hub(model_name, organization="hustvl")
+ model.push_to_hub(model_name, organization="hustvl")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--yolos_name",
+ default="yolos_s_200_pre",
+ type=str,
+ help="Name of the YOLOS model you'd like to convert. Should be one of 'yolos_ti', 'yolos_s_200_pre', 'yolos_s_300_pre', 'yolos_s_dWr', 'yolos_base'.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, help="Path to the original state dict (.pth file)."
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_yolos_checkpoint(args.yolos_name, args.checkpoint_path, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/yolos/feature_extraction_yolos.py b/src/transformers/models/yolos/feature_extraction_yolos.py
new file mode 100644
index 0000000000000..76b64ec837753
--- /dev/null
+++ b/src/transformers/models/yolos/feature_extraction_yolos.py
@@ -0,0 +1,916 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for YOLOS."""
+
+import io
+import pathlib
+from collections import defaultdict
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import ImageFeatureExtractionMixin, is_torch_tensor
+from ...utils import TensorType, is_torch_available, logging
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+logger = logging.get_logger(__name__)
+
+
+ImageInput = Union[Image.Image, np.ndarray, "torch.Tensor", List[Image.Image], List[np.ndarray], List["torch.Tensor"]]
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.center_to_corners_format
+def center_to_corners_format(x):
+ """
+ Converts a PyTorch tensor of bounding boxes of center format (center_x, center_y, width, height) to corners format
+ (x_0, y_0, x_1, y_1).
+ """
+ x_c, y_c, w, h = x.unbind(-1)
+ b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
+ return torch.stack(b, dim=-1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.corners_to_center_format
+def corners_to_center_format(x):
+ """
+ Converts a NumPy array of bounding boxes of shape (number of bounding boxes, 4) of corners format (x_0, y_0, x_1,
+ y_1) to center format (center_x, center_y, width, height).
+ """
+ x_transposed = x.T
+ x0, y0, x1, y1 = x_transposed[0], x_transposed[1], x_transposed[2], x_transposed[3]
+ b = [(x0 + x1) / 2, (y0 + y1) / 2, (x1 - x0), (y1 - y0)]
+ return np.stack(b, axis=-1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.masks_to_boxes
+def masks_to_boxes(masks):
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ The masks should be in format [N, H, W] where N is the number of masks, (H, W) are the spatial dimensions.
+
+ Returns a [N, 4] tensor, with the boxes in corner (xyxy) format.
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.rgb_to_id
+def rgb_to_id(color):
+ if isinstance(color, np.ndarray) and len(color.shape) == 3:
+ if color.dtype == np.uint8:
+ color = color.astype(np.int32)
+ return color[:, :, 0] + 256 * color[:, :, 1] + 256 * 256 * color[:, :, 2]
+ return int(color[0] + 256 * color[1] + 256 * 256 * color[2])
+
+
+# Copied from transformers.models.detr.feature_extraction_detr.id_to_rgb
+def id_to_rgb(id_map):
+ if isinstance(id_map, np.ndarray):
+ id_map_copy = id_map.copy()
+ rgb_shape = tuple(list(id_map.shape) + [3])
+ rgb_map = np.zeros(rgb_shape, dtype=np.uint8)
+ for i in range(3):
+ rgb_map[..., i] = id_map_copy % 256
+ id_map_copy //= 256
+ return rgb_map
+ color = []
+ for _ in range(3):
+ color.append(id_map % 256)
+ id_map //= 256
+ return color
+
+
+class YolosFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a YOLOS feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+
+ Args:
+ format (`str`, *optional*, defaults to `"coco_detection"`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the input to a certain `size`.
+ size (`int`, *optional*, defaults to 800):
+ Resize the input to the given size. Only has an effect if `do_resize` is set to `True`. If size is a
+ sequence like `(width, height)`, output size will be matched to this. If size is an int, smaller edge of
+ the image will be matched to this number. i.e, if `height > width`, then image will be rescaled to `(size *
+ height / width, size)`.
+ max_size (`int`, *optional*, defaults to `1333`):
+ The largest size an image dimension can have (otherwise it's capped). Only has an effect if `do_resize` is
+ set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`int`, *optional*, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images. Defaults to the ImageNet mean.
+ image_std (`int`, *optional*, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images. Defaults to the
+ ImageNet std.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.__init__
+ def __init__(
+ self,
+ format="coco_detection",
+ do_resize=True,
+ size=800,
+ max_size=1333,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.format = self._is_valid_format(format)
+ self.do_resize = do_resize
+ self.size = size
+ self.max_size = max_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else [0.485, 0.456, 0.406] # ImageNet mean
+ self.image_std = image_std if image_std is not None else [0.229, 0.224, 0.225] # ImageNet std
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._is_valid_format
+ def _is_valid_format(self, format):
+ if format not in ["coco_detection", "coco_panoptic"]:
+ raise ValueError(f"Format {format} not supported")
+ return format
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare
+ def prepare(self, image, target, return_segmentation_masks=False, masks_path=None):
+ if self.format == "coco_detection":
+ image, target = self.prepare_coco_detection(image, target, return_segmentation_masks)
+ return image, target
+ elif self.format == "coco_panoptic":
+ image, target = self.prepare_coco_panoptic(image, target, masks_path)
+ return image, target
+ else:
+ raise ValueError(f"Format {self.format} not supported")
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, segmentations, height, width):
+
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_detection
+ def prepare_coco_detection(self, image, target, return_segmentation_masks=False):
+ """
+ Convert the target in COCO format into the format expected by DETR.
+ """
+ w, h = image.size
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # get all COCO annotations for the given image
+ anno = target["annotations"]
+
+ anno = [obj for obj in anno if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ boxes = [obj["bbox"] for obj in anno]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=w)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=h)
+
+ classes = [obj["category_id"] for obj in anno]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ if return_segmentation_masks:
+ segmentations = [obj["segmentation"] for obj in anno]
+ masks = self.convert_coco_poly_to_mask(segmentations, h, w)
+
+ keypoints = None
+ if anno and "keypoints" in anno[0]:
+ keypoints = [obj["keypoints"] for obj in anno]
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ num_keypoints = keypoints.shape[0]
+ if num_keypoints:
+ keypoints = keypoints.reshape((-1, 3))
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+ boxes = boxes[keep]
+ classes = classes[keep]
+ if return_segmentation_masks:
+ masks = masks[keep]
+ if keypoints is not None:
+ keypoints = keypoints[keep]
+
+ target = {}
+ target["boxes"] = boxes
+ target["class_labels"] = classes
+ if return_segmentation_masks:
+ target["masks"] = masks
+ target["image_id"] = image_id
+ if keypoints is not None:
+ target["keypoints"] = keypoints
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in anno], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno], dtype=np.int64)
+ target["area"] = area[keep]
+ target["iscrowd"] = iscrowd[keep]
+
+ target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+
+ return image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, image, target, masks_path, return_masks=True):
+ w, h = image.size
+ ann_info = target.copy()
+ ann_path = pathlib.Path(masks_path) / ann_info["file_name"]
+
+ if "segments_info" in ann_info:
+ masks = np.asarray(Image.open(ann_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([ann["id"] for ann in ann_info["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = np.asarray(masks, dtype=np.uint8)
+
+ labels = np.asarray([ann["category_id"] for ann in ann_info["segments_info"]], dtype=np.int64)
+
+ target = {}
+ target["image_id"] = np.asarray(
+ [ann_info["image_id"] if "image_id" in ann_info else ann_info["id"]], dtype=np.int64
+ )
+ if return_masks:
+ target["masks"] = masks
+ target["class_labels"] = labels
+
+ target["boxes"] = masks_to_boxes(masks)
+
+ target["size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ target["orig_size"] = np.asarray([int(h), int(w)], dtype=np.int64)
+ if "segments_info" in ann_info:
+ target["iscrowd"] = np.asarray([ann["iscrowd"] for ann in ann_info["segments_info"]], dtype=np.int64)
+ target["area"] = np.asarray([ann["area"] for ann in ann_info["segments_info"]], dtype=np.float32)
+
+ return image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._resize
+ def _resize(self, image, size, target=None, max_size=None):
+ """
+ Resize the image to the given size. Size can be min_size (scalar) or (w, h) tuple. If size is an int, smaller
+ edge of the image will be matched to this number.
+
+ If given, also resize the target accordingly.
+ """
+ if not isinstance(image, Image.Image):
+ image = self.to_pil_image(image)
+
+ def get_size_with_aspect_ratio(image_size, size, max_size=None):
+ w, h = image_size
+ if max_size is not None:
+ min_original_size = float(min((w, h)))
+ max_original_size = float(max((w, h)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (w <= h and w == size) or (h <= w and h == size):
+ return (h, w)
+
+ if w < h:
+ ow = size
+ oh = int(size * h / w)
+ else:
+ oh = size
+ ow = int(size * w / h)
+
+ return (oh, ow)
+
+ def get_size(image_size, size, max_size=None):
+ if isinstance(size, (list, tuple)):
+ return size
+ else:
+ # size returned must be (w, h) since we use PIL to resize images
+ # so we revert the tuple
+ return get_size_with_aspect_ratio(image_size, size, max_size)[::-1]
+
+ size = get_size(image.size, size, max_size)
+ rescaled_image = self.resize(image, size=size)
+
+ if target is None:
+ return rescaled_image, None
+
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
+ ratio_width, ratio_height = ratios
+
+ target = target.copy()
+ if "boxes" in target:
+ boxes = target["boxes"]
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ target["boxes"] = scaled_boxes
+
+ if "area" in target:
+ area = target["area"]
+ scaled_area = area * (ratio_width * ratio_height)
+ target["area"] = scaled_area
+
+ w, h = size
+ target["size"] = np.asarray([h, w], dtype=np.int64)
+
+ if "masks" in target:
+ # use PyTorch as current workaround
+ # TODO replace by self.resize
+ masks = torch.from_numpy(target["masks"][:, None]).float()
+ interpolated_masks = nn.functional.interpolate(masks, size=(h, w), mode="nearest")[:, 0] > 0.5
+ target["masks"] = interpolated_masks.numpy()
+
+ return rescaled_image, target
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._normalize
+ def _normalize(self, image, mean, std, target=None):
+ """
+ Normalize the image with a certain mean and std.
+
+ If given, also normalize the target bounding boxes based on the size of the image.
+ """
+
+ image = self.normalize(image, mean=mean, std=std)
+ if target is None:
+ return image, None
+
+ target = target.copy()
+ h, w = image.shape[-2:]
+
+ if "boxes" in target:
+ boxes = target["boxes"]
+ boxes = corners_to_center_format(boxes)
+ boxes = boxes / np.asarray([w, h, w, h], dtype=np.float32)
+ target["boxes"] = boxes
+
+ return image, target
+
+ def __call__(
+ self,
+ images: ImageInput,
+ annotations: Union[List[Dict], List[List[Dict]]] = None,
+ return_segmentation_masks: Optional[bool] = False,
+ masks_path: Optional[pathlib.Path] = None,
+ padding: Optional[bool] = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s) and optional annotations. Images are by default
+ padded up to the largest image in a batch.
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ annotations (`Dict`, `List[Dict]`, *optional*):
+ The corresponding annotations in COCO format.
+
+ In case [`DetrFeatureExtractor`] was initialized with `format = "coco_detection"`, the annotations for
+ each image should have the following format: {'image_id': int, 'annotations': [annotation]}, with the
+ annotations being a list of COCO object annotations.
+
+ In case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`, the annotations for
+ each image should have the following format: {'image_id': int, 'file_name': str, 'segments_info':
+ [segment_info]} with segments_info being a list of COCO panoptic annotations.
+
+ return_segmentation_masks (`Dict`, `List[Dict]`, *optional*, defaults to `False`):
+ Whether to also include instance segmentation masks as part of the labels in case `format =
+ "coco_detection"`.
+
+ masks_path (`pathlib.Path`, *optional*):
+ Path to the directory containing the PNG files that store the class-agnostic image segmentations. Only
+ relevant in case [`DetrFeatureExtractor`] was initialized with `format = "coco_panoptic"`.
+
+ padding (`bool`, *optional*, defaults to `True`):
+ Whether or not to pad images up to the largest image in a batch.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+ - **labels** -- Optional labels to be fed to a model (when `annotations` are provided)
+ """
+ # Input type checking for clearer error
+
+ valid_images = False
+ valid_annotations = False
+ valid_masks_path = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ # Check that annotations has a valid type
+ if annotations is not None:
+ if not is_batched:
+ if self.format == "coco_detection":
+ if isinstance(annotations, dict) and "image_id" in annotations and "annotations" in annotations:
+ if isinstance(annotations["annotations"], (list, tuple)):
+ # an image can have no annotations
+ if len(annotations["annotations"]) == 0 or isinstance(annotations["annotations"][0], dict):
+ valid_annotations = True
+ elif self.format == "coco_panoptic":
+ if isinstance(annotations, dict) and "image_id" in annotations and "segments_info" in annotations:
+ if isinstance(annotations["segments_info"], (list, tuple)):
+ # an image can have no segments (?)
+ if len(annotations["segments_info"]) == 0 or isinstance(
+ annotations["segments_info"][0], dict
+ ):
+ valid_annotations = True
+ else:
+ if isinstance(annotations, (list, tuple)):
+ if len(images) != len(annotations):
+ raise ValueError("There must be as many annotations as there are images")
+ if isinstance(annotations[0], Dict):
+ if self.format == "coco_detection":
+ if isinstance(annotations[0]["annotations"], (list, tuple)):
+ valid_annotations = True
+ elif self.format == "coco_panoptic":
+ if isinstance(annotations[0]["segments_info"], (list, tuple)):
+ valid_annotations = True
+
+ if not valid_annotations:
+ raise ValueError(
+ """
+ Annotations must of type `Dict` (single image) or `List[Dict]` (batch of images). In case of object
+ detection, each dictionary should contain the keys 'image_id' and 'annotations', with the latter
+ being a list of annotations in COCO format. In case of panoptic segmentation, each dictionary
+ should contain the keys 'file_name', 'image_id' and 'segments_info', with the latter being a list
+ of annotations in COCO format.
+ """
+ )
+
+ # Check that masks_path has a valid type
+ if masks_path is not None:
+ if self.format == "coco_panoptic":
+ if isinstance(masks_path, pathlib.Path):
+ valid_masks_path = True
+ if not valid_masks_path:
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a `pathlib.Path` object."
+ )
+
+ if not is_batched:
+ images = [images]
+ if annotations is not None:
+ annotations = [annotations]
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ if not isinstance(image, Image.Image):
+ image = self.to_pil_image(image)
+ image, target = self.prepare(image, target, return_segmentation_masks, masks_path)
+ images[idx] = image
+ annotations[idx] = target
+
+ # transformations (resizing + normalization)
+ if self.do_resize and self.size is not None:
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ image, target = self._resize(image=image, target=target, size=self.size, max_size=self.max_size)
+ images[idx] = image
+ annotations[idx] = target
+ else:
+ for idx, image in enumerate(images):
+ images[idx] = self._resize(image=image, target=None, size=self.size, max_size=self.max_size)[0]
+
+ if self.do_normalize:
+ if annotations is not None:
+ for idx, (image, target) in enumerate(zip(images, annotations)):
+ image, target = self._normalize(
+ image=image, mean=self.image_mean, std=self.image_std, target=target
+ )
+ images[idx] = image
+ annotations[idx] = target
+ else:
+ images = [
+ self._normalize(image=image, mean=self.image_mean, std=self.image_std)[0] for image in images
+ ]
+
+ if padding:
+ # pad images up to largest image in batch
+ max_size = self._max_by_axis([list(image.shape) for image in images])
+ c, h, w = max_size
+ padded_images = []
+ for image in images:
+ # create padded image
+ padded_image = np.zeros((c, h, w), dtype=np.float32)
+ padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
+ padded_images.append(padded_image)
+ images = padded_images
+
+ # return as BatchFeature
+ data = {}
+ data["pixel_values"] = images
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ if annotations is not None:
+ # Convert to TensorType
+ tensor_type = return_tensors
+ if not isinstance(tensor_type, TensorType):
+ tensor_type = TensorType(tensor_type)
+
+ if not tensor_type == TensorType.PYTORCH:
+ raise ValueError("Only PyTorch is supported for the moment.")
+ else:
+ if not is_torch_available():
+ raise ImportError("Unable to convert output to PyTorch tensors format, PyTorch is not installed.")
+
+ encoded_inputs["labels"] = [
+ {k: torch.from_numpy(v) for k, v in target.items()} for target in annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor._max_by_axis
+ def _max_by_axis(self, the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+ def pad(self, pixel_values_list: List["torch.Tensor"], return_tensors: Optional[Union[str, TensorType]] = None):
+ """
+ Pad images up to the largest image in a batch.
+
+ Args:
+ pixel_values_list (`List[torch.Tensor]`):
+ List of images (pixel values) to be padded. Each image should be a tensor of shape (C, H, W).
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of NumPy arrays. If set to `'pt'`, return PyTorch `torch.Tensor`
+ objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following field:
+
+ - **pixel_values** -- Pixel values to be fed to a model.
+
+ """
+
+ max_size = self._max_by_axis([list(image.shape) for image in pixel_values_list])
+ c, h, w = max_size
+ padded_images = []
+ for image in pixel_values_list:
+ # create padded image
+ padded_image = np.zeros((c, h, w), dtype=np.float32)
+ padded_image[: image.shape[0], : image.shape[1], : image.shape[2]] = np.copy(image)
+ padded_images.append(padded_image)
+
+ # return as BatchFeature
+ data = {"pixel_values": padded_images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process
+ def post_process(self, outputs, target_sizes):
+ """
+ Converts the output of [`DetrForObjectDetection`] into the format expected by the COCO api. Only supports
+ PyTorch.
+
+ Args:
+ outputs ([`DetrObjectDetectionOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation). For visualization, this should be the image size after data
+ augment, but before padding.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, out_bbox = outputs.logits, outputs.pred_boxes
+
+ if len(out_logits) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as the batch dimension of the logits")
+ if target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ prob = nn.functional.softmax(out_logits, -1)
+ scores, labels = prob[..., :-1].max(-1)
+
+ # convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(out_bbox)
+ # and from relative [0, 1] to absolute [0, height] coordinates
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = [{"scores": s, "labels": l, "boxes": b} for s, l, b in zip(scores, labels, boxes)]
+
+ return results
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_segmentation
+ def post_process_segmentation(self, outputs, target_sizes, threshold=0.9, mask_threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into image segmentation predictions. Only supports PyTorch.
+
+ Parameters:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction.
+ threshold (`float`, *optional*, defaults to 0.9):
+ Threshold to use to filter out queries.
+ mask_threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, and masks for an image
+ in the batch as predicted by the model.
+ """
+ out_logits, raw_masks = outputs.logits, outputs.pred_masks
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, size in zip(out_logits, raw_masks, target_sizes):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_masks = (cur_masks.sigmoid() > mask_threshold) * 1
+
+ predictions = {"scores": cur_scores, "labels": cur_classes, "masks": cur_masks}
+ preds.append(predictions)
+ return preds
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_instance
+ def post_process_instance(self, results, outputs, orig_target_sizes, max_target_sizes, threshold=0.5):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual instance segmentation predictions. Only supports
+ PyTorch.
+
+ Args:
+ results (`List[Dict]`):
+ Results list obtained by [`~DetrFeatureExtractor.post_process`], to which "masks" results will be
+ added.
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ orig_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the size (h, w) of each image of the batch. For evaluation, this must be the original
+ image size (before any data augmentation).
+ max_target_sizes (`torch.Tensor` of shape `(batch_size, 2)`):
+ Tensor containing the maximum size (h, w) of each image of the batch. For evaluation, this must be the
+ original image size (before any data augmentation).
+ threshold (`float`, *optional*, defaults to 0.5):
+ Threshold to use when turning the predicted masks into binary values.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels, boxes and masks for an
+ image in the batch as predicted by the model.
+ """
+
+ if len(orig_target_sizes) != len(max_target_sizes):
+ raise ValueError("Make sure to pass in as many orig_target_sizes as max_target_sizes")
+ max_h, max_w = max_target_sizes.max(0)[0].tolist()
+ outputs_masks = outputs.pred_masks.squeeze(2)
+ outputs_masks = nn.functional.interpolate(
+ outputs_masks, size=(max_h, max_w), mode="bilinear", align_corners=False
+ )
+ outputs_masks = (outputs_masks.sigmoid() > threshold).cpu()
+
+ for i, (cur_mask, t, tt) in enumerate(zip(outputs_masks, max_target_sizes, orig_target_sizes)):
+ img_h, img_w = t[0], t[1]
+ results[i]["masks"] = cur_mask[:, :img_h, :img_w].unsqueeze(1)
+ results[i]["masks"] = nn.functional.interpolate(
+ results[i]["masks"].float(), size=tuple(tt.tolist()), mode="nearest"
+ ).byte()
+
+ return results
+
+ # Copied from transformers.models.detr.feature_extraction_detr.DetrFeatureExtractor.post_process_panoptic
+ def post_process_panoptic(self, outputs, processed_sizes, target_sizes=None, is_thing_map=None, threshold=0.85):
+ """
+ Converts the output of [`DetrForSegmentation`] into actual panoptic predictions. Only supports PyTorch.
+
+ Parameters:
+ outputs ([`DetrSegmentationOutput`]):
+ Raw outputs of the model.
+ processed_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`):
+ Torch Tensor (or list) containing the size (h, w) of each image of the batch, i.e. the size after data
+ augmentation but before batching.
+ target_sizes (`torch.Tensor` of shape `(batch_size, 2)` or `List[Tuple]` of length `batch_size`, *optional*):
+ Torch Tensor (or list) corresponding to the requested final size (h, w) of each prediction. If left to
+ None, it will default to the `processed_sizes`.
+ is_thing_map (`torch.Tensor` of shape `(batch_size, 2)`, *optional*):
+ Dictionary mapping class indices to either True or False, depending on whether or not they are a thing.
+ If not set, defaults to the `is_thing_map` of COCO panoptic.
+ threshold (`float`, *optional*, defaults to 0.85):
+ Threshold to use to filter out queries.
+
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing a PNG string and segments_info values for
+ an image in the batch as predicted by the model.
+ """
+ if target_sizes is None:
+ target_sizes = processed_sizes
+ if len(processed_sizes) != len(target_sizes):
+ raise ValueError("Make sure to pass in as many processed_sizes as target_sizes")
+
+ if is_thing_map is None:
+ # default to is_thing_map of COCO panoptic
+ is_thing_map = {i: i <= 90 for i in range(201)}
+
+ out_logits, raw_masks, raw_boxes = outputs.logits, outputs.pred_masks, outputs.pred_boxes
+ if not len(out_logits) == len(raw_masks) == len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits and masks"
+ )
+ preds = []
+
+ def to_tuple(tup):
+ if isinstance(tup, tuple):
+ return tup
+ return tuple(tup.cpu().tolist())
+
+ for cur_logits, cur_masks, cur_boxes, size, target_size in zip(
+ out_logits, raw_masks, raw_boxes, processed_sizes, target_sizes
+ ):
+ # we filter empty queries and detection below threshold
+ scores, labels = cur_logits.softmax(-1).max(-1)
+ keep = labels.ne(outputs.logits.shape[-1] - 1) & (scores > threshold)
+ cur_scores, cur_classes = cur_logits.softmax(-1).max(-1)
+ cur_scores = cur_scores[keep]
+ cur_classes = cur_classes[keep]
+ cur_masks = cur_masks[keep]
+ cur_masks = nn.functional.interpolate(cur_masks[:, None], to_tuple(size), mode="bilinear").squeeze(1)
+ cur_boxes = center_to_corners_format(cur_boxes[keep])
+
+ h, w = cur_masks.shape[-2:]
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.flatten(1)
+ stuff_equiv_classes = defaultdict(lambda: [])
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label.item()]:
+ stuff_equiv_classes[label.item()].append(k)
+
+ def get_ids_area(masks, scores, dedup=False):
+ # This helper function creates the final panoptic segmentation image
+ # It also returns the area of the masks that appears on the image
+
+ m_id = masks.transpose(0, 1).softmax(-1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = torch.zeros((h, w), dtype=torch.long, device=m_id.device)
+ else:
+ m_id = m_id.argmax(-1).view(h, w)
+
+ if dedup:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ if len(equiv) > 1:
+ for eq_id in equiv:
+ m_id.masked_fill_(m_id.eq(eq_id), equiv[0])
+
+ final_h, final_w = to_tuple(target_size)
+
+ seg_img = Image.fromarray(id_to_rgb(m_id.view(h, w).cpu().numpy()))
+ seg_img = seg_img.resize(size=(final_w, final_h), resample=Image.NEAREST)
+
+ np_seg_img = torch.ByteTensor(torch.ByteStorage.from_buffer(seg_img.tobytes()))
+ np_seg_img = np_seg_img.view(final_h, final_w, 3)
+ np_seg_img = np_seg_img.numpy()
+
+ m_id = torch.from_numpy(rgb_to_id(np_seg_img))
+
+ area = []
+ for i in range(len(scores)):
+ area.append(m_id.eq(i).sum().item())
+ return area, seg_img
+
+ area, seg_img = get_ids_area(cur_masks, cur_scores, dedup=True)
+ if cur_classes.numel() > 0:
+ # We know filter empty masks as long as we find some
+ while True:
+ filtered_small = torch.as_tensor(
+ [area[i] <= 4 for i, c in enumerate(cur_classes)], dtype=torch.bool, device=keep.device
+ )
+ if filtered_small.any().item():
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ cur_masks = cur_masks[~filtered_small]
+ area, seg_img = get_ids_area(cur_masks, cur_scores)
+ else:
+ break
+
+ else:
+ cur_classes = torch.ones(1, dtype=torch.long, device=cur_classes.device)
+
+ segments_info = []
+ for i, a in enumerate(area):
+ cat = cur_classes[i].item()
+ segments_info.append({"id": i, "isthing": is_thing_map[cat], "category_id": cat, "area": a})
+ del cur_classes
+
+ with io.BytesIO() as out:
+ seg_img.save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+ preds.append(predictions)
+ return preds
diff --git a/src/transformers/models/yolos/modeling_yolos.py b/src/transformers/models/yolos/modeling_yolos.py
new file mode 100755
index 0000000000000..86ef903167d67
--- /dev/null
+++ b/src/transformers/models/yolos/modeling_yolos.py
@@ -0,0 +1,1324 @@
+# coding=utf-8
+# Copyright 2022 School of EIC, Huazhong University of Science & Technology and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch YOLOS model."""
+
+
+import collections.abc
+import math
+from dataclasses import dataclass
+from typing import Dict, List, Optional, Set, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import Tensor, nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_scipy_available,
+ is_vision_available,
+ logging,
+ replace_return_docstrings,
+ requires_backends,
+)
+from .configuration_yolos import YolosConfig
+
+
+if is_scipy_available():
+ from scipy.optimize import linear_sum_assignment
+
+if is_vision_available():
+ from transformers.models.detr.feature_extraction_detr import center_to_corners_format
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "YolosConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "YolosFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "hustvl/yolos-small"
+_EXPECTED_OUTPUT_SHAPE = [1, 3401, 384]
+
+
+YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "hustvl/yolos-small",
+ # See all YOLOS models at https://huggingface.co/models?filter=yolos
+]
+
+
+@dataclass
+class YolosObjectDetectionOutput(ModelOutput):
+ """
+ Output type of [`YolosForObjectDetection`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` are provided)):
+ Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a
+ bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized
+ scale-invariant IoU loss.
+ loss_dict (`Dict`, *optional*):
+ A dictionary containing the individual losses. Useful for logging.
+ logits (`torch.FloatTensor` of shape `(batch_size, num_queries, num_classes + 1)`):
+ Classification logits (including no-object) for all queries.
+ pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
+ values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
+ possible padding). You can use [`~DetrFeatureExtractor.post_process`] to retrieve the unnormalized bounding
+ boxes.
+ auxiliary_outputs (`list[Dict]`, *optional*):
+ Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
+ and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
+ `pred_boxes`) for each decoder layer.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
+ the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ loss_dict: Optional[Dict] = None
+ logits: torch.FloatTensor = None
+ pred_boxes: torch.FloatTensor = None
+ auxiliary_outputs: Optional[List[Dict]] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Copied from transformers.models.vit.modeling_vit.to_2tuple
+def to_2tuple(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return (x, x)
+
+
+class YolosEmbeddings(nn.Module):
+ """
+ Construct the CLS token, detection tokens, position and patch embeddings.
+
+ """
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.detection_tokens = nn.Parameter(torch.zeros(1, config.num_detection_tokens, config.hidden_size))
+ self.patch_embeddings = PatchEmbeddings(
+ image_size=config.image_size,
+ patch_size=config.patch_size,
+ num_channels=config.num_channels,
+ embed_dim=config.hidden_size,
+ )
+ num_patches = self.patch_embeddings.num_patches
+ self.position_embeddings = nn.Parameter(
+ torch.zeros(1, num_patches + config.num_detection_tokens + 1, config.hidden_size)
+ )
+
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.interpolation = InterpolateInitialPositionEmbeddings(config)
+ self.config = config
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ batch_size, num_channels, height, width = pixel_values.shape
+ embeddings = self.patch_embeddings(pixel_values)
+
+ batch_size, seq_len, _ = embeddings.size()
+
+ # add the [CLS] and detection tokens to the embedded patch tokens
+ cls_tokens = self.cls_token.expand(batch_size, -1, -1)
+ detection_tokens = self.detection_tokens.expand(batch_size, -1, -1)
+ embeddings = torch.cat((cls_tokens, embeddings, detection_tokens), dim=1)
+
+ # add positional encoding to each token
+ # this might require interpolation of the existing position embeddings
+ position_embeddings = self.interpolation(self.position_embeddings, (height, width))
+
+ embeddings = embeddings + position_embeddings
+
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class InterpolateInitialPositionEmbeddings(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.config = config
+
+ def forward(self, pos_embed, img_size=(800, 1344)) -> torch.Tensor:
+ cls_pos_embed = pos_embed[:, 0, :]
+ cls_pos_embed = cls_pos_embed[:, None]
+ det_pos_embed = pos_embed[:, -self.config.num_detection_tokens :, :]
+ patch_pos_embed = pos_embed[:, 1 : -self.config.num_detection_tokens, :]
+ patch_pos_embed = patch_pos_embed.transpose(1, 2)
+ batch_size, hidden_size, seq_len = patch_pos_embed.shape
+
+ patch_height, patch_width = (
+ self.config.image_size[0] // self.config.patch_size,
+ self.config.image_size[1] // self.config.patch_size,
+ )
+ patch_pos_embed = patch_pos_embed.view(batch_size, hidden_size, patch_height, patch_width)
+
+ height, width = img_size
+ new_patch_heigth, new_patch_width = height // self.config.patch_size, width // self.config.patch_size
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed, size=(new_patch_heigth, new_patch_width), mode="bicubic", align_corners=False
+ )
+ patch_pos_embed = patch_pos_embed.flatten(2).transpose(1, 2)
+ scale_pos_embed = torch.cat((cls_pos_embed, patch_pos_embed, det_pos_embed), dim=1)
+ return scale_pos_embed
+
+
+class InterpolateMidPositionEmbeddings(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.config = config
+
+ def forward(self, pos_embed, img_size=(800, 1344)) -> torch.Tensor:
+ cls_pos_embed = pos_embed[:, :, 0, :]
+ cls_pos_embed = cls_pos_embed[:, None]
+ det_pos_embed = pos_embed[:, :, -self.config.num_detection_tokens :, :]
+ patch_pos_embed = pos_embed[:, :, 1 : -self.config.num_detection_tokens, :]
+ patch_pos_embed = patch_pos_embed.transpose(2, 3)
+ depth, batch_size, hidden_size, seq_len = patch_pos_embed.shape
+
+ patch_height, patch_width = (
+ self.config.image_size[0] // self.config.patch_size,
+ self.config.image_size[1] // self.config.patch_size,
+ )
+ patch_pos_embed = patch_pos_embed.view(depth * batch_size, hidden_size, patch_height, patch_width)
+ height, width = img_size
+ new_patch_height, new_patch_width = height // self.config.patch_size, width // self.config.patch_size
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed, size=(new_patch_height, new_patch_width), mode="bicubic", align_corners=False
+ )
+ patch_pos_embed = (
+ patch_pos_embed.flatten(2)
+ .transpose(1, 2)
+ .contiguous()
+ .view(depth, batch_size, new_patch_height * new_patch_width, hidden_size)
+ )
+ scale_pos_embed = torch.cat((cls_pos_embed, patch_pos_embed, det_pos_embed), dim=2)
+ return scale_pos_embed
+
+
+# Based on timm implementation, which can be found here:
+# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
+class PatchEmbeddings(nn.Module):
+ """
+ Image to Patch Embedding.
+
+ """
+
+ def __init__(
+ self,
+ image_size: int = 224,
+ patch_size: Union[int, Tuple[int, int]] = 16,
+ num_channels: int = 3,
+ embed_dim: int = 768,
+ ):
+ super().__init__()
+ image_size = to_2tuple(image_size)
+ patch_size = to_2tuple(patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_patches = num_patches
+
+ self.projection = nn.Conv2d(num_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViT->Yolos
+class YolosSelfAttention(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->Yolos
+class YolosSelfOutput(nn.Module):
+ """
+ The residual connection is defined in YolosLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->Yolos
+class YolosAttention(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.attention = YolosSelfAttention(config)
+ self.output = YolosSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->Yolos
+class YolosIntermediate(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->Yolos
+class YolosOutput(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->Yolos
+class YolosLayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = YolosAttention(config)
+ self.intermediate = YolosIntermediate(config)
+ self.output = YolosOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in Yolos, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in Yolos, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+class YolosEncoder(nn.Module):
+ def __init__(self, config: YolosConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([YolosLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ seq_length = (
+ 1 + (config.image_size[0] * config.image_size[1] // config.patch_size**2) + config.num_detection_tokens
+ )
+ self.mid_position_embeddings = (
+ nn.Parameter(
+ torch.zeros(
+ config.num_hidden_layers - 1,
+ 1,
+ seq_length,
+ config.hidden_size,
+ )
+ )
+ if config.use_mid_position_embeddings
+ else None
+ )
+
+ self.interpolation = InterpolateMidPositionEmbeddings(config) if config.use_mid_position_embeddings else None
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ height,
+ width,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ if self.config.use_mid_position_embeddings:
+ interpolated_mid_position_embeddings = self.interpolation(self.mid_position_embeddings, (height, width))
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if self.config.use_mid_position_embeddings:
+ if i < (self.config.num_hidden_layers - 1):
+ hidden_states = hidden_states + interpolated_mid_position_embeddings[i]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class YolosPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = YolosConfig
+ base_model_prefix = "vit"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module: YolosEncoder, value: bool = False) -> None:
+ if isinstance(module, YolosEncoder):
+ module.gradient_checkpointing = value
+
+
+YOLOS_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`YolosConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+YOLOS_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare YOLOS Model transformer outputting raw hidden-states without any specific head on top.",
+ YOLOS_START_DOCSTRING,
+)
+class YolosModel(YolosPreTrainedModel):
+ def __init__(self, config: YolosConfig, add_pooling_layer: bool = True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = YolosEmbeddings(config)
+ self.encoder = YolosEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.pooler = YolosPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> PatchEmbeddings:
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model.
+
+ Args:
+ heads_to_prune (`dict` of {layer_num: list of heads to prune in this layer}):
+ See base class `PreTrainedModel`.
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(YOLOS_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ height=pixel_values.shape[-2],
+ width=pixel_values.shape[-1],
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ head_outputs = (sequence_output, pooled_output) if pooled_output is not None else (sequence_output,)
+ return head_outputs + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class YolosPooler(nn.Module):
+ def __init__(self, config: YolosConfig):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+@add_start_docstrings(
+ """
+ YOLOS Model (consisting of a ViT encoder) with object detection heads on top, for tasks such as COCO detection.
+ """,
+ YOLOS_START_DOCSTRING,
+)
+class YolosForObjectDetection(YolosPreTrainedModel):
+ def __init__(self, config: YolosConfig):
+ super().__init__(config)
+
+ # YOLOS (ViT) encoder model
+ self.vit = YolosModel(config, add_pooling_layer=False)
+
+ # Object detection heads
+ # We add one for the "no object" class
+ self.class_labels_classifier = YolosMLPPredictionHead(
+ input_dim=config.hidden_size, hidden_dim=config.hidden_size, output_dim=config.num_labels + 1, num_layers=3
+ )
+ self.bbox_predictor = YolosMLPPredictionHead(
+ input_dim=config.hidden_size, hidden_dim=config.hidden_size, output_dim=4, num_layers=3
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # taken from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+ @torch.jit.unused
+ def _set_aux_loss(self, outputs_class, outputs_coord):
+ # this is a workaround to make torchscript happy, as torchscript
+ # doesn't support dictionary with non-homogeneous values, such
+ # as a dict having both a Tensor and a list.
+ return [{"logits": a, "pred_boxes": b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+
+ @add_start_docstrings_to_model_forward(YOLOS_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=YolosObjectDetectionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ labels=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`List[Dict]` of len `(batch_size,)`, *optional*):
+ Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the
+ following 2 keys: `'class_labels'` and `'boxes'` (the class labels and bounding boxes of an image in the
+ batch respectively). The class labels themselves should be a `torch.LongTensor` of len `(number of bounding
+ boxes in the image,)` and the boxes a `torch.FloatTensor` of shape `(number of bounding boxes in the image,
+ 4)`.
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import YolosFeatureExtractor, YolosForObjectDetection
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> feature_extractor = YolosFeatureExtractor.from_pretrained("hustvl/yolos-small")
+ >>> model = YolosForObjectDetection.from_pretrained("hustvl/yolos-small")
+
+ >>> inputs = feature_extractor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+
+ >>> # model predicts bounding boxes and corresponding COCO classes
+ >>> logits = outputs.logits
+ >>> bboxes = outputs.pred_boxes
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # First, sent images through YOLOS base model to obtain hidden states
+ outputs = self.vit(
+ pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ # Take the final hidden states of the detection tokens
+ sequence_output = sequence_output[:, -self.config.num_detection_tokens :, :]
+
+ # Class logits + predicted bounding boxes
+ logits = self.class_labels_classifier(sequence_output)
+ pred_boxes = self.bbox_predictor(sequence_output).sigmoid()
+
+ loss, loss_dict, auxiliary_outputs = None, None, None
+ if labels is not None:
+ # First: create the matcher
+ matcher = YolosHungarianMatcher(
+ class_cost=self.config.class_cost, bbox_cost=self.config.bbox_cost, giou_cost=self.config.giou_cost
+ )
+ # Second: create the criterion
+ losses = ["labels", "boxes", "cardinality"]
+ criterion = YolosLoss(
+ matcher=matcher,
+ num_classes=self.config.num_labels,
+ eos_coef=self.config.eos_coefficient,
+ losses=losses,
+ )
+ criterion.to(self.device)
+ # Third: compute the losses, based on outputs and labels
+ outputs_loss = {}
+ outputs_loss["logits"] = logits
+ outputs_loss["pred_boxes"] = pred_boxes
+ if self.config.auxiliary_loss:
+ intermediate = outputs.intermediate_hidden_states if return_dict else outputs[4]
+ outputs_class = self.class_labels_classifier(intermediate)
+ outputs_coord = self.bbox_predictor(intermediate).sigmoid()
+ auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_loss["auxiliary_outputs"] = auxiliary_outputs
+
+ loss_dict = criterion(outputs_loss, labels)
+ # Fourth: compute total loss, as a weighted sum of the various losses
+ weight_dict = {"loss_ce": 1, "loss_bbox": self.config.bbox_loss_coefficient}
+ weight_dict["loss_giou"] = self.config.giou_loss_coefficient
+ if self.config.auxiliary_loss:
+ aux_weight_dict = {}
+ for i in range(self.config.decoder_layers - 1):
+ aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
+ weight_dict.update(aux_weight_dict)
+ loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
+
+ if not return_dict:
+ if auxiliary_outputs is not None:
+ output = (logits, pred_boxes) + auxiliary_outputs + outputs
+ else:
+ output = (logits, pred_boxes) + outputs
+ return ((loss, loss_dict) + output) if loss is not None else output
+
+ return YolosObjectDetectionOutput(
+ loss=loss,
+ loss_dict=loss_dict,
+ logits=logits,
+ pred_boxes=pred_boxes,
+ auxiliary_outputs=auxiliary_outputs,
+ last_hidden_state=outputs.last_hidden_state,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.detr.modeling_detr.dice_loss
+def dice_loss(inputs, targets, num_boxes):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.sigmoid_focal_loss
+def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
+ """
+ Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ alpha: (optional) Weighting factor in range (0,1) to balance
+ positive vs negative examples. Default = -1 (no weighting).
+ gamma: Exponent of the modulating factor (1 - p_t) to
+ balance easy vs hard examples.
+
+ Returns:
+ Loss tensor
+ """
+ prob = inputs.sigmoid()
+ ce_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+ p_t = prob * targets + (1 - prob) * (1 - targets)
+ loss = ce_loss * ((1 - p_t) ** gamma)
+
+ if alpha >= 0:
+ alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
+ loss = alpha_t * loss
+
+ return loss.mean(1).sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrLoss with Detr->Yolos
+class YolosLoss(nn.Module):
+ """
+ This class computes the losses for YolosForObjectDetection/YolosForSegmentation. The process happens in two steps:
+ 1) we compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each
+ pair of matched ground-truth / prediction (supervise class and box).
+
+ A note on the `num_classes` argument (copied from original repo in detr.py): "the naming of the `num_classes`
+ parameter of the criterion is somewhat misleading. It indeed corresponds to `max_obj_id` + 1, where `max_obj_id` is
+ the maximum id for a class in your dataset. For example, COCO has a `max_obj_id` of 90, so we pass `num_classes` to
+ be 91. As another example, for a dataset that has a single class with `id` 1, you should pass `num_classes` to be 2
+ (`max_obj_id` + 1). For more details on this, check the following discussion
+ https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"
+
+
+ Args:
+ matcher (`YolosHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ eos_coef (`float`):
+ Relative classification weight applied to the no-object category.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
+ """
+
+ def __init__(self, matcher, num_classes, eos_coef, losses):
+ super().__init__()
+ self.matcher = matcher
+ self.num_classes = num_classes
+ self.eos_coef = eos_coef
+ self.losses = losses
+ empty_weight = torch.ones(self.num_classes + 1)
+ empty_weight[-1] = self.eos_coef
+ self.register_buffer("empty_weight", empty_weight)
+
+ # removed logging parameter, which was part of the original implementation
+ def loss_labels(self, outputs, targets, indices, num_boxes):
+ """
+ Classification loss (NLL) targets dicts must contain the key "class_labels" containing a tensor of dim
+ [nb_target_boxes]
+ """
+ if "logits" not in outputs:
+ raise KeyError("No logits were found in the outputs")
+ src_logits = outputs["logits"]
+
+ idx = self._get_src_permutation_idx(indices)
+ target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])
+ target_classes = torch.full(
+ src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device
+ )
+ target_classes[idx] = target_classes_o
+
+ loss_ce = nn.functional.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
+ losses = {"loss_ce": loss_ce}
+
+ return losses
+
+ @torch.no_grad()
+ def loss_cardinality(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the cardinality error, i.e. the absolute error in the number of predicted non-empty boxes.
+
+ This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients.
+ """
+ logits = outputs["logits"]
+ device = logits.device
+ tgt_lengths = torch.as_tensor([len(v["class_labels"]) for v in targets], device=device)
+ # Count the number of predictions that are NOT "no-object" (which is the last class)
+ card_pred = (logits.argmax(-1) != logits.shape[-1] - 1).sum(1)
+ card_err = nn.functional.l1_loss(card_pred.float(), tgt_lengths.float())
+ losses = {"cardinality_error": card_err}
+ return losses
+
+ def loss_boxes(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss.
+
+ Targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]. The target boxes
+ are expected in format (center_x, center_y, w, h), normalized by the image size.
+ """
+ if "pred_boxes" not in outputs:
+ raise KeyError("No predicted boxes found in outputs")
+ idx = self._get_src_permutation_idx(indices)
+ src_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ loss_bbox = nn.functional.l1_loss(src_boxes, target_boxes, reduction="none")
+
+ losses = {}
+ losses["loss_bbox"] = loss_bbox.sum() / num_boxes
+
+ loss_giou = 1 - torch.diag(
+ generalized_box_iou(center_to_corners_format(src_boxes), center_to_corners_format(target_boxes))
+ )
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ def loss_masks(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the masks: the focal loss and the dice loss.
+
+ Targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w].
+ """
+ if "pred_masks" not in outputs:
+ raise KeyError("No predicted masks found in outputs")
+
+ src_idx = self._get_src_permutation_idx(indices)
+ tgt_idx = self._get_tgt_permutation_idx(indices)
+ src_masks = outputs["pred_masks"]
+ src_masks = src_masks[src_idx]
+ masks = [t["masks"] for t in targets]
+ # TODO use valid to mask invalid areas due to padding in loss
+ target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
+ target_masks = target_masks.to(src_masks)
+ target_masks = target_masks[tgt_idx]
+
+ # upsample predictions to the target size
+ src_masks = nn.functional.interpolate(
+ src_masks[:, None], size=target_masks.shape[-2:], mode="bilinear", align_corners=False
+ )
+ src_masks = src_masks[:, 0].flatten(1)
+
+ target_masks = target_masks.flatten(1)
+ target_masks = target_masks.view(src_masks.shape)
+ losses = {
+ "loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
+ "loss_dice": dice_loss(src_masks, target_masks, num_boxes),
+ }
+ return losses
+
+ def _get_src_permutation_idx(self, indices):
+ # permute predictions following indices
+ batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
+ src_idx = torch.cat([src for (src, _) in indices])
+ return batch_idx, src_idx
+
+ def _get_tgt_permutation_idx(self, indices):
+ # permute targets following indices
+ batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
+ tgt_idx = torch.cat([tgt for (_, tgt) in indices])
+ return batch_idx, tgt_idx
+
+ def get_loss(self, loss, outputs, targets, indices, num_boxes):
+ loss_map = {
+ "labels": self.loss_labels,
+ "cardinality": self.loss_cardinality,
+ "boxes": self.loss_boxes,
+ "masks": self.loss_masks,
+ }
+ if loss not in loss_map:
+ raise ValueError(f"Loss {loss} not supported")
+ return loss_map[loss](outputs, targets, indices, num_boxes)
+
+ def forward(self, outputs, targets):
+ """
+ This performs the loss computation.
+
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
+ """
+ outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs"}
+
+ # Retrieve the matching between the outputs of the last layer and the targets
+ indices = self.matcher(outputs_without_aux, targets)
+
+ # Compute the average number of target boxes accross all nodes, for normalization purposes
+ num_boxes = sum(len(t["class_labels"]) for t in targets)
+ num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
+ # (Niels): comment out function below, distributed training to be added
+ # if is_dist_avail_and_initialized():
+ # torch.distributed.all_reduce(num_boxes)
+ # (Niels) in original implementation, num_boxes is divided by get_world_size()
+ num_boxes = torch.clamp(num_boxes, min=1).item()
+
+ # Compute all the requested losses
+ losses = {}
+ for loss in self.losses:
+ losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
+
+ # In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
+ if "auxiliary_outputs" in outputs:
+ for i, auxiliary_outputs in enumerate(outputs["auxiliary_outputs"]):
+ indices = self.matcher(auxiliary_outputs, targets)
+ for loss in self.losses:
+ if loss == "masks":
+ # Intermediate masks losses are too costly to compute, we ignore them.
+ continue
+ l_dict = self.get_loss(loss, auxiliary_outputs, targets, indices, num_boxes)
+ l_dict = {k + f"_{i}": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ return losses
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrMLPPredictionHead with Detr->Yolos
+class YolosMLPPredictionHead(nn.Module):
+ """
+ Very simple multi-layer perceptron (MLP, also called FFN), used to predict the normalized center coordinates,
+ height and width of a bounding box w.r.t. an image.
+
+ Copied from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+
+ """
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = nn.functional.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrHungarianMatcher with Detr->Yolos
+class YolosHungarianMatcher(nn.Module):
+ """
+ This class computes an assignment between the targets and the predictions of the network.
+
+ For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
+ predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
+ un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
+ """
+
+ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
+ super().__init__()
+ requires_backends(self, ["scipy"])
+
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ if class_cost == 0 or bbox_cost == 0 or giou_cost == 0:
+ raise ValueError("All costs of the Matcher can't be 0")
+
+ @torch.no_grad()
+ def forward(self, outputs, targets):
+ """
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
+
+ Returns:
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
+ For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
+ """
+ batch_size, num_queries = outputs["logits"].shape[:2]
+
+ # We flatten to compute the cost matrices in a batch
+ out_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
+ out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
+
+ # Also concat the target labels and boxes
+ tgt_ids = torch.cat([v["class_labels"] for v in targets])
+ tgt_bbox = torch.cat([v["boxes"] for v in targets])
+
+ # Compute the classification cost. Contrary to the loss, we don't use the NLL,
+ # but approximate it in 1 - proba[target class].
+ # The 1 is a constant that doesn't change the matching, it can be ommitted.
+ class_cost = -out_prob[:, tgt_ids]
+
+ # Compute the L1 cost between boxes
+ bbox_cost = torch.cdist(out_bbox, tgt_bbox, p=1)
+
+ # Compute the giou cost between boxes
+ giou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(tgt_bbox))
+
+ # Final cost matrix
+ cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
+
+ sizes = [len(v["boxes"]) for v in targets]
+ indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
+ return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t: Tensor) -> Tensor:
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+# Copied from transformers.models.detr.modeling_detr.box_area
+def box_area(boxes: Tensor) -> Tensor:
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+# Copied from transformers.models.detr.modeling_detr.box_iou
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+# Copied from transformers.models.detr.modeling_detr.generalized_box_iou
+def generalized_box_iou(boxes1, boxes2):
+ """
+ Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
+
+ Returns:
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+ iou, union = box_iou(boxes1, boxes2)
+
+ lt = torch.min(boxes1[:, None, :2], boxes2[:, :2])
+ rb = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])
+
+ wh = (rb - lt).clamp(min=0) # [N,M,2]
+ area = wh[:, :, 0] * wh[:, :, 1]
+
+ return iou - (area - union) / area
+
+
+# Copied from transformers.models.detr.modeling_detr._max_by_axis
+def _max_by_axis(the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+
+# Copied from transformers.models.detr.modeling_detr.NestedTensor
+class NestedTensor(object):
+ def __init__(self, tensors, mask: Optional[Tensor]):
+ self.tensors = tensors
+ self.mask = mask
+
+ def to(self, device):
+ cast_tensor = self.tensors.to(device)
+ mask = self.mask
+ if mask is not None:
+ cast_mask = mask.to(device)
+ else:
+ cast_mask = None
+ return NestedTensor(cast_tensor, cast_mask)
+
+ def decompose(self):
+ return self.tensors, self.mask
+
+ def __repr__(self):
+ return str(self.tensors)
+
+
+# Copied from transformers.models.detr.modeling_detr.nested_tensor_from_tensor_list
+def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
+ if tensor_list[0].ndim == 3:
+ max_size = _max_by_axis([list(img.shape) for img in tensor_list])
+ batch_shape = [len(tensor_list)] + max_size
+ b, c, h, w = batch_shape
+ dtype = tensor_list[0].dtype
+ device = tensor_list[0].device
+ tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
+ mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
+ for img, pad_img, m in zip(tensor_list, tensor, mask):
+ pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
+ m[: img.shape[1], : img.shape[2]] = False
+ else:
+ raise ValueError("Only 3-dimensional tensors are supported")
+ return NestedTensor(tensor, mask)
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 898848d5ba16e..112759671bbfe 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -4697,6 +4697,30 @@ def load_tf_weights_in_xlnet(*args, **kwargs):
requires_backends(load_tf_weights_in_xlnet, ["torch"])
+YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class YolosForObjectDetection(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class YolosModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class YolosPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
YOSO_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 6ffeeb52b3e8f..8ba819156143f 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -141,3 +141,10 @@ class ViTFeatureExtractor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class YolosFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/yolos/__init__.py b/tests/yolos/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/tests/yolos/test_feature_extraction_yolos.py b/tests/yolos/test_feature_extraction_yolos.py
new file mode 100644
index 0000000000000..4fc9217bbe036
--- /dev/null
+++ b/tests/yolos/test_feature_extraction_yolos.py
@@ -0,0 +1,336 @@
+# coding=utf-8
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_vision_available
+
+from ..test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import YolosFeatureExtractor
+
+
+class YolosFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ max_size=1333, # by setting max_size > max_resolution we're effectively not testing this :p
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.max_size = max_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "max_size": self.max_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to YolosFeatureExtractor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size * h / w)
+ expected_width = self.size
+ elif w > h:
+ expected_height = self.size
+ expected_width = int(self.size * w / h)
+ else:
+ expected_height = self.size
+ expected_width = self.size
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+
+@require_torch
+@require_vision
+class YolosFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = YolosFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = YolosFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "max_size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (1, self.feature_extract_tester.num_channels, expected_height, expected_width),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+
+ expected_height, expected_width = self.feature_extract_tester.get_expected_values(image_inputs, batched=True)
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_equivalence_padding(self):
+ # Initialize feature_extractors
+ feature_extractor_1 = self.feature_extraction_class(**self.feat_extract_dict)
+ feature_extractor_2 = self.feature_extraction_class(do_resize=False, do_normalize=False)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test whether the method "pad" and calling the feature extractor return the same tensors
+ encoded_images_with_method = feature_extractor_1.pad(image_inputs, return_tensors="pt")
+ encoded_images = feature_extractor_2(image_inputs, return_tensors="pt")
+
+ assert torch.allclose(encoded_images_with_method["pixel_values"], encoded_images["pixel_values"], atol=1e-4)
+
+ @slow
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ # encode them
+ feature_extractor = YolosFeatureExtractor.from_pretrained("hustvl/yolos-small")
+ encoding = feature_extractor(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ assert torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ assert torch.allclose(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ assert torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ assert torch.allclose(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ assert torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ assert torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ assert torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ assert torch.allclose(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ # encode them
+ feature_extractor = YolosFeatureExtractor(format="coco_panoptic")
+ encoding = feature_extractor(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ assert torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ assert torch.allclose(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ assert torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ assert torch.allclose(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ assert torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ assert torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822338
+ self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ assert torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ assert torch.allclose(encoding["labels"][0]["size"], expected_size)
diff --git a/tests/yolos/test_modeling_yolos.py b/tests/yolos/test_modeling_yolos.py
new file mode 100644
index 0000000000000..e64795b1ea011
--- /dev/null
+++ b/tests/yolos/test_modeling_yolos.py
@@ -0,0 +1,373 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch YOLOS model. """
+
+
+import inspect
+import unittest
+
+from transformers import YolosConfig
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ..test_configuration_common import ConfigTester
+from ..test_modeling_common import ModelTesterMixin, floats_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import YolosForObjectDetection, YolosModel
+ from transformers.models.yolos.modeling_yolos import YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST, to_2tuple
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoFeatureExtractor
+
+
+class YolosModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=[30, 30],
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ n_targets=8,
+ num_detection_tokens=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+ self.n_targets = n_targets
+ self.num_detection_tokens = num_detection_tokens
+ # we set the expected sequence length (which is used in several tests)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token) + num_detection_tokens
+ image_size = to_2tuple(self.image_size)
+ patch_size = to_2tuple(self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.expected_seq_len = num_patches + 1 + self.num_detection_tokens
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size[0], self.image_size[1]])
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return YolosConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ num_detection_tokens=self.num_detection_tokens,
+ num_labels=self.num_labels,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = YolosModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.expected_seq_len, self.hidden_size)
+ )
+
+ def create_and_check_for_object_detection(self, config, pixel_values, labels):
+ model = YolosForObjectDetection(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_detection_tokens, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_detection_tokens, 4))
+
+ result = model(pixel_values=pixel_values, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_detection_tokens, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_detection_tokens, 4))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class YolosModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as YOLOS does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (YolosModel, YolosForObjectDetection) if is_torch_available() else ()
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torchscript = False
+
+ # special case for head model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "YolosForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = YolosModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=YolosConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_inputs_embeds(self):
+ # YOLOS does not use inputs_embeds
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ # in YOLOS, the seq_len is different
+ seq_len = self.model_tester.expected_seq_len
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # YOLOS has a different seq_length
+ seq_length = self.model_tester.expected_seq_len
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_for_object_detection(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_object_detection(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = YolosModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class YolosModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return AutoFeatureExtractor.from_pretrained("hustvl/yolos-small") if is_vision_available() else None
+
+ @slow
+ def test_inference_object_detection_head(self):
+ model = YolosForObjectDetection.from_pretrained("hustvl/yolos-small").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(inputs.pixel_values)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 100, 92))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice_logits = torch.tensor(
+ [[-24.0248, -10.3024, -14.8290], [-42.0392, -16.8200, -27.4334], [-27.2743, -11.8154, -18.7148]],
+ device=torch_device,
+ )
+ expected_slice_boxes = torch.tensor(
+ [[0.2559, 0.5455, 0.4706], [0.2989, 0.7279, 0.1875], [0.7732, 0.4017, 0.4462]], device=torch_device
+ )
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice_logits, atol=1e-4))
+ self.assertTrue(torch.allclose(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, atol=1e-4))
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 12ca41b413a0a..05119b292cbfc 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -18,6 +18,7 @@ src/transformers/models/big_bird/modeling_big_bird.py
src/transformers/models/blenderbot/modeling_blenderbot.py
src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
src/transformers/models/convnext/modeling_convnext.py
+src/transformers/models/ctrl/modeling_ctrl.py
src/transformers/models/data2vec/modeling_data2vec_audio.py
src/transformers/models/data2vec/modeling_data2vec_vision.py
src/transformers/models/deit/modeling_deit.py
@@ -58,5 +59,5 @@ src/transformers/models/vit_mae/modeling_vit_mae.py
src/transformers/models/wav2vec2/modeling_wav2vec2.py
src/transformers/models/wav2vec2/tokenization_wav2vec2.py
src/transformers/models/wav2vec2_with_lm/processing_wav2vec2_with_lm.py
-src/transformers/models/wavlm/modeling_wavlm.py
-src/transformers/models/ctrl/modeling_ctrl.py
+src/transformers/models/wavlm/modeling_wavlm.py
+src/transformers/models/yolos/modeling_yolos.py