"unable to enqueue message" when AsyncClient<UdpResponse> sends too many requests
#1276
Comments
|
It might be caused by |
|
I found out this is not related to buffer size, but I used async Mutex across |
|
Can you explain a bit more about the changes that fixed the problem you were seeing? It sounds like there might be a potential deadlock in trust-dns that you triggered? |
|
Sure, here is the problematic code. I have roughly an async Either block the async Also, unbounded or bounded
|
|
Why are you holding on to so many separate |
|
No, I am not. I created a |
|
I tested the same code on with Tokio 0.3 on main branch, seems like it is able to enqueue messages, but it has to wait for a long time. Can we change the channel to be unlimited? Or have an option for that |
|
Effectively this is the |
|
Does having multiple AsyncClient help? I suppose each client has its own queue (background)? |
|
If you set up multiple async clients separately that should mitigate the problem, yes. But again, that just means now you're potentially opening multiple connections to the same backend servers, which might cause your client to get rate-limited sooner. It would be useful to know what the bottleneck in draining the queue is, in your application. |
|
Thanks, I would investigate further to see where exact point is. |
|
dcompass looks like a cool project, BTW! Is there a particular reason you're using trust-dns-client here rather than trust-dns-resolver? |
|
To tell you the truth, the first prototype used resolver because I didn't understand how the client works. However, that means I have to refill the IP response back to create a new packet and send back, which is cumbersome. Using client means I only need to forward query and send back the answers, which is kind of more native. |
|
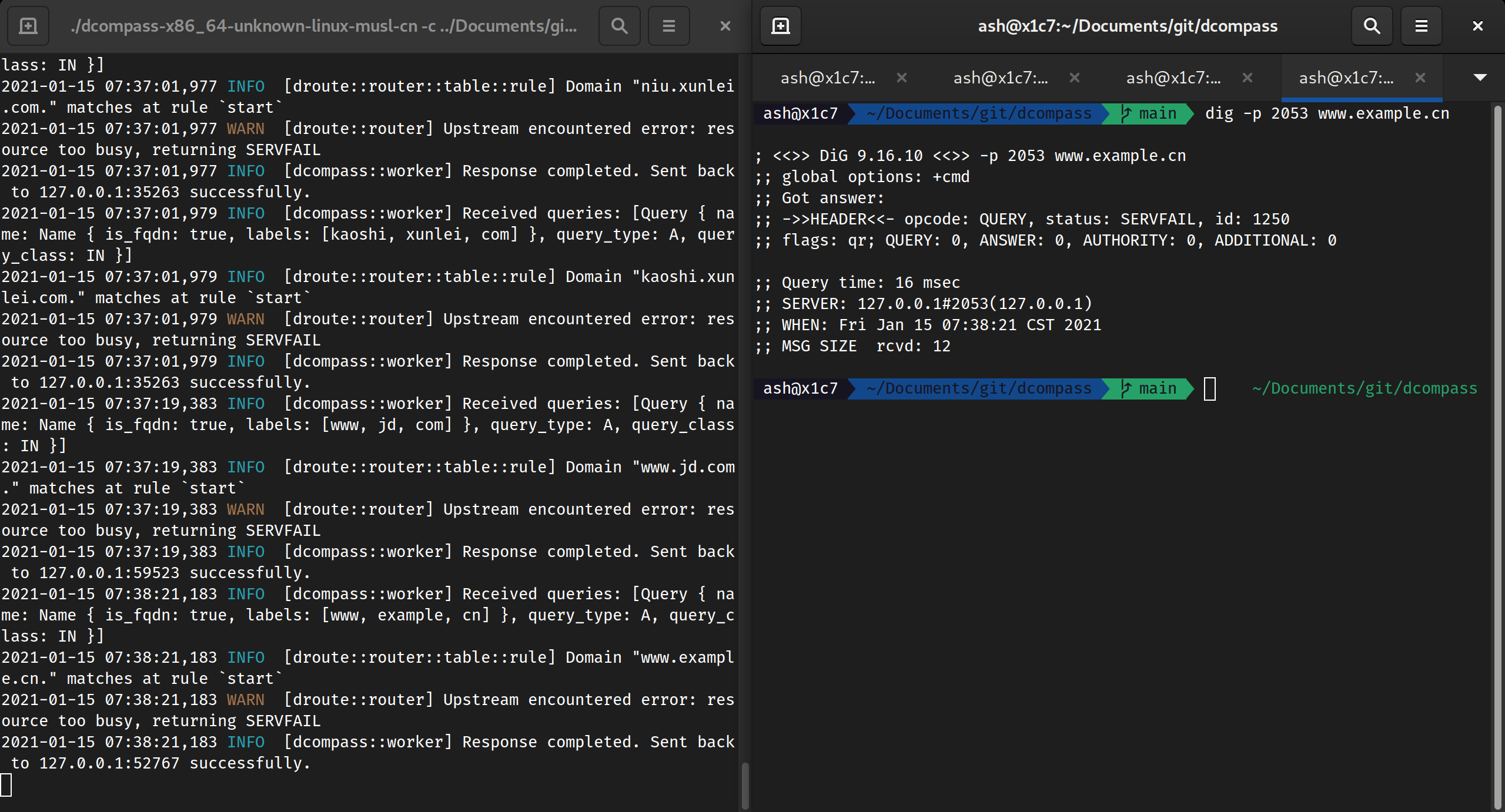
Seems like it's a network issue only. It now can top |
|
So this can be closed again, right? |
I think so. However, regarding the queue size, I hope it could be increased or exposed with an argument. |
|
I don't really see a good reason to do that: if there's a network delay for example, it's better for your application to become aware of that sooner rather than later (through timeouts). |
|
Update: |
|
Would be nice to have a minimal reproduction that demonstrates the issue. |
use std::net::SocketAddr;
use std::sync::Arc;
use tokio::net::UdpSocket;
use trust_dns_client::{client::AsyncClient, udp::UdpClientStream};
use trust_dns_proto::op::Message;
use trust_dns_proto::xfer::dns_handle::DnsHandle;
#[tokio::main]
async fn main() {
// Bind an UDP socket
let socket = Arc::new(
UdpSocket::bind("127.0.0.1:2053".parse::<SocketAddr>().unwrap())
.await
.unwrap(),
);
let client = {
let stream = UdpClientStream::<UdpSocket>::new("8.8.8.8:53".parse().unwrap());
let (client, bg) = AsyncClient::connect(stream).await.unwrap();
tokio::spawn(bg);
client
};
// Event loop
loop {
let mut buf = [0; 1232];
let (_, src) = socket.recv_from(&mut buf).await.unwrap();
let msg = Message::from_vec(&buf).unwrap();
let socket = socket.clone();
let mut client = client.clone();
tokio::spawn(async move {
let id = msg.id();
let mut r = Message::from(client.send(msg).await.unwrap());
r.set_id(id);
socket.send_to(&r.to_vec().unwrap(), src).await
});
}
}I believe this is the minimal sample. However, due to having a "good" network environment now, I cannot really test it out. (It works under current environment). |
|
I don't think it would be a bug if that fails. The application needs to be able to "handle" backpressure from the underlying library, by slowing down the rate of requests if necessary. The channel always being full just means the receiver cannot handle the rate of requests faster than the sender is trying to send it. If that happens with your application, you should find some way for your application to "handle" the backpressure, for example by temporarily delaying further requests or load balancing with another channel. Maybe do some reading on backpressure if you're not familiar with it: https://medium.com/@jayphelps/backpressure-explained-the-flow-of-data-through-software-2350b3e77ce7 |
|
However, the situation here is that the channel is full even though the sender stopped sending any message for a considerable amount of time. That is what I unexpected. I think by either cancelling or dropping or handling internally in |
|
But I cannot reproduce on that minimal sample still. Maybe this issue is related to my codebase, however, I don't see any substantial difference between the sample and my codebase. |
|
Okay, that does sound look a bug. Without some way to reproduce it or a more detailed problem report, I'm not sure I have any avenues for fixing it, though. |
|
impl Udp {
pub async fn new(addr: SocketAddr) -> Result<Self> {
let stream = UdpClientStream::<UdpSocket>::new(addr);
let (client, bg) = AsyncClient::connect(stream).await?;
tokio::spawn(bg);
Ok(Self { client })
}
}
#[async_trait]
impl ClientPool for Udp {
async fn get_client(&self) -> Result<AsyncClient> {
Ok(self.client.clone())
}
}It's weird to see receiver being dropped though. |

|
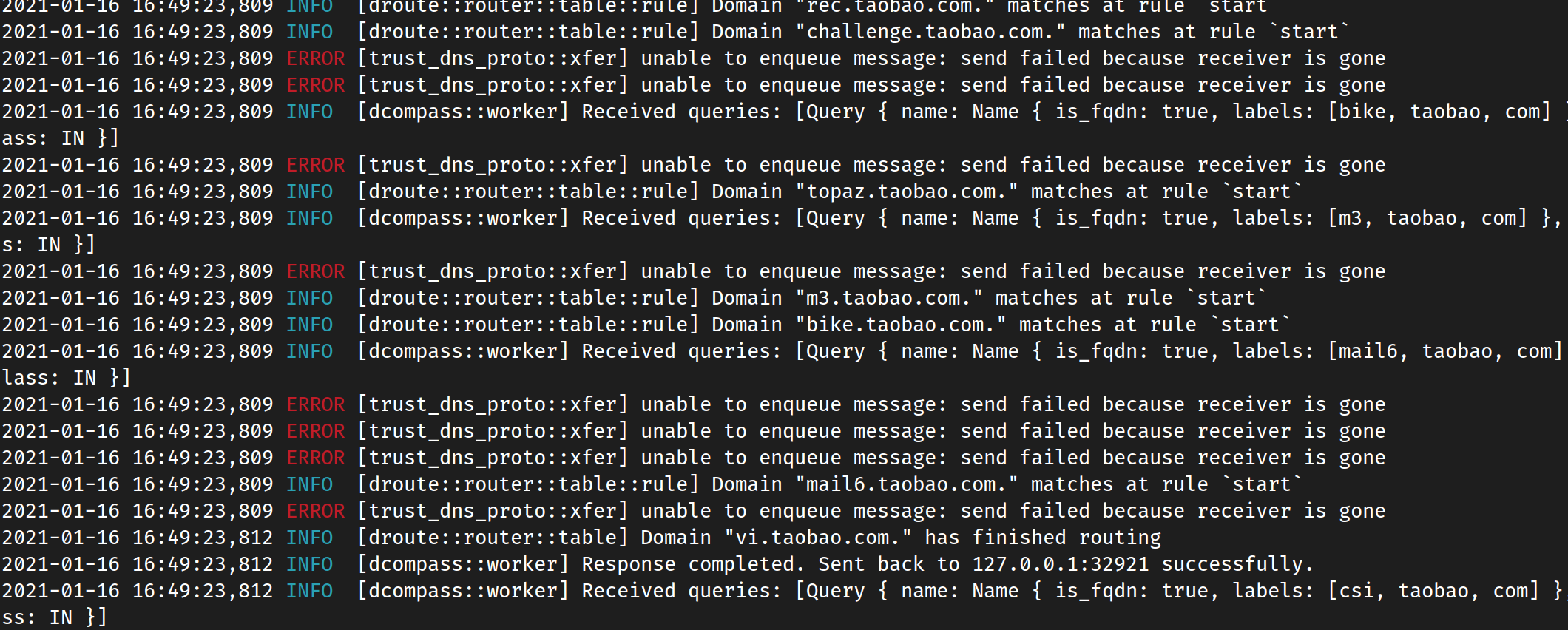
Seems like before the receiver was gone, there was always some error like |
|
The root cause of this issue is that the background task encountered some error and exited, while the client tried to send the message but failed due to non-existed background. What I did is to create a new |
|
Did you figure out what error the background task encountered? We should maybe make the background task more resilient to failure if the error is at all recoverable. |
|
Mainly |
|
Thanks for all the research on this. I'm wondering if the issue here is that we are hitting a network error, but the request future waiting for the result isn't able to be notified, b/c there is no ID associated back to the stream (thus forcing the timeout to expire before resolving itself). Do we need a better method of binding the request id and IO Stream associated together, such that when the IO Stream fails we can immediately return a result to the channel waiting for a response? (I'm guessing this might be the issue based on @LEXUGE 's research). |
|
There are two cases separately. However, if the error is transient (like a network issue, if the background is able to tell), I expect the background to survive through those errors. |
|
The behavior in the case of failing to associate seems wrong; see if #1356 improves the situation? For the other one, is that the exact message? I cannot find where the "not an error" phrase would have come from. |
It is not exact. The exact message (for DoH clients) is |
|
And for Can we figure out how to let the background exit if and only if all clients are dropped or some irrecoverable errors encountered (better to let all the clients know in that case). |
|
That's not how I understand the change I made. It seems to me that the change only lets the task go on if sending a response to a receiver fails. However, the |
|
Thanks, that seems right to me now. |
Describe the bug
During pressure tests for scale like 890 qps, I found
where
drouteis the name of my project.To Reproduce
Hard to get down to a minimal reproducible code snippet. However, I did the following:
AsyncClientand send through it.There is only one
AsyncClient, but it is cloned for several times.I tested with delay in between, 1 millisecond doesn't help (issue persists for
unable to enqueue), 2 milliseconds result in timeout (I set timeout for like 2 seconds per query).I also tested to have multiple
AsyncClient, which results in high rate of timeout.Code related can be found here
Expected behavior
No error
System:
Version:
Crate: client
Version: 0.19.5
Additional context
I also used
tokio-compat, but it doesn't seem to occur the issue.The text was updated successfully, but these errors were encountered: