Add PySpark Integration #519
Conversation
| from sentry_sdk.integrations.spark.spark_driver import SparkIntegration | ||
| from sentry_sdk.integrations.spark.spark_worker import sentry_worker_main | ||
|
|
||
| __all__ = ["SparkIntegration", "sentry_worker_main"] |
There was a problem hiding this comment.
Why do we need to export sentry_worker_main for users to patch in? Why can't we patch main ourselves?
There was a problem hiding this comment.
We can't patch main ourselves because the daemon code has already been sent to the distributed executors by the time we patch SparkContext (which is the earliest we can do anything). As a result, we opt to set it when Sentry.init is called in the daemon.
There was a problem hiding this comment.
Do you think we should also have a SparkWorkerIntegration in this case?
6912e94
to
0b9a6f8
Compare
|
Update: This is probably ready for another look through. I went through and refactored some of the driver/worker code. I also added tests for the driver integration. For some more context - here is a WIP branch for the docs https://github.com/getsentry/sentry-docs/compare/abhi/pyspark-docs. I'm not sure if I should be using spark or pyspark, thoughts? |
|
@AbhiPrasad spark is probably fine |
|
|
||
| sparkContext = SparkContext._active_spark_context | ||
| if sparkContext: | ||
| sparkContext.setLocalProperty("app_name", sparkContext.appName) |
There was a problem hiding this comment.
Can we safely do this without interfering with user-set properties? Why do we need this?
There was a problem hiding this comment.
We set a local property so that the worker has access to "app_name" and "application_id".
if "app_name" in taskContext._localProperties:
scope.set_tag("app_name", taskContext._localProperties["app_name"])
scope.set_tag(
"application_id", taskContext._localProperties["application_id"]
)It might be a good idea to rename it to something more sentry specific so that it won't get changed by the user. sentry_integration_app_name?
There was a problem hiding this comment.
I don't understand why this is necessary. Couldn't you set them on the scope directly?
(also I would prefer it if you used an event processor here like in the other code sample I posted)
There was a problem hiding this comment.
https://github.com/apache/spark/blob/master/python/pyspark/context.py#L1015-L1020
The driver propagates these local properties to the workers, I'm essentially using this as a way to communicate between the driver process and worker process (because they are on different clusters). We set the local property with the driver integration so that the worker integration can access it.
If we don't use setLocalProperty in the driver, the worker integration cannot set tags for application_id and app_name (which makes it much harder to pair worker errors with driver errors by tag in Sentry itself). I have not found any other way to access this information with just a worker.
Did change to use an event processor 👍
There was a problem hiding this comment.
Hmm, could you add a short comment that this is how you transport data over the wire
Codecov Report
@@ Coverage Diff @@
## master #519 +/- ##
=========================================
- Coverage 85.91% 79.81% -6.1%
=========================================
Files 103 99 -4
Lines 8155 7823 -332
Branches 864 819 -45
=========================================
- Hits 7006 6244 -762
- Misses 831 1299 +468
+ Partials 318 280 -38
Continue to review full report at Codecov.
|

91fee09
to
1e56a2c
Compare
|
Update: Addressed review comments, fix lint errors. Seems like the pyspark tests are timing out, not sure why though. Edit: Seems like |
|
@AbhiPrasad you had both pyspark and spark in the tox.ini which caused it to run the main test suite within the pyspark build. It's a mistake that |
|
Hi guys, I'm right now building this branch to try it on one of our pipelines. I don't have much time for testing unfortunately, it's a busy week, but I could at least tell you if I manage to set it up initially. |
|
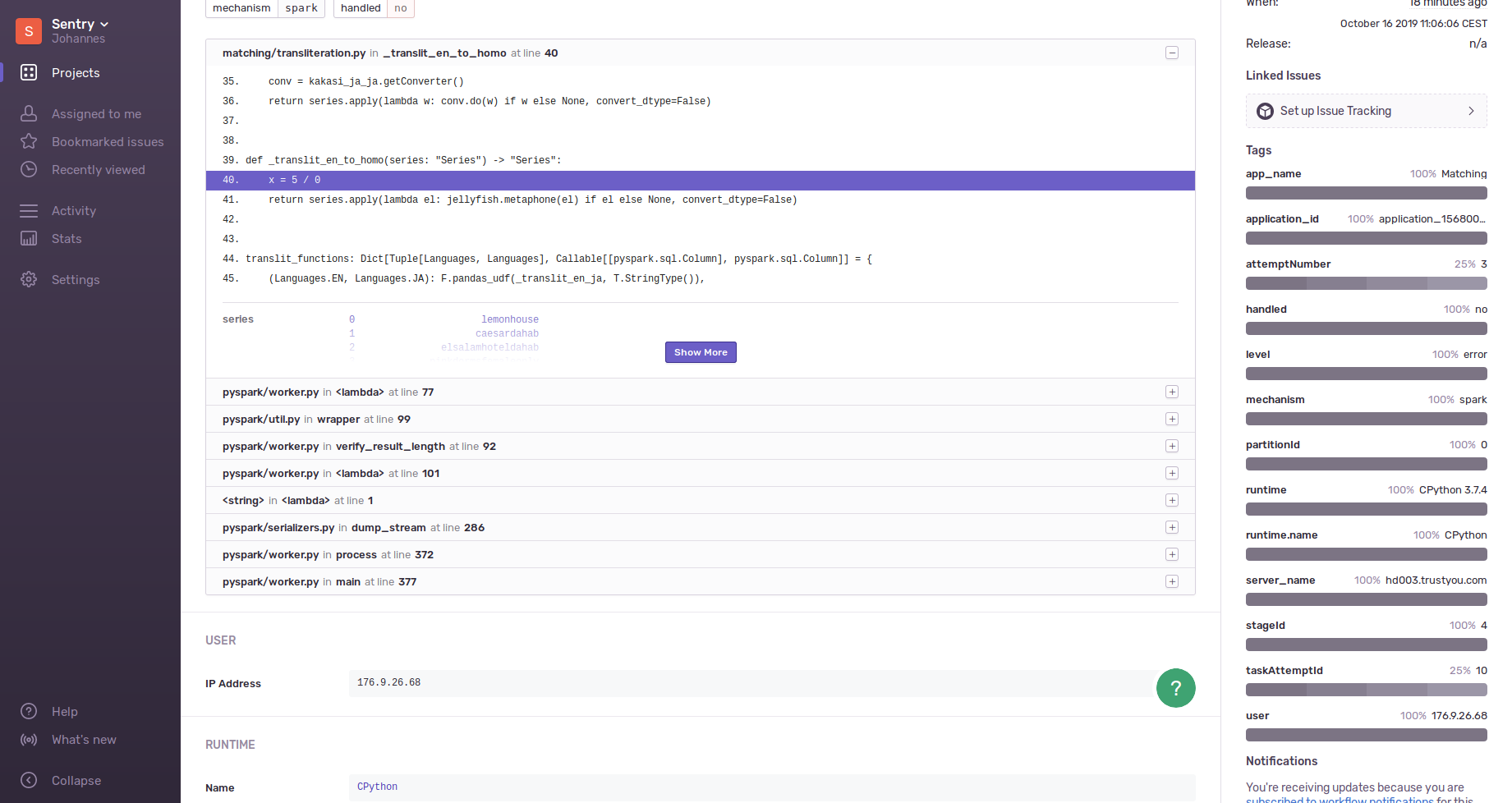
The general setup worked flawlessly! Managed to capture an error in a Arrow UDF with a proper Python Stacktrace - perfect, that's exactly what I was hoping for. I didn't have much time to look into details, but I noticed one thing: with sentry_sdk.configure_scope() as scope:
scope.set_tag("source", args["source"])
scope.set_tag("target", args["target"])
scope.set_tag("run-id", args["run_id"])In the event form the worker, these tags are missing In the event from the driver, these tags (and also some additional ones that this integration is setting) are present I guess this might just be a technical limitation by this setup, but I think it warrants a note in the documentation at least. |
854b6ce
to
0eb6122
Compare
|
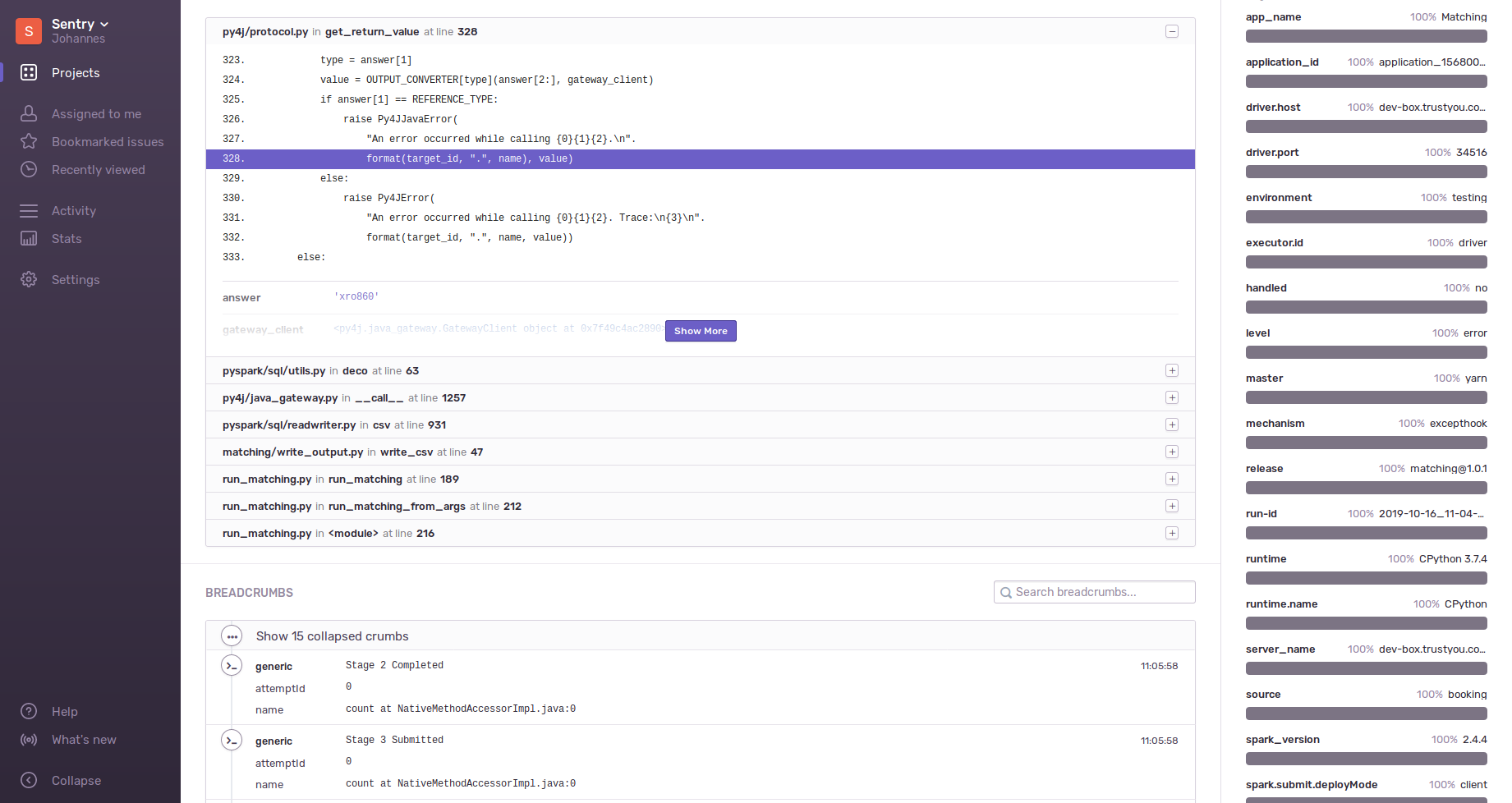
@harpaj thank you for your feedback! Any code executed in the main spark job outside of spark actions only run the driver, that's why only the driver tagged it, again as you said just a technical limitation of this approach (not much more we can do as the driver process and worker process are running on different clusters). You might be able to tag inside the UDF itself, because that is serialized and sent to the worker, but I have not tested that yet. This might also add a lot of overhead and slow down the UDF too much. Edit: Tested setting tag inside spark action function spark = SparkSession.builder.appName("Testing123").getOrCreate()
def bad_func(a, b):
with sentry_sdk.configure_scope() as scope:
scope.set_tag("source", "This should be in worker")
a = b / 0
return a + b
this_breaks = spark.sparkContext.parallelize(range(1, 20), 2).reduce(bad_func)
spark.stop()This set the |
0eb6122
to
fc14fbf
Compare
| @@ -153,7 +153,7 @@ deps = | |||
| sqlalchemy-1.2: sqlalchemy>=1.2,<1.3 | |||
| sqlalchemy-1.3: sqlalchemy>=1.3,<1.4 | |||
|
|
|||
| spark: spark==2.4.4 | |||
| spark: pyspark==2.4.4 | |||
07cf916
to
b120ef4
Compare
This is draft PR for the purposes of reviewing the work I have so far. Much of this is still in flux, and has to be extensively tested on different executions env like Databricks/Dataproc/YARN.We make available the integration for both the Spark driver as well as Spark workers (which may be in different clusters depending on the execution environment). In order to add the sentry-integration, you must install the
sentry-sdk.In order to start sending Sentry errors from the main Spark driver, you can simply init Sentry before you init your
SparkContextwhen writing your job.You can also just use
StreamingContextin case of SparkStreaming usage or just useSparkContext.This will log errors to Sentry, building breadcrumbs using
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala#L216
In order to instrument workers, additional steps will have to be taken. The configuration options used to instrument the workers are only available in Spark 2.4 and above.
First, you must install the
sentry-sdkon your workers. This can be done locally be sending thesentry-pythonegg or zip to spark using the--py-filescmd line option or withsc.addPyFile().Next, we have to monkey patch the spark daemon to initialize Sentry on each worker. This can be done by creating a file with the following code.
In order to tell Spark to replace the daemon, you must set some properties, either with a custom
SparkConfor using the--confcmd line option. These arespark.python.use.daemon=trueandspark.python.daemon.module=sentry_patched_worker_file_name. You must also use--py-filesto sendsentry_patched_worker_file_name.pyto each of the workers.https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/api/python/PythonWorkerFactory.scala#L56-L63
Both the workers and drivers share a common
application_id, so we can easily filter for which workers are associated with what drivers.Next Steps:
Test with DatabricksTest with DataprocWrite tests on this branchUpdate documentationAdd documentation for PySpark sentry-docs#1275