diff --git a/README.md b/README.md
index 908d2e690faade..7ca06f42b5a657 100644
--- a/README.md
+++ b/README.md
@@ -290,6 +290,7 @@ Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/master/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](https://huggingface.co/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
diff --git a/README_ko.md b/README_ko.md
index d6bc4ae44a4afb..e9a09f6d55d265 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -269,6 +269,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/master/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](https://huggingface.co/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index c5878ca2004f5e..49f96b6c641294 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -293,6 +293,7 @@ conda install -c huggingface transformers
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (来自 Deepmind) 伴随论文 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 由 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 发布。
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (来自 VinAI Research) 伴随论文 [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) 由 Dat Quoc Nguyen and Anh Tuan Nguyen 发布。
+1. **[PoolFormer](https://huggingface.co/docs/transformers/master/model_doc/poolformer)** (来自 Sea AI Labs) 伴随论文 [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) 由 Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng 发布。
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
1. **[REALM](https://huggingface.co/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index bd9cb706aa054b..bb7786cb4d765e 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -305,6 +305,7 @@ conda install -c huggingface transformers
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/master/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](https://huggingface.co/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index 70d2455d0aeaaa..0d23eff7ddd39a 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -246,6 +246,8 @@
title: Pegasus
- local: model_doc/phobert
title: PhoBERT
+ - local: model_doc/poolformer
+ title: PoolFormer
- local: model_doc/prophetnet
title: ProphetNet
- local: model_doc/qdqbert
diff --git a/docs/source/index.mdx b/docs/source/index.mdx
index 9ee4377110cd8c..3e69dcb1c40a16 100644
--- a/docs/source/index.mdx
+++ b/docs/source/index.mdx
@@ -114,6 +114,7 @@ conversion utilities for the following models.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](https://huggingface.co/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
@@ -214,6 +215,7 @@ Flax), PyTorch, and/or TensorFlow.
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
diff --git a/docs/source/model_doc/poolformer.mdx b/docs/source/model_doc/poolformer.mdx
new file mode 100644
index 00000000000000..a3f9a3b7ba11a5
--- /dev/null
+++ b/docs/source/model_doc/poolformer.mdx
@@ -0,0 +1,61 @@
+
+
+# PoolFormer
+
+## Overview
+
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+
+The abstract from the paper is the following:
+
+*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
+
+The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+
+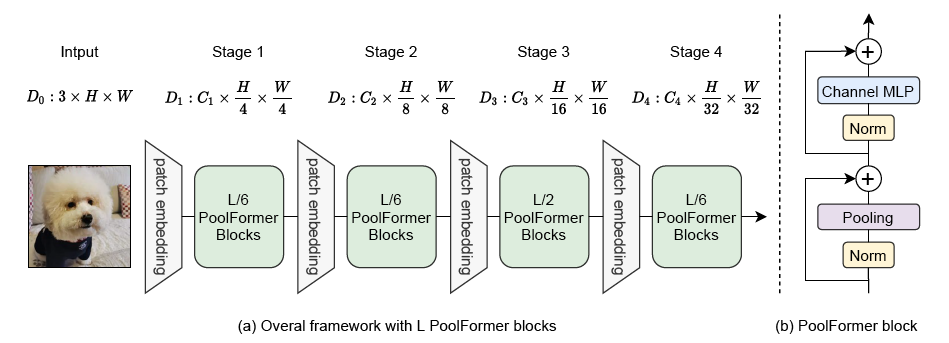 +
+
+Tips:
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## PoolFormerConfig
+
+[[autodoc]] PoolFormerConfig
+
+## PoolFormerFeatureExtractor
+
+[[autodoc]] PoolFormerFeatureExtractor
+ - __call__
+
+## PoolFormerModel
+
+[[autodoc]] PoolFormerModel
+ - forward
+
+## PoolFormerForImageClassification
+
+[[autodoc]] PoolFormerForImageClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index ad05486104ee79..8efc520dc01369 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -263,6 +263,7 @@
"models.pegasus": ["PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP", "PegasusConfig", "PegasusTokenizer"],
"models.perceiver": ["PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PerceiverConfig", "PerceiverTokenizer"],
"models.phobert": ["PhobertTokenizer"],
+ "models.poolformer": ["POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PoolFormerConfig"],
"models.prophetnet": ["PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP", "ProphetNetConfig", "ProphetNetTokenizer"],
"models.qdqbert": ["QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "QDQBertConfig"],
"models.rag": ["RagConfig", "RagRetriever", "RagTokenizer"],
@@ -523,6 +524,7 @@
_import_structure["models.layoutlmv2"].append("LayoutLMv2Processor")
_import_structure["models.layoutxlm"].append("LayoutXLMProcessor")
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
+ _import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
_import_structure["models.segformer"].append("SegformerFeatureExtractor")
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
@@ -1214,6 +1216,14 @@
"PerceiverPreTrainedModel",
]
)
+ _import_structure["models.poolformer"].extend(
+ [
+ "POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "PoolFormerForImageClassification",
+ "PoolFormerModel",
+ "PoolFormerPreTrainedModel",
+ ]
+ )
_import_structure["models.prophetnet"].extend(
[
"PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2483,6 +2493,7 @@
from .models.pegasus import PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP, PegasusConfig, PegasusTokenizer
from .models.perceiver import PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP, PerceiverConfig, PerceiverTokenizer
from .models.phobert import PhobertTokenizer
+ from .models.poolformer import POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, PoolFormerConfig
from .models.prophetnet import PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP, ProphetNetConfig, ProphetNetTokenizer
from .models.qdqbert import QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, QDQBertConfig
from .models.rag import RagConfig, RagRetriever, RagTokenizer
@@ -2700,6 +2711,7 @@
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2Processor
from .models.layoutxlm import LayoutXLMProcessor
from .models.perceiver import PerceiverFeatureExtractor
+ from .models.poolformer import PoolFormerFeatureExtractor
from .models.segformer import SegformerFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
@@ -3272,6 +3284,12 @@
PerceiverModel,
PerceiverPreTrainedModel,
)
+ from .models.poolformer import (
+ POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ PoolFormerForImageClassification,
+ PoolFormerModel,
+ PoolFormerPreTrainedModel,
+ )
from .models.prophetnet import (
PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST,
ProphetNetDecoder,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index d6cf69197ea961..50d287c61efcde 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -83,6 +83,7 @@
pegasus,
perceiver,
phobert,
+ poolformer,
prophetnet,
qdqbert,
rag,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 9223123d3432d4..1115ffb7a3663d 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("poolformer", "PoolFormerConfig"),
("convnext", "ConvNextConfig"),
("yoso", "YosoConfig"),
("swin", "SwinConfig"),
@@ -125,6 +126,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here
+ ("poolformer", "POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -207,6 +209,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("poolformer", "PoolFormer"),
("convnext", "ConvNext"),
("yoso", "YOSO"),
("swin", "Swin"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 50e7ff1b823be5..ed0e58e0081a14 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -53,6 +53,7 @@
("vit_mae", "ViTFeatureExtractor"),
("segformer", "SegformerFeatureExtractor"),
("convnext", "ConvNextFeatureExtractor"),
+ ("poolformer", "PoolFormerFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index fe472cc654eac5..5e8c8149dd44f5 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("poolformer", "PoolFormerModel"),
("convnext", "ConvNextModel"),
("yoso", "YosoModel"),
("swin", "SwinModel"),
@@ -275,6 +276,7 @@
),
("swin", "SwinForImageClassification"),
("convnext", "ConvNextForImageClassification"),
+ ("poolformer", "PoolFormerForImageClassification"),
]
)
diff --git a/src/transformers/models/poolformer/__init__.py b/src/transformers/models/poolformer/__init__.py
new file mode 100644
index 00000000000000..246dc7645596f4
--- /dev/null
+++ b/src/transformers/models/poolformer/__init__.py
@@ -0,0 +1,58 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_poolformer": ["POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PoolFormerConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_poolformer"] = ["PoolFormerFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_poolformer"] = [
+ "POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "PoolFormerForImageClassification",
+ "PoolFormerModel",
+ "PoolFormerPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_poolformer import POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, PoolFormerConfig
+
+ if is_vision_available():
+ from .feature_extraction_poolformer import PoolFormerFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_poolformer import (
+ POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ PoolFormerForImageClassification,
+ PoolFormerModel,
+ PoolFormerPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure)
diff --git a/src/transformers/models/poolformer/configuration_poolformer.py b/src/transformers/models/poolformer/configuration_poolformer.py
new file mode 100644
index 00000000000000..d5cb07bd584fe7
--- /dev/null
+++ b/src/transformers/models/poolformer/configuration_poolformer.py
@@ -0,0 +1,127 @@
+# coding=utf-8
+# Copyright 2022 Sea AI Labs and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PoolFormer model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "sail/poolformer_s12": "https://huggingface.co/sail/poolformer_s12/resolve/main/config.json",
+ # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
+}
+
+
+class PoolFormerConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of [`PoolFormerModel`]. It is used to instantiate a
+ PoolFormer model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the PoolFormer
+ [sail/poolformer_s12](https://huggingface.co/sail/poolformer_s12) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of channels in the input image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size of the input patch.
+ stride (`int`, *optional*, defaults to 16):
+ The stride of the input patch.
+ pool_size (`int`, *optional*, defaults to 3):
+ The size of the pooling window.
+ mlp_ratio (`float`, *optional*, defaults to 4.0):
+ The ratio of the number of channels in the output of the MLP to the number of channels in the input.
+ depths (`list`, *optional*, defaults to `[2, 2, 6, 2]`):
+ The depth of each encoder block.
+ hidden_sizes (`list`, *optional*, defaults to `[64, 128, 320, 512]`):
+ The hidden sizes of each encoder block.
+ patch_sizes (`list`, *optional*, defaults to `[7, 3, 3, 3]`):
+ The size of the input patch for each encoder block.
+ strides (`list`, *optional*, defaults to `[4, 2, 2, 2]`):
+ The stride of the input patch for each encoder block.
+ padding (`list`, *optional*, defaults to `[2, 1, 1, 1]`):
+ The padding of the input patch for each encoder block.
+ num_encoder_blocks (`int`, *optional*, defaults to 4):
+ The number of encoder blocks.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ The dropout rate for the dropout layers.
+ hidden_act (`str`, *optional*, defaults to `"gelu"`):
+ The activation function for the hidden layers.
+ use_layer_scale (`bool`, *optional*, defaults to `True`):
+ Whether to use layer scale.
+ layer_scale_init_value (`float`, *optional*, defaults to 1e-5):
+ The initial value for the layer scale.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The initializer range for the weights.
+
+ Example:
+
+ ```python
+ >>> from transformers import PoolFormerModel, PoolFormerConfig
+
+ >>> # Initializing a PoolFormer sail/poolformer_s12 style configuration
+ >>> configuration = PoolFormerConfig()
+
+ >>> # Initializing a model from the sail/poolformer_s12 style configuration
+ >>> model = PoolFormerModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```
+ """
+ model_type = "poolformer"
+
+ def __init__(
+ self,
+ num_channels=3,
+ patch_size=16,
+ stride=16,
+ pool_size=3,
+ mlp_ratio=4.0,
+ depths=[2, 2, 6, 2],
+ hidden_sizes=[64, 128, 320, 512],
+ patch_sizes=[7, 3, 3, 3],
+ strides=[4, 2, 2, 2],
+ padding=[2, 1, 1, 1],
+ num_encoder_blocks=4,
+ drop_path_rate=0.0,
+ hidden_act="gelu",
+ use_layer_scale=True,
+ layer_scale_init_value=1e-5,
+ initializer_range=0.02,
+ **kwargs
+ ):
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.stride = stride
+ self.padding = padding
+ self.pool_size = pool_size
+ self.hidden_sizes = hidden_sizes
+ self.mlp_ratio = mlp_ratio
+ self.depths = depths
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.num_encoder_blocks = num_encoder_blocks
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_layer_scale = use_layer_scale
+ self.layer_scale_init_value = layer_scale_init_value
+ self.initializer_range = initializer_range
+ super().__init__(**kwargs)
diff --git a/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py b/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
new file mode 100644
index 00000000000000..eebc8b0c5e713d
--- /dev/null
+++ b/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
@@ -0,0 +1,214 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert PoolFormer checkpoints from the original repository. URL: https://github.com/sail-sg/poolformer"""
+
+import argparse
+import json
+from collections import OrderedDict
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import cached_download, hf_hub_url
+from transformers import PoolFormerConfig, PoolFormerFeatureExtractor, PoolFormerForImageClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def replace_key_with_offset(key, offset, original_name, new_name):
+ """
+ Replaces the key by subtracting the offset from the original layer number
+ """
+ to_find = original_name.split(".")[0]
+ key_list = key.split(".")
+ orig_block_num = int(key_list[key_list.index(to_find) - 2])
+ layer_num = int(key_list[key_list.index(to_find) - 1])
+ new_block_num = orig_block_num - offset
+
+ key = key.replace(f"{orig_block_num}.{layer_num}.{original_name}", f"block.{new_block_num}.{layer_num}.{new_name}")
+ return key
+
+
+def rename_keys(state_dict):
+ new_state_dict = OrderedDict()
+ total_embed_found, patch_emb_offset = 0, 0
+ for key, value in state_dict.items():
+ if key.startswith("network"):
+ key = key.replace("network", "poolformer.encoder")
+ if "proj" in key:
+ # Works for the first embedding as well as the internal embedding layers
+ if key.endswith("bias") and "patch_embed" not in key:
+ patch_emb_offset += 1
+ to_replace = key[: key.find("proj")]
+ key = key.replace(to_replace, f"patch_embeddings.{total_embed_found}.")
+ key = key.replace("proj", "projection")
+ if key.endswith("bias"):
+ total_embed_found += 1
+ if "patch_embeddings" in key:
+ key = "poolformer.encoder." + key
+ if "mlp.fc1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "mlp.fc1", "output.conv1")
+ if "mlp.fc2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "mlp.fc2", "output.conv2")
+ if "norm1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "norm1", "before_norm")
+ if "norm2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "norm2", "after_norm")
+ if "layer_scale_1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "layer_scale_1", "layer_scale_1")
+ if "layer_scale_2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "layer_scale_2", "layer_scale_2")
+ if "head" in key:
+ key = key.replace("head", "classifier")
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+# We will verify our results on a COCO image
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+
+ return image
+
+
+@torch.no_grad()
+def convert_poolformer_checkpoint(model_name, checkpoint_path, pytorch_dump_folder_path):
+ """
+ Copy/paste/tweak model's weights to our PoolFormer structure.
+ """
+
+ # load default PoolFormer configuration
+ config = PoolFormerConfig()
+
+ # set attributes based on model_name
+ repo_id = "datasets/huggingface/label-files"
+ size = model_name[-3:]
+ config.num_labels = 1000
+ filename = "imagenet-1k-id2label.json"
+ expected_shape = (1, 1000)
+
+ # set config attributes
+ id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename)), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+ if size == "s12":
+ config.depths = [2, 2, 6, 2]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ crop_pct = 0.9
+ elif size == "s24":
+ config.depths = [4, 4, 12, 4]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ crop_pct = 0.9
+ elif size == "s36":
+ config.depths = [6, 6, 18, 6]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.9
+ elif size == "m36":
+ config.depths = [6, 6, 18, 6]
+ config.hidden_sizes = [96, 192, 384, 768]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.95
+ elif size == "m48":
+ config.depths = [8, 8, 24, 8]
+ config.hidden_sizes = [96, 192, 384, 768]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.95
+ else:
+ raise ValueError(f"Size {size} not supported")
+
+ # load feature extractor
+ feature_extractor = PoolFormerFeatureExtractor(crop_pct=crop_pct)
+
+ # Prepare image
+ image = prepare_img()
+ pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ logger.info(f"Converting model {model_name}...")
+
+ # load original state dict
+ state_dict = torch.load(checkpoint_path, map_location=torch.device("cpu"))
+
+ # rename keys
+ state_dict = rename_keys(state_dict)
+
+ # create HuggingFace model and load state dict
+ model = PoolFormerForImageClassification(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # Define feature extractor
+ feature_extractor = PoolFormerFeatureExtractor(crop_pct=crop_pct)
+ pixel_values = feature_extractor(images=prepare_img(), return_tensors="pt").pixel_values
+
+ # forward pass
+ outputs = model(pixel_values)
+ logits = outputs.logits
+
+ # define expected logit slices for different models
+ if size == "s12":
+ expected_slice = torch.tensor([-0.3045, -0.6758, -0.4869])
+ elif size == "s24":
+ expected_slice = torch.tensor([0.4402, -0.1374, -0.8045])
+ elif size == "s36":
+ expected_slice = torch.tensor([-0.6080, -0.5133, -0.5898])
+ elif size == "m36":
+ expected_slice = torch.tensor([0.3952, 0.2263, -1.2668])
+ elif size == "m48":
+ expected_slice = torch.tensor([0.1167, -0.0656, -0.3423])
+ else:
+ raise ValueError(f"Size {size} not supported")
+
+ # verify logits
+ assert logits.shape == expected_shape
+ assert torch.allclose(logits[0, :3], expected_slice, atol=1e-2)
+
+ # finally, save model and feature extractor
+ logger.info(f"Saving PyTorch model and feature extractor to {pytorch_dump_folder_path}...")
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--model_name",
+ default="poolformer_s12",
+ type=str,
+ help="Name of the model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, help="Path to the original PyTorch checkpoint (.pth file)."
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the folder to output PyTorch model."
+ )
+ args = parser.parse_args()
+ convert_poolformer_checkpoint(args.model_name, args.checkpoint_path, args.pytorch_dump_folder_path)
diff --git a/src/transformers/models/poolformer/feature_extraction_poolformer.py b/src/transformers/models/poolformer/feature_extraction_poolformer.py
new file mode 100644
index 00000000000000..b7d44e22265193
--- /dev/null
+++ b/src/transformers/models/poolformer/feature_extraction_poolformer.py
@@ -0,0 +1,172 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for PoolFormer."""
+
+import math
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...file_utils import TensorType
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class PoolFormerFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a PoolFormer feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize_and_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shortest edge of the image and center crop the input to a certain `size`.
+ size (`int` or `Tuple(int)`, *optional*, defaults to 224):
+ Center crop the input to the given size. If a tuple is provided, it should be (width, height). If only an
+ integer is provided, then the input will be center cropped to (size, size). Only has an effect if
+ `do_resize_and_center_crop` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize_and_center_crop` is set to `True`.
+ crop_pct (`float`, *optional*, defaults to `0.9`):
+ The percentage of the image to crop from the center. Only has an effect if `do_resize_and_center_crop` is
+ set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with `image_mean` and `image_std`.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize_and_center_crop=True,
+ size=224,
+ resample=Image.BICUBIC,
+ crop_pct=0.9,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize_and_center_crop = do_resize_and_center_crop
+ self.size = size
+ self.resample = resample
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize_and_center_crop and self.size is not None and self.crop_pct is not None:
+ if isinstance(self.size, (tuple, list)):
+ assert len(self.size) == 2
+ if self.size[-1] == self.size[-2]:
+ scale_size = int(math.floor(self.size[0] / self.crop_pct))
+ else:
+ scale_size = tuple([int(x / self.crop_pct) for x in self.size])
+ else:
+ scale_size = int(math.floor(self.size / self.crop_pct))
+
+ # resize shortest edge of the image
+ images = [
+ self.resize(image=image, size=scale_size, resample=self.resample, default_to_square=False)
+ for image in images
+ ]
+ # center crop
+ images = [self.center_crop(image, size=self.size) for image in images]
+
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/poolformer/modeling_poolformer.py b/src/transformers/models/poolformer/modeling_poolformer.py
new file mode 100755
index 00000000000000..17205e31124728
--- /dev/null
+++ b/src/transformers/models/poolformer/modeling_poolformer.py
@@ -0,0 +1,499 @@
+# coding=utf-8
+# Copyright 2022 Sea AI Lab and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch PoolFormer model."""
+
+
+import collections.abc
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import logging
+from .configuration_poolformer import PoolFormerConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "PoolFormerConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "sail/poolformer_s12"
+_EXPECTED_OUTPUT_SHAPE = [1, 197, 768]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "sail/poolformer_s12"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "'tabby, tabby cat'"
+
+POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "sail/poolformer_s12",
+ # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
+]
+
+
+# Copied from transformers.models.vit.modeling_vit.to_2tuple
+def to_2tuple(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return (x, x)
+
+
+@dataclass
+class PoolFormerModelOutput(ModelOutput):
+ """
+ Class for PoolFormerModel's outputs, with potential hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class PoolFormerClassifierOutput(ModelOutput):
+ """
+ Class for PoolformerForImageClassification's outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+def drop_path(x, drop_prob: float = 0.0, training: bool = False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is
+ misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion:
+ https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and
+ argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class PoolFormerDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob=None):
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class PoolFormerEmbeddings(nn.Module):
+ """
+ Construct Patch Embeddings.
+ """
+
+ def __init__(self, hidden_size, num_channels, patch_size, stride, padding, norm_layer=None):
+ super().__init__()
+ patch_size = to_2tuple(patch_size)
+ stride = to_2tuple(stride)
+ padding = to_2tuple(padding)
+
+ self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=stride, padding=padding)
+ self.norm = norm_layer(hidden_size) if norm_layer else nn.Identity()
+
+ def forward(self, pixel_values):
+ x = self.projection(pixel_values)
+ x = self.norm(x)
+ return x
+
+
+class PoolFormerGroupNorm(nn.GroupNorm):
+ """
+ Group Normalization with 1 group. Input: tensor in shape [B, C, H, W]
+ """
+
+ def __init__(self, num_channels, **kwargs):
+ super().__init__(1, num_channels, **kwargs)
+
+
+class PoolFormerPooling(nn.Module):
+ def __init__(self, pool_size):
+ super().__init__()
+ self.pool = nn.AvgPool2d(pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
+
+ def forward(self, hidden_states):
+ return self.pool(hidden_states) - hidden_states
+
+
+class PoolFormerOutput(nn.Module):
+ def __init__(self, config, dropout_prob, hidden_size, intermediate_size):
+ super().__init__()
+ self.conv1 = nn.Conv2d(hidden_size, intermediate_size, 1)
+ self.conv2 = nn.Conv2d(intermediate_size, hidden_size, 1)
+ self.drop = PoolFormerDropPath(dropout_prob)
+ if isinstance(config.hidden_act, str):
+ self.act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.act_fn(hidden_states)
+ hidden_states = self.drop(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = self.drop(hidden_states)
+
+ return hidden_states
+
+
+class PoolFormerLayer(nn.Module):
+ """This corresponds to the 'PoolFormerBlock' class in the original implementation."""
+
+ def __init__(self, config, num_channels, pool_size, hidden_size, intermediate_size, drop_path):
+ super().__init__()
+ self.pooling = PoolFormerPooling(pool_size)
+ self.output = PoolFormerOutput(config, drop_path, hidden_size, intermediate_size)
+ self.before_norm = PoolFormerGroupNorm(num_channels)
+ self.after_norm = PoolFormerGroupNorm(num_channels)
+
+ # Useful for training neural nets
+ self.drop_path = PoolFormerDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+ self.use_layer_scale = config.use_layer_scale
+ if config.use_layer_scale:
+ self.layer_scale_1 = nn.Parameter(
+ config.layer_scale_init_value * torch.ones((num_channels)), requires_grad=True
+ )
+ self.layer_scale_2 = nn.Parameter(
+ config.layer_scale_init_value * torch.ones((num_channels)), requires_grad=True
+ )
+
+ def forward(self, hidden_states):
+ if self.use_layer_scale:
+ pooling_output = self.pooling(self.before_norm(hidden_states))
+ scaled_op = self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * pooling_output
+ # First residual connection
+ hidden_states = hidden_states + self.drop_path(scaled_op)
+ outputs = ()
+
+ layer_output = self.output(self.after_norm(hidden_states))
+ scaled_op = self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * layer_output
+ # Second residual connection
+ output = hidden_states + self.drop_path(scaled_op)
+
+ outputs = (output,) + outputs
+ return outputs
+
+ else:
+ pooling_output = self.drop_path(self.pooling(self.before_norm(hidden_states)))
+ # First residual connection
+ hidden_states = pooling_output + hidden_states
+ outputs = ()
+
+ # Second residual connection inside the PoolFormerOutput block
+ layer_output = self.drop_path(self.output(self.after_norm(hidden_states)))
+ output = hidden_states + layer_output
+
+ outputs = (output,) + outputs
+ return outputs
+
+
+class PoolFormerEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ # stochastic depth decay rule
+ dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+
+ # patch embeddings
+ embeddings = []
+ for i in range(config.num_encoder_blocks):
+ embeddings.append(
+ PoolFormerEmbeddings(
+ patch_size=config.patch_sizes[i],
+ stride=config.strides[i],
+ padding=config.padding[i],
+ num_channels=config.num_channels if i == 0 else config.hidden_sizes[i - 1],
+ hidden_size=config.hidden_sizes[i],
+ )
+ )
+ self.patch_embeddings = nn.ModuleList(embeddings)
+
+ # Transformer blocks
+ blocks = []
+ cur = 0
+ for i in range(config.num_encoder_blocks):
+ # each block consists of layers
+ layers = []
+ if i != 0:
+ cur += config.depths[i - 1]
+ for j in range(config.depths[i]):
+ layers.append(
+ PoolFormerLayer(
+ config,
+ num_channels=config.hidden_sizes[i],
+ pool_size=config.pool_size,
+ hidden_size=config.hidden_sizes[i],
+ intermediate_size=int(config.hidden_sizes[i] * config.mlp_ratio),
+ drop_path=dpr[cur + j],
+ )
+ )
+ blocks.append(nn.ModuleList(layers))
+
+ self.block = nn.ModuleList(blocks)
+
+ def forward(self, pixel_values, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ hidden_states = pixel_values
+ for idx, layers in enumerate(zip(self.patch_embeddings, self.block)):
+ embedding_layer, block_layer = layers
+ # Get patch embeddings from hidden_states
+ hidden_states = embedding_layer(hidden_states)
+ # Send the embeddings through the blocks
+ for i, blk in enumerate(block_layer):
+ layer_outputs = blk(hidden_states)
+ hidden_states = layer_outputs[0]
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states] if v is not None)
+
+ return PoolFormerModelOutput(last_hidden_state=hidden_states, hidden_states=all_hidden_states)
+
+
+class PoolFormerPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = PoolFormerConfig
+ base_model_prefix = "poolformer"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, PoolFormerEncoder):
+ module.gradient_checkpointing = value
+
+
+POOLFORMER_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
+ it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`PoolFormerConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+POOLFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`PoolFormerFeatureExtractor`]. See
+ [`PoolFormerFeatureExtractor.__call__`] for details.
+"""
+
+
+@add_start_docstrings(
+ "The bare PoolFormer Model transformer outputting raw hidden-states without any specific head on top.",
+ POOLFORMER_START_DOCSTRING,
+)
+class PoolFormerModel(PoolFormerPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.encoder = PoolFormerEncoder(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ @add_start_docstrings_to_model_forward(POOLFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=PoolFormerModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(self, pixel_values=None, output_hidden_states=None, return_dict=None):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ encoder_outputs = self.encoder(
+ pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+
+ if not return_dict:
+ return (sequence_output, None) + encoder_outputs[1:]
+
+ return PoolFormerModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+class PoolFormerFinalPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+
+ def forward(self, hidden_states):
+ output = self.dense(hidden_states)
+ return output
+
+
+@add_start_docstrings(
+ """
+ PoolFormer Model transformer with an image classification head on top
+ """,
+ POOLFORMER_START_DOCSTRING,
+)
+class PoolFormerForImageClassification(PoolFormerPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.poolformer = PoolFormerModel(config)
+
+ # Final norm
+ self.norm = PoolFormerGroupNorm(config.hidden_sizes[-1])
+ # Classifier head
+ self.classifier = (
+ nn.Linear(config.hidden_sizes[-1], config.num_labels) if config.num_labels > 0 else nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(POOLFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=PoolFormerClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values=None,
+ labels=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.poolformer(
+ pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ logits = self.classifier(self.norm(sequence_output).mean([-2, -1]))
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return PoolFormerClassifierOutput(loss=loss, logits=logits, hidden_states=outputs.hidden_states)
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 0741e42861efa7..be08c8f0e29be3 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -2769,6 +2769,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class PoolFormerForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class PoolFormerModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class PoolFormerPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 1084d2fc4d0c6a..e49088d8b88ee4 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -87,6 +87,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class PoolFormerFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class SegformerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/test_feature_extraction_poolformer.py b/tests/test_feature_extraction_poolformer.py
new file mode 100644
index 00000000000000..cec912846c68c6
--- /dev/null
+++ b/tests/test_feature_extraction_poolformer.py
@@ -0,0 +1,193 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from .test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import PoolFormerFeatureExtractor
+
+
+class PoolFormerFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize_and_center_crop=True,
+ size=30,
+ crop_pct=0.9,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize_and_center_crop = do_resize_and_center_crop
+ self.size = size
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "size": self.size,
+ "do_resize_and_center_crop": self.do_resize_and_center_crop,
+ "crop_pct": self.crop_pct,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+
+@require_torch
+@require_vision
+class PoolFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = PoolFormerFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = PoolFormerFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_resize_and_center_crop"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "crop_pct"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/test_modeling_poolformer.py b/tests/test_modeling_poolformer.py
new file mode 100644
index 00000000000000..afbb5e1a6f7575
--- /dev/null
+++ b/tests/test_modeling_poolformer.py
@@ -0,0 +1,331 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch PoolFormer model. """
+
+
+import inspect
+import unittest
+from typing import Dict, List, Tuple
+
+from transformers import is_torch_available, is_vision_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from .test_configuration_common import ConfigTester
+from .test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import MODEL_MAPPING, PoolFormerConfig, PoolFormerForImageClassification, PoolFormerModel
+ from transformers.models.poolformer.modeling_poolformer import POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import PoolFormerFeatureExtractor
+
+
+class PoolFormerConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "hidden_sizes"))
+ self.parent.assertTrue(hasattr(config, "num_encoder_blocks"))
+
+
+class PoolFormerModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ num_encoder_blocks=4,
+ depths=[2, 2, 2, 2],
+ sr_ratios=[8, 4, 2, 1],
+ hidden_sizes=[16, 32, 64, 128],
+ downsampling_rates=[1, 4, 8, 16],
+ is_training=False,
+ use_labels=True,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_encoder_blocks = num_encoder_blocks
+ self.sr_ratios = sr_ratios
+ self.depths = depths
+ self.hidden_sizes = hidden_sizes
+ self.downsampling_rates = downsampling_rates
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = PoolFormerConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ num_encoder_blocks=self.num_encoder_blocks,
+ depths=self.depths,
+ hidden_sizes=self.hidden_sizes,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ initializer_range=self.initializer_range,
+ )
+
+ return config, pixel_values, labels
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = PoolFormerModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ expected_height = expected_width = self.image_size // 32.0
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.hidden_sizes[-1], expected_height, expected_width)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class PoolFormerModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (PoolFormerModel, PoolFormerForImageClassification) if is_torch_available() else ()
+
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = PoolFormerModelTester(self)
+ self.config_tester = PoolFormerConfigTester(self, config_class=PoolFormerConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip("PoolFormer does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip("PoolFormer does not have get_input_embeddings method and get_output_embeddings methods")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # Since poolformer doesn't use Attention
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ hidden_states = outputs.hidden_states[0]
+
+ hidden_states.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=f"Tuple and dict output are not equal. Difference: {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`: {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}.",
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ @unittest.skip("PoolFormer does not have attention")
+ def test_attention_outputs(self):
+ pass
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = self.model_tester.num_encoder_blocks
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-3:]),
+ [
+ self.model_tester.hidden_sizes[0],
+ self.model_tester.image_size // 4,
+ self.model_tester.image_size // 4,
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class in get_values(MODEL_MAPPING):
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = PoolFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+class PoolFormerModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_image_classification_head(self):
+ feature_extractor = PoolFormerFeatureExtractor()
+ model = PoolFormerForImageClassification.from_pretrained("sail/poolformer_s12").to(torch_device)
+
+ inputs = feature_extractor(images=prepare_img(), return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.6113, 0.1685, -0.0492]).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
+
+
+Tips:
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## PoolFormerConfig
+
+[[autodoc]] PoolFormerConfig
+
+## PoolFormerFeatureExtractor
+
+[[autodoc]] PoolFormerFeatureExtractor
+ - __call__
+
+## PoolFormerModel
+
+[[autodoc]] PoolFormerModel
+ - forward
+
+## PoolFormerForImageClassification
+
+[[autodoc]] PoolFormerForImageClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index ad05486104ee79..8efc520dc01369 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -263,6 +263,7 @@
"models.pegasus": ["PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP", "PegasusConfig", "PegasusTokenizer"],
"models.perceiver": ["PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PerceiverConfig", "PerceiverTokenizer"],
"models.phobert": ["PhobertTokenizer"],
+ "models.poolformer": ["POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PoolFormerConfig"],
"models.prophetnet": ["PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP", "ProphetNetConfig", "ProphetNetTokenizer"],
"models.qdqbert": ["QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "QDQBertConfig"],
"models.rag": ["RagConfig", "RagRetriever", "RagTokenizer"],
@@ -523,6 +524,7 @@
_import_structure["models.layoutlmv2"].append("LayoutLMv2Processor")
_import_structure["models.layoutxlm"].append("LayoutXLMProcessor")
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
+ _import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
_import_structure["models.segformer"].append("SegformerFeatureExtractor")
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
@@ -1214,6 +1216,14 @@
"PerceiverPreTrainedModel",
]
)
+ _import_structure["models.poolformer"].extend(
+ [
+ "POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "PoolFormerForImageClassification",
+ "PoolFormerModel",
+ "PoolFormerPreTrainedModel",
+ ]
+ )
_import_structure["models.prophetnet"].extend(
[
"PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -2483,6 +2493,7 @@
from .models.pegasus import PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP, PegasusConfig, PegasusTokenizer
from .models.perceiver import PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP, PerceiverConfig, PerceiverTokenizer
from .models.phobert import PhobertTokenizer
+ from .models.poolformer import POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, PoolFormerConfig
from .models.prophetnet import PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP, ProphetNetConfig, ProphetNetTokenizer
from .models.qdqbert import QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, QDQBertConfig
from .models.rag import RagConfig, RagRetriever, RagTokenizer
@@ -2700,6 +2711,7 @@
from .models.layoutlmv2 import LayoutLMv2FeatureExtractor, LayoutLMv2Processor
from .models.layoutxlm import LayoutXLMProcessor
from .models.perceiver import PerceiverFeatureExtractor
+ from .models.poolformer import PoolFormerFeatureExtractor
from .models.segformer import SegformerFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
@@ -3272,6 +3284,12 @@
PerceiverModel,
PerceiverPreTrainedModel,
)
+ from .models.poolformer import (
+ POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ PoolFormerForImageClassification,
+ PoolFormerModel,
+ PoolFormerPreTrainedModel,
+ )
from .models.prophetnet import (
PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST,
ProphetNetDecoder,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index d6cf69197ea961..50d287c61efcde 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -83,6 +83,7 @@
pegasus,
perceiver,
phobert,
+ poolformer,
prophetnet,
qdqbert,
rag,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 9223123d3432d4..1115ffb7a3663d 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("poolformer", "PoolFormerConfig"),
("convnext", "ConvNextConfig"),
("yoso", "YosoConfig"),
("swin", "SwinConfig"),
@@ -125,6 +126,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here
+ ("poolformer", "POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -207,6 +209,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("poolformer", "PoolFormer"),
("convnext", "ConvNext"),
("yoso", "YOSO"),
("swin", "Swin"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 50e7ff1b823be5..ed0e58e0081a14 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -53,6 +53,7 @@
("vit_mae", "ViTFeatureExtractor"),
("segformer", "SegformerFeatureExtractor"),
("convnext", "ConvNextFeatureExtractor"),
+ ("poolformer", "PoolFormerFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index fe472cc654eac5..5e8c8149dd44f5 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("poolformer", "PoolFormerModel"),
("convnext", "ConvNextModel"),
("yoso", "YosoModel"),
("swin", "SwinModel"),
@@ -275,6 +276,7 @@
),
("swin", "SwinForImageClassification"),
("convnext", "ConvNextForImageClassification"),
+ ("poolformer", "PoolFormerForImageClassification"),
]
)
diff --git a/src/transformers/models/poolformer/__init__.py b/src/transformers/models/poolformer/__init__.py
new file mode 100644
index 00000000000000..246dc7645596f4
--- /dev/null
+++ b/src/transformers/models/poolformer/__init__.py
@@ -0,0 +1,58 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_poolformer": ["POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "PoolFormerConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_poolformer"] = ["PoolFormerFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_poolformer"] = [
+ "POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "PoolFormerForImageClassification",
+ "PoolFormerModel",
+ "PoolFormerPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_poolformer import POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, PoolFormerConfig
+
+ if is_vision_available():
+ from .feature_extraction_poolformer import PoolFormerFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_poolformer import (
+ POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ PoolFormerForImageClassification,
+ PoolFormerModel,
+ PoolFormerPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure)
diff --git a/src/transformers/models/poolformer/configuration_poolformer.py b/src/transformers/models/poolformer/configuration_poolformer.py
new file mode 100644
index 00000000000000..d5cb07bd584fe7
--- /dev/null
+++ b/src/transformers/models/poolformer/configuration_poolformer.py
@@ -0,0 +1,127 @@
+# coding=utf-8
+# Copyright 2022 Sea AI Labs and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PoolFormer model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "sail/poolformer_s12": "https://huggingface.co/sail/poolformer_s12/resolve/main/config.json",
+ # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
+}
+
+
+class PoolFormerConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of [`PoolFormerModel`]. It is used to instantiate a
+ PoolFormer model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the PoolFormer
+ [sail/poolformer_s12](https://huggingface.co/sail/poolformer_s12) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of channels in the input image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size of the input patch.
+ stride (`int`, *optional*, defaults to 16):
+ The stride of the input patch.
+ pool_size (`int`, *optional*, defaults to 3):
+ The size of the pooling window.
+ mlp_ratio (`float`, *optional*, defaults to 4.0):
+ The ratio of the number of channels in the output of the MLP to the number of channels in the input.
+ depths (`list`, *optional*, defaults to `[2, 2, 6, 2]`):
+ The depth of each encoder block.
+ hidden_sizes (`list`, *optional*, defaults to `[64, 128, 320, 512]`):
+ The hidden sizes of each encoder block.
+ patch_sizes (`list`, *optional*, defaults to `[7, 3, 3, 3]`):
+ The size of the input patch for each encoder block.
+ strides (`list`, *optional*, defaults to `[4, 2, 2, 2]`):
+ The stride of the input patch for each encoder block.
+ padding (`list`, *optional*, defaults to `[2, 1, 1, 1]`):
+ The padding of the input patch for each encoder block.
+ num_encoder_blocks (`int`, *optional*, defaults to 4):
+ The number of encoder blocks.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ The dropout rate for the dropout layers.
+ hidden_act (`str`, *optional*, defaults to `"gelu"`):
+ The activation function for the hidden layers.
+ use_layer_scale (`bool`, *optional*, defaults to `True`):
+ Whether to use layer scale.
+ layer_scale_init_value (`float`, *optional*, defaults to 1e-5):
+ The initial value for the layer scale.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The initializer range for the weights.
+
+ Example:
+
+ ```python
+ >>> from transformers import PoolFormerModel, PoolFormerConfig
+
+ >>> # Initializing a PoolFormer sail/poolformer_s12 style configuration
+ >>> configuration = PoolFormerConfig()
+
+ >>> # Initializing a model from the sail/poolformer_s12 style configuration
+ >>> model = PoolFormerModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```
+ """
+ model_type = "poolformer"
+
+ def __init__(
+ self,
+ num_channels=3,
+ patch_size=16,
+ stride=16,
+ pool_size=3,
+ mlp_ratio=4.0,
+ depths=[2, 2, 6, 2],
+ hidden_sizes=[64, 128, 320, 512],
+ patch_sizes=[7, 3, 3, 3],
+ strides=[4, 2, 2, 2],
+ padding=[2, 1, 1, 1],
+ num_encoder_blocks=4,
+ drop_path_rate=0.0,
+ hidden_act="gelu",
+ use_layer_scale=True,
+ layer_scale_init_value=1e-5,
+ initializer_range=0.02,
+ **kwargs
+ ):
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.stride = stride
+ self.padding = padding
+ self.pool_size = pool_size
+ self.hidden_sizes = hidden_sizes
+ self.mlp_ratio = mlp_ratio
+ self.depths = depths
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.num_encoder_blocks = num_encoder_blocks
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.use_layer_scale = use_layer_scale
+ self.layer_scale_init_value = layer_scale_init_value
+ self.initializer_range = initializer_range
+ super().__init__(**kwargs)
diff --git a/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py b/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
new file mode 100644
index 00000000000000..eebc8b0c5e713d
--- /dev/null
+++ b/src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
@@ -0,0 +1,214 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert PoolFormer checkpoints from the original repository. URL: https://github.com/sail-sg/poolformer"""
+
+import argparse
+import json
+from collections import OrderedDict
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import cached_download, hf_hub_url
+from transformers import PoolFormerConfig, PoolFormerFeatureExtractor, PoolFormerForImageClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def replace_key_with_offset(key, offset, original_name, new_name):
+ """
+ Replaces the key by subtracting the offset from the original layer number
+ """
+ to_find = original_name.split(".")[0]
+ key_list = key.split(".")
+ orig_block_num = int(key_list[key_list.index(to_find) - 2])
+ layer_num = int(key_list[key_list.index(to_find) - 1])
+ new_block_num = orig_block_num - offset
+
+ key = key.replace(f"{orig_block_num}.{layer_num}.{original_name}", f"block.{new_block_num}.{layer_num}.{new_name}")
+ return key
+
+
+def rename_keys(state_dict):
+ new_state_dict = OrderedDict()
+ total_embed_found, patch_emb_offset = 0, 0
+ for key, value in state_dict.items():
+ if key.startswith("network"):
+ key = key.replace("network", "poolformer.encoder")
+ if "proj" in key:
+ # Works for the first embedding as well as the internal embedding layers
+ if key.endswith("bias") and "patch_embed" not in key:
+ patch_emb_offset += 1
+ to_replace = key[: key.find("proj")]
+ key = key.replace(to_replace, f"patch_embeddings.{total_embed_found}.")
+ key = key.replace("proj", "projection")
+ if key.endswith("bias"):
+ total_embed_found += 1
+ if "patch_embeddings" in key:
+ key = "poolformer.encoder." + key
+ if "mlp.fc1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "mlp.fc1", "output.conv1")
+ if "mlp.fc2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "mlp.fc2", "output.conv2")
+ if "norm1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "norm1", "before_norm")
+ if "norm2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "norm2", "after_norm")
+ if "layer_scale_1" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "layer_scale_1", "layer_scale_1")
+ if "layer_scale_2" in key:
+ key = replace_key_with_offset(key, patch_emb_offset, "layer_scale_2", "layer_scale_2")
+ if "head" in key:
+ key = key.replace("head", "classifier")
+ new_state_dict[key] = value
+ return new_state_dict
+
+
+# We will verify our results on a COCO image
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+
+ return image
+
+
+@torch.no_grad()
+def convert_poolformer_checkpoint(model_name, checkpoint_path, pytorch_dump_folder_path):
+ """
+ Copy/paste/tweak model's weights to our PoolFormer structure.
+ """
+
+ # load default PoolFormer configuration
+ config = PoolFormerConfig()
+
+ # set attributes based on model_name
+ repo_id = "datasets/huggingface/label-files"
+ size = model_name[-3:]
+ config.num_labels = 1000
+ filename = "imagenet-1k-id2label.json"
+ expected_shape = (1, 1000)
+
+ # set config attributes
+ id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename)), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+ if size == "s12":
+ config.depths = [2, 2, 6, 2]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ crop_pct = 0.9
+ elif size == "s24":
+ config.depths = [4, 4, 12, 4]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ crop_pct = 0.9
+ elif size == "s36":
+ config.depths = [6, 6, 18, 6]
+ config.hidden_sizes = [64, 128, 320, 512]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.9
+ elif size == "m36":
+ config.depths = [6, 6, 18, 6]
+ config.hidden_sizes = [96, 192, 384, 768]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.95
+ elif size == "m48":
+ config.depths = [8, 8, 24, 8]
+ config.hidden_sizes = [96, 192, 384, 768]
+ config.mlp_ratio = 4.0
+ config.layer_scale_init_value = 1e-6
+ crop_pct = 0.95
+ else:
+ raise ValueError(f"Size {size} not supported")
+
+ # load feature extractor
+ feature_extractor = PoolFormerFeatureExtractor(crop_pct=crop_pct)
+
+ # Prepare image
+ image = prepare_img()
+ pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ logger.info(f"Converting model {model_name}...")
+
+ # load original state dict
+ state_dict = torch.load(checkpoint_path, map_location=torch.device("cpu"))
+
+ # rename keys
+ state_dict = rename_keys(state_dict)
+
+ # create HuggingFace model and load state dict
+ model = PoolFormerForImageClassification(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # Define feature extractor
+ feature_extractor = PoolFormerFeatureExtractor(crop_pct=crop_pct)
+ pixel_values = feature_extractor(images=prepare_img(), return_tensors="pt").pixel_values
+
+ # forward pass
+ outputs = model(pixel_values)
+ logits = outputs.logits
+
+ # define expected logit slices for different models
+ if size == "s12":
+ expected_slice = torch.tensor([-0.3045, -0.6758, -0.4869])
+ elif size == "s24":
+ expected_slice = torch.tensor([0.4402, -0.1374, -0.8045])
+ elif size == "s36":
+ expected_slice = torch.tensor([-0.6080, -0.5133, -0.5898])
+ elif size == "m36":
+ expected_slice = torch.tensor([0.3952, 0.2263, -1.2668])
+ elif size == "m48":
+ expected_slice = torch.tensor([0.1167, -0.0656, -0.3423])
+ else:
+ raise ValueError(f"Size {size} not supported")
+
+ # verify logits
+ assert logits.shape == expected_shape
+ assert torch.allclose(logits[0, :3], expected_slice, atol=1e-2)
+
+ # finally, save model and feature extractor
+ logger.info(f"Saving PyTorch model and feature extractor to {pytorch_dump_folder_path}...")
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--model_name",
+ default="poolformer_s12",
+ type=str,
+ help="Name of the model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, help="Path to the original PyTorch checkpoint (.pth file)."
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the folder to output PyTorch model."
+ )
+ args = parser.parse_args()
+ convert_poolformer_checkpoint(args.model_name, args.checkpoint_path, args.pytorch_dump_folder_path)
diff --git a/src/transformers/models/poolformer/feature_extraction_poolformer.py b/src/transformers/models/poolformer/feature_extraction_poolformer.py
new file mode 100644
index 00000000000000..b7d44e22265193
--- /dev/null
+++ b/src/transformers/models/poolformer/feature_extraction_poolformer.py
@@ -0,0 +1,172 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for PoolFormer."""
+
+import math
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...file_utils import TensorType
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class PoolFormerFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a PoolFormer feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize_and_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shortest edge of the image and center crop the input to a certain `size`.
+ size (`int` or `Tuple(int)`, *optional*, defaults to 224):
+ Center crop the input to the given size. If a tuple is provided, it should be (width, height). If only an
+ integer is provided, then the input will be center cropped to (size, size). Only has an effect if
+ `do_resize_and_center_crop` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize_and_center_crop` is set to `True`.
+ crop_pct (`float`, *optional*, defaults to `0.9`):
+ The percentage of the image to crop from the center. Only has an effect if `do_resize_and_center_crop` is
+ set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with `image_mean` and `image_std`.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize_and_center_crop=True,
+ size=224,
+ resample=Image.BICUBIC,
+ crop_pct=0.9,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize_and_center_crop = do_resize_and_center_crop
+ self.size = size
+ self.resample = resample
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize_and_center_crop and self.size is not None and self.crop_pct is not None:
+ if isinstance(self.size, (tuple, list)):
+ assert len(self.size) == 2
+ if self.size[-1] == self.size[-2]:
+ scale_size = int(math.floor(self.size[0] / self.crop_pct))
+ else:
+ scale_size = tuple([int(x / self.crop_pct) for x in self.size])
+ else:
+ scale_size = int(math.floor(self.size / self.crop_pct))
+
+ # resize shortest edge of the image
+ images = [
+ self.resize(image=image, size=scale_size, resample=self.resample, default_to_square=False)
+ for image in images
+ ]
+ # center crop
+ images = [self.center_crop(image, size=self.size) for image in images]
+
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/poolformer/modeling_poolformer.py b/src/transformers/models/poolformer/modeling_poolformer.py
new file mode 100755
index 00000000000000..17205e31124728
--- /dev/null
+++ b/src/transformers/models/poolformer/modeling_poolformer.py
@@ -0,0 +1,499 @@
+# coding=utf-8
+# Copyright 2022 Sea AI Lab and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch PoolFormer model."""
+
+
+import collections.abc
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import logging
+from .configuration_poolformer import PoolFormerConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "PoolFormerConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "PoolFormerFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "sail/poolformer_s12"
+_EXPECTED_OUTPUT_SHAPE = [1, 197, 768]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "sail/poolformer_s12"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "'tabby, tabby cat'"
+
+POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "sail/poolformer_s12",
+ # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
+]
+
+
+# Copied from transformers.models.vit.modeling_vit.to_2tuple
+def to_2tuple(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return (x, x)
+
+
+@dataclass
+class PoolFormerModelOutput(ModelOutput):
+ """
+ Class for PoolFormerModel's outputs, with potential hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class PoolFormerClassifierOutput(ModelOutput):
+ """
+ Class for PoolformerForImageClassification's outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+def drop_path(x, drop_prob: float = 0.0, training: bool = False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is
+ misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion:
+ https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and
+ argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class PoolFormerDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob=None):
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class PoolFormerEmbeddings(nn.Module):
+ """
+ Construct Patch Embeddings.
+ """
+
+ def __init__(self, hidden_size, num_channels, patch_size, stride, padding, norm_layer=None):
+ super().__init__()
+ patch_size = to_2tuple(patch_size)
+ stride = to_2tuple(stride)
+ padding = to_2tuple(padding)
+
+ self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=stride, padding=padding)
+ self.norm = norm_layer(hidden_size) if norm_layer else nn.Identity()
+
+ def forward(self, pixel_values):
+ x = self.projection(pixel_values)
+ x = self.norm(x)
+ return x
+
+
+class PoolFormerGroupNorm(nn.GroupNorm):
+ """
+ Group Normalization with 1 group. Input: tensor in shape [B, C, H, W]
+ """
+
+ def __init__(self, num_channels, **kwargs):
+ super().__init__(1, num_channels, **kwargs)
+
+
+class PoolFormerPooling(nn.Module):
+ def __init__(self, pool_size):
+ super().__init__()
+ self.pool = nn.AvgPool2d(pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
+
+ def forward(self, hidden_states):
+ return self.pool(hidden_states) - hidden_states
+
+
+class PoolFormerOutput(nn.Module):
+ def __init__(self, config, dropout_prob, hidden_size, intermediate_size):
+ super().__init__()
+ self.conv1 = nn.Conv2d(hidden_size, intermediate_size, 1)
+ self.conv2 = nn.Conv2d(intermediate_size, hidden_size, 1)
+ self.drop = PoolFormerDropPath(dropout_prob)
+ if isinstance(config.hidden_act, str):
+ self.act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.act_fn(hidden_states)
+ hidden_states = self.drop(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = self.drop(hidden_states)
+
+ return hidden_states
+
+
+class PoolFormerLayer(nn.Module):
+ """This corresponds to the 'PoolFormerBlock' class in the original implementation."""
+
+ def __init__(self, config, num_channels, pool_size, hidden_size, intermediate_size, drop_path):
+ super().__init__()
+ self.pooling = PoolFormerPooling(pool_size)
+ self.output = PoolFormerOutput(config, drop_path, hidden_size, intermediate_size)
+ self.before_norm = PoolFormerGroupNorm(num_channels)
+ self.after_norm = PoolFormerGroupNorm(num_channels)
+
+ # Useful for training neural nets
+ self.drop_path = PoolFormerDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+ self.use_layer_scale = config.use_layer_scale
+ if config.use_layer_scale:
+ self.layer_scale_1 = nn.Parameter(
+ config.layer_scale_init_value * torch.ones((num_channels)), requires_grad=True
+ )
+ self.layer_scale_2 = nn.Parameter(
+ config.layer_scale_init_value * torch.ones((num_channels)), requires_grad=True
+ )
+
+ def forward(self, hidden_states):
+ if self.use_layer_scale:
+ pooling_output = self.pooling(self.before_norm(hidden_states))
+ scaled_op = self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * pooling_output
+ # First residual connection
+ hidden_states = hidden_states + self.drop_path(scaled_op)
+ outputs = ()
+
+ layer_output = self.output(self.after_norm(hidden_states))
+ scaled_op = self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * layer_output
+ # Second residual connection
+ output = hidden_states + self.drop_path(scaled_op)
+
+ outputs = (output,) + outputs
+ return outputs
+
+ else:
+ pooling_output = self.drop_path(self.pooling(self.before_norm(hidden_states)))
+ # First residual connection
+ hidden_states = pooling_output + hidden_states
+ outputs = ()
+
+ # Second residual connection inside the PoolFormerOutput block
+ layer_output = self.drop_path(self.output(self.after_norm(hidden_states)))
+ output = hidden_states + layer_output
+
+ outputs = (output,) + outputs
+ return outputs
+
+
+class PoolFormerEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ # stochastic depth decay rule
+ dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+
+ # patch embeddings
+ embeddings = []
+ for i in range(config.num_encoder_blocks):
+ embeddings.append(
+ PoolFormerEmbeddings(
+ patch_size=config.patch_sizes[i],
+ stride=config.strides[i],
+ padding=config.padding[i],
+ num_channels=config.num_channels if i == 0 else config.hidden_sizes[i - 1],
+ hidden_size=config.hidden_sizes[i],
+ )
+ )
+ self.patch_embeddings = nn.ModuleList(embeddings)
+
+ # Transformer blocks
+ blocks = []
+ cur = 0
+ for i in range(config.num_encoder_blocks):
+ # each block consists of layers
+ layers = []
+ if i != 0:
+ cur += config.depths[i - 1]
+ for j in range(config.depths[i]):
+ layers.append(
+ PoolFormerLayer(
+ config,
+ num_channels=config.hidden_sizes[i],
+ pool_size=config.pool_size,
+ hidden_size=config.hidden_sizes[i],
+ intermediate_size=int(config.hidden_sizes[i] * config.mlp_ratio),
+ drop_path=dpr[cur + j],
+ )
+ )
+ blocks.append(nn.ModuleList(layers))
+
+ self.block = nn.ModuleList(blocks)
+
+ def forward(self, pixel_values, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ hidden_states = pixel_values
+ for idx, layers in enumerate(zip(self.patch_embeddings, self.block)):
+ embedding_layer, block_layer = layers
+ # Get patch embeddings from hidden_states
+ hidden_states = embedding_layer(hidden_states)
+ # Send the embeddings through the blocks
+ for i, blk in enumerate(block_layer):
+ layer_outputs = blk(hidden_states)
+ hidden_states = layer_outputs[0]
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states] if v is not None)
+
+ return PoolFormerModelOutput(last_hidden_state=hidden_states, hidden_states=all_hidden_states)
+
+
+class PoolFormerPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = PoolFormerConfig
+ base_model_prefix = "poolformer"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, PoolFormerEncoder):
+ module.gradient_checkpointing = value
+
+
+POOLFORMER_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
+ it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`PoolFormerConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+POOLFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`PoolFormerFeatureExtractor`]. See
+ [`PoolFormerFeatureExtractor.__call__`] for details.
+"""
+
+
+@add_start_docstrings(
+ "The bare PoolFormer Model transformer outputting raw hidden-states without any specific head on top.",
+ POOLFORMER_START_DOCSTRING,
+)
+class PoolFormerModel(PoolFormerPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.encoder = PoolFormerEncoder(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ @add_start_docstrings_to_model_forward(POOLFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=PoolFormerModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(self, pixel_values=None, output_hidden_states=None, return_dict=None):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ encoder_outputs = self.encoder(
+ pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+
+ if not return_dict:
+ return (sequence_output, None) + encoder_outputs[1:]
+
+ return PoolFormerModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+class PoolFormerFinalPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+
+ def forward(self, hidden_states):
+ output = self.dense(hidden_states)
+ return output
+
+
+@add_start_docstrings(
+ """
+ PoolFormer Model transformer with an image classification head on top
+ """,
+ POOLFORMER_START_DOCSTRING,
+)
+class PoolFormerForImageClassification(PoolFormerPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.poolformer = PoolFormerModel(config)
+
+ # Final norm
+ self.norm = PoolFormerGroupNorm(config.hidden_sizes[-1])
+ # Classifier head
+ self.classifier = (
+ nn.Linear(config.hidden_sizes[-1], config.num_labels) if config.num_labels > 0 else nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(POOLFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=PoolFormerClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(
+ self,
+ pixel_values=None,
+ labels=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.poolformer(
+ pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ logits = self.classifier(self.norm(sequence_output).mean([-2, -1]))
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return PoolFormerClassifierOutput(loss=loss, logits=logits, hidden_states=outputs.hidden_states)
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 0741e42861efa7..be08c8f0e29be3 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -2769,6 +2769,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class PoolFormerForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class PoolFormerModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class PoolFormerPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 1084d2fc4d0c6a..e49088d8b88ee4 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -87,6 +87,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class PoolFormerFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class SegformerFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/test_feature_extraction_poolformer.py b/tests/test_feature_extraction_poolformer.py
new file mode 100644
index 00000000000000..cec912846c68c6
--- /dev/null
+++ b/tests/test_feature_extraction_poolformer.py
@@ -0,0 +1,193 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from .test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import PoolFormerFeatureExtractor
+
+
+class PoolFormerFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize_and_center_crop=True,
+ size=30,
+ crop_pct=0.9,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize_and_center_crop = do_resize_and_center_crop
+ self.size = size
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "size": self.size,
+ "do_resize_and_center_crop": self.do_resize_and_center_crop,
+ "crop_pct": self.crop_pct,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+
+@require_torch
+@require_vision
+class PoolFormerFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = PoolFormerFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = PoolFormerFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_resize_and_center_crop"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "crop_pct"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/test_modeling_poolformer.py b/tests/test_modeling_poolformer.py
new file mode 100644
index 00000000000000..afbb5e1a6f7575
--- /dev/null
+++ b/tests/test_modeling_poolformer.py
@@ -0,0 +1,331 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch PoolFormer model. """
+
+
+import inspect
+import unittest
+from typing import Dict, List, Tuple
+
+from transformers import is_torch_available, is_vision_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from .test_configuration_common import ConfigTester
+from .test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import MODEL_MAPPING, PoolFormerConfig, PoolFormerForImageClassification, PoolFormerModel
+ from transformers.models.poolformer.modeling_poolformer import POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import PoolFormerFeatureExtractor
+
+
+class PoolFormerConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "hidden_sizes"))
+ self.parent.assertTrue(hasattr(config, "num_encoder_blocks"))
+
+
+class PoolFormerModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ num_encoder_blocks=4,
+ depths=[2, 2, 2, 2],
+ sr_ratios=[8, 4, 2, 1],
+ hidden_sizes=[16, 32, 64, 128],
+ downsampling_rates=[1, 4, 8, 16],
+ is_training=False,
+ use_labels=True,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_encoder_blocks = num_encoder_blocks
+ self.sr_ratios = sr_ratios
+ self.depths = depths
+ self.hidden_sizes = hidden_sizes
+ self.downsampling_rates = downsampling_rates
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = PoolFormerConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ num_encoder_blocks=self.num_encoder_blocks,
+ depths=self.depths,
+ hidden_sizes=self.hidden_sizes,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ initializer_range=self.initializer_range,
+ )
+
+ return config, pixel_values, labels
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = PoolFormerModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ expected_height = expected_width = self.image_size // 32.0
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.hidden_sizes[-1], expected_height, expected_width)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class PoolFormerModelTest(ModelTesterMixin, unittest.TestCase):
+
+ all_model_classes = (PoolFormerModel, PoolFormerForImageClassification) if is_torch_available() else ()
+
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = PoolFormerModelTester(self)
+ self.config_tester = PoolFormerConfigTester(self, config_class=PoolFormerConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip("PoolFormer does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip("PoolFormer does not have get_input_embeddings method and get_output_embeddings methods")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # Since poolformer doesn't use Attention
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ hidden_states = outputs.hidden_states[0]
+
+ hidden_states.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=f"Tuple and dict output are not equal. Difference: {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`: {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}.",
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ @unittest.skip("PoolFormer does not have attention")
+ def test_attention_outputs(self):
+ pass
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = self.model_tester.num_encoder_blocks
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-3:]),
+ [
+ self.model_tester.hidden_sizes[0],
+ self.model_tester.image_size // 4,
+ self.model_tester.image_size // 4,
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ return
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class in get_values(MODEL_MAPPING):
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = PoolFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+class PoolFormerModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_image_classification_head(self):
+ feature_extractor = PoolFormerFeatureExtractor()
+ model = PoolFormerForImageClassification.from_pretrained("sail/poolformer_s12").to(torch_device)
+
+ inputs = feature_extractor(images=prepare_img(), return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.6113, 0.1685, -0.0492]).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))