From bf742fb2ae3e453f530e83a9f04ad5dca300f311 Mon Sep 17 00:00:00 2001
From: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Date: Wed, 12 Oct 2022 10:11:20 +0200
Subject: [PATCH] Add LiLT (#19450)
* First draft
* Fix more things
* Improve more things
* Remove some head models
* Fix more things
* Add missing layers
* Remove tokenizer
* Fix more things
* Fix copied from statements
* Make all tests pass
* Remove print statements
* Remove files
* Fix README and docs
* Add integration test and fix organization
* Add tips
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Make tests faster, improve docs
* Fix doc tests
* Add model to toctree
* Add docs
* Add note about creating new checkpoint
* Remove is_decoder
* Make tests smaller, add docs
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
---
README.md | 1 +
README_ko.md | 1 +
README_zh-hans.md | 1 +
README_zh-hant.md | 1 +
docs/source/en/_toctree.yml | 2 +
docs/source/en/index.mdx | 2 +
docs/source/en/model_doc/lilt.mdx | 73 +
src/transformers/__init__.py | 20 +
src/transformers/models/__init__.py | 1 +
.../models/auto/configuration_auto.py | 3 +
src/transformers/models/auto/modeling_auto.py | 4 +
.../models/auto/tokenization_auto.py | 1 +
src/transformers/models/lilt/__init__.py | 64 +
.../models/lilt/configuration_lilt.py | 138 ++
src/transformers/models/lilt/modeling_lilt.py | 1211 +++++++++++++++++
src/transformers/utils/dummy_pt_objects.py | 38 +
tests/models/lilt/__init__.py | 0
tests/models/lilt/test_modeling_lilt.py | 288 ++++
utils/documentation_tests.txt | 1 +
19 files changed, 1850 insertions(+)
create mode 100644 docs/source/en/model_doc/lilt.mdx
create mode 100644 src/transformers/models/lilt/__init__.py
create mode 100644 src/transformers/models/lilt/configuration_lilt.py
create mode 100644 src/transformers/models/lilt/modeling_lilt.py
create mode 100644 tests/models/lilt/__init__.py
create mode 100644 tests/models/lilt/test_modeling_lilt.py
diff --git a/README.md b/README.md
index 20e30633afc956..15815de6336a14 100644
--- a/README.md
+++ b/README.md
@@ -323,6 +323,7 @@ Current number of checkpoints: ** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](https://huggingface.co/docs/transformers/main/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/README_ko.md b/README_ko.md
index 47c1e63a468155..06dcfc64783107 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -273,6 +273,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](https://huggingface.co/docs/transformers/main/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 1235b481ba961b..591956ee521361 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -297,6 +297,7 @@ conda install -c huggingface transformers
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) 由 Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei 发布。
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (来自 Meta AI) 伴随论文 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 由 Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 发布。
+1. **[LiLT](https://huggingface.co/docs/transformers/main/model_doc/lilt)** (来自 South China University of Technology) 伴随论文 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 由 Jiapeng Wang, Lianwen Jin, Kai Ding 发布。
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (来自 Google AI) released 伴随论文 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 由 Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 发布。
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 17e47a8d7e42b2..2968b734aeaccd 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -309,6 +309,7 @@ conda install -c huggingface transformers
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](https://huggingface.co/docs/transformers/main/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 8bd477a612b1e7..1083d908b79c80 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -275,6 +275,8 @@
title: LayoutLM
- local: model_doc/led
title: LED
+ - local: model_doc/lilt
+ title: LiLT
- local: model_doc/longformer
title: Longformer
- local: model_doc/longt5
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index a96440a29d7e21..4ca9246941d49c 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -112,6 +112,7 @@ The documentation is organized into five sections:
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
@@ -262,6 +263,7 @@ Flax), PyTorch, and/or TensorFlow.
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/lilt.mdx b/docs/source/en/model_doc/lilt.mdx
new file mode 100644
index 00000000000000..5dad69b3f04480
--- /dev/null
+++ b/docs/source/en/model_doc/lilt.mdx
@@ -0,0 +1,73 @@
+
+
+# LiLT
+
+## Overview
+
+The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
+languages.
+
+The abstract from the paper is the following:
+
+*Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.*
+
+Tips:
+
+- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
+
+```
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
+- As (lilt-roberta-en-base)[https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base] uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
+The same is true for (lilt-roberta-en-base)[https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base]: one can use [`LayoutXLMTokenizerFast`] for that model.
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+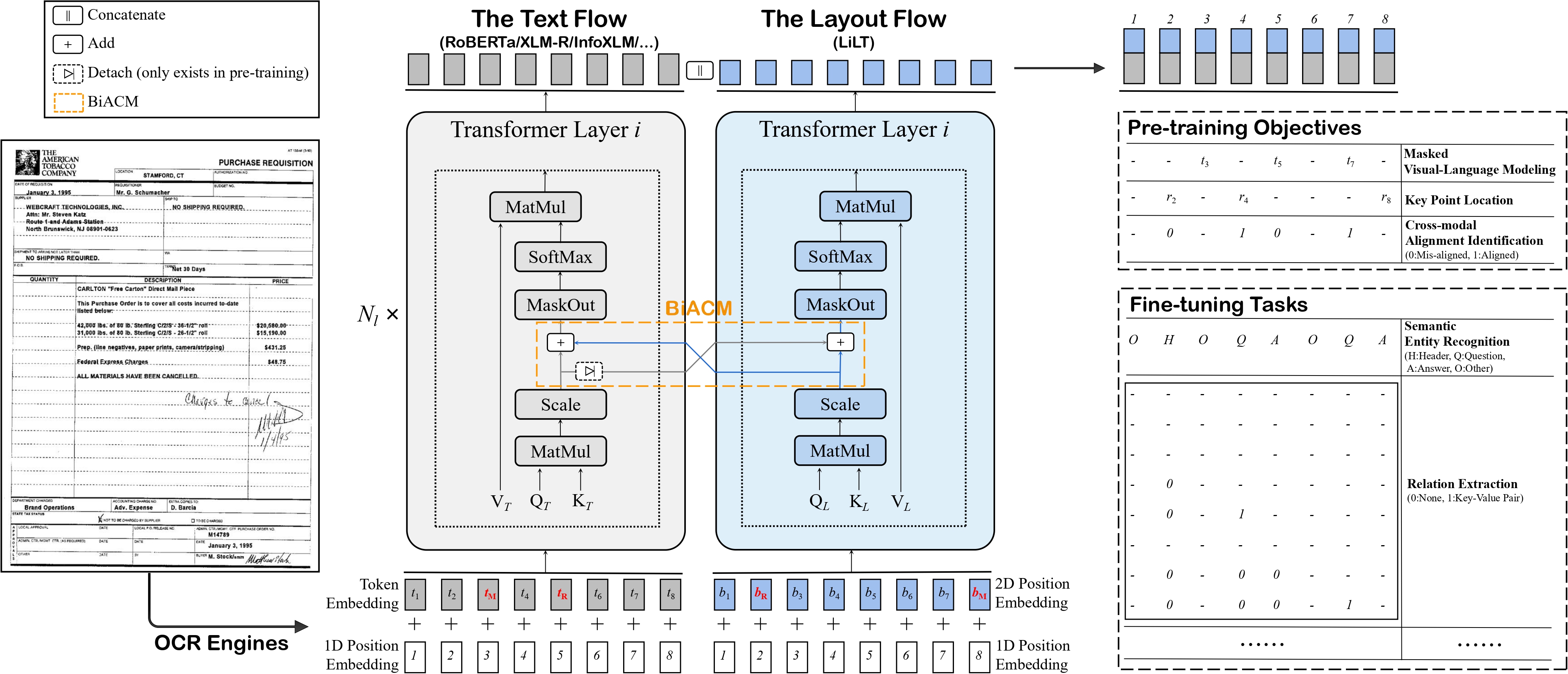 +
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+ - forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+ - forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+ - forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index f87ff33fba1711..41b49bf600e7b1 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -257,6 +257,7 @@
"models.layoutxlm": ["LayoutXLMProcessor"],
"models.led": ["LED_PRETRAINED_CONFIG_ARCHIVE_MAP", "LEDConfig", "LEDTokenizer"],
"models.levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"],
+ "models.lilt": ["LILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LiltConfig"],
"models.longformer": ["LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongformerConfig", "LongformerTokenizer"],
"models.longt5": ["LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongT5Config"],
"models.luke": ["LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP", "LukeConfig", "LukeTokenizer"],
@@ -1822,6 +1823,16 @@
"RobertaPreTrainedModel",
]
)
+ _import_structure["models.lilt"].extend(
+ [
+ "LILT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LiltForQuestionAnswering",
+ "LiltForSequenceClassification",
+ "LiltForTokenClassification",
+ "LiltModel",
+ "LiltPreTrainedModel",
+ ]
+ )
_import_structure["models.roformer"].extend(
[
"ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3271,6 +3282,7 @@
from .models.layoutxlm import LayoutXLMProcessor
from .models.led import LED_PRETRAINED_CONFIG_ARCHIVE_MAP, LEDConfig, LEDTokenizer
from .models.levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
+ from .models.lilt import LILT_PRETRAINED_CONFIG_ARCHIVE_MAP, LiltConfig
from .models.longformer import LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, LongformerConfig, LongformerTokenizer
from .models.longt5 import LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP, LongT5Config
from .models.luke import LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP, LukeConfig, LukeTokenizer
@@ -4269,6 +4281,14 @@
LevitModel,
LevitPreTrainedModel,
)
+ from .models.lilt import (
+ LILT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LiltForQuestionAnswering,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltModel,
+ LiltPreTrainedModel,
+ )
from .models.longformer import (
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
LongformerForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 0f363b22c6800d..1f4c68a38c6dde 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -83,6 +83,7 @@
layoutxlm,
led,
levit,
+ lilt,
longformer,
longt5,
luke,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index a2a17f63fb2fa5..d36962f97ee04b 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -85,6 +85,7 @@
("layoutlmv3", "LayoutLMv3Config"),
("led", "LEDConfig"),
("levit", "LevitConfig"),
+ ("lilt", "LiltConfig"),
("longformer", "LongformerConfig"),
("longt5", "LongT5Config"),
("luke", "LukeConfig"),
@@ -221,6 +222,7 @@
("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("lilt", "LILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longt5", "LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -360,6 +362,7 @@
("layoutxlm", "LayoutXLM"),
("led", "LED"),
("levit", "LeViT"),
+ ("lilt", "LiLT"),
("longformer", "Longformer"),
("longt5", "LongT5"),
("luke", "LUKE"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index edd61e1da9b6f3..9b83741aa96b5c 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -84,6 +84,7 @@
("layoutlmv3", "LayoutLMv3Model"),
("led", "LEDModel"),
("levit", "LevitModel"),
+ ("lilt", "LiltModel"),
("longformer", "LongformerModel"),
("longt5", "LongT5Model"),
("luke", "LukeModel"),
@@ -544,6 +545,7 @@
("layoutlmv2", "LayoutLMv2ForSequenceClassification"),
("layoutlmv3", "LayoutLMv3ForSequenceClassification"),
("led", "LEDForSequenceClassification"),
+ ("lilt", "LiltForSequenceClassification"),
("longformer", "LongformerForSequenceClassification"),
("luke", "LukeForSequenceClassification"),
("markuplm", "MarkupLMForSequenceClassification"),
@@ -600,6 +602,7 @@
("layoutlmv2", "LayoutLMv2ForQuestionAnswering"),
("layoutlmv3", "LayoutLMv3ForQuestionAnswering"),
("led", "LEDForQuestionAnswering"),
+ ("lilt", "LiltForQuestionAnswering"),
("longformer", "LongformerForQuestionAnswering"),
("luke", "LukeForQuestionAnswering"),
("lxmert", "LxmertForQuestionAnswering"),
@@ -673,6 +676,7 @@
("layoutlm", "LayoutLMForTokenClassification"),
("layoutlmv2", "LayoutLMv2ForTokenClassification"),
("layoutlmv3", "LayoutLMv3ForTokenClassification"),
+ ("lilt", "LiltForTokenClassification"),
("longformer", "LongformerForTokenClassification"),
("luke", "LukeForTokenClassification"),
("markuplm", "MarkupLMForTokenClassification"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 43fb6ce352a3f1..e29a5b19ddc07d 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -140,6 +140,7 @@
("layoutlmv3", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
("layoutxlm", ("LayoutXLMTokenizer", "LayoutXLMTokenizerFast" if is_tokenizers_available() else None)),
("led", ("LEDTokenizer", "LEDTokenizerFast" if is_tokenizers_available() else None)),
+ ("lilt", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
("longformer", ("LongformerTokenizer", "LongformerTokenizerFast" if is_tokenizers_available() else None)),
(
"longt5",
diff --git a/src/transformers/models/lilt/__init__.py b/src/transformers/models/lilt/__init__.py
new file mode 100644
index 00000000000000..f44c87f4b59c6d
--- /dev/null
+++ b/src/transformers/models/lilt/__init__.py
@@ -0,0 +1,64 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_lilt": ["LILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LiltConfig"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_lilt"] = [
+ "LILT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LiltForQuestionAnswering",
+ "LiltForSequenceClassification",
+ "LiltForTokenClassification",
+ "LiltModel",
+ "LiltPreTrainedModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_lilt import LILT_PRETRAINED_CONFIG_ARCHIVE_MAP, LiltConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_lilt import (
+ LILT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LiltForQuestionAnswering,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltModel,
+ LiltPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/lilt/configuration_lilt.py b/src/transformers/models/lilt/configuration_lilt.py
new file mode 100644
index 00000000000000..6306a56330fc12
--- /dev/null
+++ b/src/transformers/models/lilt/configuration_lilt.py
@@ -0,0 +1,138 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" LiLT configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+LILT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "SCUT-DLVCLab/lilt-roberta-en-base": (
+ "https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base/resolve/main/config.json"
+ ),
+}
+
+
+class LiltConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`LiltModel`]. It is used to instantiate a LiLT
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the LiLT
+ [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) architecture.
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 30522):
+ Vocabulary size of the LiLT model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`LiltModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer. Should be a multiple of 24.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 512):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 2):
+ The vocabulary size of the `token_type_ids` passed when calling [`LiltModel`].
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
+ Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
+ positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
+ with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ classifier_dropout (`float`, *optional*):
+ The dropout ratio for the classification head.
+ channel_shrink_ratio (`int`, *optional*, defaults to 4):
+ The shrink ratio compared to the `hidden_size` for the channel dimension of the layout embeddings.
+ max_2d_position_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum value that the 2D position embedding might ever be used with. Typically set this to something
+ large just in case (e.g., 1024).
+
+ Examples:
+
+ ```python
+ >>> from transformers import LiltConfig, LiltModel
+
+ >>> # Initializing a LiLT SCUT-DLVCLab/lilt-roberta-en-base style configuration
+ >>> configuration = LiltConfig()
+ >>> # Randomly initializing a model from the SCUT-DLVCLab/lilt-roberta-en-base style configuration
+ >>> model = LiltModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "lilt"
+
+ def __init__(
+ self,
+ vocab_size=30522,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ pad_token_id=0,
+ position_embedding_type="absolute",
+ use_cache=True,
+ classifier_dropout=None,
+ channel_shrink_ratio=4,
+ max_2d_position_embeddings=1024,
+ **kwargs
+ ):
+ super().__init__(pad_token_id=pad_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.position_embedding_type = position_embedding_type
+ self.use_cache = use_cache
+ self.classifier_dropout = classifier_dropout
+ self.channel_shrink_ratio = channel_shrink_ratio
+ self.max_2d_position_embeddings = max_2d_position_embeddings
diff --git a/src/transformers/models/lilt/modeling_lilt.py b/src/transformers/models/lilt/modeling_lilt.py
new file mode 100644
index 00000000000000..c78490f4b43969
--- /dev/null
+++ b/src/transformers/models/lilt/modeling_lilt.py
@@ -0,0 +1,1211 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch LiLT model."""
+
+import math
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPooling,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from .configuration_lilt import LiltConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "LiltConfig"
+
+LILT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "SCUT-DLVCLab/lilt-roberta-en-base",
+ # See all LiLT models at https://huggingface.co/models?filter=lilt
+]
+
+
+class LiltTextEmbeddings(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+
+ # End copy
+ self.padding_idx = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
+ )
+
+ def forward(
+ self,
+ input_ids=None,
+ token_type_ids=None,
+ position_ids=None,
+ inputs_embeds=None,
+ ):
+ if position_ids is None:
+ if input_ids is not None:
+ # Create the position ids from the input token ids. Any padded tokens remain padded.
+ position_ids = self.create_position_ids_from_input_ids(input_ids, self.padding_idx).to(
+ input_ids.device
+ )
+ else:
+ position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
+
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings, position_ids
+
+ def create_position_ids_from_input_ids(self, input_ids, padding_idx):
+ """
+ Args:
+ Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding
+ symbols are ignored. This is modified from fairseq's `utils.make_positions`.
+ x: torch.Tensor x:
+ Returns: torch.Tensor
+ """
+ # The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
+ mask = input_ids.ne(padding_idx).int()
+ incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask)) * mask
+ return incremental_indices.long() + padding_idx
+
+ def create_position_ids_from_inputs_embeds(self, inputs_embeds):
+ """
+ Args:
+ We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.:
+ inputs_embeds: torch.Tensor
+ Returns: torch.Tensor
+ """
+ input_shape = inputs_embeds.size()[:-1]
+ sequence_length = input_shape[1]
+
+ position_ids = torch.arange(
+ self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
+ )
+ return position_ids.unsqueeze(0).expand(input_shape)
+
+
+class LiltLayoutEmbeddings(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ # we divide the hidden_size by 6 here as there are 6 different layout embeddings,
+ # namely left_position, upper_position, right_position, lower_position, height, width
+ self.x_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.y_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.h_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.w_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+
+ self.padding_idx = config.pad_token_id
+ self.box_position_embeddings = nn.Embedding(
+ config.max_position_embeddings,
+ config.hidden_size // config.channel_shrink_ratio,
+ padding_idx=self.padding_idx,
+ )
+ self.box_linear_embeddings = nn.Linear(
+ in_features=config.hidden_size, out_features=config.hidden_size // config.channel_shrink_ratio
+ )
+ self.LayerNorm = nn.LayerNorm(config.hidden_size // config.channel_shrink_ratio, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, bbox=None, position_ids=None):
+ try:
+ left_position_embeddings = self.x_position_embeddings(bbox[:, :, 0])
+ upper_position_embeddings = self.y_position_embeddings(bbox[:, :, 1])
+ right_position_embeddings = self.x_position_embeddings(bbox[:, :, 2])
+ lower_position_embeddings = self.y_position_embeddings(bbox[:, :, 3])
+ except IndexError as e:
+ raise IndexError("The `bbox` coordinate values should be within 0-1000 range.") from e
+
+ h_position_embeddings = self.h_position_embeddings(bbox[:, :, 3] - bbox[:, :, 1])
+ w_position_embeddings = self.w_position_embeddings(bbox[:, :, 2] - bbox[:, :, 0])
+
+ spatial_position_embeddings = torch.cat(
+ [
+ left_position_embeddings,
+ upper_position_embeddings,
+ right_position_embeddings,
+ lower_position_embeddings,
+ h_position_embeddings,
+ w_position_embeddings,
+ ],
+ dim=-1,
+ )
+ spatial_position_embeddings = self.box_linear_embeddings(spatial_position_embeddings)
+ box_position_embeddings = self.box_position_embeddings(position_ids)
+
+ spatial_position_embeddings = spatial_position_embeddings + box_position_embeddings
+
+ spatial_position_embeddings = self.LayerNorm(spatial_position_embeddings)
+ spatial_position_embeddings = self.dropout(spatial_position_embeddings)
+
+ return spatial_position_embeddings
+
+
+class LiltSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.layout_query = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+ self.layout_key = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+ self.layout_value = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.channel_shrink_ratio = config.channel_shrink_ratio
+
+ def transpose_for_scores(self, x, r=1):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size // r)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states,
+ layout_inputs,
+ attention_mask=None,
+ head_mask=None,
+ output_attentions=False,
+ ):
+
+ layout_value_layer = self.transpose_for_scores(self.layout_value(layout_inputs), r=self.channel_shrink_ratio)
+ layout_key_layer = self.transpose_for_scores(self.layout_key(layout_inputs), r=self.channel_shrink_ratio)
+ layout_query_layer = self.transpose_for_scores(self.layout_query(layout_inputs), r=self.channel_shrink_ratio)
+
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+ layout_attention_scores = torch.matmul(layout_query_layer, layout_key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ tmp_attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ tmp_layout_attention_scores = layout_attention_scores / math.sqrt(
+ self.attention_head_size // self.channel_shrink_ratio
+ )
+ attention_scores = tmp_attention_scores + tmp_layout_attention_scores
+ layout_attention_scores = tmp_layout_attention_scores + tmp_attention_scores
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ layout_attention_scores = layout_attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ layout_attention_probs = nn.Softmax(dim=-1)(layout_attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ layout_attention_probs = self.dropout(layout_attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ layout_attention_probs = layout_attention_probs * head_mask
+
+ layout_context_layer = torch.matmul(layout_attention_probs, layout_value_layer)
+
+ layout_context_layer = layout_context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = layout_context_layer.size()[:-2] + (self.all_head_size // self.channel_shrink_ratio,)
+ layout_context_layer = layout_context_layer.view(*new_context_layer_shape)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in RobertaModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (
+ ((context_layer, layout_context_layer), attention_probs)
+ if output_attentions
+ else ((context_layer, layout_context_layer),)
+ )
+
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
+class LiltSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class LiltAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = LiltSelfAttention(config, position_embedding_type=position_embedding_type)
+ self.output = LiltSelfOutput(config)
+ self.pruned_heads = set()
+
+ ori_hidden_size = config.hidden_size
+ config.hidden_size = config.hidden_size // config.channel_shrink_ratio
+ self.layout_output = LiltSelfOutput(config)
+ config.hidden_size = ori_hidden_size
+
+ # Copied from transformers.models.bert.modeling_bert.BertAttention.prune_heads
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ head_mask,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0][0], hidden_states)
+ layout_attention_output = self.layout_output(self_outputs[0][1], layout_inputs)
+ outputs = ((attention_output, layout_attention_output),) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertIntermediate
+class LiltIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertOutput
+class LiltOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class LiltLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = LiltAttention(config)
+ self.intermediate = LiltIntermediate(config)
+ self.output = LiltOutput(config)
+
+ ori_hidden_size = config.hidden_size
+ ori_intermediate_size = config.intermediate_size
+ config.hidden_size = config.hidden_size // config.channel_shrink_ratio
+ config.intermediate_size = config.intermediate_size // config.channel_shrink_ratio
+ self.layout_intermediate = LiltIntermediate(config)
+ self.layout_output = LiltOutput(config)
+ config.hidden_size = ori_hidden_size
+ config.intermediate_size = ori_intermediate_size
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_attention_outputs = self.attention(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0][0]
+ layout_attention_output = self_attention_outputs[0][1]
+
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ layout_layer_output = apply_chunking_to_forward(
+ self.layout_feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, layout_attention_output
+ )
+ outputs = ((layer_output, layout_layer_output),) + outputs
+
+ return outputs
+
+ # Copied from transformers.models.bert.modeling_bert.BertLayer.feed_forward_chunk
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+ def layout_feed_forward_chunk(self, attention_output):
+ intermediate_output = self.layout_intermediate(attention_output)
+ layer_output = self.layout_output(intermediate_output, attention_output)
+ return layer_output
+
+
+class LiltEncoder(nn.Module):
+ # Copied from transformers.models.bert.modeling_bert.BertEncoder.__init__ with Bert->Lilt
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([LiltLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ layer_head_mask,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0][0]
+ layout_inputs = layer_outputs[0][1]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ all_hidden_states,
+ all_self_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+# Copied from transformers.models.bert.modeling_bert.BertPooler
+class LiltPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaPreTrainedModel with Roberta->Lilt,roberta->lilt
+class LiltPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = LiltConfig
+ base_model_prefix = "lilt"
+ supports_gradient_checkpointing = True
+
+ # Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, LiltEncoder):
+ module.gradient_checkpointing = value
+
+ def update_keys_to_ignore(self, config, del_keys_to_ignore):
+ """Remove some keys from ignore list"""
+ if not config.tie_word_embeddings:
+ # must make a new list, or the class variable gets modified!
+ self._keys_to_ignore_on_save = [k for k in self._keys_to_ignore_on_save if k not in del_keys_to_ignore]
+ self._keys_to_ignore_on_load_missing = [
+ k for k in self._keys_to_ignore_on_load_missing if k not in del_keys_to_ignore
+ ]
+
+
+LILT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`LiltConfig`]): Model configuration class with all the parameters of the
+ model. Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+LILT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`RobertaTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner. See [Overview](#Overview) for normalization.
+
+ attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare LiLT Model transformer outputting raw hidden-states without any specific head on top.",
+ LILT_START_DOCSTRING,
+)
+class LiltModel(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = LiltTextEmbeddings(config)
+ self.layout_embeddings = LiltLayoutEmbeddings(config)
+ self.encoder = LiltEncoder(config)
+
+ self.pooler = LiltPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ bbox: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPooling]:
+ r"""
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModel
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if bbox is None:
+ bbox = torch.zeros(input_shape + (4,), dtype=torch.long, device=device)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length)), device=device)
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output, position_ids = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ )
+
+ layout_embedding_output = self.layout_embeddings(bbox=bbox, position_ids=position_ids)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ layout_embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ LiLT Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
+ output) e.g. for GLUE tasks.
+ """,
+ LILT_START_DOCSTRING,
+)
+class LiltForSequenceClassification(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaForSequenceClassification.__init__ with Roberta->Lilt, roberta->lilt
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.config = config
+
+ self.lilt = LiltModel(config, add_pooling_layer=False)
+ self.classifier = LiltClassificationHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ bbox: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModelForSequenceClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> predicted_class_idx = outputs.logits.argmax(-1).item()
+ >>> predicted_class = model.config.id2label[predicted_class_idx]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.lilt(
+ input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = outputs[0]
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Lilt Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
+ Named-Entity-Recognition (NER) tasks.
+ """,
+ LILT_START_DOCSTRING,
+)
+class LiltForTokenClassification(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaForTokenClassification.__init__ with Roberta->Lilt, roberta->lilt
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.lilt = LiltModel(config, add_pooling_layer=False)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ bbox: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForTokenClassification
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModelForTokenClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> predicted_class_indices = outputs.logits.argmax(-1)
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.lilt(
+ input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ sequence_output = self.dropout(sequence_output)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaClassificationHead with Roberta->Lilt
+class LiltClassificationHead(nn.Module):
+ """Head for sentence-level classification tasks."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
+
+ def forward(self, features, **kwargs):
+ x = features[:, 0, :] # take
+
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+ - forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+ - forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+ - forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index f87ff33fba1711..41b49bf600e7b1 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -257,6 +257,7 @@
"models.layoutxlm": ["LayoutXLMProcessor"],
"models.led": ["LED_PRETRAINED_CONFIG_ARCHIVE_MAP", "LEDConfig", "LEDTokenizer"],
"models.levit": ["LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LevitConfig"],
+ "models.lilt": ["LILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LiltConfig"],
"models.longformer": ["LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongformerConfig", "LongformerTokenizer"],
"models.longt5": ["LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP", "LongT5Config"],
"models.luke": ["LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP", "LukeConfig", "LukeTokenizer"],
@@ -1822,6 +1823,16 @@
"RobertaPreTrainedModel",
]
)
+ _import_structure["models.lilt"].extend(
+ [
+ "LILT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LiltForQuestionAnswering",
+ "LiltForSequenceClassification",
+ "LiltForTokenClassification",
+ "LiltModel",
+ "LiltPreTrainedModel",
+ ]
+ )
_import_structure["models.roformer"].extend(
[
"ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3271,6 +3282,7 @@
from .models.layoutxlm import LayoutXLMProcessor
from .models.led import LED_PRETRAINED_CONFIG_ARCHIVE_MAP, LEDConfig, LEDTokenizer
from .models.levit import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP, LevitConfig
+ from .models.lilt import LILT_PRETRAINED_CONFIG_ARCHIVE_MAP, LiltConfig
from .models.longformer import LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, LongformerConfig, LongformerTokenizer
from .models.longt5 import LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP, LongT5Config
from .models.luke import LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP, LukeConfig, LukeTokenizer
@@ -4269,6 +4281,14 @@
LevitModel,
LevitPreTrainedModel,
)
+ from .models.lilt import (
+ LILT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LiltForQuestionAnswering,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltModel,
+ LiltPreTrainedModel,
+ )
from .models.longformer import (
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
LongformerForMaskedLM,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 0f363b22c6800d..1f4c68a38c6dde 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -83,6 +83,7 @@
layoutxlm,
led,
levit,
+ lilt,
longformer,
longt5,
luke,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index a2a17f63fb2fa5..d36962f97ee04b 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -85,6 +85,7 @@
("layoutlmv3", "LayoutLMv3Config"),
("led", "LEDConfig"),
("levit", "LevitConfig"),
+ ("lilt", "LiltConfig"),
("longformer", "LongformerConfig"),
("longt5", "LongT5Config"),
("luke", "LukeConfig"),
@@ -221,6 +222,7 @@
("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("lilt", "LILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("longt5", "LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -360,6 +362,7 @@
("layoutxlm", "LayoutXLM"),
("led", "LED"),
("levit", "LeViT"),
+ ("lilt", "LiLT"),
("longformer", "Longformer"),
("longt5", "LongT5"),
("luke", "LUKE"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index edd61e1da9b6f3..9b83741aa96b5c 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -84,6 +84,7 @@
("layoutlmv3", "LayoutLMv3Model"),
("led", "LEDModel"),
("levit", "LevitModel"),
+ ("lilt", "LiltModel"),
("longformer", "LongformerModel"),
("longt5", "LongT5Model"),
("luke", "LukeModel"),
@@ -544,6 +545,7 @@
("layoutlmv2", "LayoutLMv2ForSequenceClassification"),
("layoutlmv3", "LayoutLMv3ForSequenceClassification"),
("led", "LEDForSequenceClassification"),
+ ("lilt", "LiltForSequenceClassification"),
("longformer", "LongformerForSequenceClassification"),
("luke", "LukeForSequenceClassification"),
("markuplm", "MarkupLMForSequenceClassification"),
@@ -600,6 +602,7 @@
("layoutlmv2", "LayoutLMv2ForQuestionAnswering"),
("layoutlmv3", "LayoutLMv3ForQuestionAnswering"),
("led", "LEDForQuestionAnswering"),
+ ("lilt", "LiltForQuestionAnswering"),
("longformer", "LongformerForQuestionAnswering"),
("luke", "LukeForQuestionAnswering"),
("lxmert", "LxmertForQuestionAnswering"),
@@ -673,6 +676,7 @@
("layoutlm", "LayoutLMForTokenClassification"),
("layoutlmv2", "LayoutLMv2ForTokenClassification"),
("layoutlmv3", "LayoutLMv3ForTokenClassification"),
+ ("lilt", "LiltForTokenClassification"),
("longformer", "LongformerForTokenClassification"),
("luke", "LukeForTokenClassification"),
("markuplm", "MarkupLMForTokenClassification"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 43fb6ce352a3f1..e29a5b19ddc07d 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -140,6 +140,7 @@
("layoutlmv3", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
("layoutxlm", ("LayoutXLMTokenizer", "LayoutXLMTokenizerFast" if is_tokenizers_available() else None)),
("led", ("LEDTokenizer", "LEDTokenizerFast" if is_tokenizers_available() else None)),
+ ("lilt", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
("longformer", ("LongformerTokenizer", "LongformerTokenizerFast" if is_tokenizers_available() else None)),
(
"longt5",
diff --git a/src/transformers/models/lilt/__init__.py b/src/transformers/models/lilt/__init__.py
new file mode 100644
index 00000000000000..f44c87f4b59c6d
--- /dev/null
+++ b/src/transformers/models/lilt/__init__.py
@@ -0,0 +1,64 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_lilt": ["LILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "LiltConfig"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_lilt"] = [
+ "LILT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "LiltForQuestionAnswering",
+ "LiltForSequenceClassification",
+ "LiltForTokenClassification",
+ "LiltModel",
+ "LiltPreTrainedModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_lilt import LILT_PRETRAINED_CONFIG_ARCHIVE_MAP, LiltConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_lilt import (
+ LILT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ LiltForQuestionAnswering,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltModel,
+ LiltPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/lilt/configuration_lilt.py b/src/transformers/models/lilt/configuration_lilt.py
new file mode 100644
index 00000000000000..6306a56330fc12
--- /dev/null
+++ b/src/transformers/models/lilt/configuration_lilt.py
@@ -0,0 +1,138 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" LiLT configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+LILT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "SCUT-DLVCLab/lilt-roberta-en-base": (
+ "https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base/resolve/main/config.json"
+ ),
+}
+
+
+class LiltConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`LiltModel`]. It is used to instantiate a LiLT
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the LiLT
+ [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) architecture.
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 30522):
+ Vocabulary size of the LiLT model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`LiltModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer. Should be a multiple of 24.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 512):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 2):
+ The vocabulary size of the `token_type_ids` passed when calling [`LiltModel`].
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
+ Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
+ positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
+ with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ classifier_dropout (`float`, *optional*):
+ The dropout ratio for the classification head.
+ channel_shrink_ratio (`int`, *optional*, defaults to 4):
+ The shrink ratio compared to the `hidden_size` for the channel dimension of the layout embeddings.
+ max_2d_position_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum value that the 2D position embedding might ever be used with. Typically set this to something
+ large just in case (e.g., 1024).
+
+ Examples:
+
+ ```python
+ >>> from transformers import LiltConfig, LiltModel
+
+ >>> # Initializing a LiLT SCUT-DLVCLab/lilt-roberta-en-base style configuration
+ >>> configuration = LiltConfig()
+ >>> # Randomly initializing a model from the SCUT-DLVCLab/lilt-roberta-en-base style configuration
+ >>> model = LiltModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "lilt"
+
+ def __init__(
+ self,
+ vocab_size=30522,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ pad_token_id=0,
+ position_embedding_type="absolute",
+ use_cache=True,
+ classifier_dropout=None,
+ channel_shrink_ratio=4,
+ max_2d_position_embeddings=1024,
+ **kwargs
+ ):
+ super().__init__(pad_token_id=pad_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.position_embedding_type = position_embedding_type
+ self.use_cache = use_cache
+ self.classifier_dropout = classifier_dropout
+ self.channel_shrink_ratio = channel_shrink_ratio
+ self.max_2d_position_embeddings = max_2d_position_embeddings
diff --git a/src/transformers/models/lilt/modeling_lilt.py b/src/transformers/models/lilt/modeling_lilt.py
new file mode 100644
index 00000000000000..c78490f4b43969
--- /dev/null
+++ b/src/transformers/models/lilt/modeling_lilt.py
@@ -0,0 +1,1211 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch LiLT model."""
+
+import math
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPooling,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from .configuration_lilt import LiltConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "LiltConfig"
+
+LILT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "SCUT-DLVCLab/lilt-roberta-en-base",
+ # See all LiLT models at https://huggingface.co/models?filter=lilt
+]
+
+
+class LiltTextEmbeddings(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+
+ # End copy
+ self.padding_idx = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
+ )
+
+ def forward(
+ self,
+ input_ids=None,
+ token_type_ids=None,
+ position_ids=None,
+ inputs_embeds=None,
+ ):
+ if position_ids is None:
+ if input_ids is not None:
+ # Create the position ids from the input token ids. Any padded tokens remain padded.
+ position_ids = self.create_position_ids_from_input_ids(input_ids, self.padding_idx).to(
+ input_ids.device
+ )
+ else:
+ position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
+
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings, position_ids
+
+ def create_position_ids_from_input_ids(self, input_ids, padding_idx):
+ """
+ Args:
+ Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding
+ symbols are ignored. This is modified from fairseq's `utils.make_positions`.
+ x: torch.Tensor x:
+ Returns: torch.Tensor
+ """
+ # The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
+ mask = input_ids.ne(padding_idx).int()
+ incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask)) * mask
+ return incremental_indices.long() + padding_idx
+
+ def create_position_ids_from_inputs_embeds(self, inputs_embeds):
+ """
+ Args:
+ We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.:
+ inputs_embeds: torch.Tensor
+ Returns: torch.Tensor
+ """
+ input_shape = inputs_embeds.size()[:-1]
+ sequence_length = input_shape[1]
+
+ position_ids = torch.arange(
+ self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
+ )
+ return position_ids.unsqueeze(0).expand(input_shape)
+
+
+class LiltLayoutEmbeddings(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ # we divide the hidden_size by 6 here as there are 6 different layout embeddings,
+ # namely left_position, upper_position, right_position, lower_position, height, width
+ self.x_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.y_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.h_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+ self.w_position_embeddings = nn.Embedding(config.max_2d_position_embeddings, config.hidden_size // 6)
+
+ self.padding_idx = config.pad_token_id
+ self.box_position_embeddings = nn.Embedding(
+ config.max_position_embeddings,
+ config.hidden_size // config.channel_shrink_ratio,
+ padding_idx=self.padding_idx,
+ )
+ self.box_linear_embeddings = nn.Linear(
+ in_features=config.hidden_size, out_features=config.hidden_size // config.channel_shrink_ratio
+ )
+ self.LayerNorm = nn.LayerNorm(config.hidden_size // config.channel_shrink_ratio, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, bbox=None, position_ids=None):
+ try:
+ left_position_embeddings = self.x_position_embeddings(bbox[:, :, 0])
+ upper_position_embeddings = self.y_position_embeddings(bbox[:, :, 1])
+ right_position_embeddings = self.x_position_embeddings(bbox[:, :, 2])
+ lower_position_embeddings = self.y_position_embeddings(bbox[:, :, 3])
+ except IndexError as e:
+ raise IndexError("The `bbox` coordinate values should be within 0-1000 range.") from e
+
+ h_position_embeddings = self.h_position_embeddings(bbox[:, :, 3] - bbox[:, :, 1])
+ w_position_embeddings = self.w_position_embeddings(bbox[:, :, 2] - bbox[:, :, 0])
+
+ spatial_position_embeddings = torch.cat(
+ [
+ left_position_embeddings,
+ upper_position_embeddings,
+ right_position_embeddings,
+ lower_position_embeddings,
+ h_position_embeddings,
+ w_position_embeddings,
+ ],
+ dim=-1,
+ )
+ spatial_position_embeddings = self.box_linear_embeddings(spatial_position_embeddings)
+ box_position_embeddings = self.box_position_embeddings(position_ids)
+
+ spatial_position_embeddings = spatial_position_embeddings + box_position_embeddings
+
+ spatial_position_embeddings = self.LayerNorm(spatial_position_embeddings)
+ spatial_position_embeddings = self.dropout(spatial_position_embeddings)
+
+ return spatial_position_embeddings
+
+
+class LiltSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.layout_query = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+ self.layout_key = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+ self.layout_value = nn.Linear(
+ config.hidden_size // config.channel_shrink_ratio, self.all_head_size // config.channel_shrink_ratio
+ )
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.channel_shrink_ratio = config.channel_shrink_ratio
+
+ def transpose_for_scores(self, x, r=1):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size // r)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states,
+ layout_inputs,
+ attention_mask=None,
+ head_mask=None,
+ output_attentions=False,
+ ):
+
+ layout_value_layer = self.transpose_for_scores(self.layout_value(layout_inputs), r=self.channel_shrink_ratio)
+ layout_key_layer = self.transpose_for_scores(self.layout_key(layout_inputs), r=self.channel_shrink_ratio)
+ layout_query_layer = self.transpose_for_scores(self.layout_query(layout_inputs), r=self.channel_shrink_ratio)
+
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+ layout_attention_scores = torch.matmul(layout_query_layer, layout_key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ tmp_attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ tmp_layout_attention_scores = layout_attention_scores / math.sqrt(
+ self.attention_head_size // self.channel_shrink_ratio
+ )
+ attention_scores = tmp_attention_scores + tmp_layout_attention_scores
+ layout_attention_scores = tmp_layout_attention_scores + tmp_attention_scores
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ layout_attention_scores = layout_attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ layout_attention_probs = nn.Softmax(dim=-1)(layout_attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ layout_attention_probs = self.dropout(layout_attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ layout_attention_probs = layout_attention_probs * head_mask
+
+ layout_context_layer = torch.matmul(layout_attention_probs, layout_value_layer)
+
+ layout_context_layer = layout_context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = layout_context_layer.size()[:-2] + (self.all_head_size // self.channel_shrink_ratio,)
+ layout_context_layer = layout_context_layer.view(*new_context_layer_shape)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in RobertaModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (
+ ((context_layer, layout_context_layer), attention_probs)
+ if output_attentions
+ else ((context_layer, layout_context_layer),)
+ )
+
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
+class LiltSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class LiltAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = LiltSelfAttention(config, position_embedding_type=position_embedding_type)
+ self.output = LiltSelfOutput(config)
+ self.pruned_heads = set()
+
+ ori_hidden_size = config.hidden_size
+ config.hidden_size = config.hidden_size // config.channel_shrink_ratio
+ self.layout_output = LiltSelfOutput(config)
+ config.hidden_size = ori_hidden_size
+
+ # Copied from transformers.models.bert.modeling_bert.BertAttention.prune_heads
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ head_mask,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0][0], hidden_states)
+ layout_attention_output = self.layout_output(self_outputs[0][1], layout_inputs)
+ outputs = ((attention_output, layout_attention_output),) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertIntermediate
+class LiltIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertOutput
+class LiltOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class LiltLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = LiltAttention(config)
+ self.intermediate = LiltIntermediate(config)
+ self.output = LiltOutput(config)
+
+ ori_hidden_size = config.hidden_size
+ ori_intermediate_size = config.intermediate_size
+ config.hidden_size = config.hidden_size // config.channel_shrink_ratio
+ config.intermediate_size = config.intermediate_size // config.channel_shrink_ratio
+ self.layout_intermediate = LiltIntermediate(config)
+ self.layout_output = LiltOutput(config)
+ config.hidden_size = ori_hidden_size
+ config.intermediate_size = ori_intermediate_size
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_attention_outputs = self.attention(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0][0]
+ layout_attention_output = self_attention_outputs[0][1]
+
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ layout_layer_output = apply_chunking_to_forward(
+ self.layout_feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, layout_attention_output
+ )
+ outputs = ((layer_output, layout_layer_output),) + outputs
+
+ return outputs
+
+ # Copied from transformers.models.bert.modeling_bert.BertLayer.feed_forward_chunk
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+ def layout_feed_forward_chunk(self, attention_output):
+ intermediate_output = self.layout_intermediate(attention_output)
+ layer_output = self.layout_output(intermediate_output, attention_output)
+ return layer_output
+
+
+class LiltEncoder(nn.Module):
+ # Copied from transformers.models.bert.modeling_bert.BertEncoder.__init__ with Bert->Lilt
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([LiltLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ layout_inputs: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ layout_inputs,
+ attention_mask,
+ layer_head_mask,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0][0]
+ layout_inputs = layer_outputs[0][1]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ all_hidden_states,
+ all_self_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+# Copied from transformers.models.bert.modeling_bert.BertPooler
+class LiltPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaPreTrainedModel with Roberta->Lilt,roberta->lilt
+class LiltPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = LiltConfig
+ base_model_prefix = "lilt"
+ supports_gradient_checkpointing = True
+
+ # Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, LiltEncoder):
+ module.gradient_checkpointing = value
+
+ def update_keys_to_ignore(self, config, del_keys_to_ignore):
+ """Remove some keys from ignore list"""
+ if not config.tie_word_embeddings:
+ # must make a new list, or the class variable gets modified!
+ self._keys_to_ignore_on_save = [k for k in self._keys_to_ignore_on_save if k not in del_keys_to_ignore]
+ self._keys_to_ignore_on_load_missing = [
+ k for k in self._keys_to_ignore_on_load_missing if k not in del_keys_to_ignore
+ ]
+
+
+LILT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`LiltConfig`]): Model configuration class with all the parameters of the
+ model. Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+LILT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`RobertaTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner. See [Overview](#Overview) for normalization.
+
+ attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare LiLT Model transformer outputting raw hidden-states without any specific head on top.",
+ LILT_START_DOCSTRING,
+)
+class LiltModel(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = LiltTextEmbeddings(config)
+ self.layout_embeddings = LiltLayoutEmbeddings(config)
+ self.encoder = LiltEncoder(config)
+
+ self.pooler = LiltPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ bbox: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPooling]:
+ r"""
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModel
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if bbox is None:
+ bbox = torch.zeros(input_shape + (4,), dtype=torch.long, device=device)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length)), device=device)
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output, position_ids = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ )
+
+ layout_embedding_output = self.layout_embeddings(bbox=bbox, position_ids=position_ids)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ layout_embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ LiLT Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
+ output) e.g. for GLUE tasks.
+ """,
+ LILT_START_DOCSTRING,
+)
+class LiltForSequenceClassification(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaForSequenceClassification.__init__ with Roberta->Lilt, roberta->lilt
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.config = config
+
+ self.lilt = LiltModel(config, add_pooling_layer=False)
+ self.classifier = LiltClassificationHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ bbox: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModelForSequenceClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> predicted_class_idx = outputs.logits.argmax(-1).item()
+ >>> predicted_class = model.config.id2label[predicted_class_idx]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.lilt(
+ input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = outputs[0]
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Lilt Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
+ Named-Entity-Recognition (NER) tasks.
+ """,
+ LILT_START_DOCSTRING,
+)
+class LiltForTokenClassification(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaForTokenClassification.__init__ with Roberta->Lilt, roberta->lilt
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.lilt = LiltModel(config, add_pooling_layer=False)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ bbox: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForTokenClassification
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModelForTokenClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> predicted_class_indices = outputs.logits.argmax(-1)
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.lilt(
+ input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ sequence_output = self.dropout(sequence_output)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaClassificationHead with Roberta->Lilt
+class LiltClassificationHead(nn.Module):
+ """Head for sentence-level classification tasks."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ classifier_dropout = (
+ config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout)
+ self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
+
+ def forward(self, features, **kwargs):
+ x = features[:, 0, :] # take token (equiv. to [CLS])
+ x = self.dropout(x)
+ x = self.dense(x)
+ x = torch.tanh(x)
+ x = self.dropout(x)
+ x = self.out_proj(x)
+ return x
+
+
+@add_start_docstrings(
+ """
+ Lilt Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
+ layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
+ """,
+ LILT_START_DOCSTRING,
+)
+class LiltForQuestionAnswering(LiltPreTrainedModel):
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ # Copied from transformers.models.roberta.modeling_roberta.RobertaForQuestionAnswering.__init__ with Roberta->Lilt, roberta->lilt
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.lilt = LiltModel(config, add_pooling_layer=False)
+ self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(LILT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=QuestionAnsweringModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ bbox: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], QuestionAnsweringModelOutput]:
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
+ >>> from datasets import load_dataset
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+ >>> model = AutoModelForQuestionAnswering.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+
+ >>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+
+ >>> answer_start_index = outputs.start_logits.argmax()
+ >>> answer_end_index = outputs.end_logits.argmax()
+
+ >>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
+ >>> predicted_answer = tokenizer.decode(predict_answer_tokens)
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.lilt(
+ input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ logits = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 28056b66f541db..7e7917a783ce48 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -2825,6 +2825,44 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+LILT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class LiltForQuestionAnswering(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LiltForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LiltForTokenClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LiltModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class LiltPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/tests/models/lilt/__init__.py b/tests/models/lilt/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/lilt/test_modeling_lilt.py b/tests/models/lilt/test_modeling_lilt.py
new file mode 100644
index 00000000000000..718d2bd287fb8d
--- /dev/null
+++ b/tests/models/lilt/test_modeling_lilt.py
@@ -0,0 +1,288 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import LiltConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...generation.test_generation_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ LiltForQuestionAnswering,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltModel,
+ )
+ from transformers.models.lilt.modeling_lilt import LILT_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+class LiltModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=24,
+ num_hidden_layers=2,
+ num_attention_heads=6,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ range_bbox=1000,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+ self.range_bbox = range_bbox
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ bbox = ids_tensor([self.batch_size, self.seq_length, 4], self.range_bbox)
+ # Ensure that bbox is legal
+ for i in range(bbox.shape[0]):
+ for j in range(bbox.shape[1]):
+ if bbox[i, j, 3] < bbox[i, j, 1]:
+ t = bbox[i, j, 3]
+ bbox[i, j, 3] = bbox[i, j, 1]
+ bbox[i, j, 1] = t
+ if bbox[i, j, 2] < bbox[i, j, 0]:
+ t = bbox[i, j, 2]
+ bbox[i, j, 2] = bbox[i, j, 0]
+ bbox[i, j, 0] = t
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels
+
+ def get_config(self):
+ return LiltConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ model = LiltModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, bbox=bbox, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox=bbox, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox=bbox)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_for_token_classification(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = LiltForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids, bbox=bbox, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_question_answering(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ):
+ model = LiltForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "bbox": bbox,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class LiltModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+
+ all_model_classes = (
+ (
+ LiltModel,
+ LiltForSequenceClassification,
+ LiltForTokenClassification,
+ LiltForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+ fx_compatible = False
+ test_pruning = False
+
+ def setUp(self):
+ self.model_tester = LiltModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=LiltConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in LILT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = LiltModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+@require_torch
+@slow
+class LiltModelIntegrationTest(unittest.TestCase):
+ def test_inference_no_head(self):
+ model = LiltModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base").to(torch_device)
+
+ input_ids = torch.tensor([[1, 2]], device=torch_device)
+ bbox = torch.tensor([[[1, 2, 3, 4], [5, 6, 7, 8]]], device=torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(input_ids=input_ids, bbox=bbox)
+
+ expected_shape = torch.Size([1, 2, 768])
+ expected_slice = torch.tensor(
+ [[-0.0653, 0.0950, -0.0061], [-0.0545, 0.0926, -0.0324]],
+ device=torch_device,
+ )
+
+ self.assertTrue(outputs.last_hidden_state.shape, expected_shape)
+ self.assertTrue(torch.allclose(outputs.last_hidden_state[0, :, :3], expected_slice, atol=1e-3))
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 769b7ca0982ca3..6c571f5aa2c5f0 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -49,6 +49,7 @@ src/transformers/models/layoutlm/modeling_tf_layoutlm.py
src/transformers/models/layoutlmv2/modeling_layoutlmv2.py
src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
+src/transformers/models/lilt/modeling_lilt.py
src/transformers/models/longformer/modeling_longformer.py
src/transformers/models/longformer/modeling_tf_longformer.py
src/transformers/models/longt5/modeling_longt5.py