ln2sql is a NLP tool to query a database in natural language. The tool takes in input a database model and a sentence and translate the latter in a valid SQL statement able to query the input data model.
The initial tool is described in the following French paper (which can be found in the docs/ directory):
Please cite the paper if you use ln2sql.
ln2sql is not the state-of-the-art tool for copyright reasons. It's just a quick & dirty Python wrapper but it has some speed optimizations.
-
In the paper, TreeTagger is used to filter the words of the input sentence according to its POS tagging. In this way, a mapping between the keywords of the input sentence and the keywords of the data model can be performed. In ln2sql, Treegagger is left in favour of an import of personal configuration files (for languages, stop words and synonyms) to be more generic.
Beware that ln2sql cannot therefore automatically solve the gender and number problem. So if the word "students" is in the input sentence, it does not match with the table "student" in the model of data. To do that, the equivalence "students → student" must be appear in the used thesaurus. If you want a version using TreeTagger, a Python wrapper exists and a documentation can be found here.
-
A grammar still parse the input sentence to generate the corresponding query structure, but now this structure is stocked in a Python class able to print a query structure JSON file. Thus, the hash map for the query generation was abandoned. In addition, a multi-threading implementation was adopted.
- SELECT
- one column
- multiple columns
- all columns
- distinct select
- aggregate functions
- count-select
- sum-select
- avg-select
- min-select
- max-select
- JOIN
- inner join
- natural join
- WHERE
- one condition
- multiple conditions
- junction
- disjunction
- cross-condition
- operators
- equal operator
- not equal operator
- greater-than operator
- less-than operator
- like operator
- between operator (not 100% efficient)
- aggregate functions
- sum in condition
- avg in condition
- min in condition
- max in condition
- ORDER BY
- ASC
- DESC
- GROUP BY
- multiple queries
- exception and error handling
- detection of values (not 100% efficient)
The tool can deal with any language, so long as it has its configuration file (i.e. a file with the keywords of the language).
Language configuration files can be found in lang/ directory. The files are CSV files. Each line represent a type of keywords. Anything before the colon is ignored. Keywords must be separated by a comma.
You can build your own language configuration file following the English and French templates.
To be effective ln2sql need to learn the data model of the database that the user want to query. It need to load the corresponding SQL dump file to do that.
A database dump is a file containing a record of the table structure and/or the data of a database.
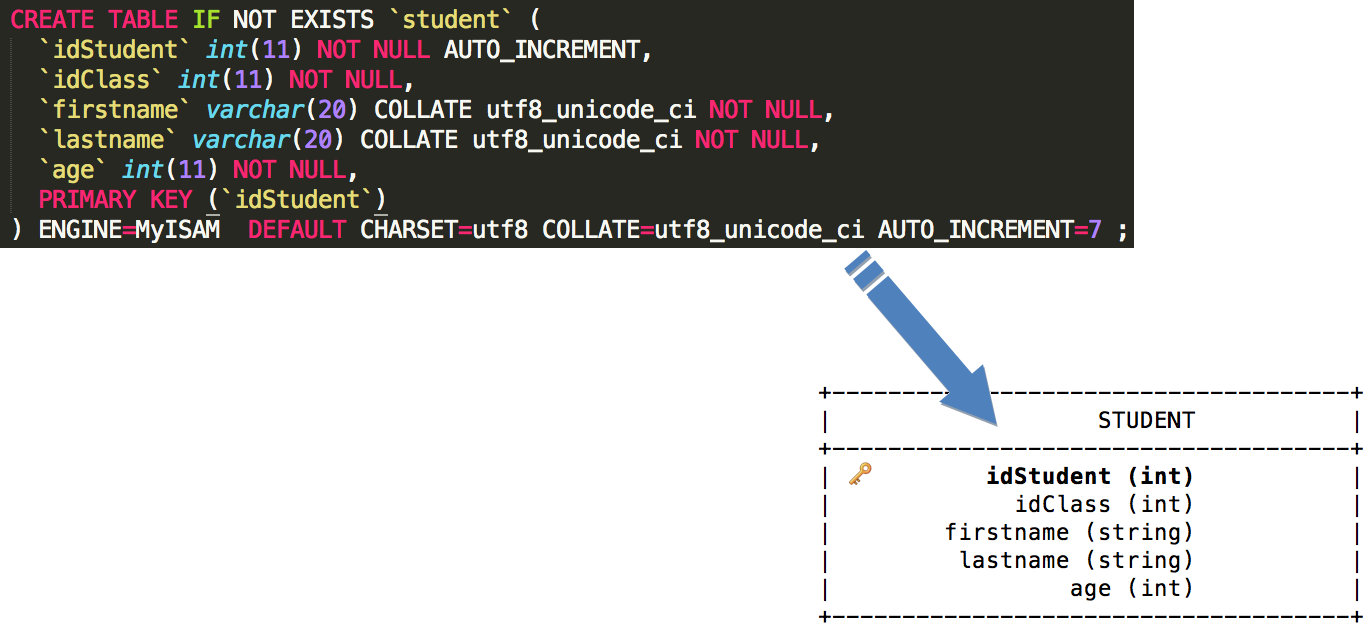
database = Database()
database.load("database/tal.sql")
database.print_me()For the following SQL statements loaded, the output in the terminal looks like:
You can improve the keyword filtering using a thesaurus. Thesaurus can be found in thesaurus/ directory. You can build your own thesaurus following the OpenOffice template.
You can improve the stop word filtering using a stop word list. You can build your own stop word list following the template of the lists in stopwords/ directory.
You can directly use the python wrapper by the following way:
Usage:
From the cloned source:
python3 -m ln2sql.main -d <path> -l <path> -i <input-sentence> [-j <path>] [-t <path>] [-s <path>]
Parameters:
-h print this help message
-d <path> path to sql dump file
-l <path> path to language configuration file
-i <input-sentence> input sentence to parse
-j <path> path to JSON output file
-t <path> path to thesaurus file
-s <path> path to stopwords file
example of usage:
python3 -m ln2sql.main -d database_store/city.sql -l lang_store/english.csv -j output.json -i "Count how many city there are with the name blob?"
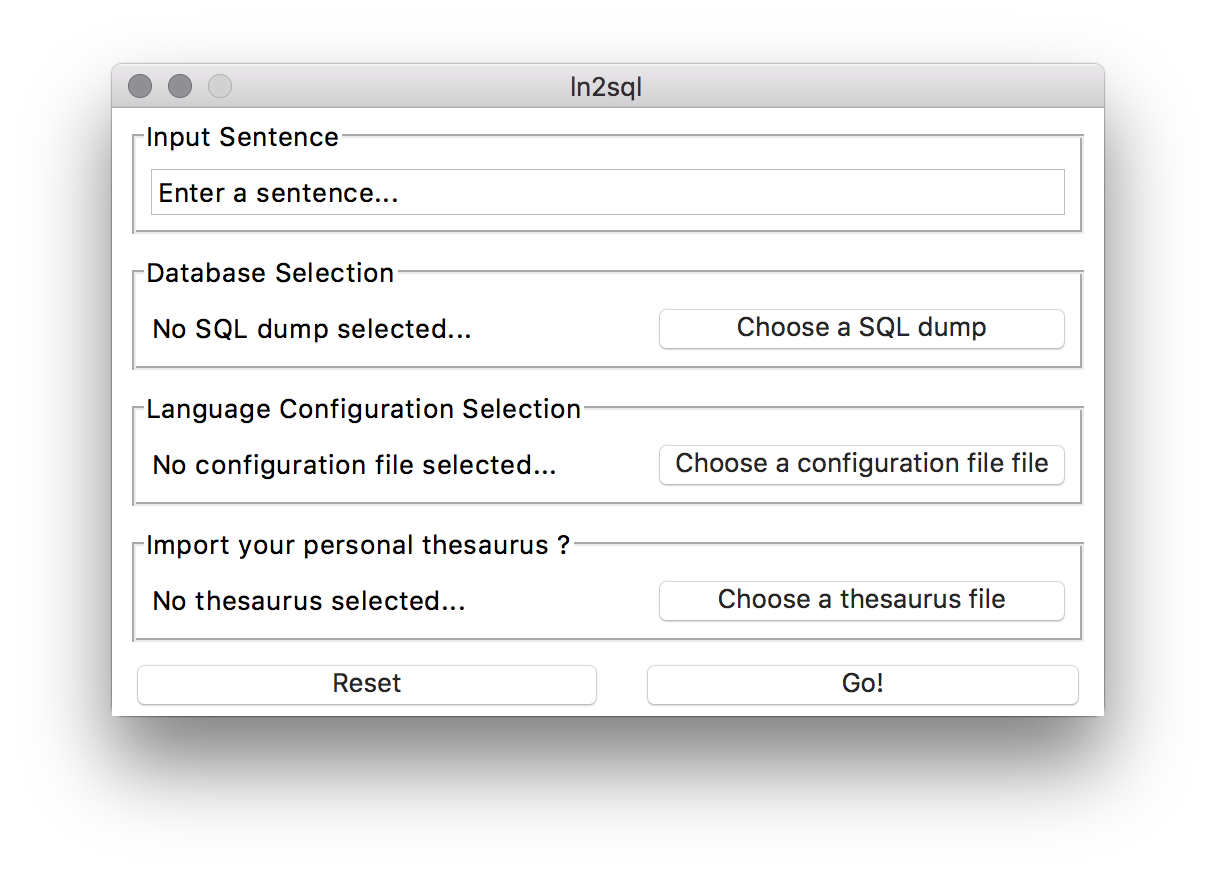
or by graphical interface by typing the following command:
python ln2sql/ln2sql_gui.py
a window like the one below will appear:
With the following input:
What is the average age of students whose name is Doe or age over 25?
the output is:
{
"select": {
"column": "age",
"type": "AVG"
},
"from": {
"table": "student"
},
"join": {
},
"where": {
"conditions": [
{ "column": "name",
"operator": "=",
"value": "Doe"
},
{
"operator": "OR"
},
{ "column": "age",
"operator": ">",
"value": "25"
}
]
},
"group_by": {
},
"order_by": {
}
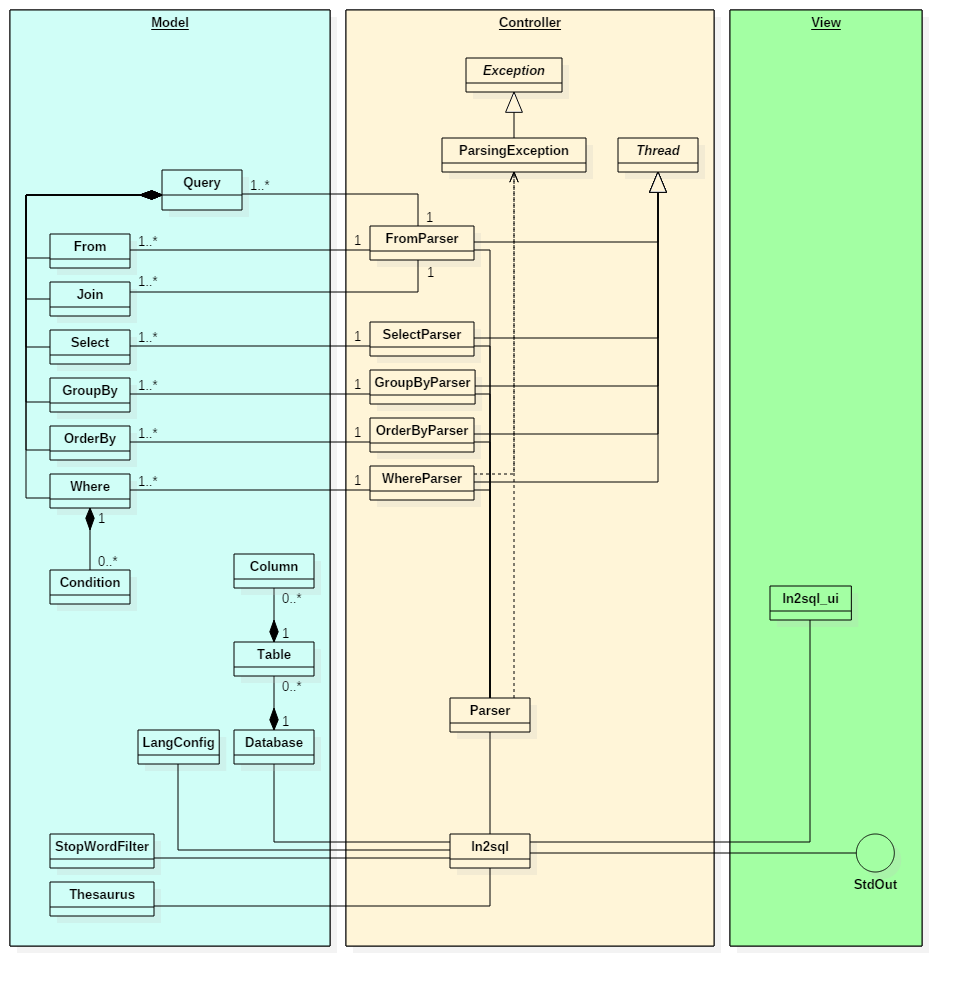
}The tool is implemented under the Model-View-Controller pattern. The classes imported from the Python Standard Library do not appear in the diagram except those required for inheritance (e.g. Thread or Exception).