The order of eviction in weight-limited cache makes it essentially static #583
Comments
|
Can you provide a runnable test case? You could simply capture a trace of key hashes. Many of the simulator's traces are like that, and would allow us to run against a variety of policies to see the hit rate options. It is true that the cache defaults towards LFU / MRU by rejecting new candidates, but this is only if less than or equal to the victim's frequency. In a small cache like yours, it can be difficult to capture enough statistics to determine the workload distribution. We do that by a CountMinSketch (historic popularity) and hill climbing (adaptive region sizes) in order to obtain a high hit rate. A cache of only 10 entries might simply stay in an MRU configuration because repeated hits are too spread out. In your case of a scan there is no clear benefit of keeping the new arrival, e.g. think a sql row scan, so the main region is protected from one-hit wonders polluting the cache. |
|
Here's a runnable test case Note that the delay in add() is crucial; without it the behavior is different. Increasing the cache maxWeight just delays the appearance of the issue, but does not eliminate it. For comparison, here is the output when running the same example with maxSize = 10: I would prefer to see FIFO eviction (all other things considered) but it's better that evicting the newcomers. The advantage of not evicting new elements is that the content of the cache follows the moving "hot spot". If we evict newcomers, the cache will fill in with no longer relevant elements that will stay there for the duration of TTL. As the "hot spot" moves, the cache hit rate will drop. To make the cache useful in this scenario as well as in the scenario you described, maybe we should have a parameter that sets the eviction preference. |
|
I ran a few more tests with both the size based and the weight based eviction adding 800 elements to 100-element cache (by size or weight). The cache seems to be heavily LIFO biased with a larger bias when the cache is set to the weight-based eviction. |
|
The cache is optimized towards maximizing the hit rate and the algorithms evolve over time. In your test case there is a 0% hit rate (32 misses, 22 evictions). From a policy's perspective evicting any entry is fair, but each has a bias. Guava's LRU will keep different content than Caffeine's, but the result is identical. The cache defaults to a policy configuration that is similar to a LIFO. This is because many workloads have "one-hit wonders" which should be discarded quickly. If there are hits then the recent entries will be promoted for retention and the cache will be frequency-biased. As many samples are acquired, the cache may reconfigure itself to prefer holding new arrivals longer if it determines that is more beneficial. That can result in a policy that is roughly LRU. For example in the workload below the cache switches adapts due to a sequence of LRU => MRU => LRU traces. When I simulate a weighted workload that is LRU-biased, like Twitter's, then I do see the cache reconfigure itself appropriately.
We don't make any promises about what our algorithms prefer to keep, only that we will try to maximize the hit rate by taking multiple signals into account. If you have a business need for LRU and don't want to rely on our adaptivity to suss that, then you should use an LRU cache. There may be excellent reasons for that requirement, but is it is not something that we promises in our offering. It sounds like you don't have a requirement, just a different default expectation. A "hot spot" should be captured by frequency, e.g. we do well on a Zipfian trace. I think that if you tried a real workload then you'd see that this cache does quite well. We have many in our simulator and can easily add new ones. From your test, though, I don't think one should have any expectations on the contents when optimal is a 0% hit rate. |
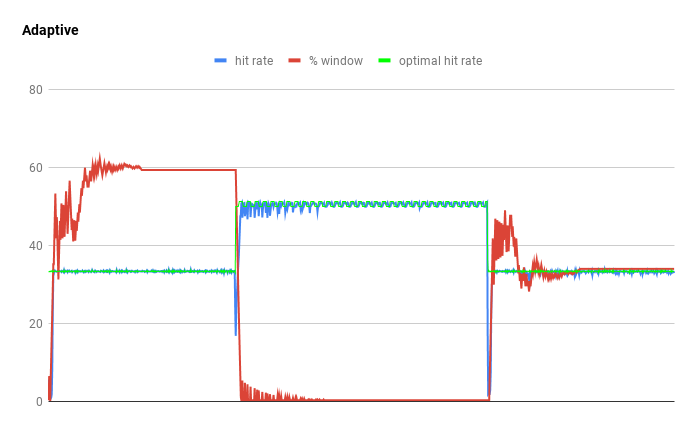
|
An example using a CDN object trace from the AdaptSize caching policy, which is a weight-based algorithm. In this case the maximum is set to 5,000,000 and the largest entry is 4,092,928.
Here you can see that Caffeine does not mimic MRU, which has the worst hit rate. It more closely follows LRU, but improves upon it by a small margin. The gold standard, Greedy-Dual-Size-Frequency, is the clear leader but this costs O(lg n) per operation. There is a possible improvement that would close this gap described in a recent paper, but I have not yet implemented that. The paper shows more real world workloads and that we're already very competitive to the leading options. |
|
Ben, thank you for the explanation and all the details. My real-world cache is rather small. I am going to run it in a staging environment and see how well the eviction behaves. |
|
Great. Please let me know the results. If you can capture an access trace then we can dissect it. I’ll close for now but reopen if you get some data for us. Small caches may be difficult for us because there is not much room to adapt. For example the hill climber changes the ratio by a step size, e.g. 5%, and monitors the impact for a sample period. A 10 entry cache can’t be climbed with that step size and changes might be too noisy to discern if we could. No one has reported a problem yet, but I believe there could be improvements made if we can find a real world trace that we do poorly at. |
|
The cache maintains the item's popularity outside of the working set. This is done by using a 4-bit CountMinSketch (FrequencySketch) that is periodically aged. If the item was prematurely evicted then it will incur another cache miss, each of which causes its score to increase. When evicting we compare a recent arrival to the LRU victim and retain whichever is considered more valuable. This is referred to as the TinyLFU admission policy. We extend that idea by using an admission window (an LRU) to delay the evaluation of admitting into the main region. The cache starts at a 1% admission window / 99% main region ratio. We then adjust the ratio using a hill climber by observing the hit ratio within the sample period. This allows the cache to reconfigure itself as shown above to maximize the hit rate to the workload's pattern. In the example above it switches between LRU and MRU traces. If you capture an access trace (log the key's hash and weight, if applicable, on every get request) then we can then run it in the simulator so that you can see the hit rate curves across different algorithms. We've run it across dozens of different workload types from public sources in order to try to find an approach that is robustly near optimal (either the best or comparable). The simulator implements the common and advanced policies, so we can be data driven in our optimizations of the algorithms. |
Hi Ben,
First of all, thanks for the excellent cache library. It works great! However, I found that if I switch from a size-and-time based eviction to a weight-and-time based eviction, the eviction starts removing newly added elements making the cache effectively static in the absence of TTL-based removal.
Here is how my cache is configured
and this is the result of a test run
Remaining elements in the cache
I am on Caffeine v3.0.3.
I am aware of #513. I tried increasing the max weight, but that only delayed the moment when the cache starts evicting the latest additions.
Any suggestions?
The text was updated successfully, but these errors were encountered: