40个分区的topic消息严重不均衡下个别partition无法被consumer消费 #12800
Comments
|
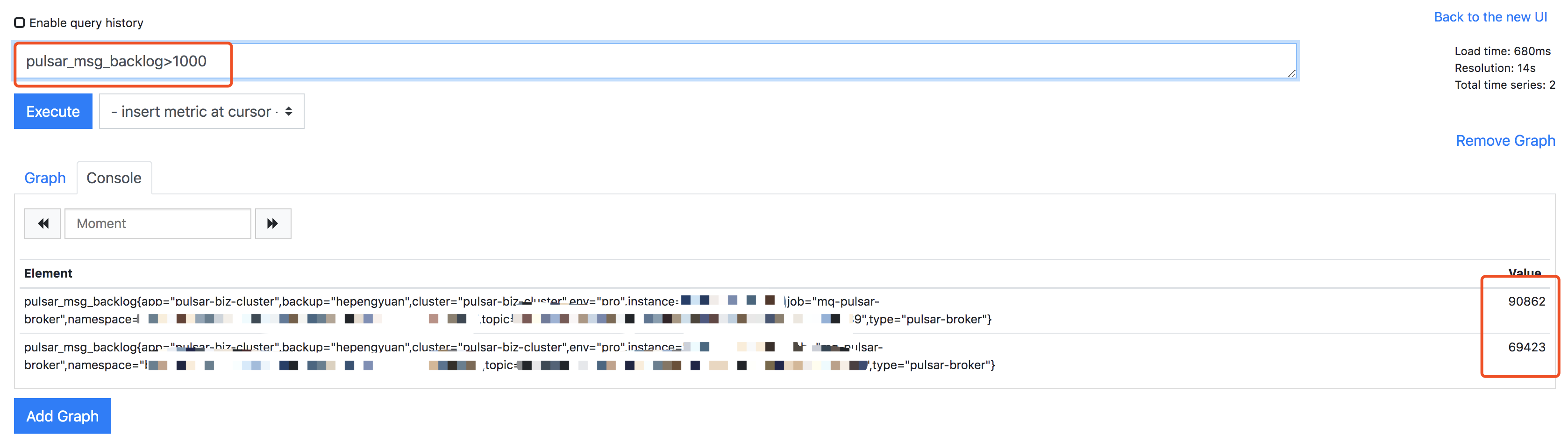
补充一下: 综上现象,是我怀疑是pulsar-broker的疑似bug的原因。 |
|
补充2: |
|
补充3: arthas查看dashboard如下: threads: |

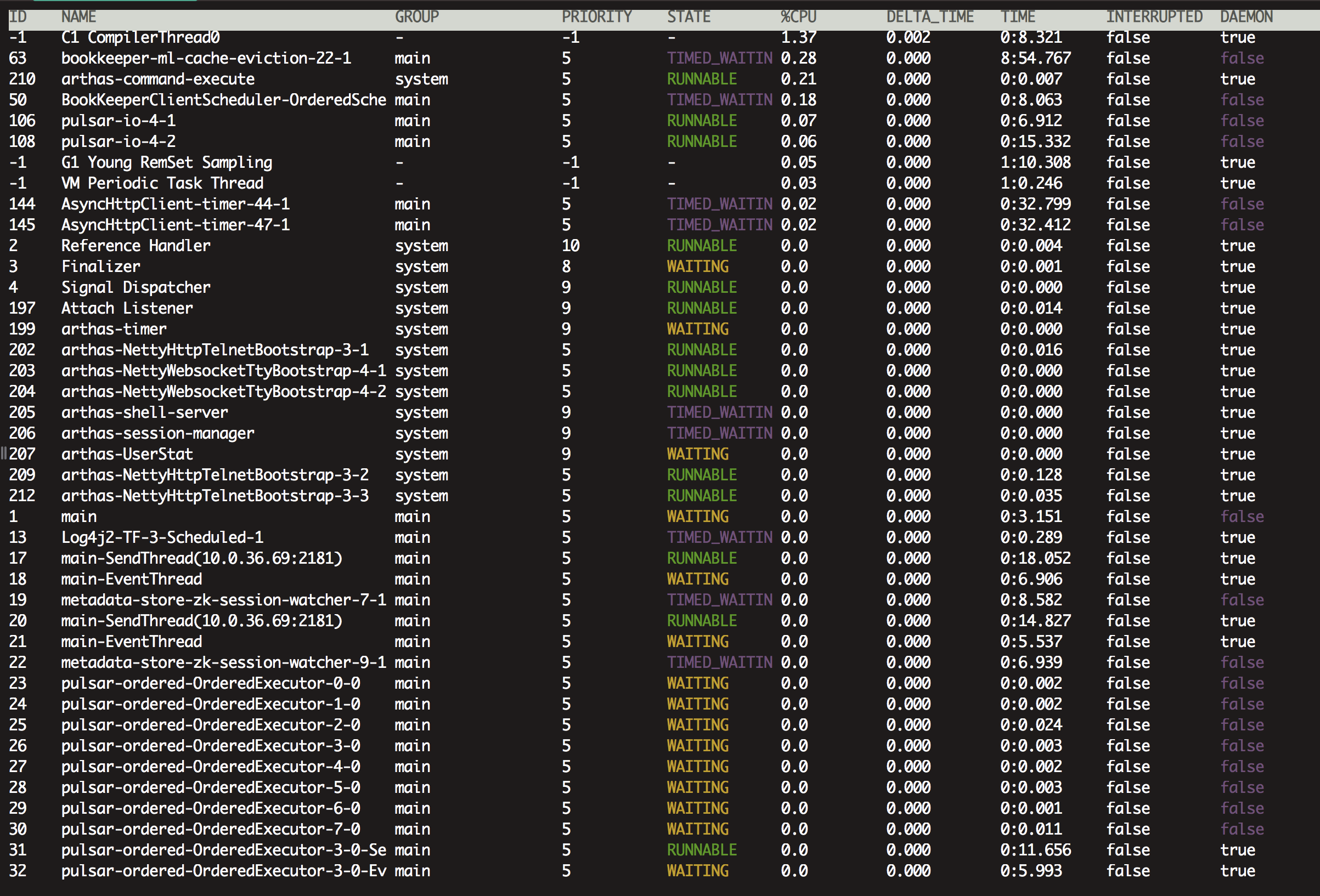
|
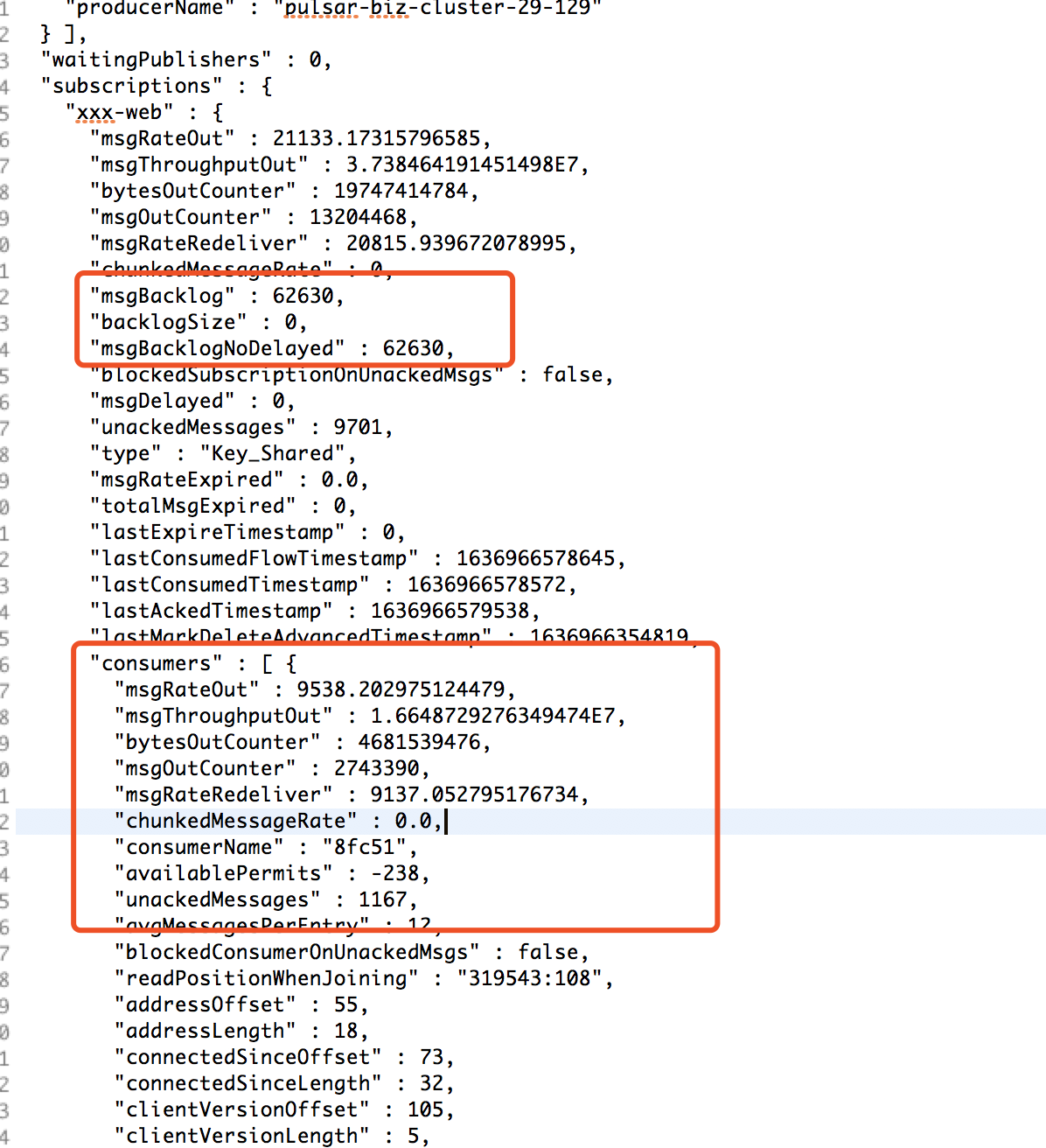
补充4: 我查阅了2.8.1release的fix list,注意到了2.8.1的这个修复: 然后我同样看了下问题分区的stats,和上述issue中的stats做对比,不是同一个现象,但确实有些问题: 下附脱敏后的topic stats(只把订阅者名称改了,其余都保持现场): |
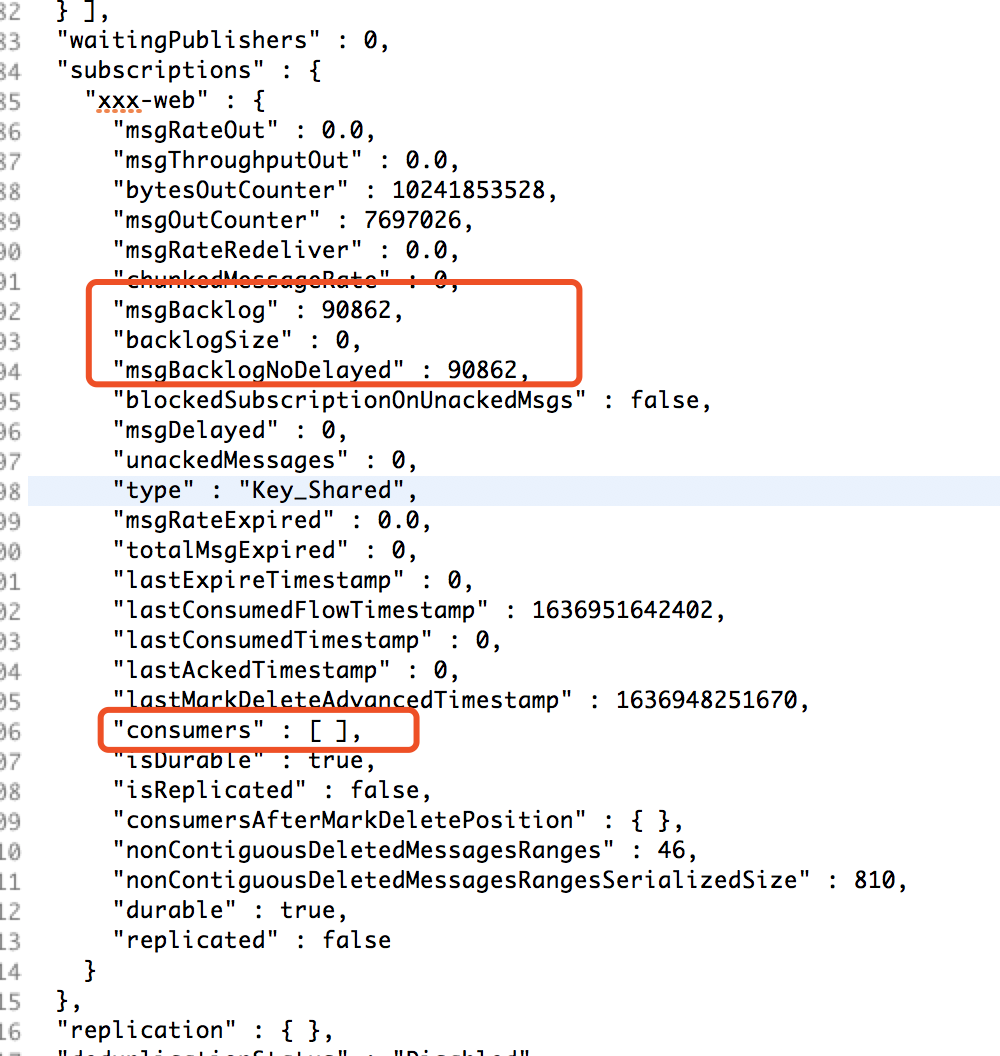
|
补充5: 顺着补充4, 我查看了这个topic其他正常的分区,正常分区的stats是: 也就是说,在这种场景下,somehow的未知原因会导致严重堆积/不均衡的分区会丢失自己的consumer? 下附脱敏后的topic stats(只把订阅者名称改了,其余都保持现场): |
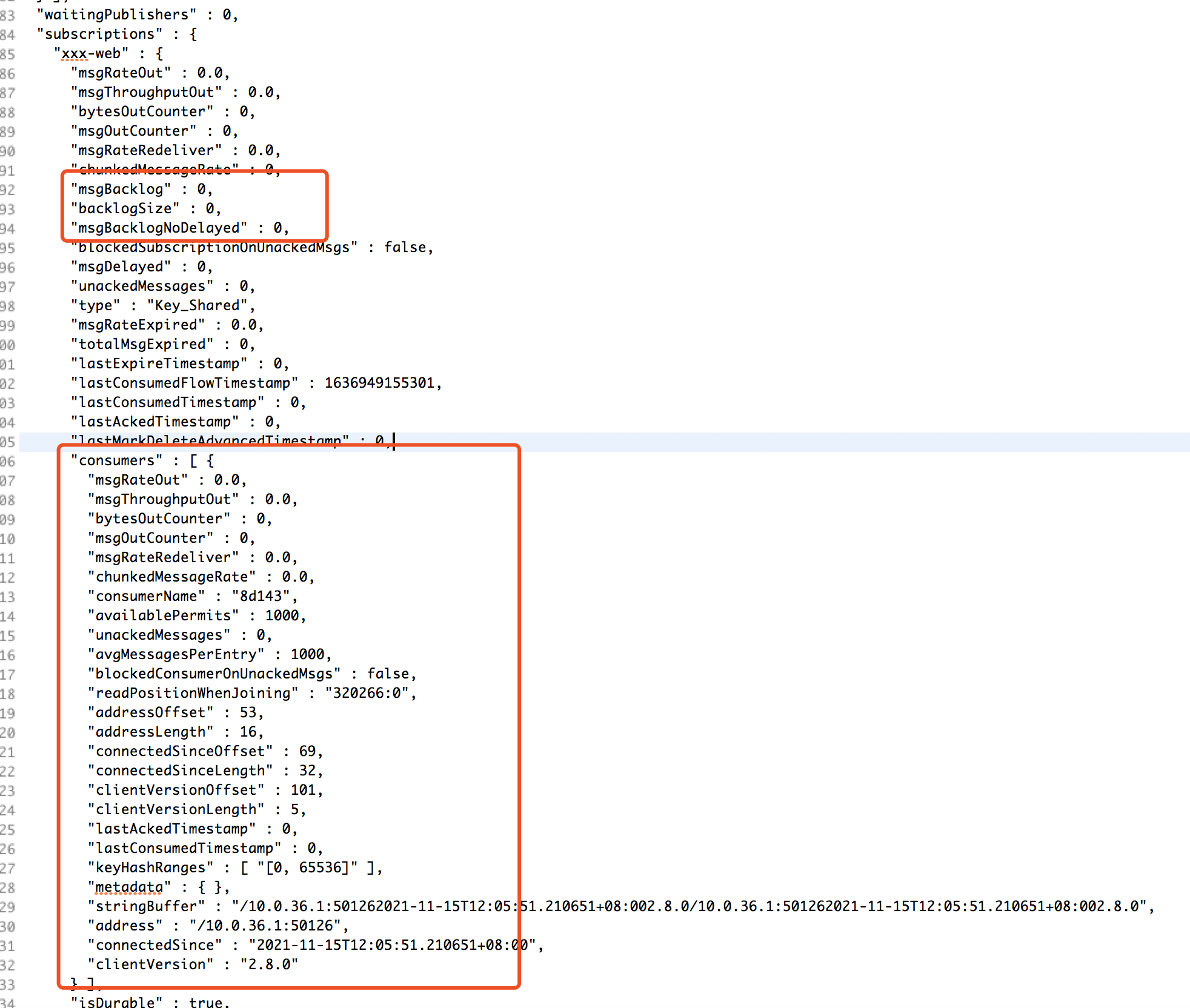
|
补充6: 假死原因是因为垃圾回收用的是G1,之前用ZGC的时候,即使积压了几十万,从来没死过,过会就缓过来了。 现在我把consumer重启(垃圾回收还是G1),问题分区的topic stats:然后跑一跑又停了(消费者hang住了),但是topic stats中的consuemrs还在,但是我估计等一会又会消失,正在观察。 |
|
补充7: 目前从重现&各种现象下的分析结果是:消费者如果使用的是G1(已经做调优),并且在海量消息段时间涌入时,会出现假死,然后从pulsar-broker上断开。导致无法消费。
后边我们会将消费者的GC切换为ZGC验证是否恢复正常。 |
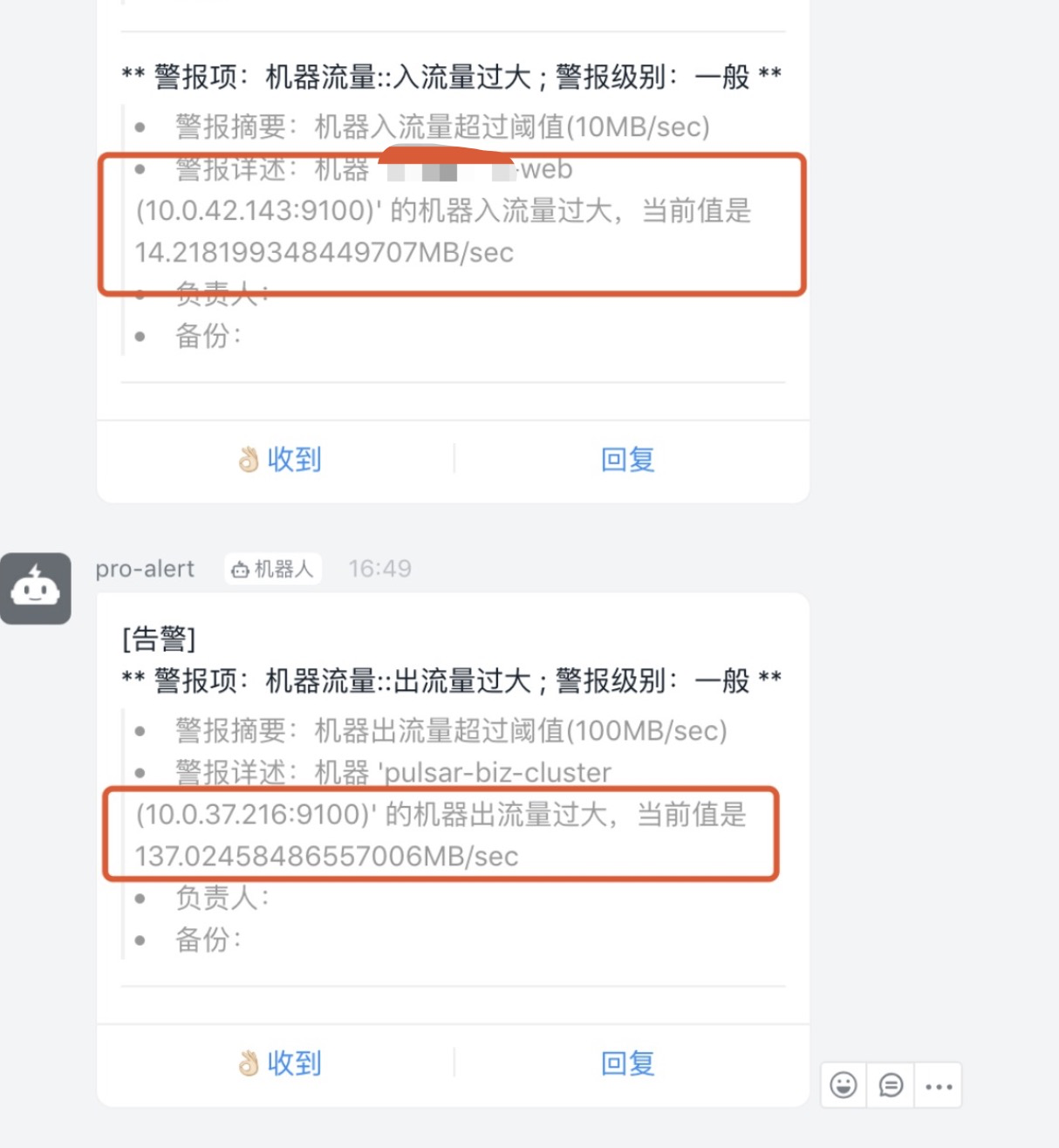
|
补充8: ZGC也不行,经查是因为每批发送40个消息,之前用ZGC的时候是每批发送10个消息。 如下图,是consumer刚恢复时pulsar给consumer吐出的速率,但是一个消费者的TPS是600多(业务重),肯定是无法消费过来的,但还接受海量的消息,会不会把内存中的queue撑爆了? 我的问题是:为啥我的消费能力只有600多,但是pulsar却给我这么海量的消息,我并没有取这么多消息啊。 |

|
目前阶段定位是: |
|
just a little translation to make this issue searchable in english language: Suspected pulsar-broker bug, but I can't confirm it. Contents. (1). Reasons for not using English I am not good at English, although I can read it without any problem, but if I state the whole problem & phenomenon in English, I can't guarantee the accurate line of the statement, so I use Chinese. (2). pulsar deployment version & details & architecture pulsar version is 2.8.0, deployed on openjdk11, the specific version number is: 11.0.12. Deployment details and details. (3). Problems & Phenomena & Usage Statement & Desensitization Code
The average size of this partition topic messages sent. pulsar_rate_in. pulsar_rate_out: The time of the spike is the time we found not consumed, but it is possible that there was already a problem before, so high is the restart of the consumer.
consumer is using the key-sharding method of consumption, desensitization code |
|
@hepyu I think there are 2 questions
|
|
you could try to enable pool message in consumer setting, this could reduce GC impact in consumer. |
2这个调整也没用。类似的调整消费rate等也是没有用的。都是只能让服务慢点死。 造成本issue的根本原因: 这个问题只有两种解决方式: pulsar的这个设计本身来说没有任何问题,push类型本来就是给高tps消费能力的场景使用的。但是我有个建议:是否能在push的这个方案上进行优化,来解决我们遇到的这个问题,比如key_shard的threadpool的无界队列是否可以可配,结合对broker的通知来控制推送强度。不过,这个貌似很麻烦。 这个issue我关了。 |
|
补充一下: |
|
附: 我们最终采取的方案是:不使用client提供的方案,自己实现。 |
@wangjialing218 @hpvd @codelipenghui |
|
我们使用pulsar 2.8.1版本,在broker.conf中使用key_shared一致性哈希,没有再出现接收不到消息的问题。 |
其实这个issue最后查明也不是说”收不到消息“,是因为大量堆积后push大量推,把服务的pulsar-client的无界队列打慢造成内存泄漏(消费能力严重不足),造成了“收不到消息”的现象。 已经解决了,在前文里。 |
疑似pulsar-broker的bug,但我无法确认。
目录:
(1).不用英文的原因
(2).pulsar部署版本&细节&架构
(3).问题&现象与使用陈述&脱敏代码
1.问题
2.现象与使用陈述&脱敏代码
(1).不用英文的原因
我英文不好,虽然看懂没有问题,但是如果用英文陈述整个问题&现象的话,无法保证陈述的准确行,故使用中文。
(2).pulsar部署版本&细节&架构
pulsar版本是2.8.0,部署在openjdk11上,具体版本号是:11.0.12。
在aws海外部署,使用机型是c5a.2xlarge(8c16g),一共是3台,每台部署一个broker、bookie、zk。启动命令的参数没有修改都是默认值。
部署详情与细节:
pulsar-7:aws上部署生产级别的5节点pulsar集群
https://mp.weixin.qq.com/s/YwCr-l2WcM4fJVg7NIx_HA
(3).问题&现象与使用陈述&脱敏代码
1.问题


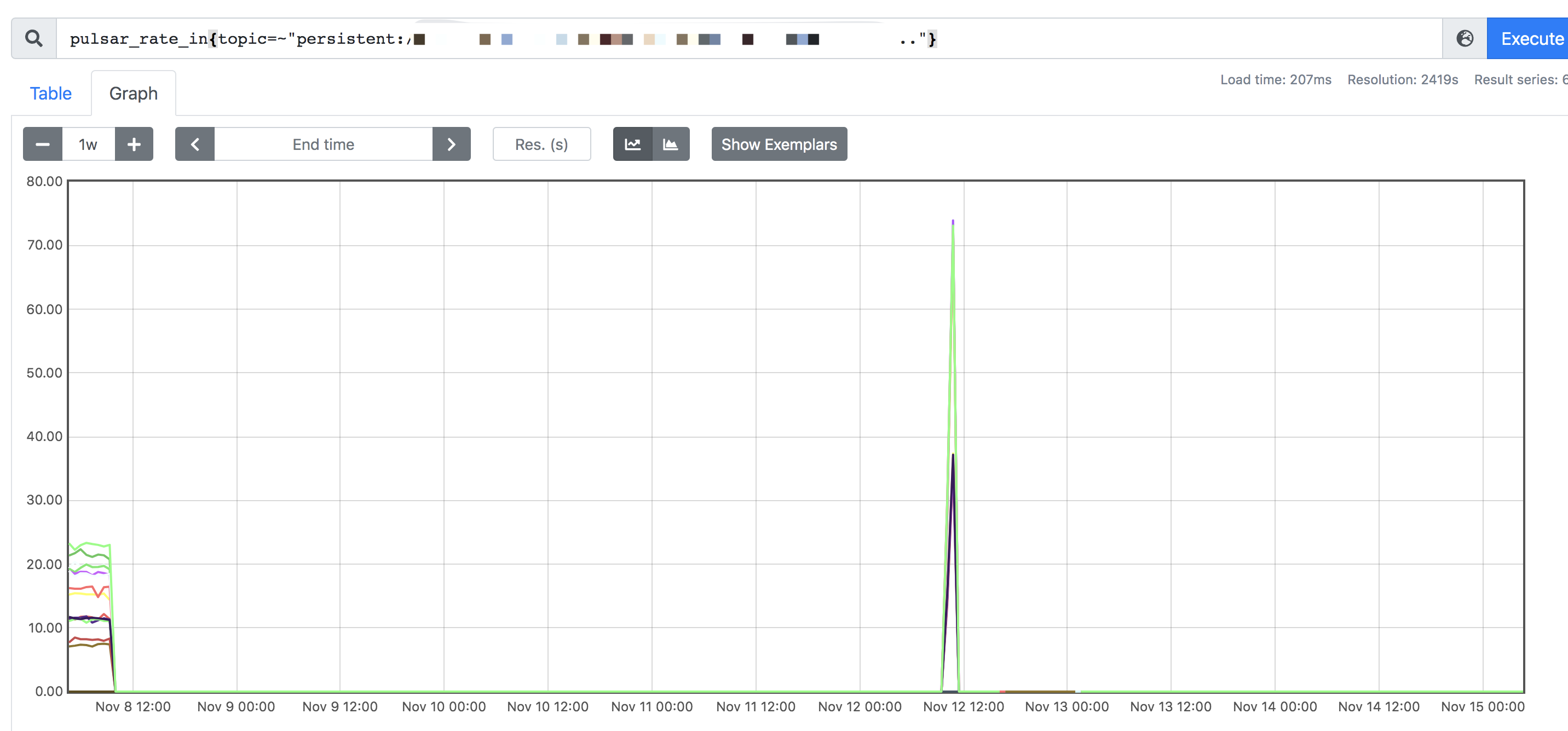

40个分区的topic消息严重不均衡下个别partition无法被consumer消费。最近一次是有两个分区各自堆积到30万左右(backlog值)。
这个分区topic消息发送平均大小:
pulsar_rate_in:
pulsar_rate_out:spike的时间是我们发现不消费的时间,但有可能之前就已经有问题了,这么高是重启了consumer。
2.现象与使用陈述&脱敏代码
producer使用的是批量发送(平均8条左右是一批,最多40条是一批),并且是异步发送,使用key-sharding的方式发送到这个topic的不同分区,脱敏代码:
consumer使用的是key-sharding方式消费,脱敏代码:
The text was updated successfully, but these errors were encountered: