TelethonClient RAM consumption increases without limit over time #3235
Comments
|
Try clearing the entity cache periodically (see #3073) |
Thanks for the reply. So you suggest calling client._entity_cache.clear()if I have understood correctly how entity cache is implemented in the This will result in the client re-fetching entities when using them again I guess. So I can call it every time scraping of a channel is finished, I suppose? |
|
Telegram sends a lot of extra data for your requests. For example, if you request channel history, you’ll also get all linked users (e.g. from post comments) and chats (e.g. from reposted messages or mentions) together with message contents. All that stuff is saved to the entity cache. In other words, entity cache saves all As far as I understand, you only need your channels' access hashes, so you can either cache them in your app and disable the entity cache entirely, or clear the entity cache selectively (delete everything except |
|
Okay. The route I have chosen for testing is just clearing the entire entity cache after the scraping of a channel is finished. This is no problem, as - at least currently - I don't re-scan lots of channels regularly, and at the current state of the application, The probability that a channel is picked up by the same client the second time is extremely low (less than 1%, I have lots of clients). So there isn't really a use for the entity cache here anyways, as every client has its own. It would be interesting though to cache some data in my PostgreSQL database to avoid calling I will keep you updated if clearing the entity cache solved the RAM issue. I restarted the application yesterday with the change, and it has gone up from 300MB to 2.1GB since. Maybe this is just because it needs some time to launch eveything and stabilize. If it stays like that, it is absolutely acceptable for me. (I am not talking about increases of 300MB / month like in the other issue, I am dealing with increases of 10GB / week here, which is obviously a problem even if you have a lot of RAM). |
You’ll need to store access hash and channel ID of each channel. https://core.telegram.org/constructor/inputPeerChannel IDs are the same across different accounts, access hashes are unique (different accounts will have different access hashes). |
|
Update handling needs to know which entities it has a hash for, because it needs to call getDifference if it's missing a hash. They could be flushed to disk and cleared periodically, but I'm personally not affected by this, so I'm unlikely to look into it any time soon. Note that update handling can also be disabled entirely. If someone is interested in working on this let me know and I can offer some guidance. v2 has some changes so that only entities from updates are stored in cache (as opposed to any request which may return entities). |
|
Finally I have new test data. After cleaning the entity cache after every scan, I get The RAM consumption growth is slowed down, but after 1-2 weeks of running, the remaining objects fill it up anyways. @Lonami do you think disabling updates can help against this, and how do I disable them? I quickly checked the docs but could not find what I was looking for. I don't have any update handlers registered. If you can provide some guidance on how to fix the RAM consumption issue, I'd be very thankful. I will need to fix this sooner or later. Either there is another cache in addition to the entity cache that makes trouble, or there might be some unreleased objects created somewhere else. Maybe not all in telethon itself, might as well be in my post processing. |
|
My recommendation is wait until v2 is released because it's going to change a lot and would probably void any attempt at looking at it now. Unfortunately the v2 release is probably not going to be sooner rather than later. |
Ok, thank you. Is there an ETA? |
|
Hi Lonami, I also faced this problem. I think I found a memory leak: Set
|
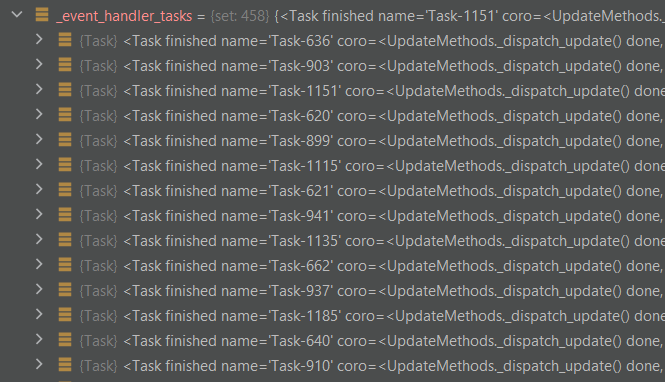
|
The only place where that set is filled is here: Telethon/telethon/client/updates.py Lines 272 to 274 in b2925f8 As far as I can tell, when a task is done, it cleans after itself. This is pretty much what Python's documentation recommends doing (funny, I don't recall this being in their docs):
Perhaps you could try changing line 274 with the following: task.add_done_callback(self._event_handler_tasks.discard)and report back. As far as I can tell though, that won't be any better (in fact it may be worse if the task is wrapped in another way as it won't be discarded). In any case, I suspect the leak may be somewhere else. But you can also comment out this line entirely and see if it helps (you may get some "task was garbage collected" messages though). |
It really helped. Comparison
I will continue to monitor the behavior and will let you know if I find anything useful. |
|
Maybe it's the loop and the lambda capturing the older task so it only clears the latest one (which is an issue if there's more than one). I will push that change to the main branch, thanks. |
See #3235. This should help tone down memory usage a little.
There is an error in the commit, it should be like this |
See #3235. This should help tone down memory usage a little.
|
Hi and thanks to both of you for having a look at this. @alexgoryushkin was this the major memory leak in your setup, is the RAM consumption approximately constant after the fix was applied, or was this just one of multiple culprits? Difficult for me to test this at the moment, as we are moving to a new infrastructure. |
Hi, after the changes, the client size has started to grow 2 times slower, but it is still ongoing, so there are still problems. Unfortunately, I do not have the opportunity to continue studying this issue now, but I will try to return to it as soon as possible. |
|
I left the client running for a few hours after joining in a few flood chats. An issue with the entity cache has been identified, it grows indefinitely. Client size log in megabytes: And as far as I can tell, automatic cleaning is not currently provided, but it needs to be implemented. At the same time, it seems to me that the cleanup should be smart enough to store only frequently used objects in memory, I think the LRU algorithm is suitable for this purpose. |
|
@alexgoryushkin have you seen all the messages above? the entity cache problem was known to us, worked for me. I did not know however that there is a second |
|
@ehtec have you found how to clean _mb_entity_cache? client._mb_entity_cache.clear() dont work( |
No, I don't have this code running at the moment so cannot test. Try to figure out what is the content and the type of this attribute by printing, if it's an object look at its declaration, maybe there is a similar method to clear. Maybe it's just a dictionary or list, then try to empty it manually |
|
@w1ld32 just call I'm having the same problem right now, hope this will help |
|
@ehtec, @w1ld32, @danielWagnerr |
|
Thanks @alexgoryushkin, I'll use your changes Also I'll keep investigating |
|
I found an interesting detail. It seems _updates_queue doesn't have time to clear itself when there are too many updates coming in. Even if there are no update handlers. This is a function to calculate the size of an object, honestly stolen from stackoverflow: import sys
from gc import get_referents
from types import ModuleType, FunctionType
BLACKLIST = type, ModuleType, FunctionType
def sizeof(obj):
if isinstance(obj, BLACKLIST):
return 0
seen_ids = set()
size = 0
objects = [obj]
while objects:
need_referents = []
for obj in objects:
if not isinstance(obj, BLACKLIST) and id(obj) not in seen_ids:
seen_ids.add(id(obj))
size += sys.getsizeof(obj)
need_referents.append(obj)
objects = get_referents(*need_referents)
return sizeLogging client memory consumption, updates to the queue, and number of tasks in asyncio: logger.debug(f"RAM (MB): client {sizeof(client) / (2 ** 20):5.2f} | "
f"_updates_queue {client._updates_queue.qsize()} | "
f"all_tasks {len(asyncio.all_tasks(loop))} | "
f"event_handlers {client.list_event_handlers()}")Log output for 2 sessions: |
|
v2 is still in alpha stage, but it will feature a However, the recommendation on #3235 (comment) stands, and now it would be possible to test v2 early. |
|
By the way, I found a problem with my code. It turned out that in some places blocking operations were being performed. As a result, the event loop did not have time to process the updates correctly. You can reproduce this behaviour with this event listener: async def my_event_handler(event: NewMessage.Event):
if random.choice((True, False)):
await asyncio.sleep(random.uniform(1, 20))
else:
time.sleep(random.uniform(1, 20)) |
|
Is there a good solution to this problem? |
|
Any update for this? |
Checklist
pip install -U https://github.com/LonamiWebs/Telethon/archive/master.zipand triggered the bug in the latest version.I experience increased memory consumption over time when running telethon in a channel-scanning setup with many parallel sessions for a longer time. For each client, an
asyncioworker task is created, which is retrieving channels / groups to scan from anasyncio.Queue. The worker executes a couple of coroutines on each channel. The relevant code is posted below.Code that causes the issue
public_nameis the channel / group name in all coroutines. The worker calls each of these coroutines on the channel / group name one by one before proceeding to the next element from the queue.Garbage collection is enabled at the top of the file:
Issue
The memory used by the script is increasing without limitation, as it can be seen from any system monitoring tool (like
gnome-system-monitor).I used
objgraphto get a little more information on what objects are causing the increased memory usage:is executed regularly.
An example result:
The text was updated successfully, but these errors were encountered: