Reduce byte array allocations when reading/writing packets #6023
Conversation
Byte arrays are a major source of LOH allocations when streaming logging events across nodes. Allocating a large MemoryStream once and then growing it as needed almost completely removes allocations for byte arrays. This should significantly improve memory traffic during large builds.
|
I'm looking at Mono failures... presumably I broke something around FEATURE_APM... a packet arrives, of the right length, but contains junk... |
|
Part 3 works, everything else fails. This commit breaks it: A lock around the method doesn't help. I'm stumped! Will go for a walk and try to attack it tomorrow. |
|
Hey @dsplaisted do you have any wisdom for me? This commit is trying to reuse the MemoryStream: and it breaks Mono, see build failures. I've isolated it to this change. I'd try a pooled memory stream but first I want to understand what is going on? Are two of these methods running simultaneously? Why does the lock not help? |
|
It looks like the initial commit is your first attempt and then you're generally just backing off the changes to try to get it to work? I'm not sure why it's not working. I don't think multiple reads or writes should be going on at the same time in a single process. Maybe a read and write can be happening at the same time and that's causing an issue? But I don't know. |
|
What if you make the fields thread local? Every thread would get its own cached byte array and avoid data races. If that fixes the problem it means that that method is indeed multi threaded, which is a surprise |
|
The command line I use locally for testing on Mac: |
|
Here's the raw MSBuild invocation: |
|
OK I understand what's happening: this async call doesn't await and returns: and then since the array is reused the Unix implementation of PipeStream trips over itself: Because we queue a new call to SendAsync before the previous call returns and frees up our array. So we can't reuse the array if we don't await on line 762 or use the synchronous Write method on the NamedPipeClientStream. |
If we use WriteAsync and don't await it, then subsequent WriteAsync may be called before the first continuation returns. If both calls share the same buffer and they overlap, we will overwrite the data in the buffer and cause junk to arrive at receiver.
0760a0d
to
6eb445d
Compare
|
OK folks, note one significant change: on Mono (== when FEATURE_APM is not set) we switch the last write of the packet to be synchronous as well: The other codepath (used by Windows) doesn't seem to have a problem sharing the array because it ends up in a WriteFileNative call where we fully read the array segment we're passed before returning from BeginWrite. On Mono it used to be a fire-and-forget async task (WriteAsync was not awaited), and it led to new writes being called when the previous write didn't return. Not only it gets in the way of reusing the array, but more importantly I think it can explain some weirdness I saw with Mono parallel builds: mono/mono#20669 Since the Mono parallel build is already slow enough, I think making this change won't make things much worse. There are much more impactful things we can do to improve perf there. |
|
@KirillOsenkov Great job on figuring out what was wrong on Mono. However, it seems like we're relying on the implementation of |
|
I had the same concern. It would make things much simpler if the last write was synchronous as well. Are we sure that making that last write fire-and-forget async is significant for perf? |
Given the excellent documentation, there's no way to know but to try it out. You can try and build orchard core with /m and do an RPS run. My gut feeling is that it won't affect perf too much because most packets are fairly short. The biggest ones that I'm aware of are ProjectInstance and BuildResult objects, and there's only two of those per built project. ProjectInstance objects are not sent during cmdline builds, only in VS builds, so running RPS would be good. Logging packets are the most frequent, but how large can those be? 😊. And besides, AFAIK packet sending happens on a separate thread than the RequestBuilder so it won't hold up builds, worst case it will congest the send queue. |
|
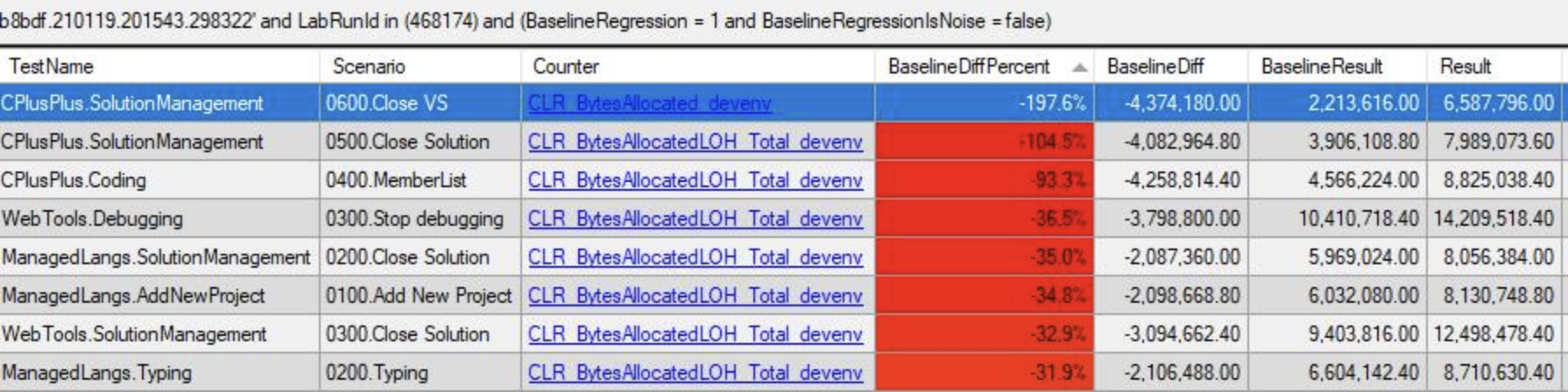
So I ran some numbers on a medium-size fully built incremental solution (so the C# compiler is never invoked).
First column is current master. Second is the PR before I made the writing synchronous. The last one is the last commit where I write the entire packet synchronously. Of course this is just a toy experiment and we'd need to run RPS but this confirms my intuition that making things sync here likely won't create much of contention. @cdmihai logging packets can easily get huge, ~ 5MB, for logging of task inputs, task outputs, item adds and removes (all items with metadata are concatenated into a giant 5MB string and sent across the wire in a single BuildMessageEventArgs). You can see some stats here: Here's a sample part of a single packet sent by RAR: |
| int lengthToWrite = Math.Min((int)writeStream.Length - i, MaxPacketWriteSize); | ||
| if ((int)writeStream.Length - i <= MaxPacketWriteSize) | ||
| int lengthToWrite = Math.Min(writeStreamLength - i, MaxPacketWriteSize); | ||
| if (writeStreamLength - i <= MaxPacketWriteSize) |
There was a problem hiding this comment.
This if looks redundant now, both branches do the same thing.
|
This is not ready yet - we have a real perf regression identified by @cdmihai: Additionally, we have an RPS failure, because we now preallocate two 1 MB byte arrays per worker node, which RPS caught: I'll need to confirm the overall memory savings on larger builds and if it is as significant as I saw, we'll need to ask for an RPS exception to allow us to take an initial hit, in exchange for almost no byte[] allocations down the line in this area. Also I'll need to look if I can make the entire SendData() async (fire-and-forget) so that we don't block on it finishing. If switching to sync for the last part of the packet has caused such a dramatic slowdown maybe we can squeeze more out of it if we move the entire SendData() call to a different async queue to queue up a packet and return immediately. |
Would it make sense to start with smaller arrays then and pay the resizing cost in scenarios where a lot of data is moved between nodes? |
|
@ladipro certainly a simple way to trick RPS ;) I'll try that. |
|
reminds me of Volkswagen for some reason |
This avoids blocking the main loop. Roughly equivalent to writing the packet asynchronously using fire-and-forget (BeginWrite).
dc5f1fb
to
c89545c
Compare
|
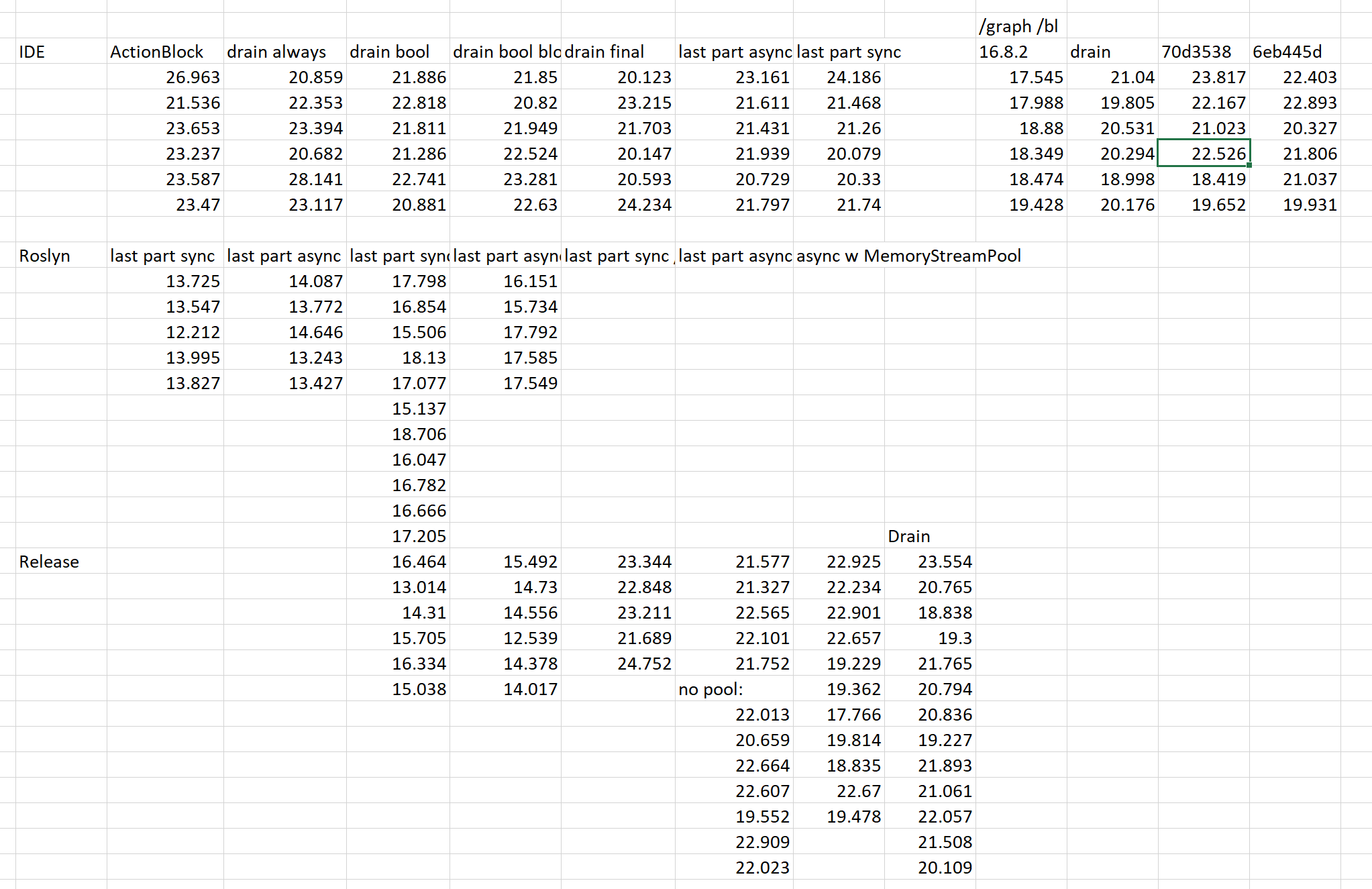
I'm experimenting with moving SendData() off the main loop (to keep Measuring this is incredibly tricky. I've spent two full days trying out various approaches, measuring various codebases, with various flags (/bl, /graph), debug vs. release, last write sync vs. async, MemoryStreamPool vs. a single memory stream, attempts at optimizing DrainPacketQueue(), etc. The numbers fluctuate and are highly inconclusive. There would be outliers and no clear picture. But the trend does show a little bit, so at least you can compare each pair of approaches. This is a rough draft, and if the approach looks OK I'll rebase and cleanup the code and add comments and such. Here are my crazy numbers from the last two days: |
|
Here are the final numbers I got that matter the most:
70d3538 is the base commit of this PR. 6eb445d reuses MemoryStreams. c89545c is the last commit which makes SendData return immediately and writes the packets on a separate thread asynchronously. |
|
I pushed this branch to exp/kirillo/memoryStream to see if RPS is more happy this way |
|
Unfortunately this is a no-go for now. On a single threaded build this PR is noticeably slower than master:
I'll need to profile and investigate why. |
|
Hmm, I've remeasured again and now it's on par with master for single-node: 32.847 I profiled and saw nothing under profiler that I touch. I even turned off Defender for the path. |
|
Without /bl and with /m the numbers are ever so slightly more favorable for this PR:
|
|
This should be ready for final review. |
src/Build/BackEnd/Components/Communications/NodeProviderOutOfProcBase.cs
Outdated
Show resolved
Hide resolved
src/Build/BackEnd/Components/Communications/NodeProviderOutOfProcBase.cs
Show resolved
Hide resolved
src/Build/BackEnd/Components/Communications/NodeProviderOutOfProcBase.cs
Show resolved
Hide resolved
|
@ladipro yup, Tasks were designed to point forward (to continuations), but not backward (a Task doesn’t know what started it and doesn’t hold on to predecessors). So the chain would just fall off and get GCed. |
|
@KirillOsenkov This looks awesome. What's holding this up from getting in? Are we targeting 16.9 or 16.10? |
|
16.10. I’m waiting for you guys to merge this :) |
|
Is this targeting 16.10 because of the risk? |
|
Yeah, not enough runway for 16.9 to get some thorough testing and dogfooding time |
Byte arrays are a major source of LOH allocations when streaming logging events across nodes. Allocating a large MemoryStream once and then growing it as needed almost completely removes allocations for byte arrays.
This should significantly improve memory traffic during large builds.
Before:
After: