GZip Header / Footer info #558
Comments
|
The header stuff that Go references is actually there: It just needs exposing or some other minor updates as it looks like the whole header is gathered. This implementation was based on another and I haven't really touched it since. |
|
Is that why my GZipEntry records don't match PeaZip? Since I am not super familiar with GZip standard and am learning as I go, I don't quite fully understand why these don't match.
|
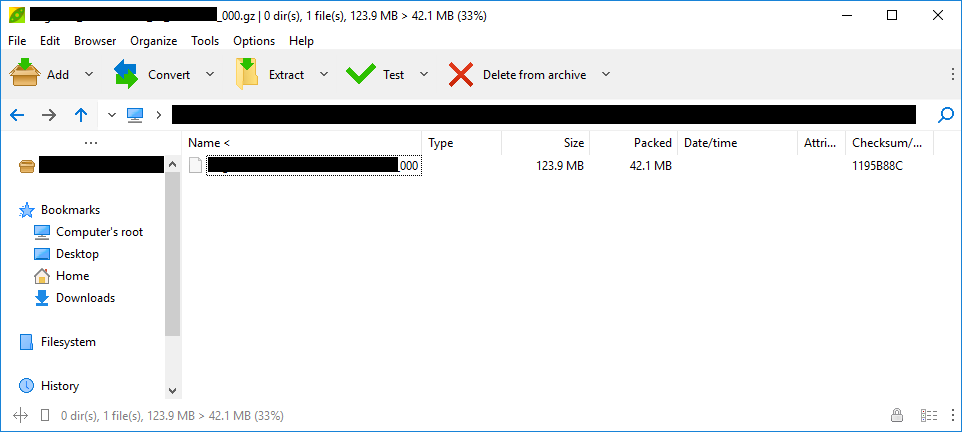
|
For what its worth, this .gz file is from a RedShift table export. https://docs.aws.amazon.com/redshift/latest/dg/t_Unloading_tables.html So, I think this would be a fairly common task to want to use GZip decompression for, as more and more people use data lakes. |
|
There might be a bug in that the GZipEntry isn't picking up the file name correctly. It's also possible that there is no file name embedded and PeaZip just gives it a default. I'm guessing I have a bug but would need a sample (and time) to validate. Any chance you get the source of sharpcompress to debug? I'd put a breakpoint on the gzip header read spot to see what comes out. If that's correct then I need to fix. Else there's just no info. |
|
I think its not a bug. I did the following to try to analyze further:
In reading online, the 4th bit of the 4th byte determines if the original filename is kept. When it is not present, the "correct" behavior used by various tools is to use the gz filename without the gz extension. Unfortunately,
This is a good idea. Will fork and see. |
|
I was able to figure it out with gzip outputs: Which, upon reading online, I'll still fork the repo and look at contributing a patch sometime soon. Seems like fun. I also think the API could use some changes to make it more friendly to generic programming and async/await all the way. |
|
Showing the filename when that byte is present isn't what this library does. The API doesn't know the name. It knows streams. That said, all the info should be exposed on GZipStream and/or GZipEntry. Exposing the info should be easy. I'm happy to rework the API. I haven't given it critical thought for 10 years! Any thoughts on issues or PRs are welcome. Async/await has been on the TODO list but I've just never made a start as it seems like a lot of grunt work. Again, PRs welcome! Even partial ones where I could help with this big task. I'm with a startup and have 3 young kids in lockdown. Not much free time. |
|
I got some time and got curious so I dug into the code and spec and then reread your use case. It looks like all you want is the name and uncompressed size. The name could be "default" which GZipStream doesn't know the file name. As for the size, it's basically the last 4 bytes on the file, assuming there's only one "member" in the file as most GZ files are. I don't think there's any value this library can add to that use case other than a static method on GZipArchive or something. I guess I could make the entries on the archive read the footers to load size and crc data. I started a branch here that just exposes LastModified but I don't see anything obvious to do: #560 |
|
Nevermind, I take that back: If you use GZipArchive it will read the trailer for CRC and size info now. really need to refactor this lib for nullables and async. |
|
Do you use Resharper? Feel like I can blaze through refactoring it. The thing I don't understand is, reading online, is there really such a thing as a GZipArchive? Isn't that just tar.gz? I didn't know what GZipFilePart was either. I think the ReaderFactory would be nicer if it supported generic types. That would clean up ReaderOptions too since you could have options per format. |
|
It's really that in sharpcompress: Ive kulged a common API over different formats as I could for fun. FilePart was a way to have the same file in an archive across multiple physical files. For example, Rar and Zip can divide an archive into multi-file archives. You might have a compressed file split over 2 or more physical archive files because of it. FilePart made sense at the time. I use Rider so basically I use Resharper :) I'll merge in my gzip changes soon and release then prepare for breaking changes. I want more nullables anyway. |
Hi @adamhathcock ,
Small world.
I have about 75GB of gzip data I need to decompress and then load into SQL tables. Since the data vendor could in theory update any historical data at any time, I wanted to ideally
But, to do this, ideally I would only read the GZip header and footer, so I know how big of a file I am extracting, but I don't see any clean .NET APIs that let you do something like the following pseudo-code:
But... this is likely slightly incorrect. Even so, I see that is approximately how Go models it: https://golang.org/src/compress/gzip/gunzip.go?s=1297:1500#L42
I'm a little surprised there doesn't seem to be a .NET library with an API with such an obvious use case, but Go does.
StackOverflow seems to suggest that an older version of this library supported a concrete FilePath value. https://stackoverflow.com/a/39081983/1040437
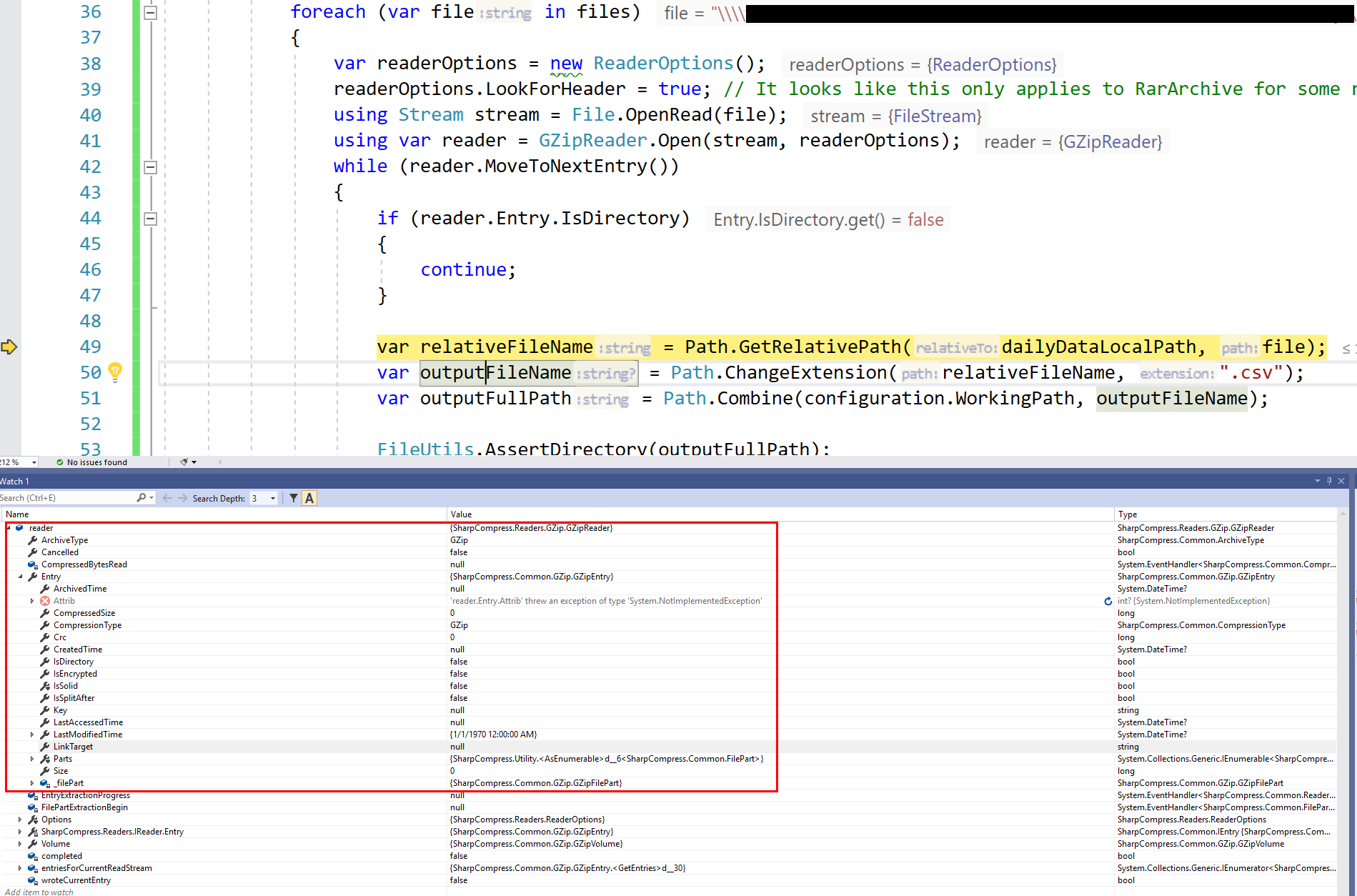
This is the code I wrote so far, but
reader.Entry.Keyis blank andreader.Entry.LinkTargetis also blank, and I don't see a FilePath option anywhere.The text was updated successfully, but these errors were encountered: